






论文指路:https://arxiv.org/pdf/2010.00456.pdf
本人刚入门目标检测,自己看论文的时候做的些记录。
有很多地方的中文翻译可能有歧义。
如果有错误还希望指正。
1 Introduction
以人为核心的计算机视觉任务(如:行人检测,行人重识别,搜索人,人脸识别)在过去十年里收到了长足的发展,而其中最重要的便是行人检测任务,因为踏实很多其他任务的基础。比如说如果你想要对某个人进行重识别再定位,那么你首先应该要精确地检测出所有场景里现存的行人。
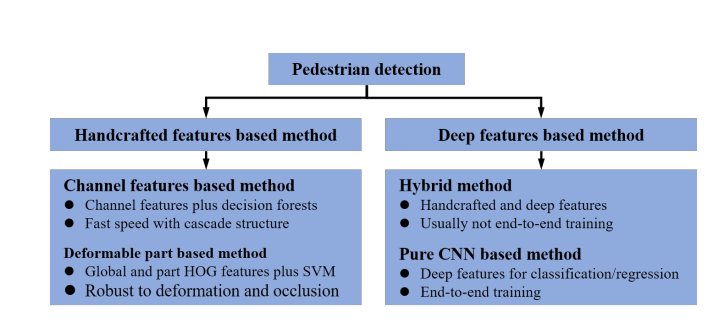
这十年来,行人检测变得愈发热门,技术也有了长足的进步。行人检测的方法一般有三种:基于手工特征的,基于深度学习的,两者兼有的。基于纯深度学习的方法包含了端到端的训练过程,其中proposal generation和classification是网络混合着一起学习的。在混合方法中,有些采用深度特征来处理proposal generation问题,而分类时则采用浅层的分类器,如SVM或者AdaBoost,而有些则采用手工方法来进行proposal generation,classification时采用深度特征的方法。
常用的数据集Caltech上的数据会分为reasonable set(R set)及high occluded set(HO set)。R set上的行人数据高于50像素,并且少于35%的身体被遮挡。HO set上的行人数据也高于50像素,但会有35%-80%的数据被遮挡。我们现在已经能在R set上取得满意的成绩,而HO set上得到的结果还远远不令人满意。
在随后的介绍中,我们会将现存的行人检测问题分成单光谱行人检测及多光谱行人检测。单光谱行人检测意味着只有单一的传感器被使用(如可见光摄像机,或者鱼眼摄像机),我们的研究通常是基于可见光传感器来进行的。而多光谱行人检测会使用多种类型的传感器,我们在下面主要是基于可见光摄像机和红外摄像机来讲述的。同单光谱行人检测相比,多光谱行人检测在光照的变化上更加的鲁棒,因此在近些年收到了更多的关注。
2 行人检测流水线(PD pipeline)
大部分行人检测方法(包括上面所提到过的基于手工特征的,基于深度学习特征的和两者兼有的)都会包含三个连续的步骤:proposal generation,classification(or regression),post processing。但也请注意并不是所有的方法都包含这三个步骤。一些创新的方法会减少了下面中的某个步骤,但不失偏颇,我们下面来说一下这三个步骤是干什么的。
(a)proposal generation
这一步旨在从输入中抽取一些候选提议。这些提议其实就是一些可能会表示物体的边缘框。常用的有三种方法:滑动窗口(SW),particle-window法及objectness法。SW:采用了一种贪婪搜索法,以固定的步长从图片左上扫到右下。PW:采用了由粗到细的级联搜索法,在当前阶段生成的proposal是按照上一阶段的概率分布来进行推断的。O法:采用了自下而上的方式从一些低级特征中抽取出proposal。几年来,一种RPN也被提出用来proposal generation,这是完全基于深度学习的方法,并且会和classification(regression)share deep features。
(b)proposal classification
这一步想要通过基于上一步proposal中抽取的feature来将候选提议进行分类:正类(行人),负类(背景)。基于手工特征的方法会采用一种浅层分类器(SVM or AdaBoost)来进行分类。基于深度特征的方法总是会通过使用一个softmax层,将抽取特征和分类融合进一个框架,即将generation 和 classification融合的方法。此外基于深度特征的方法会在classification的同时并行regression来精炼BB的位置。
(c)post processing
在进行proposal classification后,单个行人有可能会被很多边缘框选中,这种问题也叫作复制检测的问题。而NMS的技术能够帮助我们选中每个物体最佳的边缘框并且抑制其他复制的边缘框。相关的方法可以被分为两类:启发式的方法和学习式的方法。前者会根据classification的分数将边缘框融合,同时达到一直重叠边缘框和低分边缘框的效果。后者则会学习一种映射来保持大部分准确的边缘框。
