







实验5:字符串的应用
- 1. 字符串推导式
- 1.1 ['apple', 'orange', 'pear'] -> ['A', 'O', 'P'] # 第一个字母大写
- 1.2 ['apple', 'orange', 'pear'] -> ['apple', 'pear'] # 是否包含字母’p’
- 1.3 ["TA_parth", "student_poohbear", "TA_michael", "TA_guido", "student_ htiek"] -> ["parth", "michael", "guido"] #是否以 TA_开头
- 1.4 ['apple', 'orange', 'pear'] -> [('apple', 5), ('orange', 6), ('pear', 4)] #生成列表
- 1.5 ['apple', 'orange', 'pear'] -> {'apple': 5, 'orange': 6, 'pear': 4} #生成字典
- 2. 特殊单词
- 3. Caesar加密
- 4. 杨辉三角
- 5. 可读性等级
- 实验结论:
1. 字符串推导式
我们之前学过列表推导式。例如,生成前 4 个奇数,我们可以写
[2 * num - 1 for num in range(1,5)] #生成[1, 3, 5, 7]
仿照上面写法,使用推导式完成以下字符串操作:
1.1 [‘apple’, ‘orange’, ‘pear’] -> [‘A’, ‘O’, ‘P’] # 第一个字母大写
分析:
通过库函数str.upper()获得对应字母的大写字母,再利用下标访问构建列表推导式
编程实现:
# Question1
myList = ['apple', 'orange', 'pear']
res = [str.upper()[0] for str in myList]
print(res)
运行并测试:

1.2 [‘apple’, ‘orange’, ‘pear’] -> [‘apple’, ‘pear’] # 是否包含字母’p’
分析:
通过if及库函数str.find()拼接列表推导式
编程实现:
# Question2
myList = ['apple', 'orange', 'pear']
res = [str for str in myList if str.find('p') != -1]
print(res)
运行并测试:

1.3 [“TA_parth”, “student_poohbear”, “TA_michael”, “TA_guido”, “student_ htiek”] -> [“parth”, “michael”, “guido”] #是否以 TA_开头
分析:
通过if与库函数str.startwith()对“TA_”开头的字符串进行筛选。再利用字符串切片切除前三个字符。
编程实现:
# Question3
myList = ["TA_parth", "student_poohbear",
"TA_michael", "TA_guido", "student_htiek"]
res = [str[3:] for str in myList if str.startswith("TA_")]
print(res)
运行并测试:

1.4 [‘apple’, ‘orange’, ‘pear’] -> [(‘apple’, 5), (‘orange’, 6), (‘pear’, 4)] #生成列表
分析:
利用库函数len()获取长度拼接成元组,进而构建成列表
编程实现:
# Question4
myList = ['apple', 'orange', 'pear']
res = [(str, len(str)) for str in myList]
print(res)
运行并测试:

1.5 [‘apple’, ‘orange’, ‘pear’] -> {‘apple’: 5, ‘orange’: 6, ‘pear’: 4} #生成字典
分析:
利用库函数len()获取长度构建字典
编程实现:
# Question5
myList = ['apple', 'orange', 'pear']
res = {str: len(str) for str in myList}
print(res)
运行并测试:

2. 特殊单词
有一种特殊的英文单词,它的相邻字母对之间的“距离”不断增加。如单词subway,它的相邻字母对分别为 (s, u), (u, b), (b, w), (w, a), (a, y), 字母之间的距离依次为 2,19,21,22,24(如 a 是第 1 个字母,y 是第 25 个字母,a 和 y 的距离为 24)。编写函数 is_special_word(word),word 为输入单词字符串, 如为特殊单词,返回 True;否则返回 False。
分析:
设置标志变量对前两个字符的差进行保存,并通过下标遍历整个字符串,获取ASCII码之后进行做差并取绝对值,与标志变量进行比较,如果大于标志变量则进行下一次判断,否则直接返回FALSE。当遍历完整个字符串后返回TRUE。
编程实现:
# 定义函数
def is_special_word(word):
# 设置标志变量用来存邻近字符距离
flag = 0
# 遍历每个字符
for i in range(len(word)-1):
# 获得当前两个字符的距离
temp = abs(ord(word[i+1])-ord(word[i]))
if temp > flag:
flag = temp
continue
else:
return False
return True
# 获得输入并判断
str = input("Please input a word: ")
if is_special_word(str):
print(str+"is a special word")
else:
print(str+"is not a special word")
运行并测试:
①运行并测试一组特殊单词:

