







Map
这样的 Key Value 在软件开发中是非常经典的结构,常用于在内存中存放数据。
本篇主要想讨论 ConcurrentHashMap 这样一个并发容器,在正式开始之前我觉得有必要谈谈 HashMap,没有它就不会有后面的
ConcurrentHashMap
HashMap
众所周知 HashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。
JDK1.7 中的数据结构图:
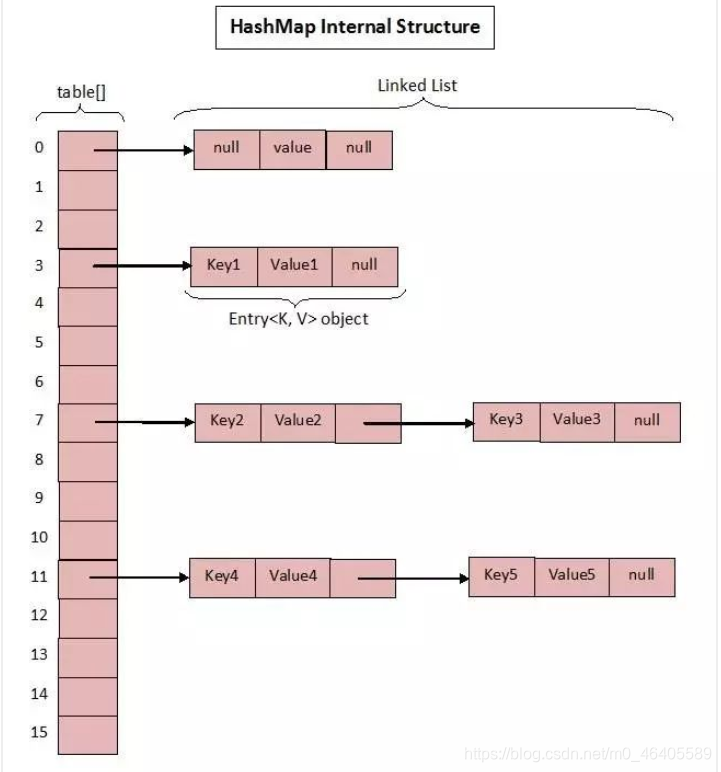
先看一下JDK1.7中:
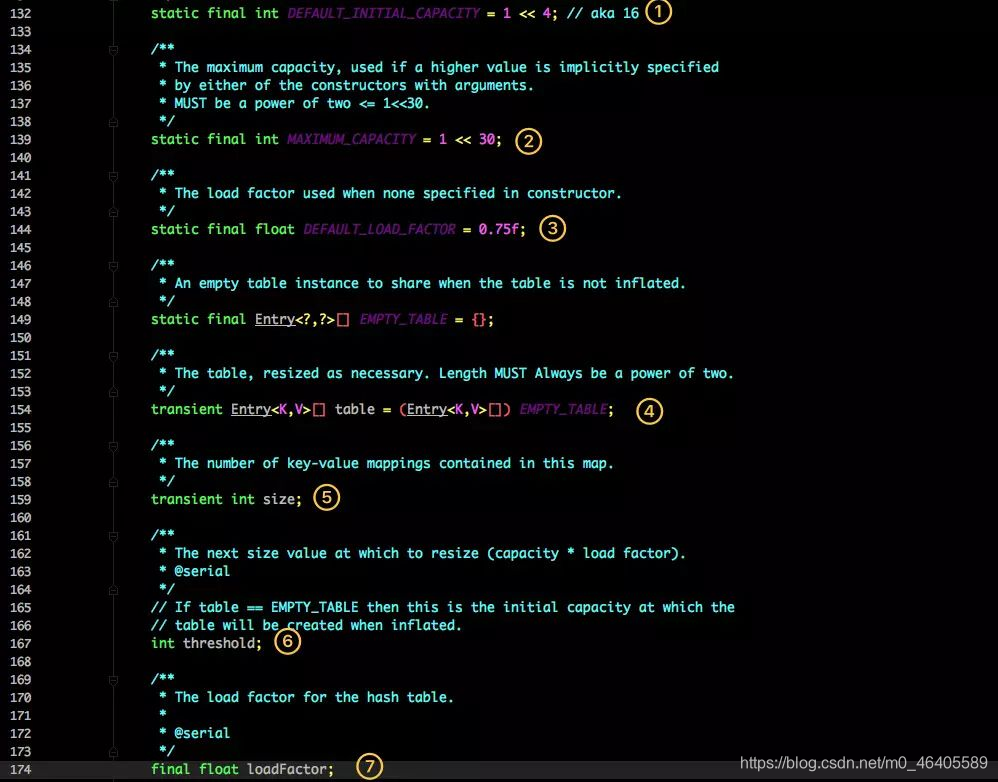
这是 HashMap 中比较核心的几个成员变量;看看分别是什么意思?