我们可以看到,特征提取是proposal generation和classification中的重要组成部分,它的主要目的是用一些高辨识力特征来取代proposal。因此,有很多特征(无论是基于手工的,还是基于深度学习的)被踢了出来。基于现成的特征提取框架,行人检测的方法可以被粗略分为两类:基于手工特征的方法和基于深度特征的方法。大部分手工特征基于局部的差或者和,其中最著名的算法HOG能够捕获局部密度上的变化。而深度特征则是从CNN里通过一系列卷积和池化抽取出来的,深层的特征更具有辨识力,而底层的特征具有高分辨率。
3 单光谱行人检测

3.1 基于手工特征的行人检测
在深度卷积神经网络大火以前,是手工特征的天下。这些手工特征总是提取颜色,纹理或者边缘信息。其中应用最广泛的就是HOG。此外,现存的基于手工特征的方法要么使用通道特征,要么就使用变形体(DPM)模型。下面我们简要介绍一下基于手工特征的训练步骤和推断步骤
Training:训练的proposal是用滑动窗口法生成的。拥有和GT有高重叠的proposal被认为是正类。给定正类和负类样本,手工特征被提取出来来代替这些样本。基于提取出来的特征,可以使用浅层分类器来学出来一个行人检测器来区分正类和负类。为了提高检测的表现,bootstrap(HNM的技术)被使用,上一阶段的hard example被留到下个阶段继续训练。在最终阶段训练好的检测器会被用于inference。
Inference:给订一张输入图片,先从不同的proposals(from SW)中提取出手工特征。当proposal被手工特征替代时,他们就可以被用于classification。因为现实世界行人总是以不同的大小出现在摄像头中,输入的图片首先要在不同的尺度被resized,然后再在不同的尺度上应用检测器。随后再使用NMS来去除复制的边缘框。
3.1.1 基于通道特征的方法
大部分基于通道特征的方法会从不同类型的通道抽取不同的局部特征。接着混合使用Boosting技术及决策森林来训练一个行人检测器。最早的应用是VJ Det.随后ChnFtrs改进了,在此基础上又出现了一些列变种(基于HOG+LUV的,和一些基于其他通道特征的方法)。
由于行人检测只关注行人这个类别,一些行人独有的特征可以被很好地使用。比如利用某些先验知识:人由头,上半身,下半身组成。并且人的样貌是稳定的,形状也是对称的。基于这些先验知识,一些新的特征又被提出。此外我们还发现在形状和空间上拥有更大自由度的手工特征会有更好的准确率。
然而所有的方法不仅仅是关注准确率,也有些方法关注提升检测的速度。Dollar提出了fast feature pyramid,旨在通过单一尺度的通道特征来估计相邻尺度的通道特征。此外还有更多的改进。
3.1.2 基于变形体(DP)的方法
DPM被提出来更好地捕获物体的变形,行人就是其中很好的例子。DPM由一个粗糙的根分类器和一系列的高清体变形的模型组成。最终的得分由根分类器的得分加上高分辨率模型的得分和再减去变形的损耗构成。在每个高分辨率的变形体模型中,HOG都被广泛使用于提取特征。因为HOG对于局部形状的变化能很好地捕捉,变形体也能很好的捕捉形体的变化,这种方法得到了很棒的结果。随后,一些DPM的变种被提出来了,一部分是关注准确率的,另一部分则是关注速度。
3.2 基于深度特征的行人检测
CNN的大火使得它被应用于行人检测,并且也获得了不错的成果。

3.2.1 混合行人检测方法
根据CNN用处的不同:generation或者classification,我们可以分成两类。但它们都使用相同的训练和推断范式。
Training
(1)CNN for generation:深度特征从与训练好的CNN+输入的样本上抽取出来。接着我们使用SVM + Bootstrap来学习行人监测器。训练样本用基于手工特征的方法或者SW生成。
(2)CNN for classification:基于手工特征的方法被用来产生proposal。然后用CNN + softmax layer以端到端的方式来进行训练分类。
Inference
