







 该论文详细探讨了自由开源软件中的许可证冲突问题,介绍了作者吴敬征的研究成果,包括DIKE工具的设计、评估和解决冲突的方法。DIKE通过自动化分析检测和管理许可证冲突,尤其是在MIT、Apache-2.0和GPL家族间的冲突。论文还提出了构建动态更新的许可证知识库以提高普适性的未来方向。
该论文详细探讨了自由开源软件中的许可证冲突问题,介绍了作者吴敬征的研究成果,包括DIKE工具的设计、评估和解决冲突的方法。DIKE通过自动化分析检测和管理许可证冲突,尤其是在MIT、Apache-2.0和GPL家族间的冲突。论文还提出了构建动态更新的许可证知识库以提高普适性的未来方向。
An Empirical Study of License Conflict in Free and Open Source Software论文分享

作者信息:
吴敬征
中国科学院软件研究所博导
研究领域:
软件安全与漏洞挖掘、开源软件与供应链安全、智能系统与机器学习、操作系统与指令集研究、网络安全与隐蔽通信。
实验室名称:智能软件研究中心
六大领域:智能理论、操作系统、开源生态、编译技术、智能安全、智能测评
四大系统:面向国产通用处理器和智能加速芯片的操作系统及工具链;面向 “RISC-V + AIoT” 的原生操作系统及工具链;开源软件可靠供应链管理平台;智能无人系统仿真测试平台
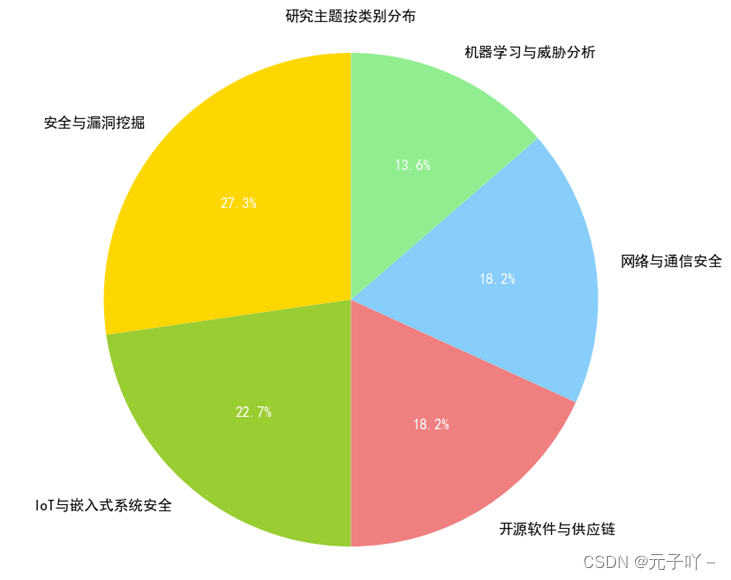
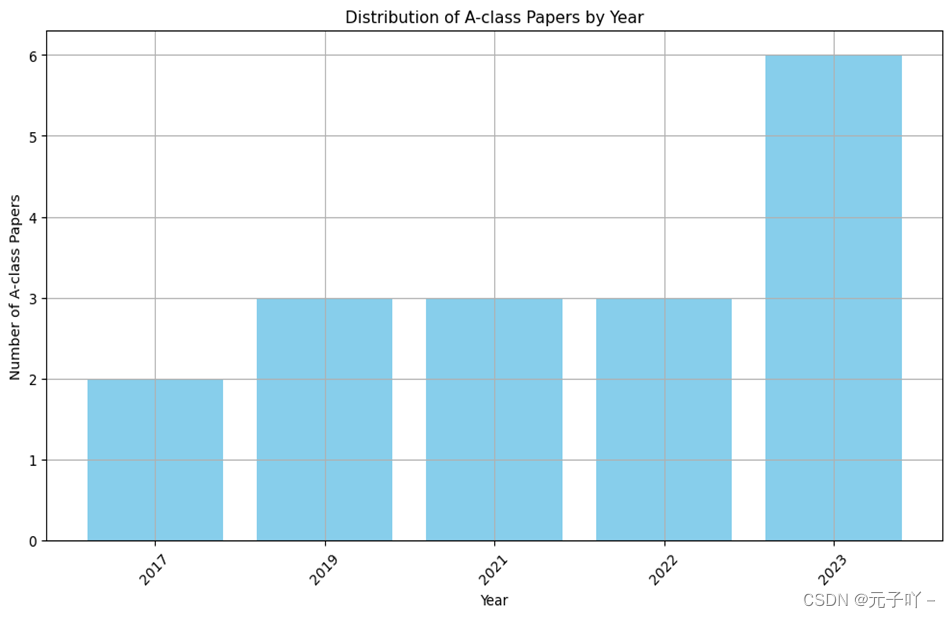
通过搜集和整理相关数据发现,在过去五年中,吴敬征主要是在信息安全领域发表了一系列CCF A类论文,如图所示。通过分析,他的研究领域跨越了从传统的安全漏洞挖掘到新兴的IoT、机器学习安全应用、开源软件等多个领域,这充分展示了他在信息安全领域中对多样性和前沿技术的深入洞察和贡献。进一步分析其近5年的发表记录,单独抽取出了他在开源软件相关研究方面的专业成就,其中包括本次讨论的论文以及两篇在《软件学报》上发表的关于软件供应链的关键研究成果。