②运行并测试一组非特殊单词:
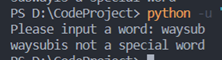
3. Caesar加密
Caesar 加密将文本中每个字符向前移动三个字母,即
A->D,B->E,…,X->A,Y->B,Z->C
如单词 PYTHON,将加密为 SBWKRQ。
编写加密函数encrypt_caesar(plaintext)和 decrypt_caesar (ciphertext),每个函数都接受一个参数,表示将要加密或解密的字符串,然后返回加密或解密之后的字符串。
注:(1)只考虑大写字母;(2)非字母字符不需要通过加密或解密来修改。如encrypt_caesar(“F1RST P0ST”)应该返回“I1UVW S0VW”;(3)encrypt_caesar(“”)应返回“”,即空字符串。
分析:
需要对待加密与待解密字符串以字符进行处理,首先获取当前待处理的字符的ASCII,并进行判断,如果不在‘A’的ASCII和‘Z’的ASCII之间则直接存入结果字符串中。如果在‘A’的ASCII和‘Z’的ASCII之间则进行下一步处理,通过将当前字符的ASCII码与‘A’的ASCII码做差获取偏移值,若为加密操作则偏移值加三(若为解密则减三)最后将偏移值对26取余后(防止偏移越界)加上‘A’的ASCII码并转回字符即可。
编程实现:
# 定义加密函数
def encrypt_caesar(plaintext):
# 定义结果字符串
res = ''
# 遍历整个字符串
for x in plaintext:
# 如果当前字符在A~Z中,则获取ASCII进行加密,要注意越界的情况
if ord(x) >= ord('A') and ord(x) <= ord('Z'):
res = res+chr(ord('A')+(ord(x)-ord('A')+3) % 26)
else:
res = res+x
return res
# 定义解密函数
def decrypt_caesar(ciphertext):
# 定义结果字符串
res = ''
# 遍历整个字符串
for x in ciphertext:
# 如果当前字符在A~Z中,则获取ASCII进行解密,要注意越界的情况
if ord(x) >= ord('A') and ord(x) <= ord('Z'):
res = res+chr(ord('A')+(ord(x)-ord('A')-3) % 26)
else:
res = res+x
return res
str = input("Please input a string to encrypt: ")
print(encrypt_caesar(str))
str = input("Please input a string to decrypt: ")
print(decrypt_caesar(str))
运行并测试:
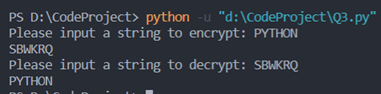
①测试一般情况下的加密与解密:
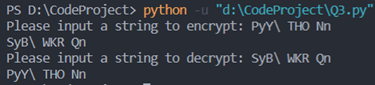
②测试含有非法字符的加密与解密:
4. 杨辉三角
编写函数 print_yanghui_triangle(N),输出杨辉三角的前 N 行,要求使用 format 函数进行格式化输出。
例子:print_yanghui_triangle(10),输出

分析:
①三角计算:
通过建立二维列表保存三角的值。首先全赋为1,然后从第二行开始,对非1值从上到下从左到右依次进行遍历计算,并将结果存在二维列表中。
②格式化输出:
通过三角的大小计算出输出的宽度和高度。通过for循环遍历每一行,再对每一行进行格式化输出。
编程实现:
# 定义打印杨辉三角的函数
def print_yanghui_triangle(num):
# 定义二维列表以生成与保存杨辉三角
triangle = [[1]]
# 首先将三角全定义为1
for i in range(2, num+1):
triangle.append([1]*i)
# 通过循环循环每一个中间层对非1值进行修改
for j in range(1, i-1):
triangle[i-1][j] = triangle[i-2][j]+triangle[i-2][j-1]
# 计算输出的宽度
width = len(str(triangle[-1][len(triangle[-1])//2]))+3
# 计算输出的高度
column = len(triangle[-1])*width
# 遍历每一行进行输出
for sublist in triangle:
result = []
# 对于一行中的每一元素进行输出
for contents in sublist:
result.append('{0:^{1}}'.format(str(contents), width))
# 利用format进行格式化输出
print('{0:^{1}}'.format(''.join(result), column))
# 进行测试
if __name__ == '__main__':
num = int(input('Please input a number:'))
print_yanghui_triangle(num)
首先设置一空二维列表用于存生成的三角。首先将三角全初始化为1。再从第二行开始,从上到下从左到右对非1值进行求解,并将结果存入二维列表中。
输出时首先计算出输出的宽度与高度。再遍历每一行对结果进行输出,对于每一行的元素采用format进行格式化输出的处理将三角形对齐。
运行并测试:
①当num=5时测试输出:
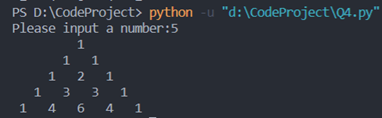
②当num=10时测试输出:

5. 可读性等级
不同书的阅读群体不一样。例如,一本书中可能有许多很长的复杂单词;而较长的单词可能与较高的阅读水平有关。同样,较长的句子也可能与较高的阅读水平相关。研究者开发了许多可读性测试,给出了计算文本阅读水平的公式化过程。其中一个可读性测试是 Coleman Liau 指标:文本的 Coleman Liau 指标旨在划分理解文本所需的阅读水平等级。Coleman Liau 指标公式如下:
i
n
d
e
x
=
0.0588
∗
L
−
0.296
∗
S
−
15.8
index = 0.0588 * L - 0.296 * S - 15.8
index=0.0588∗L−0.296∗S−15.8
其中,L 是文本中每 100 个单词的平均字母数,S 是文本中每 100 个单词的平均句子数。
考虑以下文本:
Congratulations! Today is your day. You’re off to Great Places! You’re off and away!
该文本有 65 个字母,4 个句子,14 个单词。文本中每 100 个单词的平均字母数是L=65/14100=464.29;文本中每 100 个单词的平均句子数是 S=4/14100=28.57。代入 Coleman Liau 指标公式,并向最近的整数取整,我们得到可读性指数为 3 级。
我们将编写一个函数 readability,输入参数为字符串,返回可读性等级。
实现要求:
(1)若计算结果小于 1,输出“Before Grade 1”;
(2)若计算结果大于或等于 16,输出“Grade 16+”;
(3)除(1)和(2)外,输出“Grade X”,X 为相应等级。
(4)字母包括大写字母和小写字母(不考虑数字和标点符号);
(5)以空格分隔作为标准区分单词,如;
It was a bright cold day in April, and the clocks were striking thirteen. Winston Smith, his chin nuzzled into his breast in an effort to escape the vile wind, slipped quickly through the glass doors of Victory Mansions, though not quickly enough to prevent a swirl of gritty dust from entering along with him. (55 words)
(6)句号(.)、感叹号(!)或问号(?)表示句子的结尾。如:
Mr. and Mrs. Dursley, of number four Privet Drive, were proud to say that they were perfectly normal, thank you very much. ( 3 sentences)
(7)可读性等级的参考例子见readability.txt。
分析:
①函数部分:
定义计算可读性的函数。首先利用库函数对连续空格进行去除,只保留一个空格,以防输入数据中多个连续空格造成单词统计错误。再利用str.find对空格计数并加一获得单词数。通过查找‘.’,‘!’和‘?’对句子数进行计数。通过遍历整个字符串对字母进行判断计数。都计数完成后即利用公式对可读性进行计算并取整返回。
②主函数部分:
主函数中判断函数返回值并分情况进行输出,如果小于一则输出"Before Grade 1",如果大于等于16则输出"Grade 16+",其余情况则正常输出即可。
编程实现:
# 定义可读性检测函数
def readability(str):
# 去除连续空格对单词计数的影响
str = ' '.join(str.split())
# 单词计数
numOfWord = str.count(' ')+1
# 句子计数
numOfSentence = str.count('.')+str.count('?')+str.count('!')
# 通过遍历进行字母计数
numOfLetter = 0
for x in str:
if (x >= 'A' and x <= 'Z') or (x >= 'a' and x <= 'z'):
numOfLetter += 1
# 代入公式进行计算
index = 0.0588 * numOfLetter/numOfWord*100 - 0.296*numOfSentence/numOfWord*100-15.8
# 返回取整值
return round(index)
# 获取输入
str1 = input("Please input sentences:")
res = readability(str1)
# 进行判断并输出结果
if res < 1:
print("Before Grade 1")
elif res >= 16:
print("Grade 16+")
else:
print("Grade "+str(res))
运行并测试:
①可读性小于1时:

②可读性大于16时:

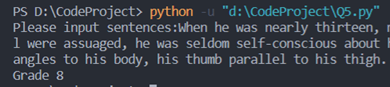
③可读性大于1小于16时:
实验结论:
通过本次实验,我学会了字符串的基本操作。学会了字符串如何进行遍历以及查找等操作。也学会了借助字符串进行构建列表推导式,通过ASCII码对字符进行加密等操作。也学会了通过格式化输出对杨辉三角进行生成与输出。这些都为我以后Python的使用中打下了坚实基础。
本次实验中的代码均有很详细的注释,体现了程序的设计思路。
此外,在本次实验中,我也遇到了一些问题。当通过ASCII码进行便宜时需要注意越界的情况,如果不对26取余,有可能发生越界导致程序错误。这告诉我在以后的编程中需要注意细节去避免程序错误。
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











