









目录
浏览器插件
极简插件
FeHelper Web前端助手:JSON格式化工具
协议类型为:http/2.0时,无法用requests请求去获取数据。
请求头说明:HTTP协议头部与Keep-Alive模式详解
response_status为500-505,此时有可能是服务器响应不过来,此时要及时停止。
ddos:大流量攻击,肉鸡攻击
fake_useragent模块
爬虫通讯原理
在线DNS解析工具:在线DNS解析_ip33.com
HTTP 和 HTTPS
在百度的首页 https://www.baidu.com/,中,URL 的开头会有 http 或 https,这个就是访问资源需要的协议类型,有时我们还会看到 ftp、sftp、smb 开头的 URL,那么这里的 ftp、sftp、smb 都是指的协议类型。在爬虫中,我们抓取的页面通常就是 http 或 https 协议的。
-
HTTP 的全称是 Hyper Text Transfer Protocol,中文名叫做超文本传输协议
-
HTTPS 的全称是 Hyper Text Transfer Protocol over Secure Socket Layer,是以安全为目标的 HTTP 通道,简单讲是 HTTP 的安全版,即 HTTP 下加入 SSL 层,简称为 HTTPS。
VPN原理

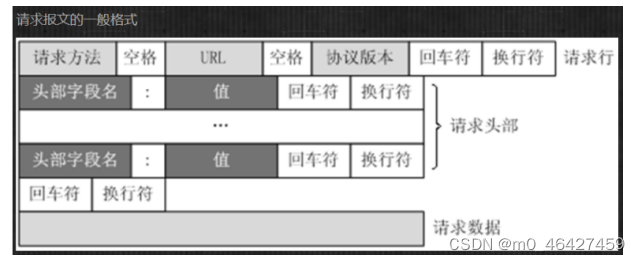
请求
请求,由客户端向服务端发出,可以分为 4 部分内容:请求方法(Request Method)、请求的网址 (Request URL)、请求头(Request Headers)、请求体(Request Body)。
window浏览器按F12可以进入调试助手
请求方法
| 方 法 | 描 述 |
|---|---|
| GET | 请求页面,并返回页面内容 |
| HEAD | 类似于 GET 请求,只不过返回的响应中没有具体的内容,用于获取报头 |
| POST | 大多用于提交表单或上传文件,数据包含在请求体中 |
| PUT | 从客户端向服务器传送的数据取代指定文档中的内容 |
| DELETE | 请求服务器删除指定的页面 |
| CONNECT | 把服务器当作跳板,让服务器代替客户端访问其他网页 |
| OPTIONS | 允许客户端查看服务器的性能 |
| TRACE | 回显服务器收到的请求,主要用于测试或诊断 |
请求网站
请求的网址,即统一资源定位符 URL,它可以唯一确定我们想请求的资源。
请求头
-
Accept
-
Accept-Language
-
Accept-Encoding
-
Host 主机
-
Cookie 会话信息 身份
-
Referer 记录来源
-
User-Agent 浏览器得指纹信息
-
Content-Type 类型
请求体
请求体一般承载的内容是 POST 请求中的表单数据,而对于 GET 请求,请求体则为空。
响应
响应,由服务端返回给客户端,可以分为三部分:响应状态码(Response Status Code)、响应头(Response Headers)和响应体(Response Body)。
1、响应状态码
响应状态码表示服务器的响应状态,如 200 代表服务器正常响应,404 代表页面未找到,500 代表服务器内部发生错误。在爬虫中,我们可以根据状态码来判断服务器响应状态,如状态码为 200,则证明成功返回数据,再进行进一步的处理,否则直接忽略。
| 状态码 | 说 明 | 详 情 |
|---|---|---|
| 100 | 继续 | 请求者应当继续提出请求。服务器已收到请求的一部分,正在等待其余部分 |
| 101 | 切换协议 | 请求者已要求服务器切换协议,服务器已确认并准备切换 |
| 200 | 成功 | 服务器已成功处理了请求 |
| 201 | 已创建 | 请求成功并且服务器创建了新的资源 |
| 202 | 已接受 | 服务器已接受请求,但尚未处理 |
| 203 | 非授权信息 | 服务器已成功处理了请求,但返回的信息可能来自另一个源 |
| 204 | 无内容 | 服务器成功处理了请求,但没有返回任何内容 |
| 205 | 重置内容 | 服务器成功处理了请求,内容被重置 |
| 206 | 部分内容 | 服务器成功处理了部分请求 |
| 300 | 多种选择 | 针对请求,服务器可执行多种操作 |
| 301 | 永久移动 | 请求的网页已永久移动到新位置,即永久重定向 |
| 302 | 临时移动 | 请求的网页暂时跳转到其他页面,即暂时重定向 |
| 303 | 查看其他位置 | 如果原来的请求是 POST,重定向目标文档应该通过 GET 提取 |
| 304 | 未修改 | 此次请求返回的网页未修改,继续使用上次的资源 |
| 305 | 使用代理 | 请求者应该使用代理访问该网页 |
| 307 | 临时重定向 | 请求的资源临时从其他位置响应 |
| 400 | 错误请求 | 服务器无法解析该请求 |
| 401 | 未授权 | 请求没有进行身份验证或验证未通过 |
| 403 | 禁止访问 | 服务器拒绝此请求 |
| 404 | 未找到 | 服务器找不到请求的网页 |
| 405 | 方法禁用 | 服务器禁用了请求中指定的方法 |
| 406 | 不接受 | 无法使用请求的内容响应请求的网页 |
| 407 | 需要代理授权 | 请求者需要使用代理授权 |
| 408 | 请求超时 | 服务器请求超时 |
| 409 | 冲突 | 服务器在完成请求时发生冲突 |
| 410 | 已删除 | 请求的资源已永久删除 |
| 411 | 需要有效长度 | 服务器不接受不含有效内容长度标头字段的请求 |
| 412 | 未满足前提条件 | 服务器未满足请求者在请求中设置的其中一个前提条件 |
| 413 | 请求实体过大 | 请求实体过大,超出服务器的处理能力 |
| 414 | 请求 URI 过长 | 请求网址过长,服务器无法处理 |
| 415 | 不支持类型 | 请求格式不被请求页面支持 |
| 416 | 请求范围不符 | 页面无法提供请求的范围 |
| 417 | 未满足期望值 | 服务器未满足期望请求标头字段的要求 |
| 500 | 服务器内部错误 | 服务器遇到错误,无法完成请求 |
| 501 | 未实现 | 服务器不具备完成请求的功能 |
| 502 | 错误网关 | 服务器作为网关或代理,从上游服务器收到无效响应 |
| 503 | 服务不可用 | 服务器目前无法使用 |
| 504 | 网关超时 | 服务器作为网关或代理,但是没有及时从上游服务器收到请求 |
| 505 | HTTP 版本不支持 | 服务器不支持请求中所用的 HTTP 协议版本 |
2、响应头
响应头包含了服务器对请求的应答信息,如 Content-Type、Server、Set-Cookie 等。下面简要说明一些常用的头信息。
-
Date:标识响应产生的时间。
-
Last-Modified:指定资源的最后修改时间。
-
Content-Encoding:指定响应内容的编码。
-
Server:包含服务器的信息,比如名称、版本号等。
-
Content-Type:文档类型,指定返回的数据类型是什么,如 text/html 代表返回 HTML 文档,application/x-javascript 则代表返回 JavaScript 文件,image/jpeg 则代表返回图片。
-
Set-Cookie:设置 Cookies。响应头中的 Set-Cookie 告诉浏览器需要将此内容放在 Cookies 中,下次请求携带 Cookies 请求。
-
Expires:指定响应的过期时间,可以使代理服务器或浏览器将加载的内容更新到缓存中。如果再次访问时,就可以直接从缓存中加载,降低服务器负载,缩短加载时间。
3、响应体
最重要的当属响应体的内容了。响应的正文数据都在响应体中,比如请求网页时,它的响应体就是网页的 HTML 代码;请求一张图片时,它的响应体就是图片的二进制数据。我们做爬虫请求网页后,要解析的内容就是响应体
在浏览器开发者工具中点击 Preview,就可以看到网页的源代码,也就是响应体的内容,它是解析的目 标。 在做爬虫时,我们主要通过响应体得到网页的源代码、JSON 数据等,然后从中做相应内容的提取。
会话和Cookies
在浏览网站的过程中,我们经常会遇到需要登录的情况,有些页面只有登录之后才可以访问,而且登录之后可以连续访问很多次网站,但是有时候过一段时间就需要重新登录。还有一些网站,在打开浏览器时就自动登录了,而且很长时间都不会失效,这种情况又是为什么?其实这里面涉及会话(Session)和 Cookies 的相关知识。
无状态HTTP
-
会话
会话,其本来的含义是指有始有终的一系列动作 / 消息。比如,打电话时,从拿起电话拨号到挂断电话这中间的一系列过程可以称为一个会话。
-
Cookies
Cookies 指某些网站为了辨别用户身份、进行会话跟踪而存储在用户本地终端上的数据。
-
Cookies 列表
- Name,即该 Cookie 的名称。Cookie 一旦创建,名称便不可更改
-
Value,即该 Cookie 的值。如果值为 Unicode 字符,需要为字符编码。如果值为二进制数据,则需要使用 BASE64 编码。
-
Max Age,即该 Cookie 失效的时间,单位秒,也常和 Expires 一起使用,通过它可以计算出其有效时间。Max Age 如果为正数,则该 Cookie 在 Max Age 秒之后失效。如果为负数,则关闭浏览器时 Cookie 即失效,浏览器也不会以任何形式保存该 Cookie。
-
Path,即该 Cookie 的使用路径。如果设置为 /path/,则只有路径为 /path/ 的页面可以访问该 Cookie。如果设置为 /,则本域名下的所有页面都可以访问该 Cookie。
-
Domain,即可以访问该 Cookie 的域名。例如如果设置为 .zhihu.com,则所有以 zhihu.com,结尾的域名都可以访问该 Cookie。
-
Size 字段,即此 Cookie 的大小。
-
Http 字段,即 Cookie 的 httponly 属性。若此属性为 true,则只有在 HTTP Headers 中会带有此 Cookie 的信息,而不能通过 document.cookie 来访问此 Cookie。true(打钩)一般是从后台返回的,false一般是前台页面生成的。
-
Secure,即该 Cookie 是否仅被使用安全协议传输。安全协议。安全协议有 HTTPS,SSL 等,在网络上传输数据之前先将数据加密。默认为 false
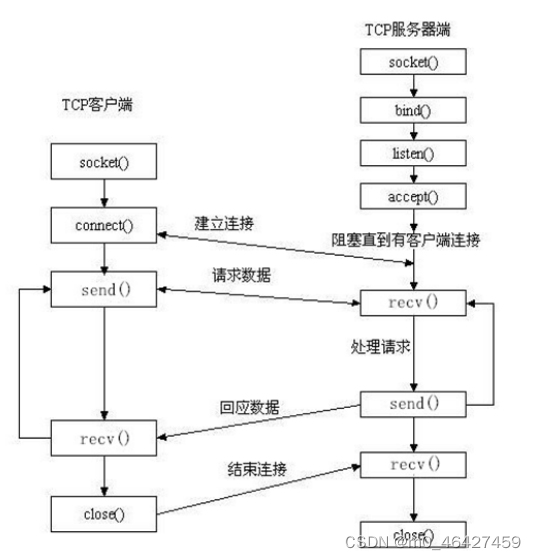
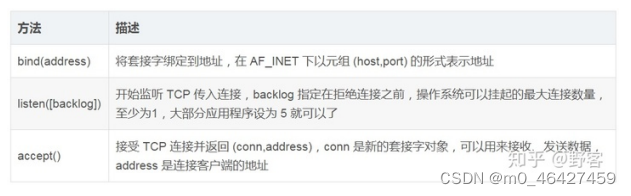
socket介绍
参考:socket编程入门:1天玩转socket通信技术(非常详细)
在计算机通信领域,socket 被翻译为“套接字”,它是计算机之间进行通信的一种约定或一种方式。通过 socket 这种约定,一台计算机可以接收其他计算机的数据,也可以向其他计算机发送数据
应该是应用层与传输层间的一个抽象层
七层协议:
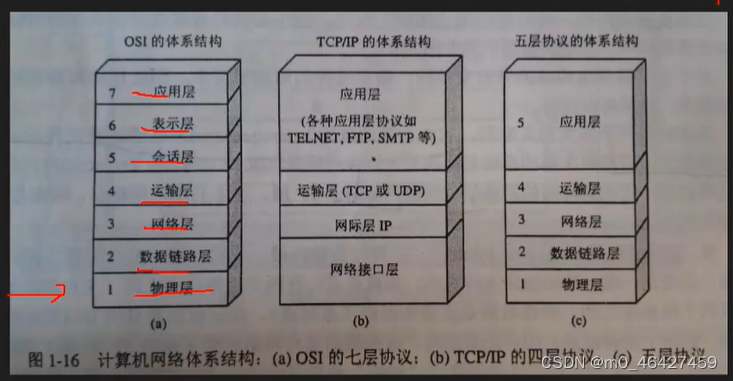
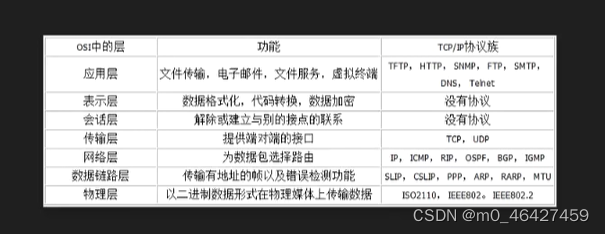
流程图
请求报文格式
套接字对象服务端方法
使用socket下载图片
import socket # socket模块是python自带的内置模块,不需要我们去下载
url = "https://timgsa.baidu.com/timg?image&quality=80&size=b9999_10000&sec=1592044641865&di=0327cb231438736083705e79ad0224ce&imgtype=0&src=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20181225%2F6ada859bf69044cbbb2304ac05b39f39.jpeg"
# 创建套接字客户端
client = socket.socket()
# 连接,通过(ip,端口)来进行连接
client.connect(("timgsa.baidu.com",80))
# 请求报文
# GET / HTTP/1.0\r\nHost:www.baoidu.com\r\n\r\n
resq = "GET /timg?image&quality=80&size=b9999_10000&sec=1592044641865&di=0327cb231438736083705e79ad0224ce&imgtype=0&src=http%3A%2F%2F5b0988e595225.cdn.sohucs.com%2Fimages%2F20181225%2F6ada859bf69044cbbb2304ac05b39f39.jpeg HTTP/1.0\r\nHost: timgsa.baidu.com\r\n\r\n"
# 根据请求头来发送请求信息
client.send(resq.encode())
# 建立一个二进制对象用来存储我们得到的数据
result = b''
data = client.recv(1024)
# 循环接收响应数据 添加到bytes类型
while data:
result+=data
data = client.recv(1024)
import re
# re.S使 . 匹配包括换行在内的所有字符 去掉响应头
images = re.findall(b'\r\n\r\n(.*)',result, re.S)
print(len(images[0])) # 查看大小
kb = len(images[0]) / 1024 # 转换大小
mb = kb / 1024
# 打开一个文件,将我们读取到的数据存入进去,即下载到本地我们获取到的图片
with open("test.jpg","wb") as f:
f.write(images[0])httpx模块