1.初始化桶大小,因为底层是数组,所以这是数组默认的大小。
2.桶最大值。
3.默认的负载因子(0.75)
4.table 真正存放数据的数组。
5.Map 存放数量的大小。
6.桶大小,可在初始化时显式指定。
7.负载因子,可在初始化时显式指定。
重点解释下负载因子: 由于给定的 HashMap 的容量大小是固定的,比如默认初始化:
1 public HashMap() {
2 this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR);
3 }
4
5 public HashMap(int initialCapacity, float loadFactor) {
6 if (initialCapacity < 0)
7 throw new IllegalArgumentException("Illegal initial capacity: " +
8 initialCapacity);
9 if (initialCapacity > MAXIMUM_CAPACITY)
10 initialCapacity = MAXIMUM_CAPACITY;
11 if (loadFactor <= 0 || Float.isNaN(loadFactor))
12 throw new IllegalArgumentException("Illegal load factor: " +
13 loadFactor);
14
15 this.loadFactor = loadFactor;
16 threshold = initialCapacity;
17 init();
18 }
给定的默认容量为 16,负载因子为 0.75。Map 在使用过程中不断的往里面存放数据,当数量达到了 16 * 0.75 = 12 就需要将当前 16 的容量进行扩容,而扩容这个过程涉及到 rehash、复制数据等操作,所以非常消耗性能。
因此通常建议能提前预估 HashMap 的大小最好,尽量的减少扩容带来的性能损耗。
根据代码可以看到其实真正存放数据的是
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
这个数组,那么它又是如何定义的呢?
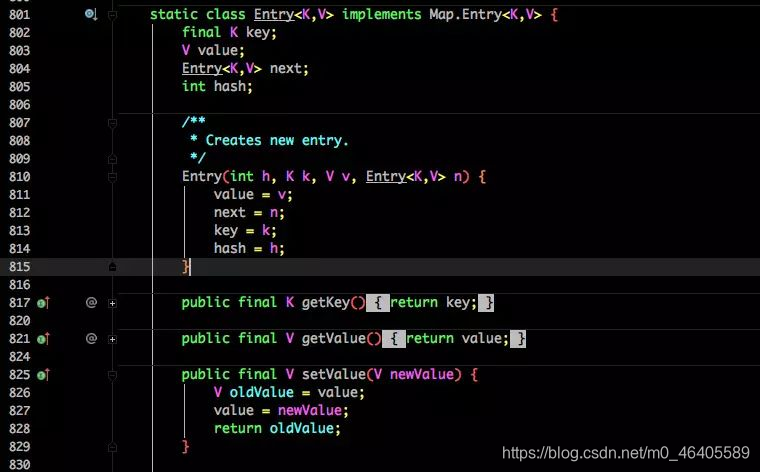
Entry 是 HashMap 中的一个内部类,从他的成员变量很容易看出:
key 就是写入时的键。
value 自然就是值。
