







本系列所有所需文件都在这里:https://www.aliyundrive.com/s/D2DViEUL8x7
字符串与数字回填
这一步会使用上一步生成的 02_ob_right_3.json文件
最终生成一份 02_ob_string_number.js文件和一份 02_ob_string_number.json 文件
之前已经下载了源JS文件,并将其分割成了两部分,
02_ob_left_3.js : 执行第二步函数调用还原时需要执行的JS文件
02_ob_right_3.js : 需要被还原的混淆文件,之后的所有分析,观察,改动,都是针对这个文件.
强烈建议: 在观察分析JS文件之前,请先拷贝一份,不要对原JS(或者程序运行中产生临时的JS文件)进行格式化/美化,
否则可能产生未知错误(因为JS有一种抗格式化的语句,可以让格式化之后的代码无法运行)
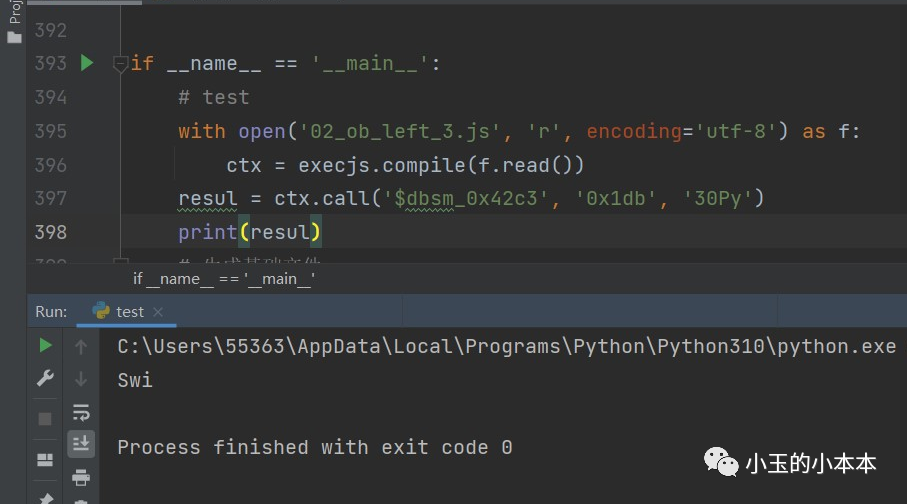
现在测试一下,前三部分的JS代码有没有问题:
# 在python中测试
with open('02_ob_left_3.js', 'r', encoding='utf-8') as f:
ctx = execjs.compile(f.read())
resul = ctx.call('$dbsm_0x42c3', '0x1db', '30Py')
print(resul)
#===============
>>> Swi
语法分析
要反混淆第一步就是对现有的代码做分析,找到其加密的规律,然后按照这个规律进行还原
我们先把源JS文件在pycharm 里格式化一下Ctrl + Alt + L,
然后复制到AST explorer,其中使用的解析器是esprima,我用的node的模块也是这个.
可以看到很快就可以将源代码转换成抽象语法树,然后随便点击一个$dbsm_0x42c3函数调用的地方看看
为什么点这个函数呢?因为它是整个JS的第三部分所声明的一个函数,又叫做解密函数,而且在整个JS中,它被调用了1000多次
这一章字符串与数字回填所要做的工作就是把调用这个函数的参数全部还原
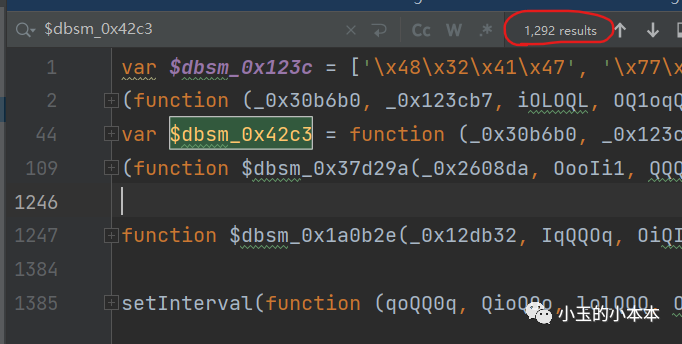

在简单一些的ob混淆中, $dbsm_0x42c3函数调用的地方,参数直接就是字符串,
但是这里我们看到,参数是在这一部分开头所声明的变量,
所以在执行函数还原之前,需要先有一步字符串与数字的回填
接下来我们随便点击一个这样的变量声明查看:
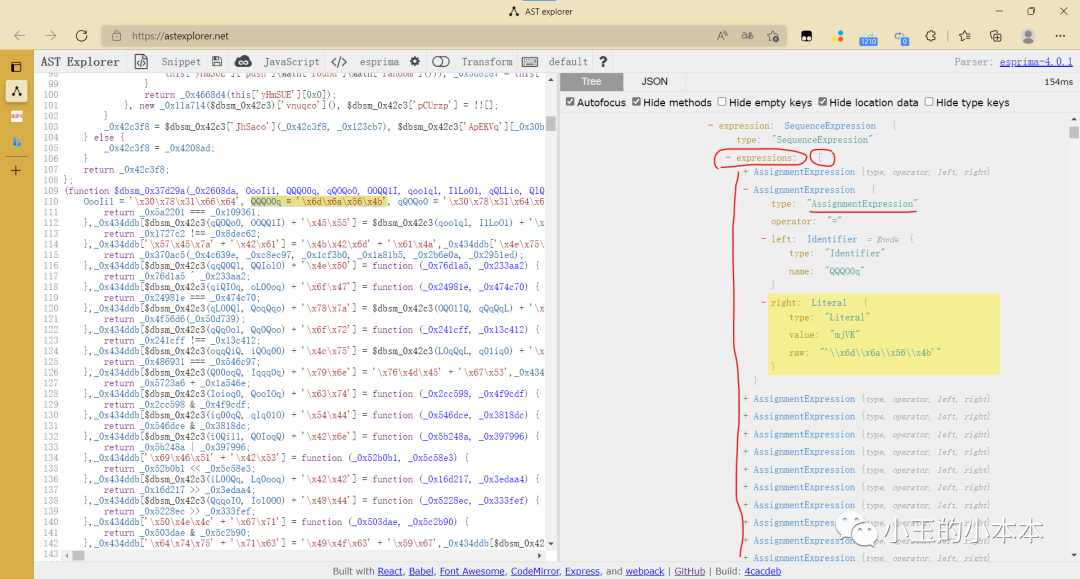
可以发现, 这本身是一个 AssignmentExpression(赋值) 的节点
AST 节点类型详解 https://github.com/babel/babel/blob/main/packages/babel-parser/ast/spec.md#assignmentexpression
被包含在一个列表里,拥有左右两个子节点,
左子节点类型 = Identifier (引用/变量)
右子节点类型 = Literal (常量/基本类型)
所以我们可以用递归的方式,找到所有这样的节点,将他们的映射保存在字典中, 以便在调用他们的地方做替换,
定位节点容器的路径
本来想用递归去查找这些声明节点,但是我发现,这些节点,全都在每个部分的开头处(4,5,6三个部分都有),意味着路径不深,
于是可以直接定位包裹这些节点的列表容器,然后遍历就OK了.
# 变量申明节点所在的列表的路径示意代码
# 说的路径不深,其实也不短
try:
# 第四部分路径
expressions_list = node['expression']['callee']['body']['body'][0]['expression']['expressions']
except TypeError:
# 第五部分路径
expressions_list = node['body']['body'][0]['expression']['expressions']
except KeyError:
# 第六部分路径
expressions_list = node['expression']['arguments'][0]['body']['body'][0]['expression']['expressions']
接着我将后三部分,分别传入,分别获取每一部分的变量与字符串映射的字典
为什么要分别提取呢? 因为这个示例里面变量名有重复,重复,复…