接下来,从背景介绍、‘DIKE’工具的设计方法、‘DIKE’工具的评估、总结与个人思考分别介绍。
背景介绍
FOSS(自由开源软件)在软件项目中很普遍,但受到基于开源许可证类型的法律条款的规范。
目前的许可证评估工具只能识别软件中许可证的名称和数量,缺乏确保安全和正确使用,以及提供兼容性和风险的全面分析的能力。

下来,我们进行论文内容部分的介绍,在开源许可证冲突问题研究中,现有的研究主要集中识别和管理开源软件中使用的许可证、许可证语义分析,FOSSology、Ninka、Licensefinder、FindossLicense可以识别项目中使用的开源软件的许可证类型。Open Digital Rights Language (ODRL)、Qualipso project、FOSS-LTE提供了编码机制,实现对许可证灵活的定义和解释。虽然市场上有以上许可评估工具可以利用,但这些工具都有明显的局限性,存在有限的可区分特征和许可证数量。这就会导致在某些情况下,可能难以区分不同的许可证类型或许可证之间的差异。其次以前的工作侧重于识别许可证名称并列出在文件或代码片段上识别的信息并没有分析许可证之间的兼容性,以及很多是通过手工检查的,适用性不高。
由此,作者等人在此基础上提出了DIKE,一种自动化的许可证冲突分析工具,分别实现了许可证检测、冲突分析、解决方案提供等功能。接下来详细介绍下DIKE的设计。
本文对此,确立了三个研究问题,开源项目中许可证的使用情况,以及开源项目是否存在许可冲突,以及如何解决许可冲突问题。
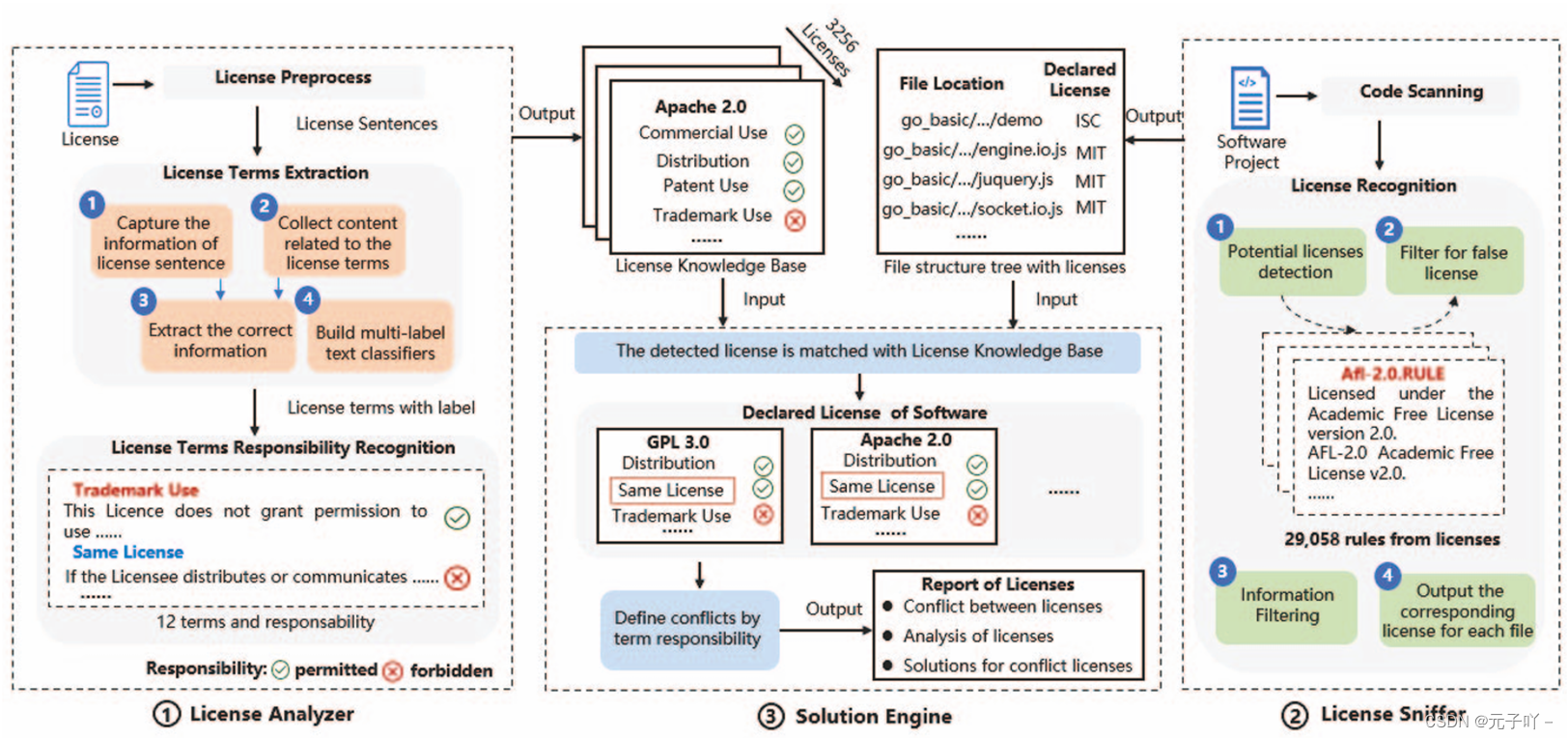
下来是DIKE框架,DIKE框架主要由许可证分析器、许可证嗅探器、解决方案的引擎三个组件组成,第一个是License Analyzer许可证分析器,负责许可证条款提取和责任认定,通过从外部知识构造许可条款责任知识库。第二个许可证嗅探器,主要负责检测软件的许可证条款。而解决方案的引擎,则是识别许可证冲突,并提供解决方案。接下来,对每一块的内容进行具体介绍。