python新一代的网络请求库,可以实现异步,特点:
-
基于Python3的功能齐全的http请求模块
-
既能发送同步请求,也能发送异步请求
-
支持HTTP/1.1和HTTP/2
-
能够直接向WSGI应用程序或者ASGI应用程序发送请求
安装:pip install httpx
测试
import httpx
headers = {'user-agent': 'my-app/1.0.0'}
params = {'key1': 'value1', 'key2': 'value2'}
url = 'https://httpbin.org/get'
r = httpx.get(url, headers=headers, params=params)有些网页会有反爬,设置了js,不允许代码网页源代码,一旦打开就会跳转。此时我们可以先在其他网页右键打开"查看网页源代码",接下来会跳转到下面这个页面,我们只需将view-source后面的链接改成我们想查看的网页的url即可。
![]()
httpx请求抓图案例
# encoding: utf-8
import httpx
import os
class S_wm(object):
def __init__(self):
self.headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.61 Safari/537.36'
}
def get_url_list(self):
url_list = ['https://img1.baidu.com/it/u=1875739781,4152007440&fm=253&fmt=auto&app=120&f=JPEG?w=1024&h=576',
'https://img1.baidu.com/it/u=3980896846,3728494487&fm=253&fmt=auto&app=138&f=JPEG?w=333&h=499',
'https://img1.baidu.com/it/u=467548803,2897629727&fm=253&fmt=auto&app=138&f=JPEG?w=800&h=500',
]
return url_list
def save_image(self,filename,img):
with open(filename, 'wb') as f:
f.write(img.content)
print('图片提取成功')
def run(self):
url_list = self.get_url_list()
for index,u in enumerate(url_list):
file_name = './image/{}.jpg'.format(index)
data = httpx.request('get', u, headers=self.headers)
# 当然也可以用httpx.get()
self.save_image(file_name,data)
if __name__ == '__main__':
url = 'https://www.vmgirls.com/13344.html'
s = S_wm()
if os.path.exists("./image") is False:
os.mkdir('./image')
s.run()数据采集HTTP库使用
一、正则
开源测试工具:http://tool.oschina.net/regex/
re官网:https://docs.python.org/zh-cn/3/library/re.html

| . | 匹配除 "\n" 之外的任何单个字符。要匹配包括 '\n' 在内的任何字符,请使用象 '[.\n]' 的模式。 |
|---|---|
| \d | 匹配一个数字字符。等价于 [0-9]。 |
| \D | 匹配一个非数字字符。等价于 0-9。 |
| \s | 匹配任何空白字符,包括空格、制表符、换页符等等。等价于 [ \f\n\r\t\v]。 |
| \S | 匹配任何非空白字符。等价于 \f\n\r\t\v。 |
| \w | 匹配包括下划线的任何单词字符。等价于'[A-Za-z0-9_]'。 |
| \W | 匹配任何非单词字符。等价于 'A-Za-z0-9_'。 |
1、match
用法: 提取关键参数 比如 token sign 后端返回得签名信息 算法
match 方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回 None
import re
content = 'Hello 123 456 welcome to tuling'
print(len(content))
result = re.match('^Hello\s\d\d\d\s\d{3}\s\w{7}', content)
print(result)
print(result.group())
print(result.span())-
group() 返回被 正则 匹配的字符串
-
start() 返回匹配开始的位置
-
span() 返回一个元组包含匹配 (开始,结束) 的位置
1、匹配数字
content = 'Hello 123456 welcome to tuling'
result = re.match('^Hello\s(\d+)\swelcome', content)
2、通用匹配
content = 'Hello 123 456 welcome to tuling'
# 匹配所有数据
result = re.match('^Hello.*ng$', content)
# 匹配某某开始到某某结束
result = re.match('^Hello(.*)ng$', content).group(1)
3、贪婪和非贪婪
- python默认贪婪模式
- 在"*","?","+","{m,n}"后面加上?,使贪婪变成非贪婪
content = 'http://feier.com/yyds'
result1 = re.match('http.*?com/(.*?)', content)
result2 = re.match('http.*?com/(.*)', content)
4、修饰符
| re.I | 使匹配对大小写不敏感 |
|---|---|
| re.L | 做本地化识别(locale-aware)匹配 |
| re.M | 多行匹配,影响 ^ 和 $ |
| re.S | 使 . 匹配包括换行在内的所有字符 |
| re.U | 根据Unicode字符集解析字符。这个标志影响 \w, \W, \b, \B. |
| re.X | 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 |
# 这个修饰符的作用是匹配包括换行符在内的所有字符。
content = '''Hello 1234567 World_This
is a Regex Demo
'''
result = re.match('^He.*?(\d+).*?Demo$', content)
result = re.match('^He.*?(\d+).*?Demo$', content,re.S)2、search
用法: 提取数据相关
匹配时会扫描整个字符串,然后返回第一个成功匹配的结果,如果搜索完了还没有找到,就返回 None。
3、匹配中文
[\u4e00-\u9fa5]
s = '大家晚上好asdasdsad'
aa = re.findall('[\u4e00-\u9fa5]+',s)二、Pyquery
安装:pip install pyquery==1.4.3
利用它,我们可以直接解析 DOM 节点的结构,并通过 DOM 节点的一些属性快速进行内容提取。
html = '''
<div id="cont">
<ul class="slist">
<li class="item-0">web开发</li>
<li class="item-1"><a href="link2.html">爬虫开发</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">数据分析</span></a></li>
<li class="item-1 active"><a href="link4.html">深度学习</a></li>
<li class="item-0"><a href="link5.html">机器学习</a></li>
</ul>
</div>
'''1、实例演示
from pyquery import PyQuery as pq
doc = pq(html) # =实例化,参数是html文档文本
print(doc('li')) # 提取li标签
2、解析网页
from pyquery import PyQuery as pq
doc = pq(url='https://www.python.org/')
print(doc('title')) # 根据标记提取
3、css选择器
doc = pq(html)
# 第一层是id选择器所以加上#,第二层是class选择器所以加上.,第三层是标签选择器,每层用空格分隔
print(doc('#cont .slist li'))
print(type(doc('#cont .slist li')))
4、提取内容
for item in doc('#cont .slist li').items():
print(item.text())
5、子节点
from pyquery import PyQuery as pq
doc = pq(html)
items = doc('.slist') # 先定位到ul标签
print(type(items))
print(items) # 提取节点所有内容
lis = items.find('li') # 获取符合条件的li标签
print(type(lis))
print(lis)
5.1 子节点
lis = items.children()
print(type(lis))
print(lis)
6、父节点
co = items.parent()
print(type(co))
print(co)
7、兄弟节点
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.slist .item-0.active')
# print(li.siblings())
print(li.siblings('.active'))
8、 属性获取
from pyquery import PyQuery as pq
doc = pq(html)
a = doc('.item-0.active a')
print(a, type(a))
print(a.attr('href'))
遍历提取
doc = pq(html)
a = doc('a')
for s in a.items():
print(s.attr('href')) # 属性获取
print(s.text()) # 值获取
9、节点操作
对节点进行动态修改,比如为某个节点添加一个 class,移除某个节点等,这些操作有时会为提取信息带来极大的便利。
addClass 和 removeClass
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('.item-0.active')
print(li)
li.removeClass('active')
print(li)
li.addClass('active')
10、伪类选择器
from pyquery import PyQuery as pq
doc = pq(html)
li = doc('li:nth-child(2)') # 第二个节点
li = doc('li:nth-child(2n)') # 偶数位节点
li = doc('li:last-child') # 最后一个节点
print(li)
注:
1、PyQuery也支持直接传url参数构造对象,此时其内部会自己去请求这个url的内容:dco = pd(url="https://www.python.org/")
三、Xpath
插件下载:极简插件_Chrome扩展插件商店_优质crx应用
搜索xpath,下载xpath helper安装到扩展程序即可。然后在网站打开这个插件即可,有些网站可能打不开,有做限制。
xpath参考:https://blog.csdn.net/m0_43432638/article/details/90319198
安装解析引擎: pip install lxml
表 3-1 XPath 常用规则
| 表 达 式 | 描 述 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从当前节点选取直接子节点 |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
案例:
text = '''
<div>
<ul>
<li class="item-0"><a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''1、解析
from lxml import etree
html = etree.HTML(text) # 实例化
result = etree.tostring(html)
print(result.decode('utf-8'))
2、节点操作
我们一般会用 // 开头的 XPath 规则来选取所有符合要求的节点。这里以前面的 HTML 文本为例,如果要选取所有节点,可以这样实现:
result = html.xpath('//*')
# 这里使用 * 代表匹配所有节点,也就是整个 HTML 文本中的所有节点都会被获取。可以看到,返回形式是一个列表,每个元素是 Element 类型,其后跟了节点的名称,如 html、body、div、ul、li、a 等,所有节点都包含在列表中了。xpath用索引去获取元素,索引下标从1开始,而不是0.