提取变量与字符串节点的映射关系
找到了容器,提取映射就变得非常简单
# 提取字符串与数字的映射示例代码
# 定义一个存储映射的字典
string_number_dict = {}
def get_string_number_dict(node):
# 后三部分,每一部分都有这样的结构,而且变量名称有重复,必须分开做
# 先清空 string_number_dict
string_number_dict.clear()
try:
expressions_list = node['expression']['callee']['body']['body'][0]['expression']['expressions']
except TypeError:
expressions_list = node['body']['body'][0]['expression']['expressions']
except KeyError:
expressions_list = node['expression']['arguments'][0]['body']['body'][0]['expression']['expressions']
for item in expressions_list:
if item['type'] != 'AssignmentExpression':
continue
if item['left']['type'] == 'Identifier':
if item['right']['type'] == 'Literal': # 左右子节点属性都符合,直接存入
string_number_dict[item['left']['name']] = item['right']
elif item['right']['type'] == 'BinaryExpression': # 右子节点是一个运算表达式
left = string_number_dict[item['right']['left']['name']]
right = item['right']['right']
try:
new_node = copy.deepcopy(right)
# 将运算后的结果存入
new_node['value'] = eval(f'{left["value"]} {item["right"]["operator"]} {right["value"]}')
string_number_dict[item['left']['name']] = new_node
except TypeError:
print(item['right'])
sys.exit()
字符串回填
映射提取好了,接着就是在调用这些变量的地方进行替换,
可以看到,这些变量被调用时,都包裹在一个名为 arguments 的 列表里
所以我递归访问每一个节点的 arguments 属性,以此找到所有变量调用的地方
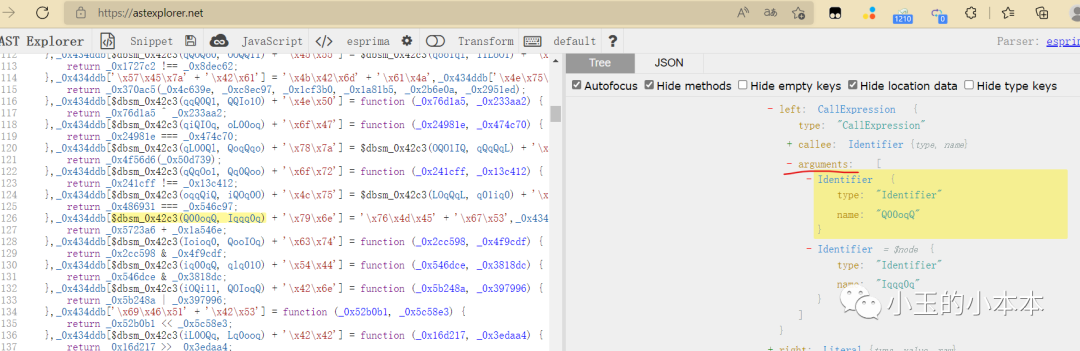
替换时和提取映射时一样,一次只能传入JS的一个部分去做,因为变量名有重复
需要替换的位置是不确定的,只能使用递归来完成
# 映射替换示例代码
# 将调用这些变量的地方进行还原
def string_number_reload(node):
# 一次只能还原一个部分
if type(node) == list:
# 虽然arguments 自身就是一个列表,但是他会在下方被捕捉,不会进入这个递归分支
for item in node:
string_number_reload(item)
return
elif type(node) != dict: # 不是容器类型,就停止递归
return
# 捕捉一个包含 arguments 属性的节点
try:
for i in range(len(node['arguments'])): # 遍历所有参数
if node['arguments'][i]['type'] == 'Identifier': # 匹配,则进入替换分支
try:
# 捕获前面参数不匹配,而后面参数匹配的情况,确保每个参数都进行匹配
node['arguments'][i] = string_number_dict[node['arguments'][i]['name']]
except KeyError:
pass
else:
raise KeyError
except KeyError: # 无论结局如何,将该节点所有属性,再次加入递归,防止漏网之鱼