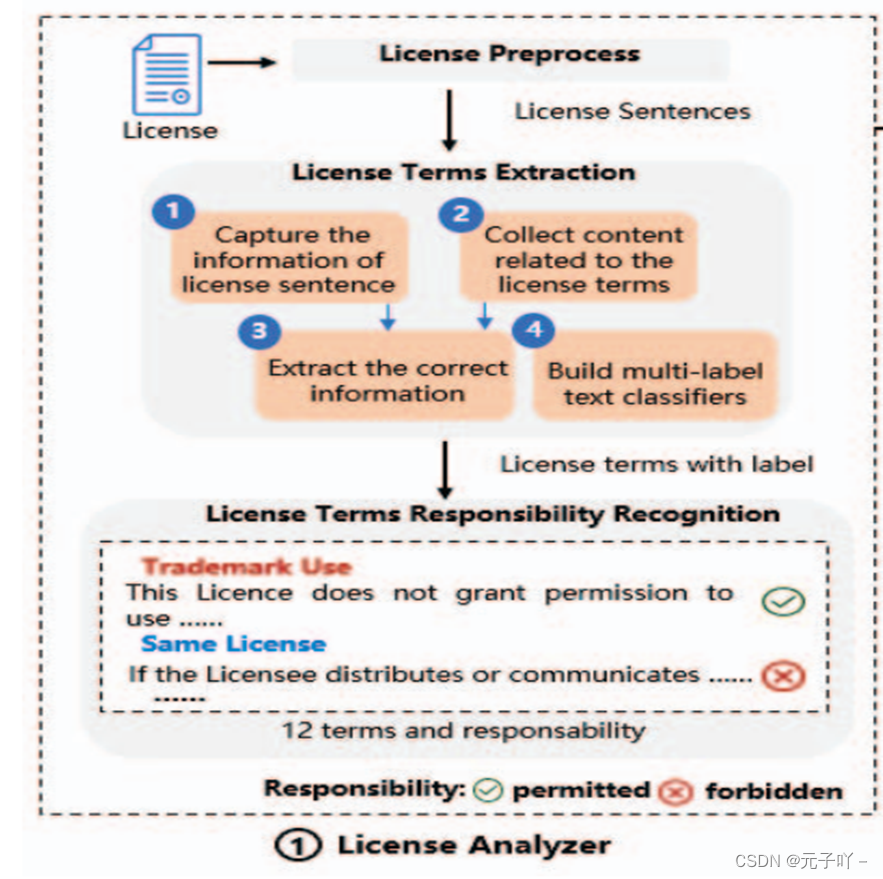
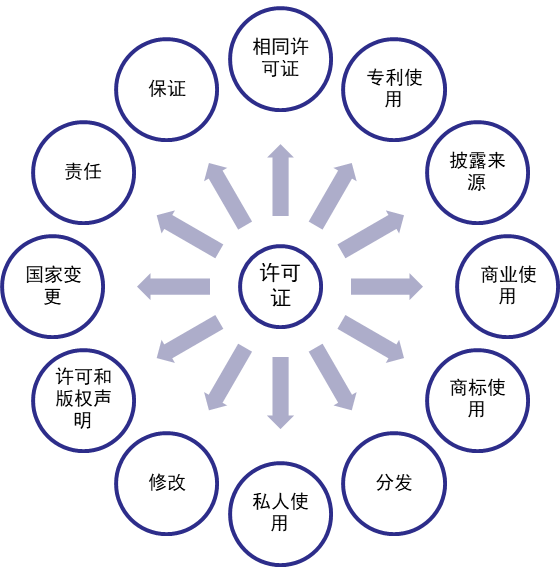
许可证分析器首先通过分析许可证文本特征构建多分类术语识别模型,术语是事先定义好的,如图呈现的,12种常见的许可证条款,然后基于二元分类,输出责任术语和可能值,最终构建包含许可证条款、责任的知识库。下面将进行展开描述。
许可证分析器要做的就是对许可证文本进行语义分析,提取出整个文本中的重要信息。先介绍下许可证分析器的注意力机制的思想。
注意力机制需要明确的是q,k,v三个指标,q查询的对象,v被查询的对象,目的是要计算Q和V里事物的重要度,自注意力机制它是需要q,k,v是同源的,也就是来源于同一文本,而注意力机制则q,v来源可不相同。比如说本论文中涉及到的标签注意力机制,Q指的是标签,v指的是文本,相当于再找于Q而言,K里面重要的信息。通过注意力机制和标签注意力机制来计算词与词和词与标签之间的关系。
下来再说下由将词向量转变为文本向量涉及到的LSTM方法,LSTM能够学习长期的依赖关系,存储部分词向量,并逐次流通每个词,也就是将词的表示组合成句子的表示,在这个过程中,决定去掉哪些信息,以及添加哪些新的信息,并不对信息进行更改处理,但因为标签具有特定的语义,它们通常是对文本内容的隐式描述,需要知道标签前后的句子信息,而lstm识别不了从后到前的信息,所以本文使用Bilstm,可以更好地捕捉双向的语义依赖。Bilstm通过两个lstm组成而成,一个是正向去处理输入序列,一个是反向处理序列,处理完成后将两个lstm输出拼接起来。介绍了以上先验知识后,说下DIKE许可证分析器的具体原理。
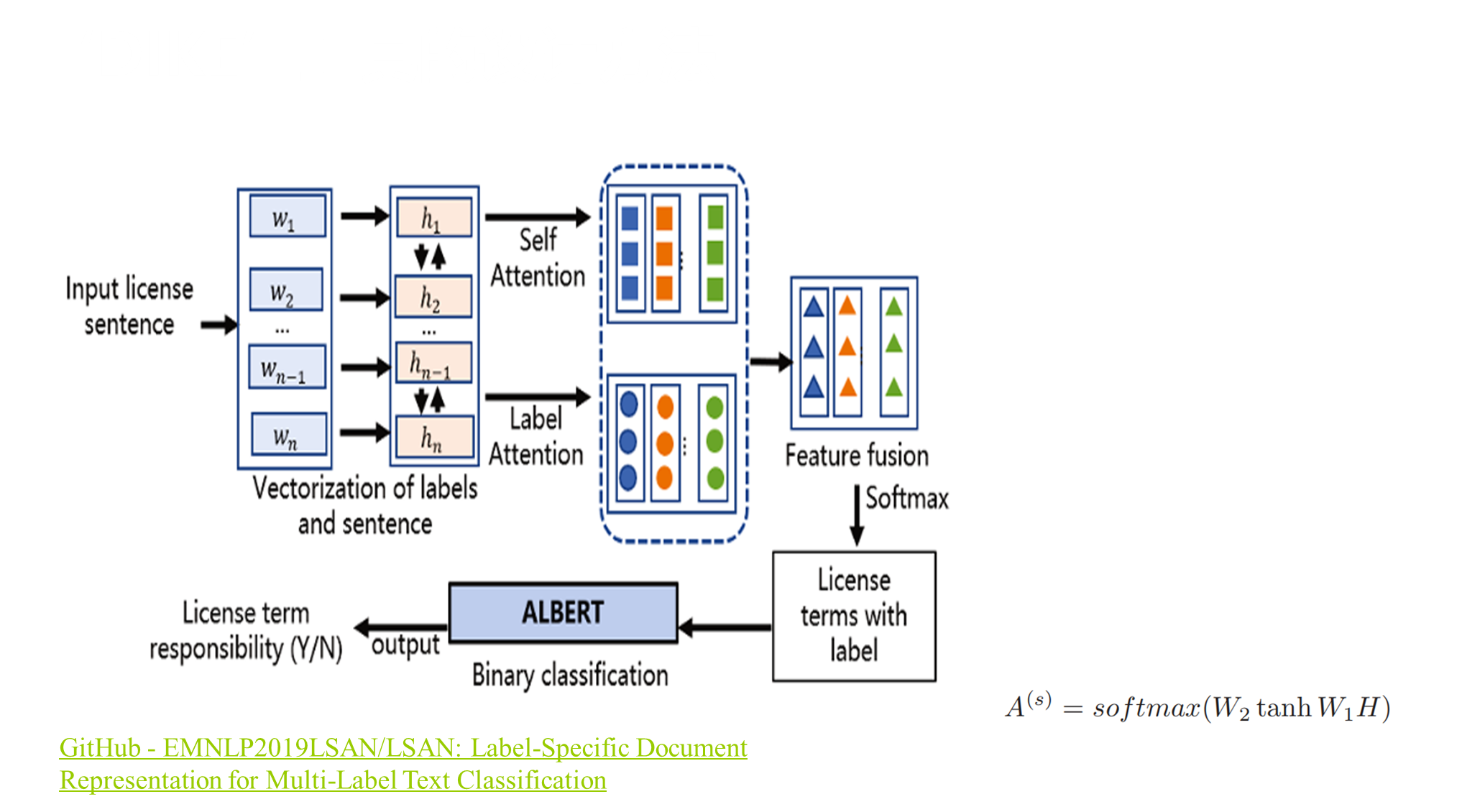