3、子节点
result = html.xpath('//li/a')
result = html.xpath('//li/a/text()') # 提取文本
result = html.xpath('//li/a/@href') # 提取属性值
4、指定节点获取
result = html.xpath('//li[@class="item-0"]/a/text()')
print(result)
# ['first item', 'fifth item']
5 、节点轴选择
XPath 提供了很多节点轴选择方法,包括获取子元素、兄弟元素、父元素、祖先元素等,示例如下:
html = etree.HTML(text)
result = html.xpath('//li[1]/ancestor::*') # 选取当前节点的所有先辈
print(result)
result = html.xpath('//li[1]/attribute::*') # 选取当前节点的所有属性
print(result)
result = html.xpath('//li[1]/child::a[@href="link1.html"]') # 选取当前节点的所有子元素
6、找翻页元素
翻页提取案例
地址:https://www.amazon.cn/s?k=%E6%89%8B%E6%9C%BA&__mk_zh_CN=%E4%BA%9A%E9%A9%AC%E9%80%8A%E7%BD%91%E7%AB%99&ref=nb_sb_noss
# 最后一个
//span[contains(@class,'s-pagination-strip')]/span[last()]
# 提取下一页
//span[contains(@class,'s-pagination-strip')]/*[last()]
# 下一页
//span[@class="s-pagination-strip"]/a[text()="下一页"]xpath()有时提取不到内容,返回空列表,这时候用索引去获取里面的元素会报错,应该加上判断。
方法一:
test = html.xpath('')
if test:
aaa = test[0]
else:
aaa = '-'
方法二:lambda表达式
test = lambda x:x[0] if x else '-'
title = test(html.xpath('//a'))四、 Beautiful Soup
参考文章:bs4介绍_- 白鹿 -的博客-CSDN博客_bs4
简单来说,BeautifulSoup 就是 Python 的一个 HTML 或 XML 的解析库,我们可以用它来方便地从网页中提取数据,官方的解释如下:
BeautifulSoup 提供一些简单的、Python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。BeautifulSoup 自动将输入文档转换为 Unicode 编码,输出文档转换为 utf-8 编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时你仅仅需要说明一下原始编码方式就可以了。BeautifulSoup 已成为和 lxml、html5lib 一样出色的 Python 解释器,为用户灵活地提供不同的解析策略或强劲的速度。
表 4-1 Beautiful Soup 支持的解析器
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python 标准库 | BeautifulSoup(markup, "html.parser") | Python 的内置标准库、执行速度适中 、文档容错能力强 | Python 2.7.3 or 3.2.2) 前的版本中文容错能力差 |
| LXML HTML 解析器 | BeautifulSoup(markup, "lxml") | 速度快、文档容错能力强 | 需要安装 C 语言库 |
| LXML XML 解析器 | BeautifulSoup(markup, "xml") | 速度快、唯一支持 XML 的解析器 | 需要安装 C 语言库 |
| html5lib | BeautifulSoup(markup, "html5lib") | 最好的容错性、以浏览器的方式解析文档、生成 HTML5 格式的文档 | 速度慢、不依赖外部扩展 |
通过以上对比可以看出,lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强,所以推荐
安装:pip install beautifulsoup4 # bs4
测试
from bs4 import BeautifulSoup
# 参数1:html文本 参数2:解析引擎
soup = BeautifulSoup('<p>Hello world</p>', 'lxml')
# 如果有多个p标签,只会提取第一个
print(soup.p.string)节点选择器
直接调用节点的名称就可以选择节点元素,再调用 string 属性就可以得到节点内的文本了,这种选择方式速度非常快。如果单个节点结构层次非常清晰,可以选用这种方式来解析。
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
<p class="story">Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1"><!-- Elsie --></a>,
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.head)
print(soup.p)获取属性
每个节点可能有多个属性,比如 id 和 class 等,选择这个节点元素后,可以调用 attrs 获取所有属性:
print(soup.p.attrs)
print(soup.p.attrs['name'])嵌套选择
html = """
<html><head><title>The Dormouse's story</title></head>
<body>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.head.title)
print(type(soup.head.title))
print(soup.head.title.string)关联选择
在做选择的时候,有时候不能做到一步就选到想要的节点元素,需要先选中某一个节点元素,然后以它为基准再选择它的子节点、父节点、兄弟节点等,这里就来介绍如何选择这些节点元素
html = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')
print(soup.p.contents)select(根据选择器选取指定内容)
标签选择器(a),类选择器(.dudu),id选择器(#lala),组合选择器(a, .dudu, #lala, .meme),层级选择器(div.dudu#lala.meme.xixi 表示下面好多级和 div>p>a>.lala 只能是下面一级 ),伪类选择器(不常用),属性选择器 (input[name=‘lala’])
htmls = """
<html>
<head>
<title>The Dormouse's story</title>
</head>
<body>
<p class="story">
Once upon a time there were three little sisters; and their names were
<a href="http://example.com/elsie" class="sister" id="link1" title="xl">
<span>Elsie</span>
</a>
<a href="http://example.com/lacie" class="sister" id="link2">Lacie</a>
and
<a href="http://example.com/tillie" class="sister" id="link3" rel="noopener noreferrer ">Tillie</a>
and they lived at the bottom of a well.
</p>
<p class="story">...</p>
"""案例
案例一(层级选择器,返回的都是列表)
soup.select('.story > a > span')[0].text
案例二(id选择器)
print(soup.select('#link1'))
案例三(提取属性)
soup.select('#link1')[0].attrs['href']
案例四 (属性选择器)
print(soup.select("input[type='password']"))
案例四(提取实际数据)
**url地址:**https://movie.douban.com/chart
ht = open('s.html',encoding='utf-8').read()
soup1 = BeautifulSoup(ht, 'lxml')
text = soup1.select('.recmd-content')
for i in text:
print(i.text)
# findAll使用
# 第一个参数是标签,第二个参数是类选择器
soup.findAll('a', class_="taest")
获取元素的文本
.get_text()
获取元素的属性
.attrs['name']HTTP请求模块
requests
基于urllib,不支持http2
安装:pip install requests
官网:http://docs.python-requests.org/zh_CN
1、实例
urllib 库中的 urlopen 方法实际上是以 GET 方式请求网页,而 requests 中相应的方法就是 get 方法
import requests
r = requests.get('https://www.baidu.com/')
print(type(r))
print(r.status_code) # 状态码
print(type(r.text))
print(r.text) # 提取文本
r.content # 非文本数据,字节流,r.content.decode()解码后就同r.text
print(r.cookies) # cookie信息
# 对于图片等其他内容,此时r.text.encode()编码后就同r.content
r = requests.post('http://httpbin.org/post')
r = requests.put('http://httpbin.org/put')
r = requests.delete('http://httpbin.org/delete')
r = requests.head('http://httpbin.org/get')
r = requests.options('http://httpbin.org/get')2、GET获取参数案例
import requests
data = {
'name': 'germey',
'age': 22
}
#params为查询字符串
r = requests.get("http://httpbin.org/get", params=data)
print(r.text)下面以 图片为例来看一下:
import requests
r = requests.get("http://qwmxpxq5y.hn-bkt.clouddn.com/hh.png")
print(r.text)
print(r.content)如果不传递 headers,就不能正常请求
但如果加上 headers 并加上 User-Agent 信息,那就没问题了:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
r = requests.get("https://mmzztt.com/, headers=headers)
print(r.text)3、post请求
import requests
data = {'name': 'germey', 'age': '22'}
# 通过data参数传参,请求时参数就会在form中,通过json参数传参请求时就会放在data中(此时数据是json流)
# 传data时,请求头headers中的Content-type为‘application/x-wwww-form-urlencoded’
# 传json时,请求头headers中的Content-type为‘application/json’
# data参数也可以传入json,使用json.dumps()
r = requests.post("http://httpbin.org/post", data=data)
print(r.text)测试网站:巨潮网络数据
import requests
url= 'http://www.cninfo.com.cn/data20/ints/statistics'
res = requests.post(url)
print(res.text)
发送请求后,得到的自然就是响应。在上面的实例中,我们使用 text 和 content 获取了响应的内容。此外,还有很多属性和方法可以用来获取其他信息,比如状态码、响应头、Cookies 等。示例如下:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
r = requests.get('http://www.jianshu.com',headers=headers)
print(type(r.status_code), r.status_code)
print(type(r.headers), r.headers)
print(type(r.cookies), r.cookies)
print(type(r.url), r.url)
print(type(r.history), r.history)状态码常用来判断请求是否成功,而 requests 还提供了一个内置的状态码查询对象 requests.codes,示例如下:
import requests
headers = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_4) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/52.0.2743.116 Safari/537.36'
}
r = requests.get('http://www.jianshu.com',headers=headers)
exit() if not r.status_code == requests.codes.ok else print('Request Successfully')那么,肯定不能只有 ok 这个条件码。下面列出了返回码和相应的查询条件:
# 信息性状态码
100: ('continue',),
101: ('switching_protocols',),
102: ('processing',),
103: ('checkpoint',),
122: ('uri_too_long', 'request_uri_too_long'),
# 成功状态码
200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\o/', '✓'),
201: ('created',),
202: ('accepted',),
203: ('non_authoritative_info', 'non_authoritative_information'),
204: ('no_content',),
205: ('reset_content', 'reset'),
206: ('partial_content', 'partial'),
207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),
208: ('already_reported',),
226: ('im_used',),
# 重定向状态码
300: ('multiple_choices',),
301: ('moved_permanently', 'moved', '\\o-'),
302: ('found',),
303: ('see_other', 'other'),
304: ('not_modified',),
305: ('use_proxy',),
306: ('switch_proxy',),
307: ('temporary_redirect', 'temporary_moved', 'temporary'),
