







MyCat基于一主一从实现读写分离
前期准备
建库语句
CREATE DATABASE mydb1;
建表语句
CREATE TABLE mytbl(id INT,NAME VARCHAR(50));
#插入数据
INSERT INTO mytbl VALUES(1,"zhang3");
上面的建库建表语句是在主机中执行的。所以后面启动mycat之后,通过配置数据源是可以获取到,主机从机的数据库数据表的,如果启动mycat之后,在创建库或者表,mycat不会读取到新创建的库表,需要重启mycat,但是我们一般不会这么做。因为我们使用mycat中间件就是在程序和MySQL中间加了一层mycat。所有的数据操作都会通过mycat,通过mycat解析之后再连接对应的数据库。
连接mycat创建逻辑库
create database mydb1;
这个名称不需要和物理库完全一致,后面还需要配置关联关系
逻辑库创建完成之后会在/lx/mycat/conf/schemas 目录下生成对应的配置文件
配置文件名称规则 逻辑库.schema.json

逻辑库配置
修改mydb1.schema.json
vim /lx/mycat/conf/schemas/mydb1.schema.json
指定数据源集群 “targetName”: “prototype”,配置主机数据源
{
"customTables":{},
"globalTables":{},
"normalProcedures":{},
"normalTables":{},
"schemaName":"mydb1",
"targetName":"prototype",
"shardingTables":{},
"views":{}
}
targetName的值是自定义的 只需要和后面的集群信息中的数据源名称保持一致即可
添加数据源 (读写分离嘛)
配置哪些是读数据源,哪些是写数据源
使用注解方式添加数据源
登录Mycat,注解方式添加数据源,指向从机 rwSepw 主机