因为本文在解释method这部分,是非常模糊的,这里主要参考github中lsan仓库提供的代码来看的,Embeddings 和 Label Embed: 是文本数据的词向量和标签的词向量,将文本数据的词向量w1,w2,w3…,wn,经过线性变换,然后通过BiLSTM,用于捕捉单词之间的关系,生成隐藏状态,即表示整个句子的嵌入矩阵 H。自注意力机制和标签注意力机制: 通过对隐藏状态应用两个线性层和激活函数(tanh),然后进行 softmax 操作,构建了自注意力机制和标签注意力机制。这两个机制生成了与文本内容和标签相关的注意力分布。这样,每个词都会有两个来源的信息,即来自句子内部上下文的自注意力信息和来自标签的有针对性的标签注意力信息。通过这种加权融合的方式,将两个信息源融合成一个综合的表示,用于最后的模型预测。然后对生成的每个条款做出相应的判断,作者这里使用ALBERT进行二值分类,最后输出责任项,这里的Y/N,个人觉得是用于描述许可证条款的严格性。也就是说,责任值Y表示对某个特定条款是需要严格遵守,而N表示更为宽松的遵守标准。之后便构建了包含“许可证条款责任”的许可证知识库。

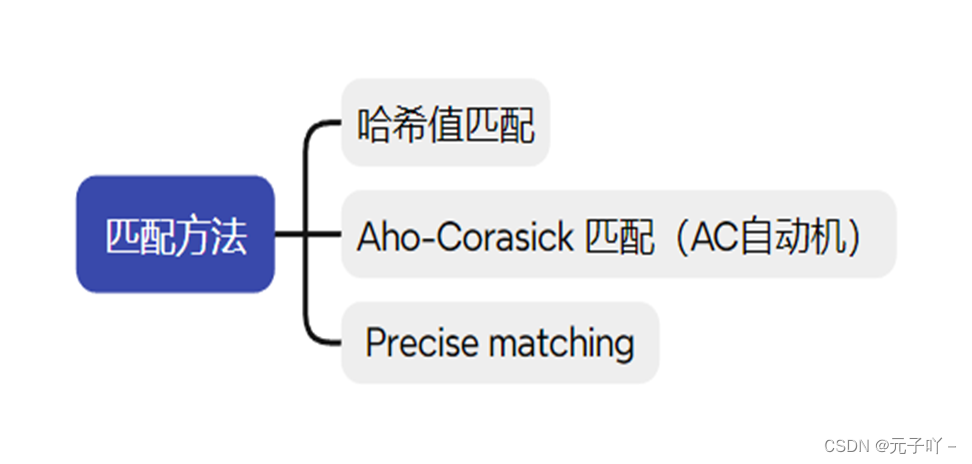
 对于许可证嗅探器,主要由四个部分组成,通过对查询对象切分,将包含许可证的文本转化为具有潜在模式的数字序列,下一步进入到潜在许可证的检测,这里涉及到了下边所列的三种匹配方法,第一种方法是哈希值匹配,通过两个文本之间的哈希值来计算相似度,但是我们都知道通过哈希值计算两个文本之间的相似度本身会存在哈希冲突的问题:不同的文本可能具有相同的哈希值,其次是哈希函数对于处理变化长度的文本相似度不够灵活(这主要是虽然不同项目中使用相同的许可证,许可证的文本可能根据具体的项目和使用情况进行微调或修改),准确性不是很高。第二种方法是AC自动机方法,接下来对该算法进行介绍。