308: ('permanent_redirect',
'resume_incomplete', 'resume',), # These 2 to be removed in 3.0
# 客户端错误状态码
400: ('bad_request', 'bad'),
401: ('unauthorized',),
402: ('payment_required', 'payment'),
403: ('forbidden',),
404: ('not_found', '-o-'),
405: ('method_not_allowed', 'not_allowed'),
406: ('not_acceptable',),
407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),
408: ('request_timeout', 'timeout'),
409: ('conflict',),
410: ('gone',),
411: ('length_required',),
412: ('precondition_failed', 'precondition'),
413: ('request_entity_too_large',),
414: ('request_uri_too_large',),
415: ('unsupported_media_type', 'unsupported_media', 'media_type'),
416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),
417: ('expectation_failed',),
418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),
421: ('misdirected_request',),
422: ('unprocessable_entity', 'unprocessable'),
423: ('locked',),
424: ('failed_dependency', 'dependency'),
425: ('unordered_collection', 'unordered'),
426: ('upgrade_required', 'upgrade'),
428: ('precondition_required', 'precondition'),
429: ('too_many_requests', 'too_many'),
431: ('header_fields_too_large', 'fields_too_large'),
444: ('no_response', 'none'),
449: ('retry_with', 'retry'),
450: ('blocked_by_windows_parental_controls', 'parental_controls'),
451: ('unavailable_for_legal_reasons', 'legal_reasons'),
499: ('client_closed_request',),
# 服务端错误状态码
500: ('internal_server_error', 'server_error', '/o\\', '✗'),
501: ('not_implemented',),
502: ('bad_gateway',),
503: ('service_unavailable', 'unavailable'),
504: ('gateway_timeout',),
505: ('http_version_not_supported', 'http_version'),
506: ('variant_also_negotiates',),
507: ('insufficient_storage',),
509: ('bandwidth_limit_exceeded', 'bandwidth'),
510: ('not_extended',),
511: ('network_authentication_required', 'network_auth', 'network_authentication')4、高级用法
github IP代理池开源源码:GitHub - jhao104/proxy_pool: Python爬虫代理IP池(proxy pool)
VPN软件:https://upnet218.vip/#/#reloaded
1、代理添加
proxy = {
'http' : 'http://183.162.171.78:4216',
}
# 返回当前IP
res = requests.get('http://httpbin.org/ip',proxies=proxy)
print(res.text)下面是使用代理的实例
首先在本机开了VPN,然后就可以像下面这样写了,29758估计就是VPN软件的端口
import requests
proxy = {
'https' : '127.0.0.1:29758',
}
# 返回当前IP
res = requests.get('https://twitter.com/typcn_com',headers={'user-agent':'agfdssedf'}, proxies=proxy, timeout=5)
print(res.text)2、快代理IP使用
打开后,默认http协议,返回格式选json,我的订单是VIP订单,所以稳定性选稳定,返回格式选json,然后点击生成链接,下面的API链接直接复制上。
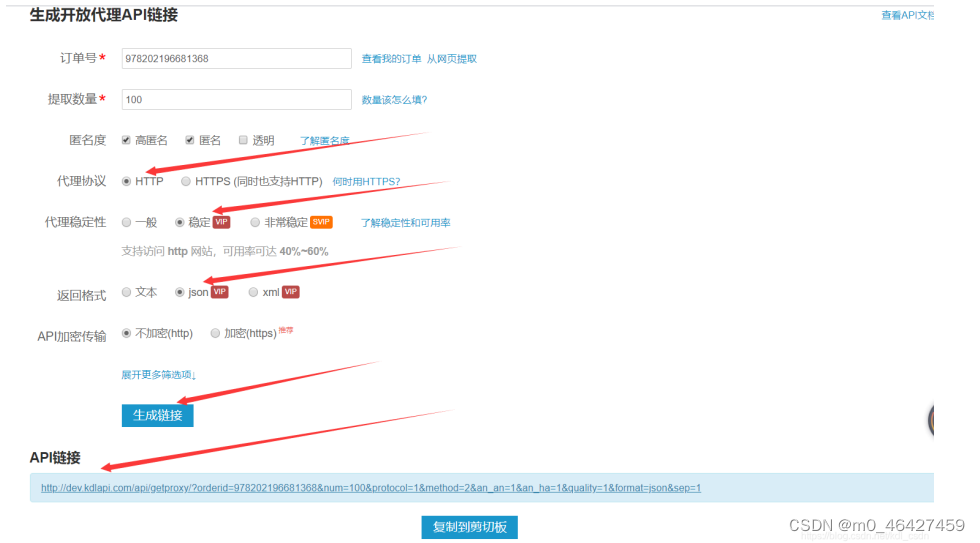 3、关闭警告
3、关闭警告
from requests.packages import urllib3
urllib3.disable_warnings()爬虫流程
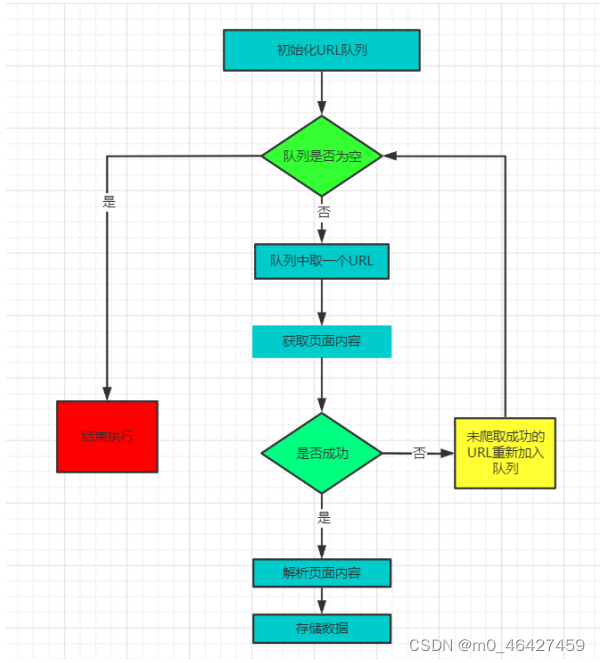
5、初级爬虫
# https://36kr.com/information/technology
import requests
from lxml import etree
def main():
# 1. 定义页面URL和解析规则
crawl_urls = [
'https://36kr.com/p/1328468833360133',
'https://36kr.com/p/1328528129988866',
'https://36kr.com/p/1328512085344642'
]
parse_rule = "//h1[contains(@class,'article-title margin-bottom-20 common-width')]/text()"
for url in crawl_urls:
# 2. 发起HTTP请求
response = requests.get(url)
# 3. 解析HTML
result = etree.HTML(response.text).xpath(parse_rule)[0]
# 4. 保存结果
print(result)
if __name__ == '__main__':
main()
6、全站采集
6.1 封装公共文件
# 在utils包下定义一个文件
# from retrying import retry
import requests
from retrying import retry
from requests.packages.urllib3.exceptions import InsecureRequestWarning
requests.packages.urllib3.disable_warnings(InsecureRequestWarning)
from lxml import etree
import random,time
#https://diag.qichacha.com/ 浏览器信息
# 用户代理基类
class FakeChromeUA:
first_num = random.randint(55, 62)
third_num = random.randint(0, 3200)
fourth_num = random.randint(0, 140)
os_type = [
'(Windows NT 6.1; WOW64)', '(Windows NT 10.0; WOW64)', '(X11; Linux x86_64)','(Macintosh; Intel Mac OS X 10_12_6)'
]
chrome_version = 'Chrome/{}.0.{}.{}'.format(first_num, third_num, fourth_num)
@classmethod
def get_ua(cls): # 随机生成ua
return ' '.join(['Mozilla/5.0', random.choice(cls.os_type), 'AppleWebKit/537.36','(KHTML, like Gecko)', cls.chrome_version, 'Safari/537.36'])
class Spiders(FakeChromeUA):
urls = []
@retry(stop_max_attempt_number=3, wait_fixed=2000)
def fetch(self, url, param=None,headers=None):
try:
if not headers:
headers ={}
headers['user-agent'] = self.get_ua()
else:
headers['user-agent'] = self.get_ua()
self.wait_some_time()
response = requests.get(url, params=param,headers=headers)
if response.status_code == 200:
response.encoding = 'utf-8'
return response
except requests.ConnectionError:
return
def wait_some_time(self):
time.sleep(random.randint(100, 300) / 1000)6.2 案例实践
# encoding: utf-8
from urllib.parse import urljoin
"""整站爬虫"""
import requests
from lxml import etree
from queue import Queue
from xl.base import Spiders
from pymongo import MongoClient
flt = lambda x :x[0] if x else None
class Crawl(Spiders):
base_url = 'https://36kr.com/'
# 种子URL
start_url = 'https://36kr.com/information/technology'
# 解析规则
rules = {
# 文章列表
'list_urls': '//div[@class="article-item-pic-wrapper"]/a/@href',
# 详情页数据
'detail_urls': '//div[@class="common-width margin-bottom-20"]//text()',
# 标题
'title': '//h1[@class="article-title margin-bottom-20 common-width"]/text()',
}
# 定义队列
list_queue = Queue()
def crawl(self, url):
"""首页"""
response =self.fetch(url)
list_urls = etree.HTML(response.text).xpath(self.rules['list_urls'])
# print(urljoin(self.base_url, list_urls))
for list_url in list_urls:
# print(urljoin(self.base_url, list_url)) # 获取url 列表信息
self.list_queue.put(urljoin(self.base_url, list_url))
def list_loop(self):
"""采集列表页"""
while True:
list_url = self.list_queue.get()
print(self.list_queue.qsize())
self.crawl_detail(list_url)
# 如果队列为空 退出程序
if self.list_queue.empty():
break
def crawl_detail(self,url):
'''详情页'''
response = self.fetch(url)
html = etree.HTML(response.text)
content = html.xpath(self.rules['detail_urls'])
title = flt(html.xpath(self.rules['title']))
print(title)
data = {
'content':content,
'title':title
}
self.save_mongo(data)
def save_mongo(self,data):
client = MongoClient() # 建立连接
col = client['python']['hh']
if isinstance(data, dict):
res = col.insert_one(data)
return res
else:
return '单条数据必须是这种格式:{"name":"age"},你传入的是%s' % type(data)
def main(self):
# 1. 标签页
self.crawl(self.start_url)
self.list_loop()
if __name__ == '__main__':
s = Crawl()
s.main()requests-cache
pip install requests-cache
能够对请求地址进行指纹编码,防止重复请求
在做爬虫的时候,我们往往可能这些情况:
-
网站比较复杂,会碰到很多重复请求。
-
有时候爬虫意外中断了,但我们没有保存爬取状态,再次运行就需要重新爬取。
**测试样例对比** import requests import time start = time.time() session = requests.Session() for i in range(10): session.get('http://httpbin.org/delay/1') print(f'Finished {i + 1} requests') end = time.time() print('Cost time', end - start) **测试样例对比2** import requests_cache import time start = time.time() session = requests_cache.CachedSession('demo_cache') for i in range(10): session.get('http://httpbin.org/delay/1') print(f'Finished {i + 1} requests') end = time.time() print('Cost time', end - start)
但是,刚才我们在写的时候把 requests 的 session 对象直接替换了。有没有别的写法呢?比如我不影响当前代码,只在代码前面加几行初始化代码就完成 requests-cache 的配置呢?
import time
import requests
import requests_cache
# 默认缓存到sqlite数据库
requests_cache.install_cache('demo_cache')
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time', end - start)
# 可以看到明显比之前时间少了很多这次我们直接调用了 requests-cache 库的 install_cache 方法就好了,其他的 requests 的 Session 照常使用即可。
刚才我们知道了,requests-cache 默认使用了 SQLite 作为缓存对象,那这个能不能换啊?比如用文件,或者其他的数据库呢?