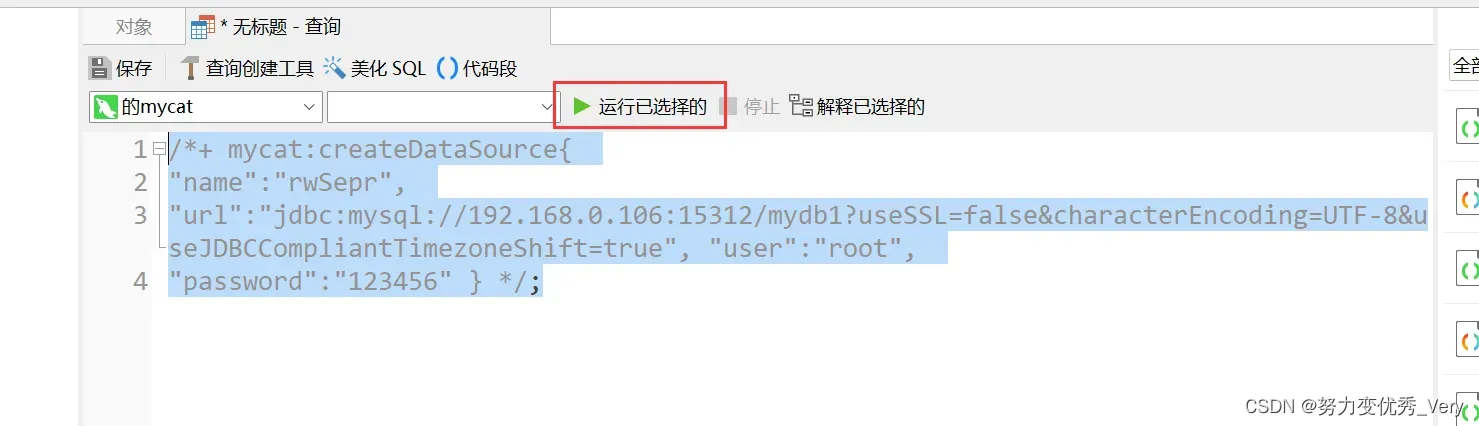
配置rwSepw写数据源
/*+ mycat:createDataSource{
"name":"rwSepw",
"url":"jdbc:mysql://192.168.0.106:15311/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true",
"user":"root",
"password":"123456"
} */
配置rwSepr读数据源
/*+ mycat:createDataSource{
"name":"rwSepr",
"url":"jdbc:mysql://192.168.0.106:15312/mydb1?useSSL=false&characterEncoding=UTF-8&useJDBCCompliantTimezoneShift=true", "user":"root",
"password":"123456" } */;
数据源配置好之后,会/lx/mycat/conf/datasources生成对应的配置文件
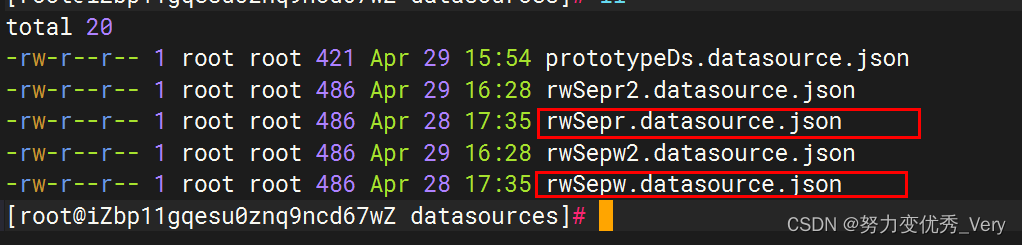
数据源配置内容如下
{
"dbType":"mysql",
"idleTimeout":60000,
"initSqls":[],
"initSqlsGetConnection":true,
"instanceType":"READ_WRITE",
"maxCon":1000,
"maxConnectTimeout":30000,
"maxRetryCount":5,
"minCon":1,
"name":"rwSepr",
"password":"123456",
"queryTimeout":0,
"type":"JDBC",
"url":"jdbc:mysql://192.168.0.106:15312/mydb1?useJDBCCompliantTimezoneShift=true&useUnicode=true&serverTimezone=Asia/Shanghai&characterEncoding=UTF-8&autoReconnect=true&useSSL=false",