对于许可证嗅探器,主要由四个部分组成,通过对查询对象切分,将包含许可证的文本转化为具有潜在模式的数字序列,下一步进入到潜在许可证的检测,这里涉及到了下边所列的三种匹配方法,第一种方法是哈希值匹配,通过两个文本之间的哈希值来计算相似度,但是我们都知道通过哈希值计算两个文本之间的相似度本身会存在哈希冲突的问题:不同的文本可能具有相同的哈希值,其次是哈希函数对于处理变化长度的文本相似度不够灵活(这主要是虽然不同项目中使用相同的许可证,许可证的文本可能根据具体的项目和使用情况进行微调或修改),准确性不是很高。第二种方法是AC自动机方法,接下来对该算法进行介绍。
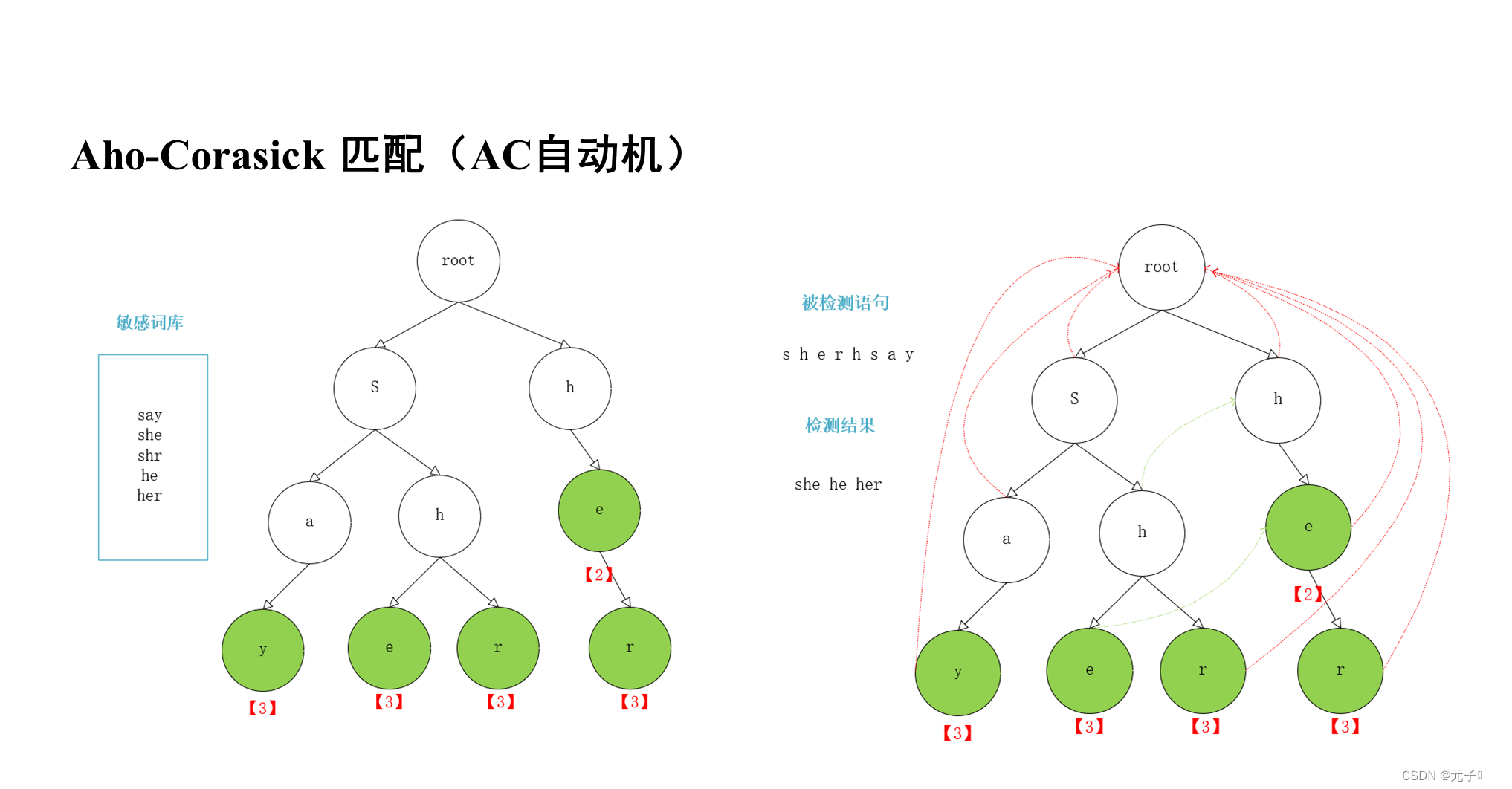
AC自动机算法主要实现的功能是将所有预定义的模式创建确定性有限自动机,也就是将预定义的许可证规则事先存放好,通过只扫描一次语句,就找出所有出现在这段文本中所包含的预定义模式中的许可证规则。这个过程中涉及到两大步骤,首先是Trie树的构建,第二个是Fail指针的构建。
关于具体算法思路的介绍,我们可以参考作者:LDLD是程序猿,所发布的视频:https://www.bilibili.com/video/BV1Ag41117YU/?spm_id_from=333.337.search-card.all.click&vd_source=cfcf36bdc0f04fcf31bb5ffddf34985a
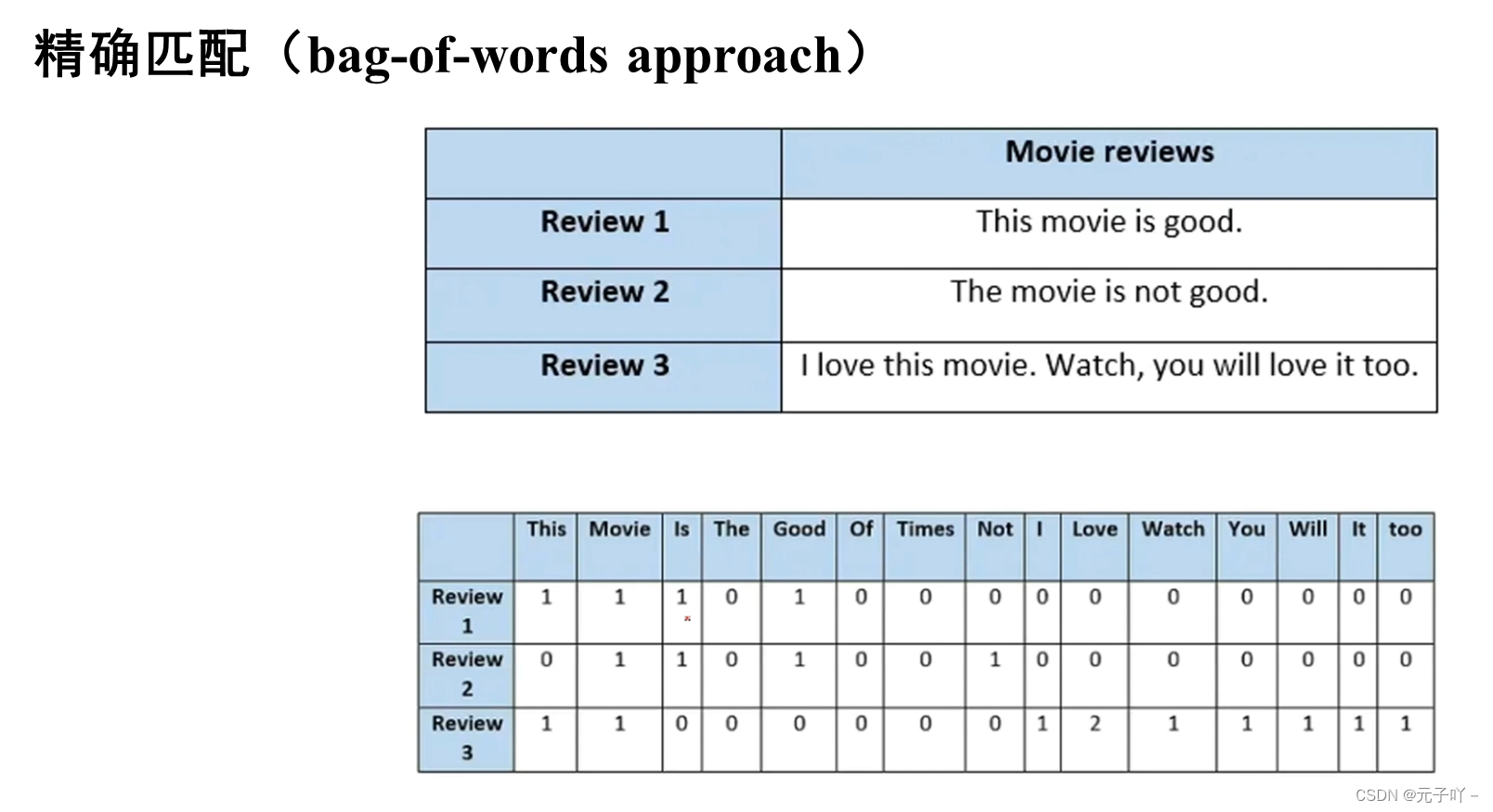
下来说下第三种匹配精确匹配,首先该方法被分为了两个阶段,第一个阶段使用的是词袋模型,比如这里是三条评论,把所有的数据都放进去,然后把所有的单词组合起来构成一个字典,针对每条评论根据这个字典进行索引,把每条评论转换成相应的数据向量的形式,数值代表的是出现的次数,那之后系统通过比较它们之间的共同元素比例等方法进行排序。之后为了评估该匹配结果的质量,使用相似性和包含关系一起排序,从而确定最优匹配结果。(这个例子,是参考网上所给出的,具体链接还在搜寻中…)
