






Python循环优化技巧
python开发中,循环代码很常见且不可避免,如何提高循环代码的质量,对我们开发有很大的帮助。
编写循环时,遵守下面三个原则可以大大提高运行效率,避免不必要的低效计算:
1.尽量使用局部变量代替全局变量。局部变量查询较快,便于维护,有利于提高性能并节省内存。
2.尽量减少循环内部不必要的计算
3…嵌套循环中,尽量减少内层循环的计算,尽可能把计算向外提
下面我们用代码测试下减少内部循环计算,能够提升多少性能
示例代码:
# -*- coding: utf-8 -*-
import datetime
start_time = datetime.datetime.now()
for i in range(10000):
result_list = []
for j in range(10000):
result_list.append(i * 100 + j * 100)
end_time = datetime.datetime.now()
print u'计算耗时:{0}'.format((end_time - start_time).microseconds)
实际运行耗时97500微秒:
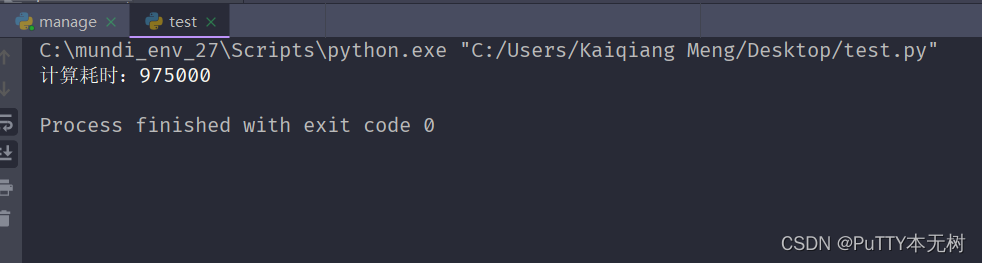 优化之前运行程序耗时
优化之前运行程序耗时
接下来我们稍微改一下代码,减少内部循环计算
# -*- coding: utf-8 -*-
import datetime
start_time = datetime.datetime.now()
for i in range(10000):
result_list = []
out_num = i * 100 # 放到第一个循环中计算
for j in range(10000):
result_list.append(out_num + j * 100)
end_time = datetime.datetime.now()
print u'计算耗时:{0}'.format((end_time - start_time).microseconds)
注意这两部分代码的区别,我们只是将第二个循环内的计算放到了第二个新欢外边,我们再来看下此时的耗时732000微秒:
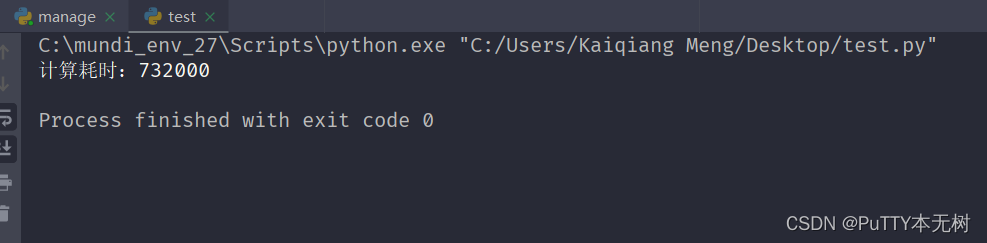 优化后耗时
优化后耗时
可以看到,性能提高大约25%左右,这只是用10000计算的,实际业务场景数据可能远远大于这个。
巧妙使用yield
关于yield定义我们就不在赘述了,直接上代码
# -*- coding: utf-8 -*-
# 使用yield
import datetime
start_time = datetime.datetime.now()
def get_list_element():
for i in range(1000000):
temp = ['111111'] * 2000
yield temp
j = get_list_element()
for ele in j:
continue
end_time = datetime.datetime.now()
print u'计算耗时:{0}'.format((end_time - start_time).microseconds)
# -*- coding: utf-8 -*-
# 不使用yield
import datetime
start_time = datetime.datetime.now()
test_list = []
for i in range(1000000):
temp = ['111111'] * 2000
test_list.append(temp)
for ele in test_list:
continue
end_time = datetime.datetime.now()
print u'计算耗时:{0}'.format((end_time - start_time).microseconds)
实际运行结果:

使用yield
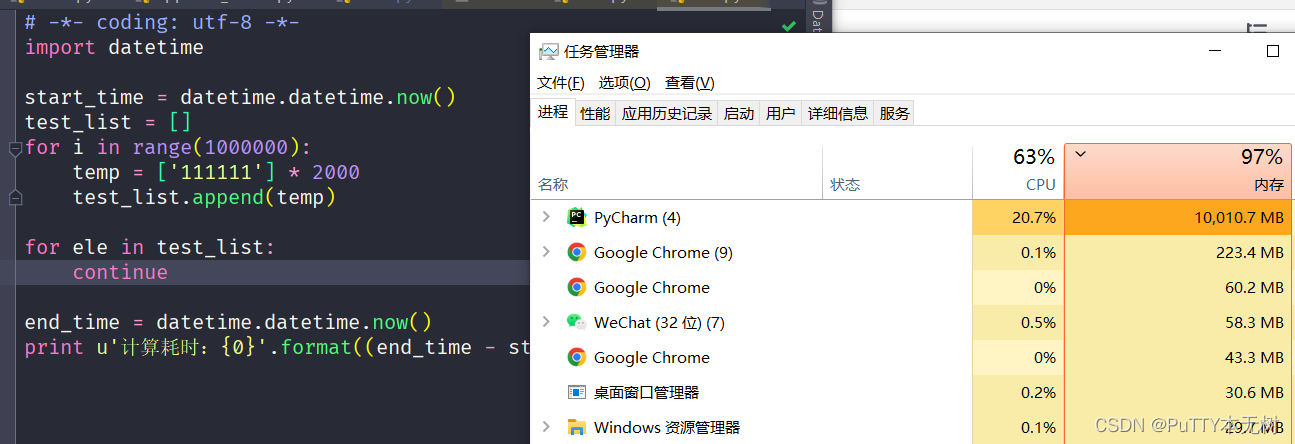 不使用yield
不使用yield
从测试结果中可以看出,在使用yield情况下,内存占用始终在30%左右,程序运行前后几乎不变,而且计算完后后耗时大约143000微秒。而不使用yield情况就不一样了。可以看到,程序运行的瞬间,内存直接拉满(电脑都卡的不要不要的),而且耗时也远远超于使用yield的情况。
可以看到,巧妙的使用yield能节省巨大的时间、空间开销。















 7339
7339











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