(1)CNN for generation:深度特征从全图上被抽取出来。接着,训练过的检测器以固定的步长在抽取出的特征图上进行滑动,每个位置按照相应的特征都会被分类会正类或者负类。最后使用NMS来抑制复制边缘框的生成。
(2)CNN for classification:基于手工特征的方法被用来进行抽取proposal。接着,训练好的CNN将这些proposal分类为正类或者负类。最后使用NMS来抑制复制边缘框的生成。
其中的具体方法也可被分为追求速度和追求准确率的两类,总体的指导思想是要充分利用每一层的特征的invariance和equivalence,并且用简单的方法、更低的算力去检测简单的物体,用困难的算法、更高的算力去检测困难的物体。
3.2.2 基于纯CNN的行人检测方法
在基于纯CNN的行人检测方法中,CNN既被用于proposal generation,又被用于proposal classification。直接将Faster-RCNN来做行人检测的效果并不好,但研究者对此做了一些改变,达到了惊人的效果:更加高效,更加简单。其训练及推断范式如下。
Training:给定一张训练的图片,CNN被用于提取深度特征。锚框被设置在特征图的每个位置,并且已经标注好正类或者负类的标签。根据不同的dataset,我们对网络进行调参以达到更好的效果。
Inference:给订一张测试图片,深度特征被CNN提取出来。首先,一些候选提议根据固定的锚框方法被生成。接着她们被丢进softmax来进行分类并且通过回归可以得到更好的效果。最后,使用NMS来抑制复制边缘框的生成。
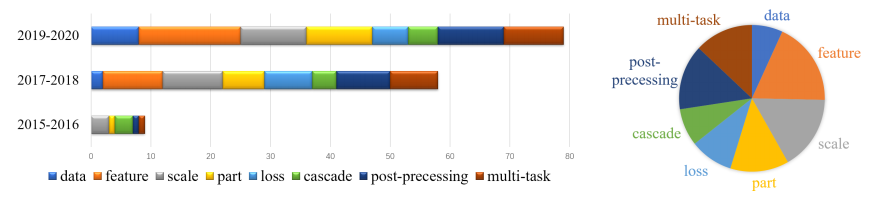
近些年来,一些基于纯CNN的行人检测方法研究方向如下:
-
Scale-aware:尺度感知的方法总体上是使用了不同的子网络来检测不同尺度大小下的物体。一些方法研究从不同的层上面抽取出RoI features(scale-aware RoI),一些方法则是研究从不同的层来生成候选提议。
-
Part-based:一个物体的局部特征在捕捉遮挡或者变形行人的情况下十分重要。一些方法研究如何整合部分信息,还有些方法则是在研究怎样更好地使用行人的可见身体部分。
-
Attention-based:基于注意力的方法旨在增强行人的特征,同时抑制背景的特征。相关的方法可以被分为:自注意力机制的方法和语义引导下的注意力的方法。前者使用注意力机制来联系特征的不同位置。后者则是想将一些高级的语义信息和行人检测结合起来,这也可以被看作是多任务方法。
-
Feature-fused:特征融合类方法旨在通过多尺度特征融合来捕捉有用的语境的和高级语义的信息。
-
Cascade-based:为了能提高定位精确性,级联的结构已经在通用物体识别中广泛地使用。现在,级联的体系结构也被用于行人检测。
-
Anchor-free:无需锚框的方法直接预测了每个位置的分数和行人的位置或者形状。与需要锚框的方法相比,无需锚框的方法避免了关于锚框的尺度和纵宽比的人工设计,因此其更加简单,有更好的泛化能力。
-
Data-augumentation based:基于数据增强的方法旨在提升检测的表现。其中的一些方法关注生成更多的行人或者图片,通过有关摄像机的先验知识及GAN,我们能不错的做到。另外一些方法则是关注更加充分利用现有的数据:如增加新的阻挡。
-
Loss-driven:损失驱使的方法要么在行人检测中使用新的损失函数,要么添加额外的损失函数。其中的一些方法致力于降低不同样本之间特征图的差别以希望使小样本检测起来像大样本一样简单。
-
Post-processing:后处理方法中希望能够通过改进NMS来得到更好的融合效果。
-
Multi-task:多任务方法使用将语义信息融入行人检测来帮助行人检测得到更好的效果。
-
Others:上面提到的方向大部分是关于色图中的行人检测的,现在还有一些针对热像或者鱼眼图的行人检测的优化被提出。
4 多光谱行人检测
单光谱检测中的色图并没有很好地在夜晚获取信息的能力,因此多光谱行人检测在自动驾驶和摄像头中的作用就体现出来了。其中的一些方法在研究如何深度融合多光谱的图片,包括输入融合,特征融合及决策融合。此外,为了解决在色图及热像定位不准确的问题,位置变换和特征融合也是值得关注的问题。
5 数据集及度量标准


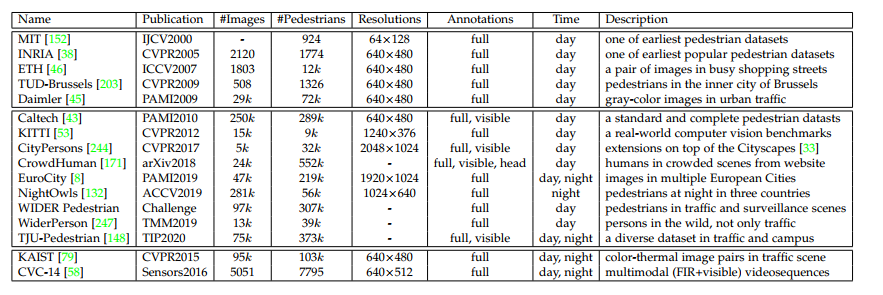