介绍完三种匹配算法之后,我们得到针对每个文本通过每一种匹配算法分别确定了最佳的许可证匹配,进入第二阶段,考虑到在进行许可证匹配的过程中,可能会有一些文本描述或规定在整个文本中,但实际上并不属于真实的许可证信息。比如,文本的开头可能包含了一些通用的描述,如“禁止软件商用”,但这并没有提供详细的、具体的商业使用权利的信息,也不属于真实的许可证规定。这些描述被视为“负面规则”(negative rules),因为它们描述了一些限制,但并没有提供完整的许可证信息。在匹配过程中,系统会将与这些“负面规则”完全匹配的部分排除,以确保最终的匹配结果更准确地涵盖真实的许可证规定。第三步,因为每种算法可能对相同的文本匹配到不同的许可证,最后根据 similarity、inclusion 和 overlap 这三个指标,从每个文本所匹配的许可证中选择最匹配的许可证。最后输出每个文本的最佳许可证。
针对该项目的每个文本确定好它们的许可证之后,之后通过递归扫描、组织关系来展示项目的目录结构,并表示每个文件采用的许可证信息,可以直观地查看每个许可证在软件中的分布,从而更好检测它们的冲突关系。
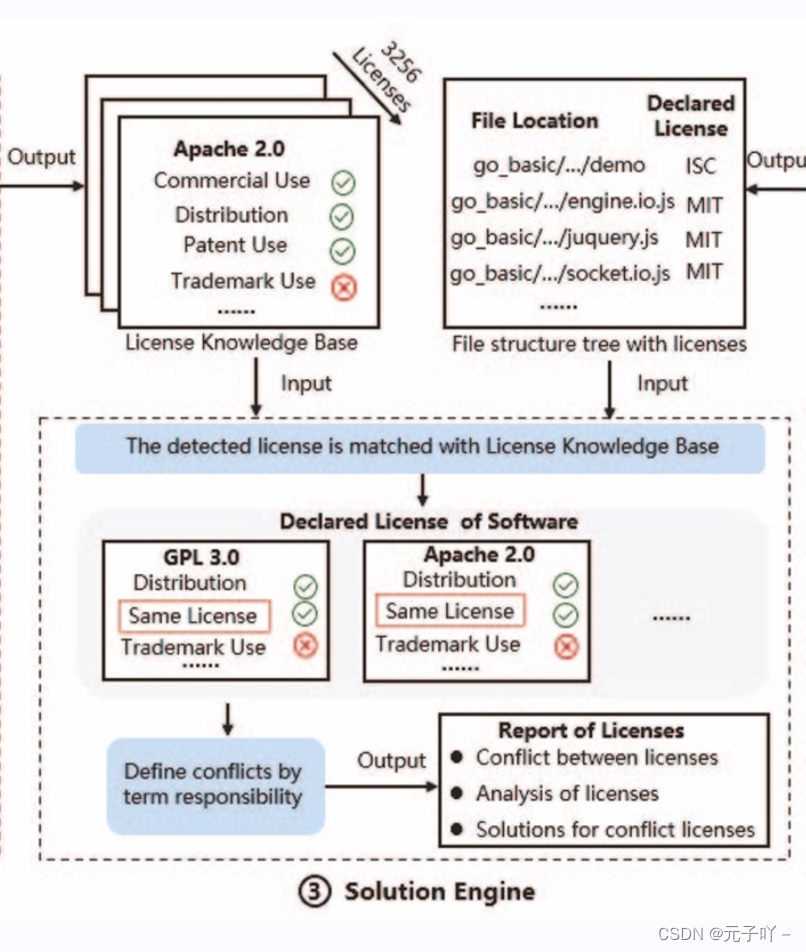
结合第一阶段的许可证分析器识别出的许可证知识库,第二阶段许可证嗅探器中得到的整个软件的许可证分布情况,进行许可证冲突检测。首先对该软件项目中涉及到的许可证的条款进行比对,如果两个不同的许可证中存在相同的术语,其中一个许可证对该术语的规定是 “Y”,而另一个许可证对该术语的规定是 “N”,那么这种情况被视为可能存在冲突。这时候需要考虑许可文件在许可结构树中的位置进行进一步的判断。在许可结构树中越靠近叶子节点越严格,如果说可能冲突的这两个许可证不在一个层级关系,那就不存在冲突。还有就是项目中明确指定的主要许可证,或者项目声明中提到的特定许可证。如果某个术语在项目声明的许可中被允许,那么即使在其他许可证中存在不同的规定,也不会被视为冲突。这种情况下,项目声明的许可具有更高的优先级,规定更具有约束力。通过这样的约束条件,检测出了软件项目中的许可冲突问题。然后并提出了两种解决冲突许可证的方法:代码替换和许可证替换。对于许可证替换,首先评估冲突许可证的组合,并创建一个包含所有严格必需条款的列表。然后,在许可证知识库中搜索一个包含这些条款集并具有严格责任的许可证,以替换冲突许可证的组合。