开始的时候就提到 HashMap 是由数组和链表组成,所以这个 next 就是用于实现链表结构。
hash 存放的是当前 key 的 hashcode。
不知道 1.7 的实现大家看出需要优化的点没有? 其实一个很明显的地方就是:
当 Hash 冲突严重时,在桶上形成的链表会变的越来越长,这样在查询时的效率就会越来越低;时间复杂度为 O(N)。
因此 1.8 中重点优化了这个查询效率。
1.8 HashMap 结构图:
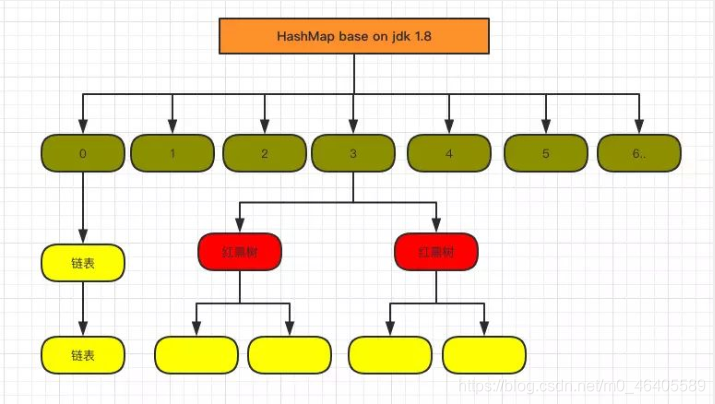
HashMap在jdk8中相较于jdk7在底层实现方面的不同:
1. new HashMap():底层没创建一个长度为16的数组
2. jdk 8底层的数组是:Node[],而非Entry[]
3. 首次调用put()方法时,底层创建长度为16的数组
4. jdk7底层结构:数组+链表。jdk8中底层结构:数组+链表+红黑树。
4.1 形成链表时,七上八下(jdk7:新的元素指向旧的元素。jdk8:旧的元素指向新的元素)
4.2 当数组的某一个索引位置上的元素以链表形式存在的数据个数 > 8 且当前数组的长度 > 64时,此时此索引位置上的所数据改为使用红黑树存储。
TREEIFY_THRESHOLD:Bucket中链表长度大于该默认值,转化为红黑树:8
MIN_TREEIFY_CAPACITY:桶中的Node被树化时最小的hash表容量:64
这里强调一下HashMap的遍历方式:
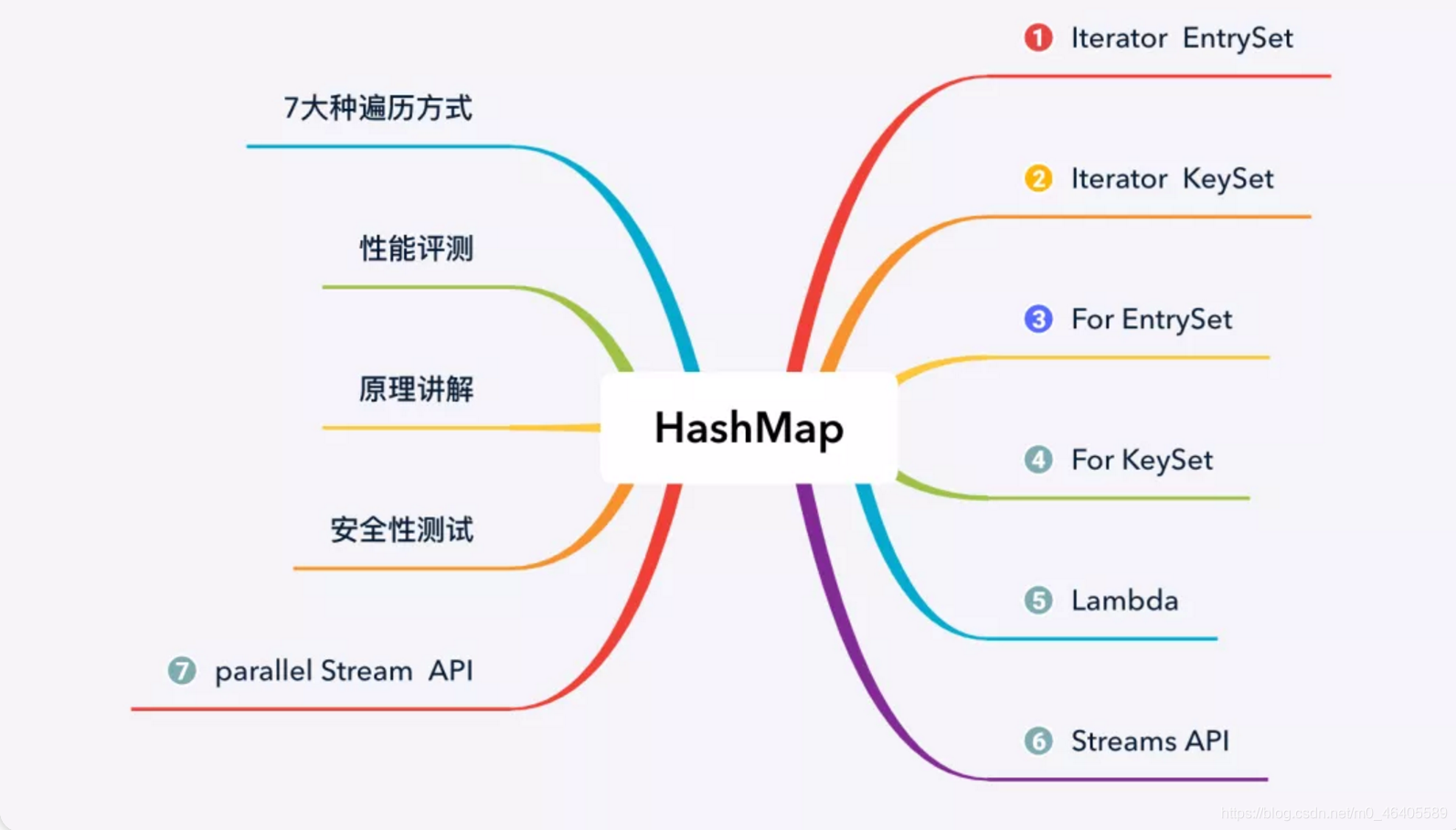
**
HashMap 遍历从大的方向来说,可分为以下 4 类:
1.迭代器(Iterator)方式遍历;
2.For Each 方式遍历;
3.Lambda 表达式遍历(JDK 1.8+);
4.Streams API 遍历(JDK 1.8+)。
但每种类型下又有不同的实现方式,因此具体的遍历方式又可以分为以下 7 种:
1.使用迭代器(Iterator)EntrySet 的方式进行遍历;
2.使用迭代器(Iterator)KeySet 的方式进行遍历;
3.使用 For Each EntrySet 的方式进行遍历;
4.使用 For Each KeySet 的方式进行遍历;
5.使用 Lambda 表达式的方式进行遍历;
6.使用 Streams API 单线程的方式进行遍历;
7.使用 Streams API 多线程的方式进行遍历。**
这里说两种常用的遍历方法:
//方式一: entrySet()
Set entrySet = map . entrySet();
Iterator iterator1 = entrySet . iterator();
while (iterator1. hasNext()){
Object obj = iterator1.next();
//entrySet集合中的元素都是entry
Map. Entry lIntry = (Map.Entry) obj;
System. out. print1n(entry. getKey() +“---->" + entry. getValue());
}
System. out . print1n();
//方式二:
Set keySet = map. keySet();
Iterator iterator2 = keySet . iterator();
while(iterator2. hasNext()){
Object key = iterator2. next();
Object value = map. get(key);
System. out . println(key + "=====" + value);
还有几种我后面会专门写一篇HashMap的不同遍历方法分析。
下面来说说ConcurrentHashMap
在Java1.5中,并发编程大师Doug Lea给我们带来了concurrent包,而该包中提供的ConcurrentHashMap是线程安全并且高效的HashMap,本节我们就来研究下ConcurrentHashMap是如何保证线程安全的同时又能高效的操作。
1.为何用ConcurrentHashMap
在并发编程中使用HashMap可能会导致死循环,而使用线程安全的HashTable效率又低下。
线程不安全的HashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap,如以下代码会导致死循环:
final HashMap<String, String> map = new HashMap<String, String>(2);
Thread t = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 600
600











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