5.1 早期的行人数据集
- MIT、INRIA、ETH、TUD-Brussels、Daimler
5.2 现代行人数据集
早期的行人数据集上的表现已经饱和了,所以我们用现代的数据集。
-
Caltech:最常用,包含了11个从城市中摄影的录像集。6个用来train,大概每3帧一个。5个用来test,大概每30帧一个。提供了全体的边缘框注释,也提供了可见部分的边缘框注释。
-
KITTI:包括了很多计算机视觉任务,不仅仅用于行人检测,也可用于一般的物体识别。更加高清。
-
CityPersons:来源:CityScapes。有不同城市,不同季节,不同天气条件的场景和更多的行人。
-
CrowdHuman:每张图平均23个人。拥有全身,可见部分,头的边缘框注释。
-
EuroCity persons:白天黑夜都有。做不同事情的人:行人,骑自行车的人等等。更加高清。欧洲城市。
-
NightOwls:仅有晚上的。
-
WIDER Pedestrian:专注于监控摄像头和车辆驾驶场景下的行人和骑自行车的人。有更多种的遮挡。
5.3 多光谱行人数据集
在可见光和热像摄像头下建设的数据集。
- KAIST:色图及热像
- CVC-14:FIR 及 可见光。注意两个传感器的视角及分辨率都不同。
5.4 评价指标
三个常用的指标是MR(miss rate),AP(average precision),JI(jaccard index)。MR和AP是最常用的,而JI是近来才开始用的。
-
対数平均误检率(log-average miss rate)
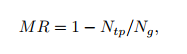
通过改变检测的置信度,误检率against FPPI(对等地分布在[10^-2, 10^0]中)可以以log曲线的趋势画出来。更低的误检率意味着更好的表现。
Caltech和CityPerson数据集在不同的集合上评估误检率,例如R set,RS set,HO set,R + HO set及 A set。R set上的行人数据高于50像素,并且少于35%的身体被遮挡。RS set上的行人数据高于50像素但低于75像素,并且少于35%的身体被遮挡。HO set上的行人数据也高于50像素,但会有35%-80%的数据被遮挡。R+HO 即 R set Union HO set。A set上的行人数据超过20像素并且少于80%的遮挡。
- 平均精度(Average precision)
召回率和精度可以按照以下的标准来进行计算。通过改变置信分数的阈值,精度against召回率可以画成一条弧线。基于这条弧线,平均精度可以通过在[0, 1]间均匀分布的召回率下能够画出。越高的AP意味着更好的表现。
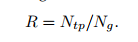
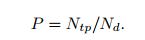
KITTI数据集在三个集合上测量AP: Easy, Medium, Hard。Easy上的行人数据超过40像素高且没有遮挡,Medium上的数据超过25像素高且只有少部分遮挡,Hard上的数据高于25像素且有更高程度的遮挡。
- Jaccard Index(雅卡尔系数)
雅卡尔系数按照如下公式计算,它被用于评价拥挤场景下的表现。当提高置信阈值时,JI会先增再减。所以一般会用贪婪搜索法来帮助找到最好的JI score。如果检测器拥有一个更大的最好情况下的JI score,那么说明它表现更好。
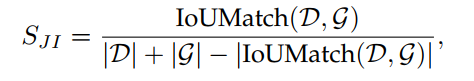
5.5 先进水平比较和分析
总体看来,基于深度特征的方法会比基于手工特征的方法表现的更好。而如果使用时间序列信息,那么表现会更好。一种可能的原因是:时间序列信息在小物体和遮挡物体检测中拥有重要的作用。
如果对Caltech数据集使用新的和更准确的标注,那么也会取得更好的效果。并且根据目前的情况看来,在Caltech数据集上的表现已经饱和。
在KITTI数据集上只采用了简单的二维标注。Hard set上的表现平均比Easy set上的表现低10%左右。采用多尺度特征融合及数据增强策略的特征金字塔体系架构会得到不错的效果。