举个例子,比如说许可证A规定为:“作者对于因使用软件而产生的任何损害概不负责。”许可证 B 的责任规定为:“作者对于因使用软件而引起的任何直接或间接损害,包括但不限于数据丢失、利润损失等,概不负责。”许可证 B 的责任规定更为严格。然后找出冲突许可证之间较为严格的条款构建一个列表,并找出一个能够兼容所有这些严格条款的许可证作为替代许可证。对于代码替换,如果代码是关键的,开发人员应根据其功能重新组织它或用具有相同功能但没有许可证冲突的代码替换它。如果代码非关键且不影响软件功能,可以考虑删除。
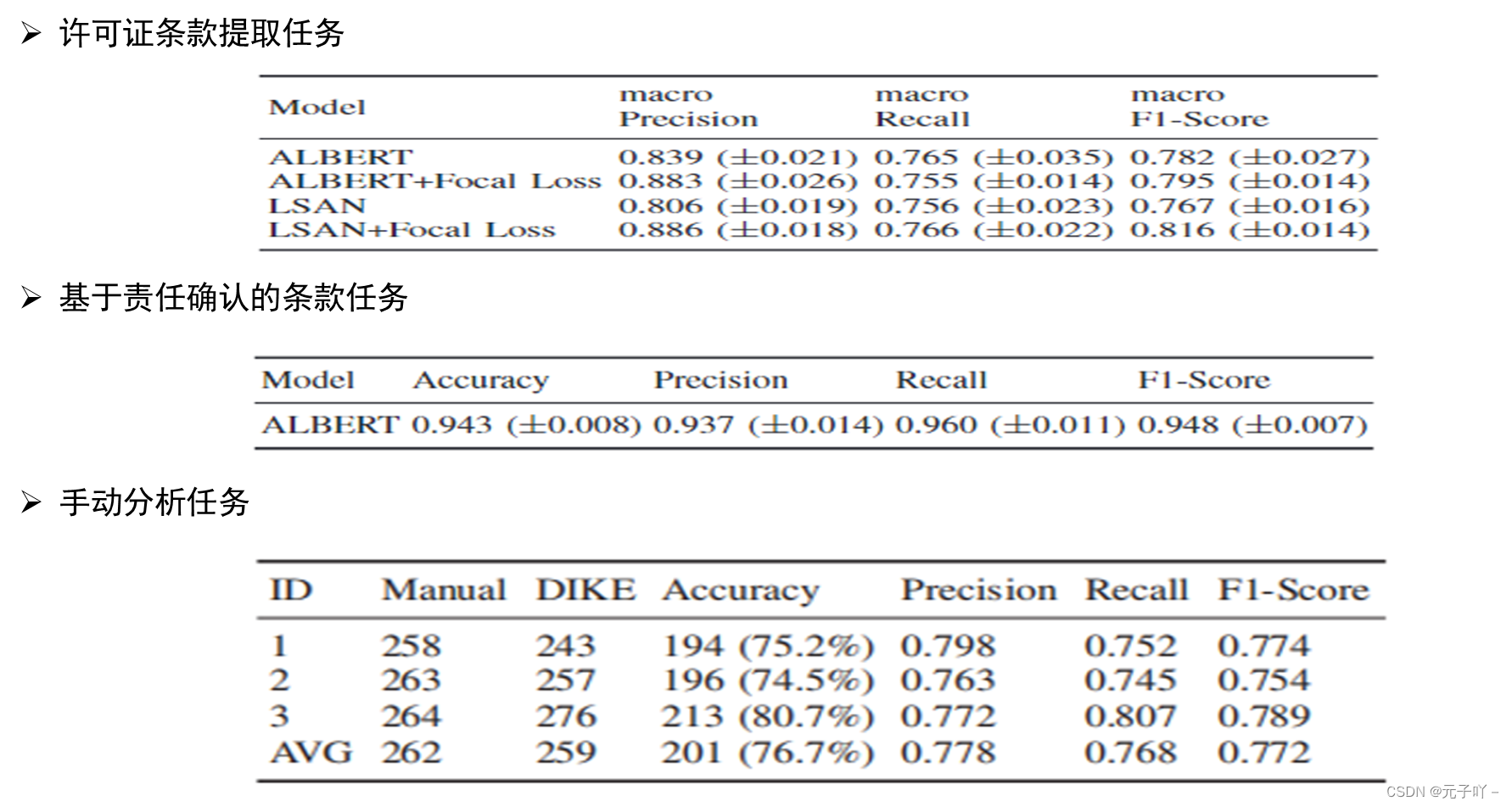
关于评估部分,就简单来说下,对于论文所提的DIKE框架的效果,本文通过三个任务进行验证,一是基于许可证条款提取任务,DIKE现在拥有3256个开源许可证数据集上获得0.886的F1值,二是基于责任确认的条款任务,DIKE设计的二元分类模型获得了0.948的fl值。三是手动分析任务:在三组随机对照试验中,许可分析器分析了知识库中的50个许可证,三位作者手动标注了相关条款及其对应责任,同时交叉验证了这些结果。然后,将手动分析结果与许可分析器的处理结果进行了比较。在三次试验中,手动分析的平均术语数为262,许可分析器分析的平均术语数为259。许可分析器准确分析的平均术语数为201,准确率为76.7%,F1分数为0.772。
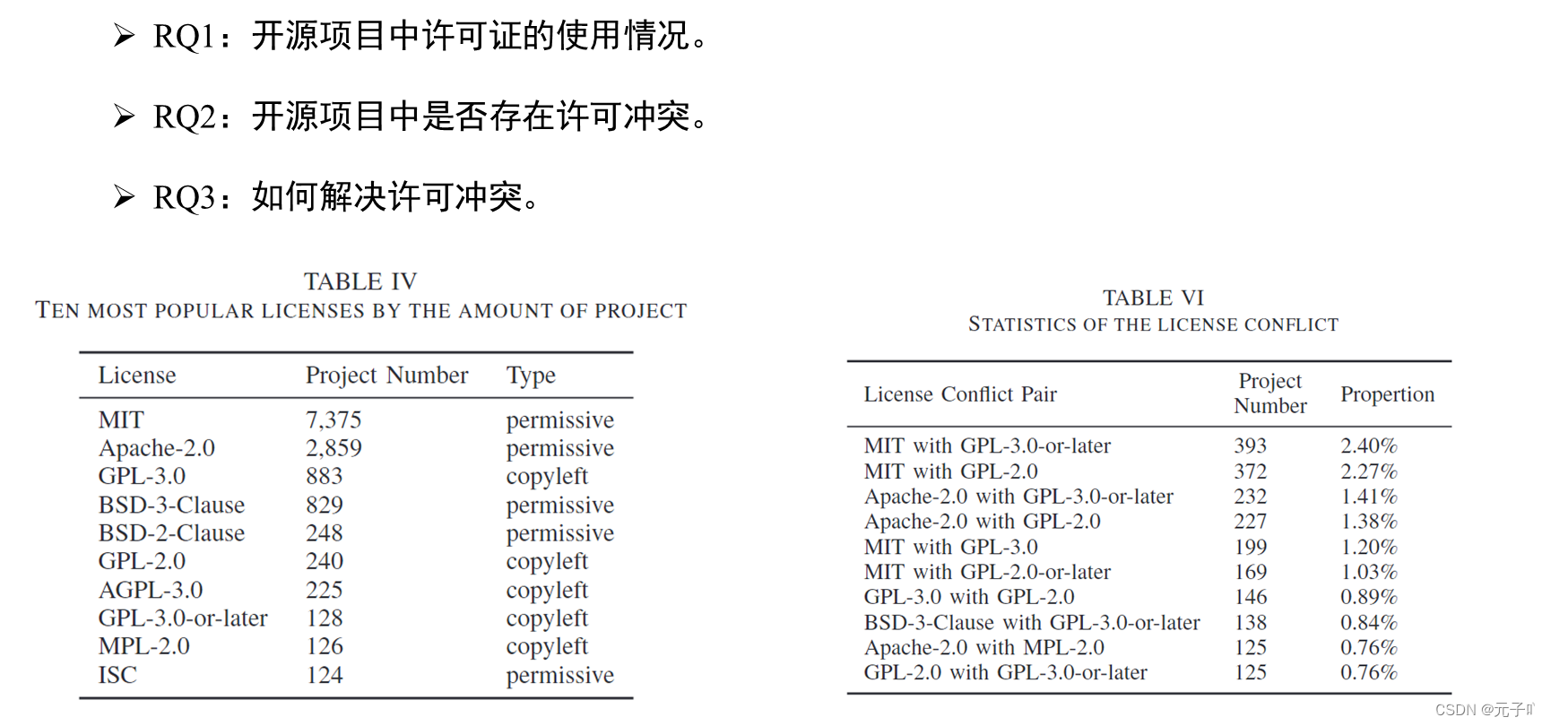