自然是可以的。比如我们可以把后端换成本地文件,那可以这么做:
会生成一个文件夹,指纹信息会放到里面的.pkl文件中
requests_cache.install_cache('demo_cache', backend='filesystem')如果不想产生文件,可以指定系统缓存文件
requests_cache.install_cache('demo_cache', backend='filesystem', use_cache_dir=True)另外除了文件系统,requests-cache 也支持其他的后端,比如 Redis、MongoDB、GridFS 甚至内存,但也需要对应的依赖库支持,具体可以参见下表:
| Backend | Class | Alias | Dependencies |
| SQLite | SQLiteCache | 'sqlite' | |
| Redis | RedisCache | 'redis' | redis-py |
| MongoDB | MongoCache | 'mongodb' | pymongo |
| GridFS | GridFSCache | 'gridfs' | pymongo |
| DynamoDB | DynamoDbCache | 'dynamodb' | boto3 |
| Filesystem | FileCache | 'filesystem' | |
| Memory | BaseCache | 'memory' |
比如使用 Redis 就可以改写如下:
backend = requests_cache.RedisCache(host='localhost', port=6379)
requests_cache.install_cache('demo_cache', backend=backend)更多详细配置可以参考官方文档:Backends - requests-cache 0.9.4 documentation
当然,我们有时候也想指定有些请求不缓存,比如只缓存 POST 请求,不缓存 GET 请求,那可以这样来配置:
import time
import requests
import requests_cache
# 只缓存post请求
requests_cache.install_cache('demo_cache2', allowable_methods=['POST'])
start = time.time()
session = requests.Session()
for i in range(10):
session.get('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for get', end - start)
start = time.time()
for i in range(10):
session.post('http://httpbin.org/delay/1')
print(f'Finished {i + 1} requests')
end = time.time()
print('Cost time for post', end - start)当然我们还可以匹配 URL,比如针对哪种 Pattern 的 URL 缓存多久,则可以这样写:
# *是通配符,-1表示永久不缓存,30应该是指缓存30s
urls_expire_after = {'*.site_1.com': 30, 'site_2.com/static': -1}
requests_cache.install_cache('demo_cache2', urls_expire_after=urls_expire_after)好了,到现在为止,一些基本配置、过期时间配置、后端配置、过滤器配置等基本常见的用法就介绍到这里啦,更多详细的用法大家可以参考官方文档:User Guide - requests-cache 0.9.4 documentation。
数据存储
1 、JSON 文件存储
json解析网站:JSON在线解析及格式化验证 - JSON.cn
JSON,全称为 JavaScript Object Notation, 也就是 JavaScript 对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。本节中,我们就来了解如何利用 Python 保存数据到 JSON 文件。
1. 对象和数组
在 JavaScript 语言中,一切都是对象。因此,任何支持的类型都可以通过 JSON 来表示,例如字符串、数字、对象、数组等,但是对象和数组是比较特殊且常用的两种类型,下面简要介绍一下它们。
对象:它在 JavaScript 中是使用花括号 {} 包裹起来的内容,数据结构为 {key1:value1, key2:value2, ...} 的键值对结构。在面向对象的语言中,key 为对象的属性,value 为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
数组:数组在 JavaScript 中是方括号 [] 包裹起来的内容,数据结构为 ["java", "javascript", "vb", ...] 的索引结构。在 JavaScript 中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
2.数据写入规范
可以看到,中文字符都变成了 Unicode 字符,这并不是我们想要的结果。
为了输出中文,还需要指定参数 ensure_ascii 为 False,另外还要规定文件输出的编码:
import json
data = [{
'name': ' 王伟 ',
'gender': ' 男 ',
'birthday': '1992-10-18'
}]
with open('data.json', 'w', encoding='utf-8') as file:
file.write(json.dumps(data, indent=2, ensure_ascii=False))json.load和json.dump则是操作文件。
2、CSV 文件存储
CSV,全称为 Comma-Separated Values,中文可以叫作逗号分隔值或字符分隔值,其文件以纯文本形式存储表格数据。该文件是一个字符序列,可以由任意数目的记录组成,记录间以某种换行符分隔。每条记录由字段组成,字段间的分隔符是其他字符或字符串,最常见的是逗号或制表符。不过所有记录都有完全相同的字段序列,相当于一个结构化表的纯文本形式。它比 Excel 文件更加简洁,XLS 文本是电子表格,它包含了文本、数值、公式和格式等内容,而 CSV 中不包含这些内容,就是特定字符分隔的纯文本,结构简单清晰。所以,有时候用 CSV 来保存数据是比较方便的。本节中,我们来讲解 Python 读取和写入 CSV 文件的过程。
1. 写入
import csv
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
# 按行写入,三列四行
writer.writerow(['id', 'name', 'age'])
writer.writerow(['10001', 'Mike', 20])
writer.writerow(['10002', 'Bob', 22])
writer.writerow(['10003', 'Jordan', 21])首先,打开 data.csv 文件,然后指定打开的模式为 w(即写入),获得文件句柄,随后调用 csv 库的 writer 方法初始化写入对象,传入该句柄,然后调用 writerow 方法传入每行的数据即可完成写入。
如果想修改列与列之间的分隔符,可以传入 delimiter 参数,其代码如下:
writer = csv.writer(csvfile, delimiter=' ')此时会有多余空行,加入参数newline='',with open('','',newline='')
2.多行写入
调用 writerows 方法同时写入多行,此时参数就需要为二维列表,例如:
import csv
with open('data.csv', 'w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name', 'age'])
writer.writerows([['10001', 'Mike', 20], ['10002', 'Bob', 22], ['10003', 'Jordan', 21]])3.字典写入
用字典来表示。在 csv 库中也提供了字典的写入方式,示例如下:
import csv
with open('data.csv', 'w') as csvfile:
fieldnames = ['id', 'name', 'age']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'id': '10001', 'name': 'Mike', 'age': 20})
writer.writerow({'id': '10002', 'name': 'Bob', 'age': 22})
writer.writerow({'id': '10003', 'name': 'Jordan', 'age': 21})4. 爬虫采集入库
import httpx
res = httpx.get('https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1647605552864&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=python&pageIndex=2&pageSize=10&language=zh-cn&area=cn')
# 数据变字典格式
items = res.json()
item = items.get('Data')['Posts'] # 列表形式
data = []
for i in item:
title = i.get('RecruitPostName'),
times = i.get('LastUpdateTime'),
data.append([title[0],times[0]])
import csv
with open('data2.csv', 'w',encoding='utf-8') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['id', 'name'])
writer.writerows(data)3、关系型数据库存储
关系型数据库是基于关系模型的数据库,而关系模型是通过二维表来保存的,所以它的存储方式就是行列组成的表,每一列是一个字段,每一行是一条记录。表可以看作某个实体的集合,而实体之间存在联系,这就需要表与表之间的关联关系来体现,如主键外键的关联关系。多个表组成一个数据库,也就是关系型数据库。
关系型数据库有多种,如 SQLite、MySQL、Oracle、SQL Server、DB2 等。
1. 准备工作
在开始之前,请确保已经安装好了 MySQL 数据库并保证它能正常运行,而且需要安装好 Py MySQL 库。如果没有安装找班主任老师拿包
下载地址;MySQL :: Download MySQL Community Server
安装包:https://downloads.mysql.com/archives/get/p/23/file/mysql-5.7.9-winx64.zip
参考地址:Windows下MySQL的安装_CoderYYN的博客-CSDN博客_mysql windows
2. 连接数据库
安装:pip install pymysql
这里,首先尝试连接一下数据库。假设当前的 MySQL 运行在本地,用户名为 root,密码为 123456,运行端口为 3306。这里利用 PyMySQL 先连接 MySQL,然后创建一个新的数据库,名字叫作 spiders,代码如下:
import pymysql
db = pymysql.connect(host='localhost',user='root', password='123456', port=3306)
cursor = db.cursor() # 游标
cursor.execute('SELECT VERSION()')
data = cursor.fetchone()
print('Database version:', data)
cursor.execute("CREATE DATABASE spiders DEFAULT CHARACTER SET utf8")
db.close()3. 创建数据表
import pymysql
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'CREATE TABLE IF NOT EXISTS students (id VARCHAR(255) NOT NULL, name VARCHAR(255) NOT NULL, age INT NOT NULL, PRIMARY KEY (id))'
cursor.execute(sql)
db.close()4. 插入数据
插入、更新和删除操作都是对数据库进行更改的操作,而更改操作都必须为一个事务,所以这些操作的标准写法就是:
import pymysql
id = '20220315'
user = '菲菲'
age = 20
db = pymysql.connect(host='localhost', user='root', password='123456', port=3306, db='spiders')
cursor = db.cursor()
sql = 'INSERT INTO students(id, name, age) values(% s, % s, % s)'
try:
cursor.execute(sql, (id, user, age))
db.commit()
except:
db.rollback()
db.close()5. 字典数据插入
data = {
'id':'20220315',
'name': '菲菲',
'age': 20
}
keys = ', '.join(data.keys())
values = ', '.join(['% s'] * len(data)) # 先填充百分号,执行时再传入具体参数
sql = 'INSERT INTO students({keys}) VALUES ({values})'.format( keys=keys, values=values)
try:
if cursor.execute(sql, tuple(data.values())):
print('Successful')
db.commit()
except:
print('Failed')
db.rollback()
db.close()6. 爬虫数据采集入库
有时requests直接请求url是无法拿到网页数据的,因为有风控,后端到了nginx识别出是爬虫,就进行重定向了,这是一种反爬机制,像天猫淘宝等。
后端给前端响应数据的格式:
①数据直接嵌入html文档中,一起返回给前端,统称MVT架构(静态页面,用xpath解析)
②后端只返回json数据,前端通过JS拿数据加载到html文档中,统称MVC架构(动态页面,通过请求响应去获取)
API数据反爬虫,看请求头(get)和请求体/载荷(post)有没有类似乱码的数据,一般有就是有反爬,如api-key之类的,这种一般需要js逆向构造出这个参数。最后再确定cookie。
import requests
import pymysql
def conn_mysql():
db = pymysql.connect(host='localhost', user='root', password='', port=3306, db='xxxxx')
cursor = db.cursor()
return db,cursor
def get_huya_data():
url = 'https://www.huya.com/cache.php?m=LiveList&do=getLiveListByPage&gameId=1663&tagAll=0&page=3'
res = requests.get(url)
# 如果res.json() 给你报错了 先查看数据格式
try:
items = res.json()
data = items.get('data').get('datas')
datas = []
for it in data:
title = it.get('introduction')
nick = it.get('nick')
