






十大排序算法
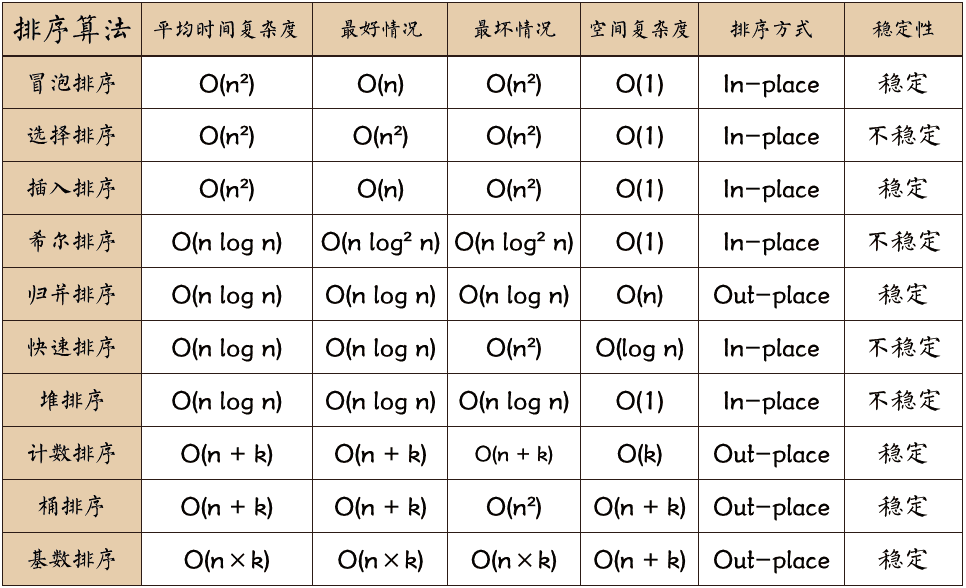
常见的排序算法包括:冒泡排序、选择排序、插入排序、归并排序、快速排序、希尔排序、堆排序、计数排序、桶排序、基数排序
冒泡排序
在相邻元素相等时,它们并不会交换位置,所以,冒泡排序是稳定排序。
void bubbleSort(vector<int> & nums){
// 循环n-1次
for(int i = 0; i < nums.size() - 1; i++){
// 每次循环找到一个最大(小)值,因此每次循环次数随着i的增加减少
for(int j = 0; j < nums.size() - i - 1; j++){
//升序,把大数换到靠后的位置
if(nums[j] > nums[j + 1]){
//交换相邻两个数
swap(nums[j], nums[j + 1]);
}
}
}
}
选择排序
void selectSort(vector<int> & nums){
for(int i = 0; i < nums.size() - 1; i++){ // 循环 n - 1 次
int minIdx = i; //循环找到最小值的下标,然后将最小值与起始值交换
for(int j = i; j < nums.size(); j++){
if(nums[minIdx] > nums[j]){
minIdx = j;
}
}
swap(nums[i], nums[minIdx]);
}
}
插入排序
void insertSort(vector<int> & nums){
for(int i = 1; i < nums.size(); i++){ // n - 1次循环
int j;
int num = nums[i];
//向前找到第一个小于等于当前数的元素num[j],将之后的元素向后移动一位
for(j = i - 1; j >= 0; j--){
if(num < nums[j]){ //后移
nums[j + 1] = nums[j]; //或者swap(nums[j], nums[j + 1]);
}else{
break;
}
}
//将num赋值给num[j]的下一位
nums[j + 1] = num;
}
}
希尔排序
希尔排序,也称递减增量排序算法,是插入排序的一种更高效的改进版本。但希尔排序是非稳定排序算法。
希尔排序是基于插入排序的以下两点性质而提出改进方法的:
- 插入排序在对几乎已经排好序的数据操作时,效率高,即可以达到线性排序的效率;
- 但插入排序一般来说是低效的,因为插入排序每次只能将数据移动一位;
希尔排序的基本思想是:先将整个待排序的记录序列分割成为若干子序列分别进行直接插入排序,待整个序列中的记录"基本有序"时,再对全体记录进行依次直接插入排序。
void shell_sort(vector<int> & nums) {
//增量gap,并逐步缩小增量
for (int gap = nums.size() / 2; gap > 0; gap /= 2) {
//从第gap个元素,逐个对其所在组进行直接插入排序操作
for (int i = gap; i < nums.size(); i++) {
for(int j = i; j >= gap && nums[j] < nums[j - gap]; j -= gap){
swap(nums[j], nums[j - gap]);
}
}
}
}
归并排序
void merge(vector<int> & vec, int L1, int R1, int L2, int R2){
vector<int> temp; //辅助数组
int begin = L1;
while(L1 <= R1 && L2 <= R2){
if(vec[L1] < vec[L2]){
temp.push_back(vec[L1++]);
}else{
temp.push_back(vec[L2++]);
}
}
while(L1 <= R1){
temp.push_back(vec[L1++]);
}
while(L2 <= R2){
temp.push_back(vec[L2++]);
}
vec.assign(temp.begin(), temp.end());
}
void mergeSort(vector<int> & vec, int left, int right){
if(left < right){
int mid = (left + right) / 2;
mergeSort(vec, left, mid);
mergeSort(vec, mid + 1, right);
merge(vec, left, mid, mid + 1, right);
}
}
快速排序
快速排序为什么叫快速排序?
https://blog.csdn.net/weixin_41445507/article/details/90255906
https://blog.csdn.net/linfeng24/article/details/38429055
int quick(vector<int> & vec, int left, int right){
int temp = vec[left];
while(left < right){