下来说下研究结果,针对研究问题一,针对许可证的使用情况,作者在 GitHub 上收集了超过 1,000 颗恒星的 16,341 个 FOSS 项目。关于许可证的使用情况:84.4%的项目使用许可证,并得到左边所示的图,可以看到不同许可证的使用情况。针对问题二,在开源项目中是否存在许可证冲突?利用DIKE基于RQ1收集的数据来检测许可冲突。结果表明,4448个项目包含冲突,这超过了观察到的总数的四分之一(27.2%),从上图可以看出许可证冲突主要发生在MIT、Apache-2.0和GPL家族之间。主要是因为GPL具有强传染性,同时这也意味着使用GPL的项目更容易导致许可证冲突。针对问题三如何解决冲突问题在之前已经说明。

这里来说下个人的思考。
作者的核心贡献:主要来说两点,其实在2019年作者的团队就已经提出lsan这个算法,然后之后并将基于该算法提出了一种自动且有效的工具DIKE,用于识别许可证条款及其责任,并构建了拥有3256种独特许可证的许可证知识库。这个意义还是蛮大的,从提出到落地。作者不仅仅是在识别许可证这一冲突问题,为此还提出了解决方案,对于这些实际存在许可冲突的项目,作者在github上发起了issue,帮助作者能够及时识别该问题并解决,从而避免随着项目不断庞大,带来的后果愈发严重的问题。
关于未来目标的话,作者提到,因为现有的许可证知识库还是静态的,希望未来能够持续不断地更新许可证知识库的内容。
在读论文的过程中,注意到了一些问题,以下是一些建议:
关于论文的普适性,有两点需要考虑:
论文使用了12种常见许可证条款进行分类检测冲突,但这些条款可能无法覆盖所有可能的冲突情况。在实际应用中,许可证冲突可能涉及更多的条款和复杂的组合。建议进行进一步的研究和扩展,以包含更多许可证条款和冲突情况,从而提高分类检测的全面性。
有些许可证会存在可兼容的特殊条款的情况,使得原本不兼容的许可证能够与其他许可证合并。这种情况在实际中占有相当大的比例。因此,仅通过条款的冲突来确定项目的许可证冲突可能缺乏普适性。建议在研究中考虑这一点,并寻求更全面的方法来判断许可证冲突。
以上就是这篇论文的分享,谢谢观看!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