在CityPerson上,两步的检测器和一步的检测器两者都在检测准确率上达到了先进水平。对遮挡行人检测来说,使用部分信息(head,visible body)会有很不错的帮助。而除了检测准确率,我们发现一步的检测器会有更快的速度。这表明,单步的检测器在准确率和检测速度上有更好的权衡。
而在多光谱数据集KAIST上,单步的检测器MBNet取得了更好的成绩。
在下面,我们将从不同方面对行人检测进行分析。
- 与一般物体识别的比较
通常来说,行人识别只需识别行人这一类别,而通用物体识别则需要识别多个类别。经过试验我们发现使用多类别训练的策略并不会帮助提升在行人检测上的表现。那么如何有效地研究语境信息和人与物体的关系会是未来的一个重要研究方向。
- 数据处理的影响
通过控制变量,我们发现如下五点:(1)在训练样本中添加小尺度和遮挡样本会增强检测器的检测能力;(2)使用多尺度训练策略也会提升检测器的表现;(3)随机地擦除像素级别行人信息会提升检测器对遮挡样本的检测能力,因为这会增加行人遮挡的多样性;(4)如果只是单纯的复制粘贴行人来增加样本数据,并不会获得重大的提升。考虑到简单的复制粘贴边缘框的方法也会带来不正确的背景信息和样式的不一致性;(5)如果在相似场景或者多样本的数据集上进行预训练则会获得不错的提升,否则并不会有重大的改变。
- 特征提取的影响
使用不同的backbone进行试验,发现HRNet得到了最好的效果。可能的解释是高分辨率和高语义的表示对提升行人检测来说十分重要。
- 泛化能力
相对于单数据集的训练而言,跨数据集的训练并不能够带来很好的效果,但可以用来检测模型的泛化能力。相较而言,RCNN系列的模型在泛化能力上表现的更差一些。
6 挑战
6.1 尺度变化
交通和监控是行人检测应用最多的场景,但大尺度的目标和小尺度的目标总是会表现出类内区别。因此,想用单传感器来对不同尺度的行人进行检测是很困难的问题。
一种直接的想法就是采用基于尺度的策略,包括基于图像金字塔和特征金字塔的两类方法。对前者而言,提升它的效率是很重要的事情。而对后者而言如何提取鲁棒的特征则是更重要的事情。一种其他做法是减少不同尺度的行人的区别,我们可以通过GAN研究如何减少图像程度和特征程度上的类内区别。
此外,小尺度行人检测也是尺度变化里的瓶颈问题。但也同时缺少研究。
6.2 遮挡
现实中的行人总是被遮挡住的,而遮挡一般分为两类:跨类遮挡和类内遮挡。对跨类遮挡的主要解决办法就是增强未遮挡部分的特征并且抑制遮挡部分的特征。而这又分为两种策略:非清晰策略和清晰策略。前者通常学习多个部分的分类器来覆盖不同的遮挡模式。那么,如何更好的分割/组合部分就变成了要解决的问题。而后者则是使用额外的标记,但额外的标记是很贵的。但用少量的部分标记的方式来帮助遮挡行人检测是很有效的。
通常,行人检测会使用NMS来去除复制的边缘框。但这样也带来负面效果:NMS可能会将拥挤场景下的属于不同物体的边缘框融合为一个。这种情况下的解决办法又分为两种:1.提升NMS的策略2.使用非NMS的策略来避免边缘框融合。此外,时序信息对于遮挡行人检测十分重要。
6.3 域适配
行人检测的问题通常是在某个特定的数据集上进行训练和检测,通常并不能拥有很棒的泛化能力。一些领域适应性的方法是基于数据级别,特征级别和物体级别的对抗学习而提出的。未来或许可以更多考虑行人或者场景特征来帮助增强域适配。此外在未来我们也可以研究相同领域和跨领域的评估,这可能也会有所帮助。
6.4 多传感器融合
多光谱行人检测在不同的光照条件下会更加鲁棒。但是如何去提高同质的传感器之间或者非同质的传感器之前的融合也是十分值得讨论的问题。
6.5 实时监测
很多的检测方法更加关注检测速度却忽略了检测效率,这样就导致了交通和监控应用方面的限制。并且检测的速度是与使用的设备息息相关的,因此去考虑如何让嵌入式设备达到实时的效率也是值得关注的问题。
参考文献
[1]Cao J, Pang Y, Xie J, et al. From handcrafted to deep features for pedestrian detection: a survey[J]. IEEE transactions on pattern analysis and machine intelligence, 2021.















 368
368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