//找到左边第一个大于等于temp的数
while(left < right && vec[left] < temp){
left += 1;
}
//找到右边第一个小于等于temp的数
while(left < right && vec[right] > temp){
right -= 1;
}
//交换两数
swap(vec[left], vec[right]);
}
return left;
}
void quickSort(vector<int> & vec, int left, int right){
if(left < right){
int pos = quick(vec, left, right);
quickSort(vec, left, pos - 1);
quickSort(vec, pos + 1, right);
}
}
堆排序
堆排序(Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆积是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。堆排序可以说是一种利用堆的概念来排序的选择排序。分为两种方法:
- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列;
- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列;
堆排序的平均时间复杂度为 Ο(nlogn)。
// 建立大顶堆
void buildMaxHeap(vector<int> & nums) {
// 对每一个非叶子结点进行堆调整
for (int i = nums.size() / 2; i >= 0; i--) {
heapify(nums, i);
}
}
// 堆调整, 从第i个节点开始调整
void heapify(vector<int> & nums, int i, int size) {
int left = 2 * i + 1; //左孩子
int right = 2 * i + 2; //右孩子
int largest = i;
//找到左右孩子中的最大值
if (left < size && nums[left] > nums[largest]) {
largest = left;
}
if (right < size && nums[right] > nums[largest]) {
largest = right;
}
//与父结点替换
if (largest != i) {
swap(nums[i], nums[largest]);
heapify(nums, largest);
}
}
void heapSort(vector<int> & nums) {
buildMaxHeap(nums);
for (int i = nums.size() - 1; i > 0; i--) {
// 每次将堆顶节点放到最后
swap(nums[0], nums[i]);
heapify(nums, 0, i);
}
return nums;
}
计数排序
计数排序不是比较排序,排序的速度快于任何比较排序算法。
由于用来计数的数组的长度取决于待排序数组中数据的范围(等于待排序数组的最大值与最小值的差加上1),这使得计数排序对于数据范围很大的数组,需要大量时间和内存。
void countingSort(vector<int> & nums) {
int maxValue = nums[0];
//找最大值
for(int i = 1; i < nums.size(); i++){
maxValue = max(maxValue, nums[i]);
}
vector<int> bucket(maxValue + 1, 0);
for (int i = 0; i < maxValue + 1; i++) {
bucket[nums[i]] += 1;
}
int idx = 0;
for (int i = 0; i < maxValue + 1; i++) {
while(bucket[i] > 0) {
nums[idx++] = i;
bucket[i] -= 1;
}
}
}
桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。为了使桶排序更加高效,我们需要做到这两点:
- 在额外空间充足的情况下,尽量增大桶的数量
- 使用的映射函数能够将输入的 N 个数据均匀的分配到 K 个桶中
同时,对于桶中元素的排序,选择何种比较排序算法对于性能的影响至关重要。
- 什么时候最快
当输入的数据可以均匀的分配到每一个桶中。
- 什么时候最慢
当输入的数据被分配到了同一个桶中。
基数排序
基数排序是一种非比较型整数排序算法
基数排序,计数排序,桶排序这三种排序算法都利用了桶的概念,但对桶的使用方法上有明显差异:
- 基数排序:根据键值的每位数字来分配桶;
- 计数排序:每个桶只存储单一键值;
- 桶排序:每个桶存储一定范围的数值;















 2974
2974











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