"user":"root",
"weight":0
}
也可以连接mycat使用sql语句查询配置的数据库
/*+ mycat:showDataSources{} */;
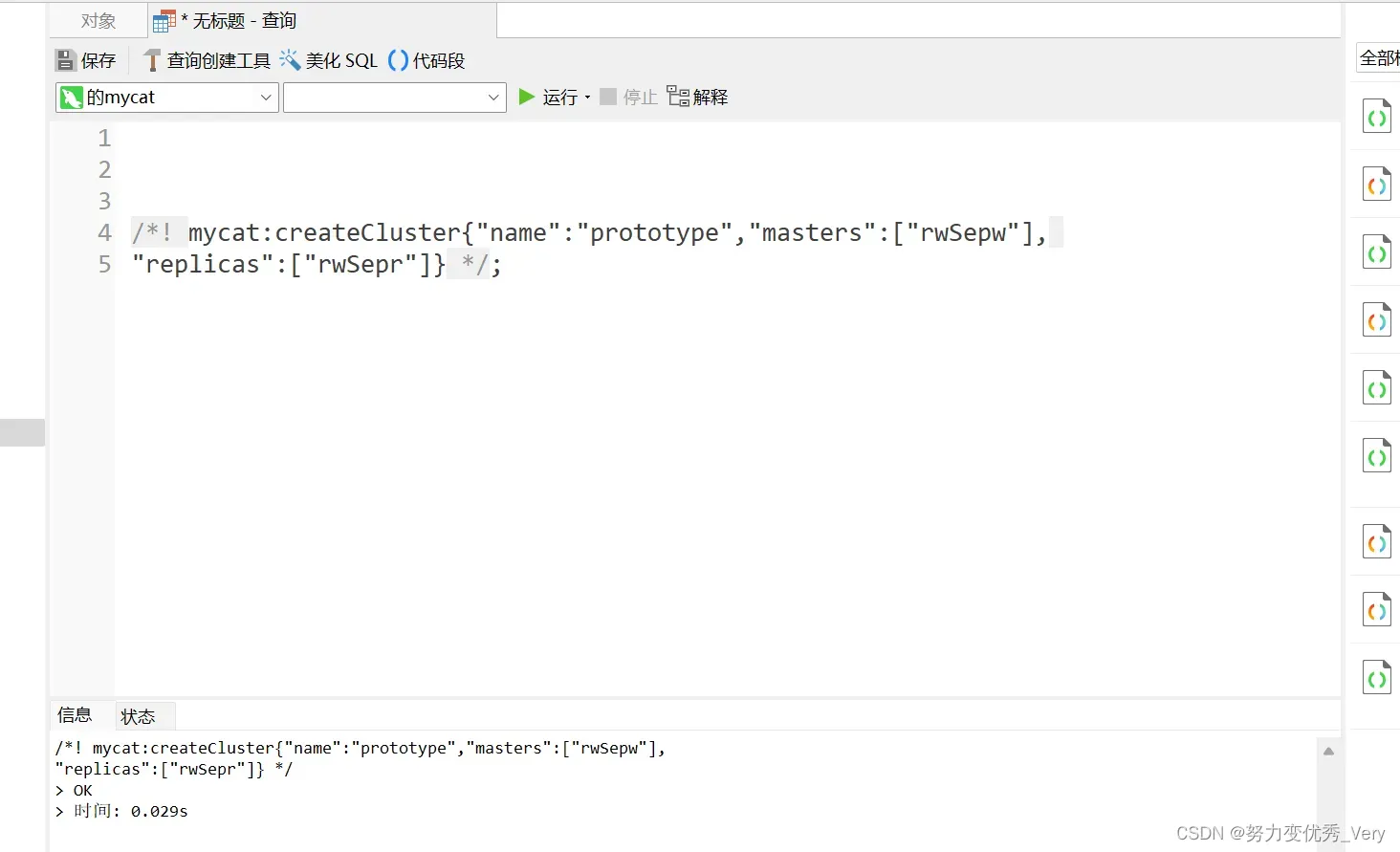
更新集群信息,添加主rwSepw 从rwSepr 节点.实现读写分离
/*! mycat:createCluster{
"name":"prototype",
"masters":["rwSepw"],
"replicas":["rwSepr"]} */;
- name 定义了集群的名称为prototype。这个名称用于在其他配置或规则中引用此集群。 其中的targetName的值 “prototype” 就是配置的mydb1.schema.json中的targetName值保持一致。因为配置读写分离嘛,得创建一个数据源集群,这些集群中,其中就包括了读的数据源、写的数据源。
- masters 指定了主服务器(Master)列表。在这个例子中,集群有一个主服务器,其标识名为rwSepw。主服务器通常是处理写操作的节点。
- replicas 指定了副本服务器 列表。这里也只有一个副本服务器,标识名为rwSepr。副本服务器通常用于读操作,实现读写分离,提高系统的读取能力及可用性。
也可以连接mycat使用sql语句查询配置的集群信息
/*+ mycat:showClusters{} */;
集群信息配置好之后,会/lx/mycat/conf/clusters生成对应的配置文件prototype.cluster.json

查看配置文件
cat prototype.cluster.json
内容如下
{
"clusterType":"MASTER_SLAVE",
"heartbeat":{
"heartbeatTimeout":1000,