for key in node.keys():
string_number_reload(node[key])
return
删除映射节点
在回填结束后,所有的之前找到的变量申明节点都没有用了,
需要进行删除,我们使用之前的方式重新查找映射,之前是找到就存入,现在是找到就删除
# 删除变量与字符串映射的节点
def del_string_number_node(node):
string_number_dict.clear()
try:
expressions_list = node['expression']['callee']['body']['body'][0]['expression']['expressions']
except TypeError:
expressions_list = node['body']['body'][0]['expression']['expressions']
except KeyError:
expressions_list = node['expression']['arguments'][0]['body']['body'][0]['expression']['expressions']
for i in range(len(expressions_list) - 1, -1, -1):
if expressions_list[i]['type'] != 'AssignmentExpression':
continue
if expressions_list[i]['left']['type'] == 'Identifier' and expressions_list[i]['right']['type'] in (
'Literal', 'BinaryExpression'):
del expressions_list[i]
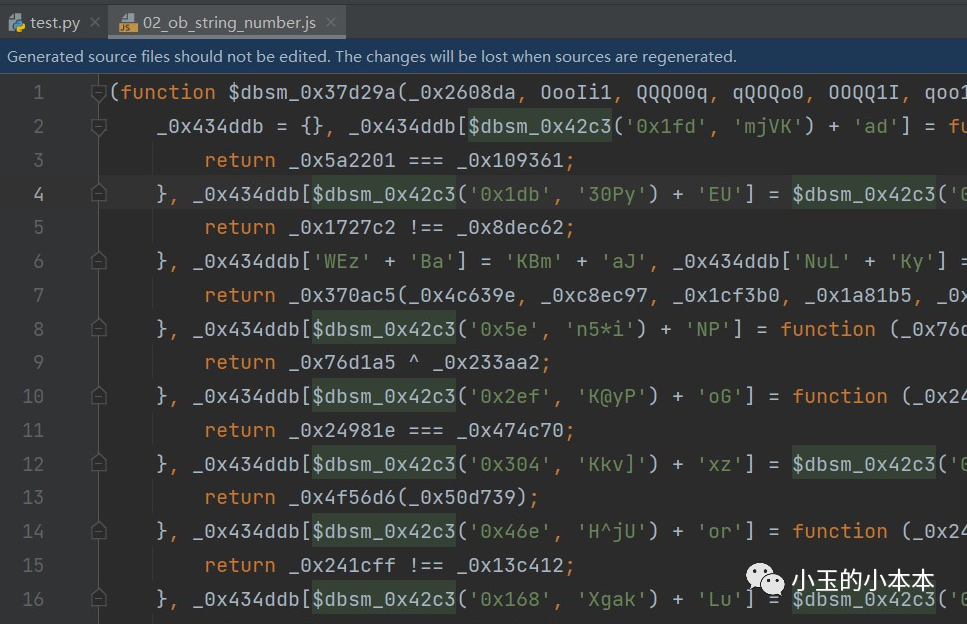
至此,第一步(字符串与数字回填)已完成,查看生成的 02_ob_string_number.js文件
最终效果如图:
可以看到所有函数调用的地方,参数已经还原成了字符串,申明变量的地方也已经被删除
附件: 第一步完整代码
字符串与数字回填,完整代码:
# test.py
import copy
import json
import os
import sys
import requests
import config
import execjs
""" 字符串与数字回填 """
string_number_dict = {}
# 提取变量与字符串的映射
def get_string_number_dict(node):
# 后三部分,每一部分都有这样的结构,而且变量名称有重复,必须分开做
# 先清空 string_number_dict
string_number_dict.clear()
try:
# 第四部分路径
expressions_list = node['expression']['callee']['body']['body'][0]['expression']['expressions']
except TypeError:
# 第五部分路径
expressions_list = node['body']['body'][0]['expression']['expressions']
except KeyError:
# 第六部分路径
expressions_list = node['expression']['arguments'][0]['body']['body'][0]['expression']['expressions']
for item in expressions_list:
if item['type'] != 'AssignmentExpression':
continue
if item['left']['type'] == 'Identifier':
if item['right']['type'] == 'Literal':
string_number_dict[item['left']['name']] = item['right']
elif item['right']['type'] == 'BinaryExpression':
left = string_number_dict[item['right']['left']['name']]
right = item['right']['right']
try:
new_node = copy.deepcopy(right)
new_node['value'] = eval(f'{left["value"]} {item["right"]["operator"]} {right["value"]}')
string_number_dict[item['left']['name']] = new_node
except TypeError:
print(item['right'])
sys.exit()
# 将调用这些变量的地方进行还原
def string_number_reload(node):
# 一次只能还原一个部分
if type(node) == list:
for item in node:
string_number_reload(item)
return
elif type(node) != dict:
return
# 调用这些变量的地方都是实参
try:
for i in range(len(node['arguments'])):
if node['arguments'][i]['type'] == 'Identifier':
try:
# 捕获前面参数不匹配,而后面参数匹配的情况
node['arguments'][i] = string_number_dict[node['arguments'][i]['name']]
except KeyError:
pass
else:
raise KeyError
except KeyError:
for key in node.keys():
string_number_reload(node[key])
return
# 删除变量与字符串映射的节点
def del_string_number_node(node):
string_number_dict.clear()
try:
expressions_list = node['expression']['callee']['body']['body'][0]['expression']['expressions']
except TypeError:
expressions_list = node['body']['body'][0]['expression']['expressions']
except KeyError:
# 第五部分路径
expressions_list = node['expression']['arguments'][0]['body']['body'][0]['expression']['expressions']
for i in range(len(expressions_list) - 1, -1, -1):
if expressions_list[i]['type'] != 'AssignmentExpression':
continue
if expressions_list[i]['left']['type'] == 'Identifier' and expressions_list[i]['right']['type'] in (
'Literal', 'BinaryExpression'):
del expressions_list[i]
""" ********************************************************* """
if __name__ == '__main__':
# 生成基础文件
# get_02_ob_js()
""" 字符串与数字回填[ok] """
with open('02_ob_right_3.json', 'r', encoding='utf8') as f:
data = json.loads(f.read())
for item in data['body']: # 将每一部分,分别做回填
get_string_number_dict(item)
string_number_reload(item)
del_string_number_node(item)
with open('02_ob_string_number.json', 'w', encoding='utf8') as f:
f.write(json.dumps(data)) # 将结果写入json给下一步读取继续更改,写入js供下一步观察分析















 6287
6287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