totalCount = it.get('totalCount')
# 如果想获取更过,根据对应的key value 进行提取就好
datas.append([title,nick,totalCount]) # 是不是列表嵌套列表 [[],[],[],[]]
save_mysql(datas)
except Exception as e:
print(e)
def save_mysql(data):
db, cursor = conn_mysql()
for d in data:
sql = 'insert into xx (title,nick,star) values (%s, %s, %s)'
try:
cursor.execute(sql, (d[0],d[1],d[2]))
db.commit()
except Exception as e:
print(e)
db.rollback()
if __name__ == '__main__':
get_huya_data()
4、非关系型数据库存储
1. MongoDB简介
MongoDB 是由 C++ 语言编写的非关系型数据库,是一个基于分布式文件存储的开源数据库系统,其内容存储形式类似 JSON 对象,它的字段值可以包含其他文档、数组及文档数组,非常灵活。在这一节中,我们就来看看 Python 3 下 MongoDB 的存储操作。
安装地址
链接:https://pan.baidu.com/s/1EirO3Obk8sI8uZhHJCcbTA
提取码:1234
2. 连接 MongoDB
连接 MongoDB 时,我们需要使用 PyMongo 库里面的 MongoClient。一般来说,传入 MongoDB 的 IP 及端口即可,其中第一个参数为地址 host,第二个参数为端口 port(如果不给它传递参数,默认是 27017)
import pymongo
# 如果是云服务的数据库 用公网IP连接
client = pymongo.MongoClient(host='localhost', port=27017)3. 指定数据库和表
db = client.test
collection = db['students'] # 都可以4. 插入数据
插入数据。对于 students 这个集合,新建一条学生数据,这条数据以字典形式表示:
student = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
result = collection.insert(student)
插入多条数据
student1 = {
'id': '20170101',
'name': 'Jordan',
'age': 20,
'gender': 'male'
}
student2 = {
'id': '20170202',
'name': 'Mike',
'age': 21,
'gender': 'male'
}
result = collection.insert([student1, student2])
print(result)5. 爬虫数据采集入库
import pymongo
client = pymongo.MongoClient(host='localhost', port=27017)
db = client.test
collection = db['students'] # 都可以
import httpx
def get_data():
res = httpx.get('https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1647605552864&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=python&pageIndex=2&pageSize=10&language=zh-cn&area=cn')
# 数据变字典格式
items = res.json()
item = items.get('Data')['Posts'] # 列表形式
for i in item:
if isinstance(i,dict):
collection.insert_one(i)
get_data()
有些数据返回是像上面这种有getLiveListJsonpCallback的,此时我们只要在请求url删除callback= getLiveListJsonpCallback即可直接返回json。
5、Elasticsearch 搜索引擎存储
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。Elasticsearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
重要特性:
-
分布式的实时文件存储,每个字段都被索引并可被搜索
-
实时分析的分布式搜索引擎
-
可以扩展到上百台服务器,处理PB级结构化或非结构化数据
基本概念:
索引(indices)-------------------Databases 数据库
类型(type)----------------------Table 数据表
文档(Document)---------------Row 行
字段(Field)---------------------Columns 列
详细说明:
| 概念 | 说明 |
|---|---|
| 索引库(indices) | indices是index的复数,代表许多的索引, |
| 类型(type) | 类型是模拟mysql中的table概念,一个索引库下可以有不同类型的索引,比如商品索引,订单索引,其数据格式不同。不过这会导致索引库混乱,因此未来版本中会移除这个概念 |
| 文档(document) | 存入索引库原始的数据。比如每一条商品信息,就是一个文档 |
| 字段(field) | 文档中的属性 |
| 映射配置(mappings) | 字段的数据类型、属性、是否索引、是否存储等特性 |
要注意的是:Elasticsearch 本身就是分布式的,因此即便你只有一个节点,Elasticsearch 默认也会对你的数据进行分片和副本操作,当你向集群添加新数据时,数据也会在新加入的节点中进行平衡。
1 安装服务端
地址:Download Elasticsearch | Elastic
包地址:https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.0-windows-x86_64.zip
注意: 解压ZIP文件,打开bin文件的 elasticsearch.bat
启动服务最好用powshell 使用管理员形式
2. 创建索引
安装客户端环境pip install elasticsearch==6.2.0
创建和删除索引库
from elasticsearch import Elasticsearch
es = Elasticsearch()
result = es.indices.create(index='news', ignore=400)
es.indices.delete(index='news')
print(result)
添加数据
from elasticsearch import Elasticsearch
es = Elasticsearch()
data = {
'title':'路漫漫其修远兮,吾将上下而求索',
'url':'www.123.com',
}
es.index(index="xl",doc_type="test_type",id=2,body=data)
查询数据
result = es.search(index="xl")
for item in result["hits"]["hits"]:
print(item["_source"])
3. 插入多条数据
data = [{
'title':'路漫漫其修远兮,吾将上下而求索',
'url':'www.123.com',
},{
'title':'路漫漫其修远兮,吾将上下而求索',
'url':'www.123.com',
},{
'title':'路漫漫其修远兮,吾将上下而求索',
'url':'www.123.com',
},{
'title':'路漫漫其修远兮,吾将上下而求索',
'url':'www.123.com',
}]
for da in data:
es.index(index='my_index2',doc_type='text',body=da)4. 查询
res = es.search(index='my_index2')
print(res)
过滤查询
dsl = {
'query':{
'match':{
'title':'路漫漫 求索'
}
}
}
res1 = es.search(index='my_index2',body=dsl)
print(res1)动态数据采集
1、简介
有时候我们在用 requests 抓取页面的时候,得到的结果可能和在浏览器中看到的不一样:在浏览器中可以看到正常显示的页面数据,但是使用 requests 得到的结果并没有。这是因为 requests 获取的都是原始的 HTML 文档,而浏览器中的页面则是经过 JavaScript 处理数据后生成的结果,这些数据的来源有多种,可能是通过 Ajax 加载的,可能是包含在 HTML 文档中的,也可能是经过 JavaScript 和特定算法计算后生成的。
对于第一种情况,数据加载是一种异步加载方式,原始的页面最初不会包含某些数据,原始页面加载完后,会再向服务器请求某个接口获取数据,然后数据才被处理从而呈现到网页上,这其实就是发送了一个 Ajax 请求。
照 Web 发展的趋势来看,这种形式的页面越来越多。网页的原始 HTML 文档不会包含任何数据,数据都是通过 Ajax 统一加载后再呈现出来的,这样在 Web 开发上可以做到前后端分离,而且降低服务器直接渲染页面带来的压力。
所以如果遇到这样的页面,直接利用 requests 等库来抓取原始页面,是无法获取到有效数据的,这时需要分析网页后台向接口发送的 Ajax 请求,如果可以用 requests 来模拟 Ajax 请求,那么就可以成功抓取了。
1.1 什么是ajax
Ajax,全称为 Asynchronous JavaScript and XML,即异步的 JavaScript 和 XML。它不是一门编程语言,而是利用 JavaScript 在保证页面不被刷新、页面链接不改变的情况下与服务器交换数据并更新部分网页的技术。
对于传统的网页,如果想更新其内容,那么必须要刷新整个页面,但有了 Ajax,便可以在页面不被全部刷新的情况下更新其内容。在这个过程中,页面实际上是在后台与服务器进行了数据交互,获取到数据之后,再利用 JavaScript 改变网页,这样网页内容就会更新了。
1.2 手写Ajax接口服务
框架简介
Flask是一个基于Python并且依赖于Jinja2模板引擎和Werkzeug WSGI 服务的一个微型框架WSGI :Web Server Gateway Interface(WEB服务网关接口),定义了使用python编写的web app与web server之间接口格式。
安装:pip install flask
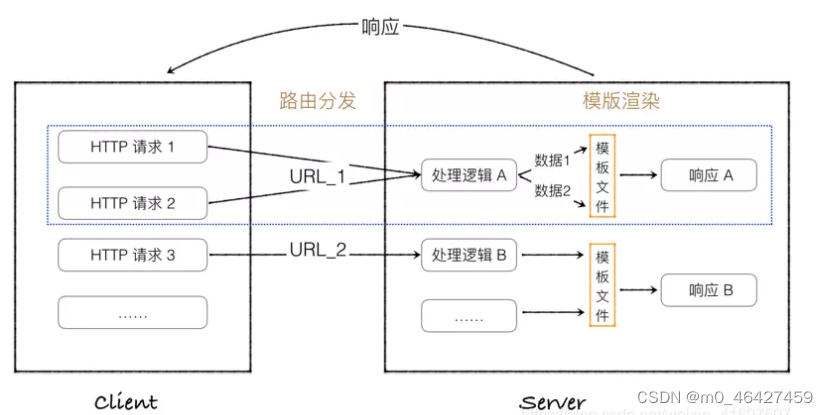
前端静态接口:
{#templates 下的index.html#}
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
</head>
<style>
td{
width: 65px;
text-align: center;
font-size: 18px;
}
</style>
<body>
<h1>大家晚上好</h1>
<table style="margin: 0 auto; border: 1px solid; margin-top: 100px">
<tr>
<th>序号</th>
<th>姓名</th>
<th>年龄</th>
</tr>
<tbody>
{% for i in data.data %}
<tr>
<td>{{ i.id }}</td>
<td>{{ i.name }}</td>
<td>{{ i.age }}</td>
</tr>
{% endfor %}
</tbody>
</table>
</body>
</html>pycharm开发html时使用Jinja2模板引擎自动补全
Setting-语言和框架-模板语言,将模板语言改为jinja2即可,然后输入{%时pycharm会自动补全。
后端静态接口设计
from flask import Flask,render_template,jsonify
# 实例
app = Flask(__name__)
#静态响应,渲染完html后将整个html返回前端
@app.route('/api') # 路由,也可以程序api
def index():
data = []
# 这里面的数据 应该是 来自于 数据库
for i in range(1,7):
data.append(
{'id':i, 'name': '夏'+str(i), 'age':18+i}
)
# 构造数据格式
content = {
'status': 0,
'data':data
}
print(content)
# flask 框架 返回数据给前端
return render_template('index.html',data=content)
if __name__ == '__main__':
app.run()后端动态响应接口
@app.route('/api')
def index():
data = []
# 这里面的数据 应该是 来自于 数据库
for i in range(1,7):
data.append(
{'id':i, 'name': '夏'+str(i), 'age':18+i}
)
# 构造数据格式
content = {
'status': 0,
'data':data
}
return jsonify(data=content)<script src="http://www.ccmsy.com/static/js/jquery-1.8.3.min.js"></script>
<script>
load_data();
function load_data() {
$.ajax({
url: '/api',
type: "GET",
dataType: 'json'
})
.done(function (res) {
{#响应成功时调用的内容#}
console.log(res.data.data)
res.data.data.forEach(function (info) {
let content = `
<tr>
<td>${info.id}</td>
<td>${info.name}</td>
<td>${info.age}</td>
</tr>
`
$("#data").append(content)
})
})
}
</script>2、基本原理
初步了解了 Ajax 之后,我们再来详细了解它的基本原理。发送 Ajax 请求到网页更新的这个过程可以简单分为以下 3 步:
-
发送请求
-
解析内容
-
渲染网页
3、数据采集案例
爬虫工具:爬虫工具库-spidertools.cn
如可以对请求头转成对应的json类型格式
3.1 Ajax 数据加载实践
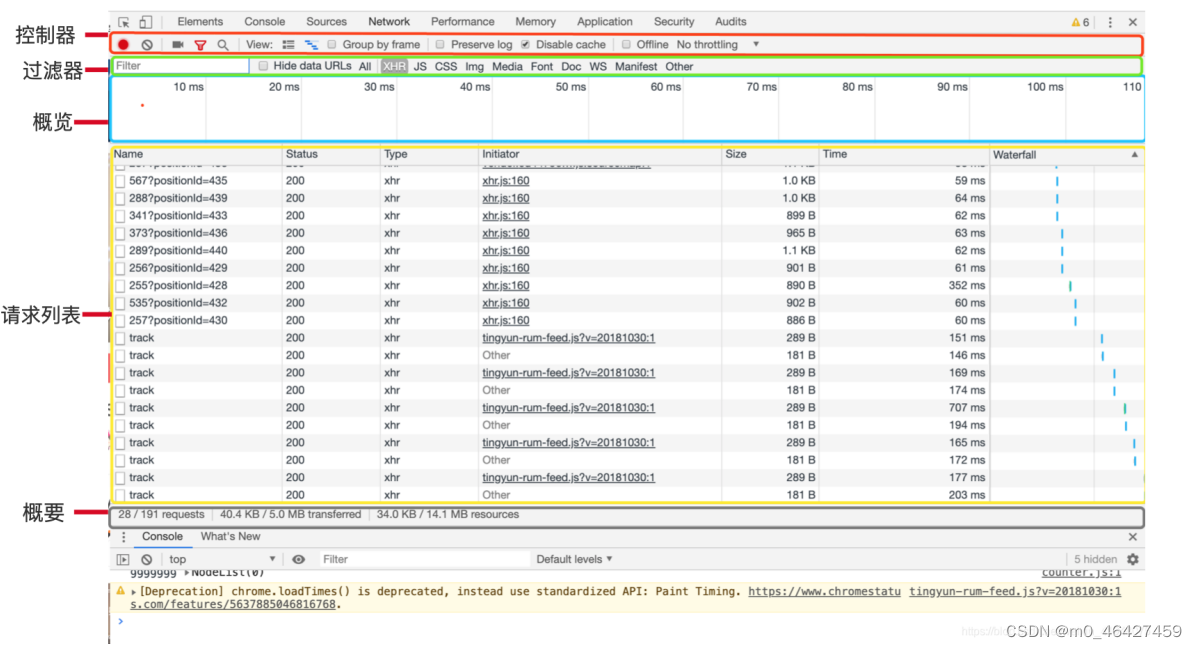
Ajax 其实有其特殊的请求类型,其 Type 为 xhr,这就是一个 Ajax 请求。用鼠标点击这个请求,可以查看这个请求的详细信息。
示例网站:
https://danjuanapp.com/rank/performance
http://www.cninfo.com.cn/new/commonUrl?url=disclosure/list/notice#szseGem
https://cs.lianjia.com/
3.2 数据采集实战
采集地址:长沙房产网_长沙房地产_长沙房产门户(长沙链家网)
import requests
from loguru import logger
import json
class Spdier_data():
def __init__(self):
self.headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Accept-Language": "zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7,zh-TW;q=0.6",