"maxRetryCount":3,
"minSwitchTimeInterval":300,
"showLog":false,
"slaveThreshold":0.0
},
"masters":[
"rwSepw"
],
"maxCon":2000,
"name":"prototype",
"readBalanceType":"BALANCE_ALL",
"replicas":[
"rwSepr"
],
"switchType":"SWITCH"
}
readBalanceType 查询负载均衡策略
可选值:
BALANCE_ALL(默认值):获取集群中所有数据源
BALANCE_ALL_READ:获取集群中允许读的数据源
BALANCE_READ_WRITE :获取集群中允许读写的数据源,但允许读的数据源优先
BALANCE_NONE:获取集群中允许写数据源,即主节点中选择
switchType
NOT_SWITCH:不进行主从切换
SWITCH:进行主从切换
重启mycqt完成读写分离
/lx/mycat/bin目录下执行
./mycat restart
验证读写分离
在主机数据库下执行以下sql语句
INSERT INTO mytbl VALUES(2,@@hostname);
查看主机和从机的值
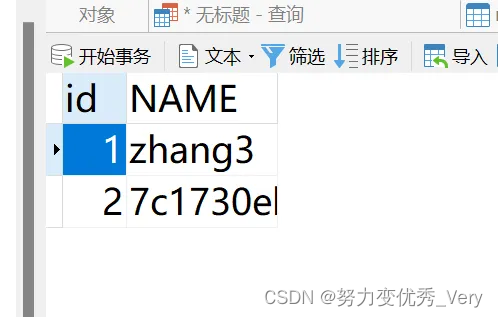
从机
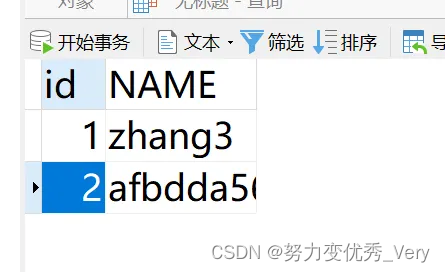
登录mycat验证读写分离成功
多运行几次 SELECT * FROM mytbl
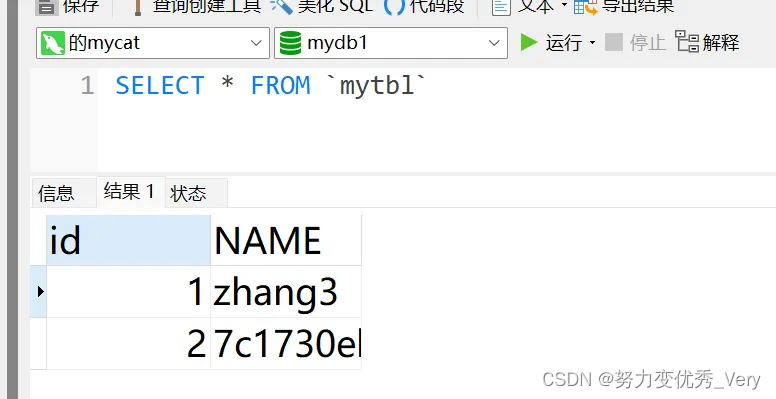
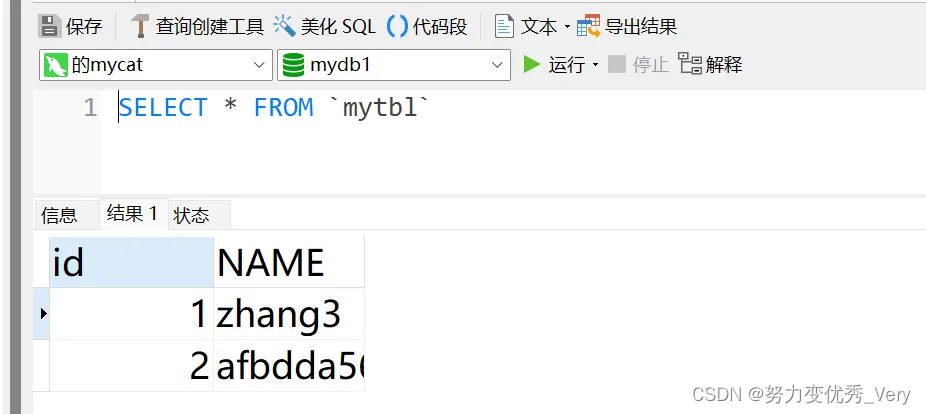
值不一样说明搭建成功
可关注公众号 佳哇程序员
或直接扫码关注
















 2864
2864

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