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"Pragma": "no-cache",
"Referer": "https://cs.fang.lianjia.com/loupan/pg2/",
"Sec-Fetch-Dest": "empty",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36",
"X-Requested-With": "XMLHttpRequest",
"sec-ch-ua": "^\\^",
"sec-ch-ua-mobile": "?0",
"sec-ch-ua-platform": "^\\^Windows^^"
}
def http(self,url,params):
res = requests.get(url,params=params,headers=self.headers)
if res.status_code == 200:
return res
def get_data(self,url,params):
response = self.http(url=url,params=params)
items = response.json()
lists = items.get('data').get('list')
for i in lists:
item = {}
item['address'] = i.get('address')
item['city_name'] = i.get('city_name')
item['decoration'] = i.get('decoration')
item['district'] = i.get('district')
item['title'] = i.get('title')
item['show_price_info'] = i.get('show_price_info')
logger.info(json.dumps(item))
self.save_data(item)
def save_data(self,data):
with open('data.json','a',encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
f.write(',')
def run(self):
for i in range(1,3):
url = "https://cs.fang.lianjia.com/loupan/pg{}/".format(str(i))
params = {
"_t": "1"
}
self.get_data(url,params)
if __name__ == '__main__':
Spdier_data().run()4、数据去重算法
数据去重算法使用redis进行承载
# encoding: utf-8
去重方式
redis 去重 集合类型
布隆算法
2种方式
URL去重 针对采集的地址
data去重 针对某一个数据
redis 默认会进行encode 编码 获取数据要解码 decode
'''
import requests
from base_request import Spiders
from lxml import etree
from loguru import logger
import time
import redis
client = redis.Redis()
import hashlib
class Crawl(Spiders):
def __init__(self):
self.url = 'https://36kr.com/information/web_news/latest/'
self.maps = lambda x:x[0] if x else x
def ma5_data(self,content): # 换成md5格式记录已爬取过的
m = hashlib.md5()
m.update(content.encode())
return m.hexdigest()
def crawl(self):
res = self.fetch(self.url)
html = etree.HTML(res.text)
obj = html.xpath('//div[@class="information-flow-list"]/div')
for i in obj:
title = self.maps(i.xpath('.//p[@class="title-wrapper ellipsis-2"]/a/text()'))
xxx = self.ma5_data(title) # 对数据进行压缩 减少内存损耗
tag = client.sadd('xialuo3',xxx) # 返回值 0 1
if tag:
# 表示数据可以继续爬(没入库没爬过) 对数据进行入库 logger = print
logger.info('可以入库{}'.format(title))
else:
time.sleep(5)
logger.info('休息5秒钟')
self.crawl()
def save(self,data):
with open('data.txt','a',encoding='utf-8') as x:
x.write(data)
x.write('\r\n')
def run(self):
while True:
logger.info('开始启动爬虫')
self.crawl()
if __name__ == '__main__':
Crawl().run()多任务提速
1、多线程
多线程都是关于功能的并发执行。而异步编程是关于函数之间的非阻塞执行,我们可以将异步应用于单线程或多线程当中。多线程是与具体的执行者相关的,而异步是与任务相关的。
1.1 并发和并行
说到多进程和多线程,这里就需要再讲解两个概念,那就是并发和并行。我们知道,一个程序在计算机中运行,其底层是处理器通过运行一条条的指令来实现的。
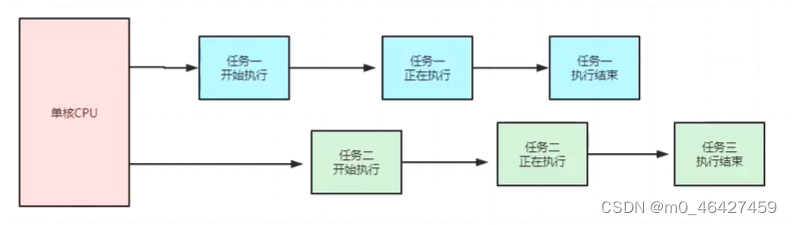
并发,英文叫作 concurrency。它是指同一时刻只能有一条指令执行,但是多个线程的对应的指令被快速轮换地执行。比如一个处理器,它先执行线程 A 的指令一段时间,再执行线程 B 的指令一段时间,再切回到线程 A 执行一段时间。
由于处理器执行指令的速度和切换的速度非常非常快,人完全感知不到计算机在这个过程中有多个线程切换上下文执行的操作,这就使得宏观上看起来多个线程在同时运行。但微观上只是这个处理器在连续不断地在多个线程之间切换和执行,每个线程的执行一定会占用这个处理器一个时间片段,同一时刻,其实只有一个线程在执行。
并行,英文叫作 parallel。它是指同一时刻,有多条指令在多个处理器上同时执行,并行必须要依赖于多个处理器。不论是从宏观上还是微观上,多个线程都是在同一时刻一起执行的。
并行只能在多处理器系统中存在,如果我们的计算机处理器只有一个核,那就不可能实现并行。而并发在单处理器和多处理器系统中都是可以存在的,因为仅靠一个核,就可以实现并发。
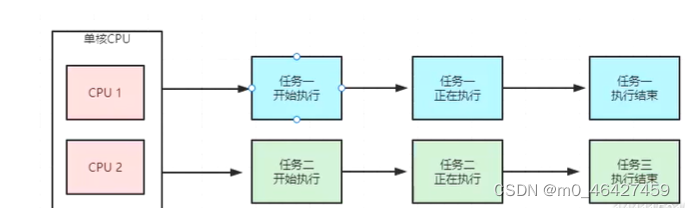
总结:当系统有一个以上 CPU 时,则线程的操作有可能非并发。当一个 CPU 执行一个线程时,另一个 CPU 可以执行另一个线程,两个线程互不抢占 CPU 资源,可以同时进行,这种方式我们称之为并行(Parallel)
单线程
import requests,time
def test(url):
res = requests.get(url)
return res
if __name__ == '__main__':
start = time.time()
url = 'http://www.baidu.com'
for i in range(10):
test(url)
res = time.time() - start
print(res,'单线程')
——————————————————————————
0.31724119186401367 单线程
多线程测试
import requests,time,threading
def tests(url,i):
print(i)
res = requests.get(url)
return res
if __name__ == '__main__':
start = time.time()
url = 'http://www.baidu.com'
t = []
for i in range(10):
thread = threading.Thread(target=tests, args=(url,i))
t.append(thread)
thread.start()
for i in t:
i.join()
res = time.time() - start
print(res,'多线程')
——————————————————————————————————
0.05385732650756836 多线程1.2 线程样例
def target(second):
print(f'Threading {threading.current_thread().name} is running')
print(f'Threading {threading.current_thread().name} sleep {second}s')
time.sleep(second)
print(f'Threading {threading.current_thread().name} is ended')
print(f'Threading {threading.current_thread().name} is running')
for i in [1, 5]:
thread = threading.Thread(target=target, args=[i])
thread.start()
print(f'Threading {threading.current_thread().name} is ended')
————————————————————————————————————————————————————————
Threading MainThread is running
Threading Thread-1 is running
Threading Thread-1 sleep 1s
Threading Thread-2 is runningThreading MainThread is ended
Threading Thread-2 sleep 5s
Threading Thread-1 is ended
Threading Thread-2 is ended可以发现这里主线程先结束了,而子线程还在继续跑,可能会造成资源回收问题,因此一般加一个join等待。
1.3 线程等待
join()
t = []
for i in [1, 5]:
thread = threading.Thread(target=target, args=[i])
t.append(thread)
thread.start()
for i in t:
i.join()
print(f'Threading {threading.current_thread().name} is ended')1.4 线程池
线程池,是一种线程的使用模式,它为了降低线程使用中频繁的创建和销毁所带来的资源消耗与代价。通过创建一定数量的线程,让他们时刻准备就绪等待新任务的到达,而任务执行结束之后再重新回来继续待命
from concurrent.futures import ThreadPoolExecutor
import requests
def crawl(url):
res =requests.get(url)
print(res)
if __name__ == '__main__':
base_url = 'https://cs.fang.lianjia.com/loupan/pg{}/?_t=1/'
start = time.time()
with ThreadPoolExecutor(10) as f: # 线程池只有10个线程
for i in range(1,15): # 发出15个请求
f.submit(crawl,url=base_url.format(i))
end_time = time.time() - start
print(end_time,'结束时间')
————————————————————————————————————————————
1.0494952201843262 结束时间进程虚拟内存一般是2G,1个线程栈一般是1MB,所以最多可以有2048个线程。
缺点
某个线程想要执行,必须先拿到 GIL,我们可以把 GIL 看作是通行证,并且在一个 Python 进程中,GIL 只有一个。拿不到通行证的线程,就不允许执行。这样就会导致,即使是多核条件下,一个 Python 进程下的多个线程,同一时刻也只能执行一个线程。
1.5 多线程采集案例
import requests
import os
import json
import threading
from lxml import etree
import time
h=[]
s=time.time()
def pa(j):
num = j['ename'] #从data中获取ename的值
name = j['cname']
res2 = requests.get("https://pvp.qq.com/web201605/herodetail/{}.shtml".format(num))
res2_decode = res2.content.decode('gbk') # 返回相应的html页面,字符串格式,解码为utf-8
_element = etree.HTML(res2_decode) # 将html转换为_Element对象,可以方便的使用getparent()、remove()、xpath()等方法
element_img = _element.xpath('//div[@class="pic-pf"]/ul/@data-imgname')
#print(element_img)
name_img = element_img[0].split('|') # 去掉字符串中的|字符,并分割
#print(name_img)
for i in range(0,10):
res1=requests.get("https://game.gtimg.cn/images/yxzj/img201606/skin/hero-info/{0}/{0}-bigskin-{1}.jpg".format(num,i+1)) #返回响应包
if res1.status_code == 200:
aa=name_img[i].find('&')
#print(aa)
bb=name_img[i][:aa]
res_img=res1.content #把相应包内容转换为2进制
a = './王者荣耀/' + str(name)
b='./王者荣耀/'+str(name)+'/'+bb+'.jpg'
if not os.path.exists('./王者荣耀/'):
os.mkdir('./王者荣耀/')
if not os.path.exists(a):
os.mkdir(a)
with open(b,"wb") as f: #创建一个名为1.jpg的图片
f.write(res_img) #把响应包2进制内容写入到1.jpg中
print(name, bb)
else:
break
def duo():
response=requests.get('https://pvp.qq.com/web201605/js/herolist.json')
data=json.loads(response.text)
#print(data)
# 这里是每一个英雄开一个线程
for j in data:
t=threading.Thread(target=pa,args=(j,))
t.start()
h.append(t)
# 等待所有线程运行完毕
for k in h:
k.join()
if __name__=='__main__':
duo()
g=time.time()
print("用时:",g-s,"秒")1.6 线程池采集
from concurrent.futures.thread import ThreadPoolExecutor
import time
import requests
from pymongo import MongoClient
def save_one_data(data: dict): # 保存数据
global collection
collection.insert_one(data)
def download_one_page(data: dict): # 请求一页数据
url = 'http://www.xinfadi.com.cn/getPriceData.html'
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/102.0.0.0 Safari/537.36',
'referer': 'http://www.xinfadi.com.cn/priceDetail.html'
}
resp = requests.post(url=url, headers=headers, data=data)
if resp.status_code == 200:
for i in resp.json().get('list'):
save_one_data(i)
def download_pages(page_start: int, page_end: int, page_limit: int = 20):
with ThreadPoolExecutor(100) as t: # 线程池最多有100个线程
for i in range(page_start, page_end + 1):
data = {
'limit': f'{page_limit}',
'current': f'{i}',
'pubDateStartTime': '',
'pubDateEndTime': '',
'prodPcatid': '',
'prodCatid': '',
'prodName': ''
}
t.submit(download_one_page,data)
if __name__ == '__main__':
start_time = time.time()
mongo = MongoClient(host='localhost', port=27017)
collection = mongo['spider']['grain_price']
download_pages(page_start=1, page_end=100, page_limit=20)
end_time = time.time()
print(f'总耗时{end_time - start_time}s')2、多进程
参考文档:multiprocessing --- 基于进程的并行 — Python 3.10.5 文档
Python 中的多线程是不能很好发挥多核优势的,如果想要发挥多核优势,最好还是使用多进程。
进程是系统进行资源分配和调度的一个独立单位。
IO密集型如爬虫,此时用多线程就有用。但对于CPU密集型如模型训练等,要提速一般得通过多进程来实现。
2.1 进程样例
import multiprocessing
def process(index):
print(f'Process: {index}')
if __name__ == '__main__':
for i in range(5):
p = multiprocessing.Process(target=process, args=(i,))
p.start()2.2 进程等待
如果主进程不等待子进程结束而先结束,会导致子进程变成僵尸进程,没人管,此时会造成资源浪费。
import multiprocessing
def process1(index):
print(f'Process: {index}')
if __name__ == '__main__':
processes = []
for i in range(2,5):
p = multiprocessing.Process(target=process1, args=(i,))
processes.append(p)
p.daemon = True # 进程的守护标志,一个布尔值。这必须在 start() 被调用之前设置。
p.start()
for j in processes:
j.join(1)2.3 进程池
控制并发数量
from multiprocessing import Pool
import requests
def scrape(url):
try:
requests.get(url)
print(f'URL {url} Scraped')
except requests.ConnectionError:
print(f'URL {url} not Scraped')
if __name__ == '__main__':
pool = Pool(processes=3)
urls = [
'https://www.baidu.com',
'http://www.meituan.com/',
'http://blog.csdn.net/',
'http://xxxyxxx.net'
]
pool.map(scrape, urls)
pool.close()
——————————————————————————————————————————
URL https://www.baidu.com Scraped
URL http://xxxyxxx.net not Scraped
URL http://blog.csdn.net/ Scraped
URL http://www.meituan.com/ Scraped2.4 多进程案例
使用多进程采集机车数据,30页的数据总耗时是1.7秒
from multiprocessing import Pool
import multiprocessing
from lxml import etree
import requests
maps1 = lambda x: x[0] if x else x
def request(url):
headers= {
'user-agent':'123123',
'Cookie': 'BAIDU_SSP_lcr=https://www.baidu.com/link?url=MHEtdkDrZiaQ_Fo9zGor7bR9k3gFykSpTtWIpPmJXZvJWVEzlFA6DL83dC7m-1qv&wd=&eqid=ee92cf0700010b5000000006622f2938; Hm_lvt_8b80e9af8bc9476c3b2068990922a408=1647257918; ASPSESSIONIDQWDRCSDC=BLCMBEEDPAPHFAICHNJFGGNA; countsql=%5BS%5Fchexi%5Dwhere+1%3D1; fenyecounts=1183; ASPSESSIONIDQWBTBSDD=BHOENMODOFLOPJIFEHAMEHPC; Hm_lpvt_8b80e9af8bc9476c3b2068990922a408=1647326383',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36'
}
res = requests.get(url,headers=headers)
if res.status_code == 200:
res.encoding = 'gb2312'
parse(res)
def parse_xpath(obj,tag):
html = etree.HTML(obj)
text = html.xpath(tag)
return text
def parse(res):
url = '//ul[@class="goods_list"]/li'
items = parse_xpath(res.text,url)
for item in items:
title = maps1(item.xpath('./p[@class="name"]/a/@title'))
price = maps1(item.xpath('./p[@class="price_wrap"]/span/text()'))
print({'品牌':title,'价格':price})
print('='*50)
def run():
import time
s = time.time()
url = 'https://www.2smoto.com/pinpai/'
res = requests.get(url)
res.encoding = 'gb2312'
html = maps1(parse_xpath(res.text,"//a[contains(text(),'尾页')]/@href"))
count = html.split('=')[-1] # 获取总共页数
# 网站很简单,没有反爬,也不是api的就是一个静态页面,直接xpath解析
# https://www.2smoto.com/pinpai.asp?ppt=&slx=0&skey=&page=2
cpu_count = multiprocessing.cpu_count() # 获取本机cpu数
print("CPU 核心数量是:", cpu_count)
pool = Pool(processes=cpu_count) # 8个进程
for i in range(1,int(count)+1):
url = 'https://www.2smoto.com/pinpai.asp?ppt=&slx=0&skey=&page={}'.format(i)
pool.apply_async(request, (url,))
pool.close() # 关闭进程池,关闭之后,不能再向进程池中添加进程
pool.join() # 当进程池中的所有进程执行完后,主进程才可以继续执行。
print('程序耗时{}'.format(time.time() - s))
if __name__ == '__main__':
run()
上一次进程池我们用的是pool.map,这里用的是pool.apply_async,两者区别?
3、异步携程
我们知道爬虫是 IO 密集型任务,比如如果我们使用 requests 库来爬取某个站点的话,发出一个请求之后,程序必须要等待网站返回响应之后才能接着运行,而在等待响应的过程中,整个爬虫程序是一直在等待的,实际上没有做任何的事情。对于这种情况我们有没有优化方案呢?
基本概念
异步
为完成某个任务,不同程序单元之间过程中无需通信协调,也能完成任务的方式,不相关的程序单元之间可以是异步的。
例如,爬虫下载网页。调度程序调用下载程序后,即可调度其他任务,而无需与该下载任务保持通信以协调行为。不同网页的下载、保存等操作都是无关的,也无需相互通知协调。这些异步操作的完成时刻并不确定。
同步
不同程序单元为了完成某个任务,在执行过程中需靠某种通信方式以协调一致,我们称这些程序单元是同步执行的。
阻塞
阻塞状态指程序未得到所需计算资源时被挂起的状态。程序在等待某个操作完成期间,自身无法继续处理其他的事情,则称该程序在该操作上是阻塞的。
非阻塞
程序在等待某操作过程中,自身不被阻塞,可以继续处理其他的事情,则称该程序在该操作上是非阻塞的。
-
同步/异步关注的是消息通信机制 (synchronous communication/ asynchronous communication) 。
-
阻塞/非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
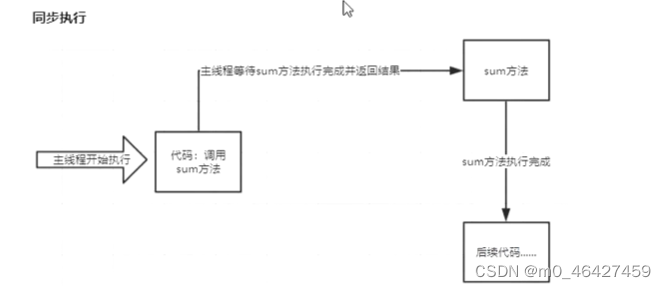
注:同步执行当调用方法执行完成后并返回结果,才能执行后续代码
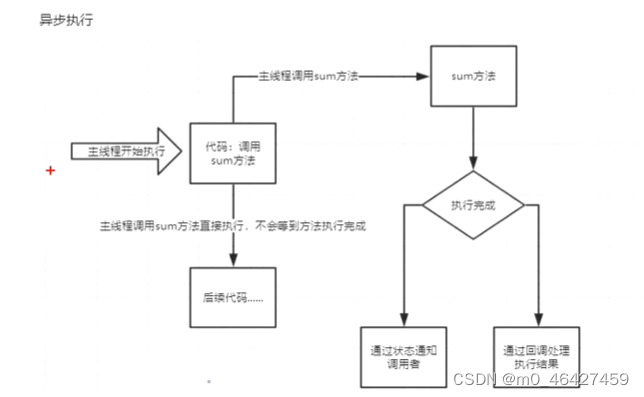
3.1 概念
安装:pip install aiohttp
aiohttp 是一个基于 asyncio 的异步 HTTP 网络模块,它既提供了服务端,又提供了客户端。其中我们用服务端可以搭建一个支持异步处理的服务器
async 用来声明一个函数为异步函数
await 用来声明程序挂起,比如异步程序执行到某一步时需要等待的时间很长,就将此挂起,去执行其他的异步程序
同步异步实例
同步
import time
def test1():
print('test1 start')
time.sleep(3)
print('test1 end')
def test2():
print('test2 start')
time.sleep(3)
print('test2 end')
if __name__ == '__main__':
start = time.time()
test1()
test2()
print(time.time() - start)
——————————————————————————————————
test1 start
test1 end
test2 start
test2 end
6.018089532852173
异步
import time
import asyncio
async def test1():
print('test1 start')
time.sleep(3)
print('test1 end')
async def test2():
print('test2 start')
time.sleep(3)
print('test2 end')
if __name__ == '__main__':
start = time.time()
f1 = test1()
f2 = test2()
tasks = [f1, f2] # 放到一个任务列表中
asyncio.run(asyncio.wait(tasks))
print(time.time() - start)
————————————————————————————————
test1 start
test1 end
test2 start
test2 end
6.058378458023071
# 还是6s,跟之前差不多,说明变成同步了,这是因为time.sleep是同步,因此异步遇到同步仍会变成同步。所以需要将其挂起,用await,并且使用异步的sleep
此处是异步非阻塞式
将time.sleep改成await asyncio.sleep(3),其他地方不变,重新运行得到:
test1 start
test2 start
test1 end
test2 end
3.0039594173431396
3.2 同步发100次请求
import time
import httpx
def main():
with httpx.Client() as client:
for i in range(100):
res = client.get('https://www.baidu.com')
print(f'第{i + 1}次请求,status_code = {res.status_code}')
if __name__ == '__main__':
start = time.time()
main()
end = time.time()
print(f'同步发送100次请求,耗时:{end - start}')
——————————————————————————————————————————————————————————————
同步发送100次请求,耗时:2.5904803276062013.3 异步发100次请求
import asyncio
import time
import httpx
async def req(client, i):
res = await client.get('https://www.baidu.com') # 发起请求有耗时,因此挂起
print(f'第{i + 1}次请求,status_code = {res.status_code}')
return res
async def main():
async with httpx.AsyncClient() as client:
task_list = [] # 任务列表
for i in range(100):
res = req(client, i)
task = asyncio.create_task(res) # 创建任务
task_list.append(task)
await asyncio.gather(*task_list) # 收集任务
if __name__ == '__main__':
start = time.time()
asyncio.run(main())
end = time.time()
print(f'异步发送100次请求,耗时:{end - start}')
——————————————————————————————————————————————————————————
异步发送100次请求,耗时:0.55882263183593753.4 异步案例,爬取视频
扩展1:you-get下载视频
先pip install you-get,然后在终端you-get url 即可
扩展2:ffmpeg,下载合并视频等操作,直接传m3u8文件即可,能下载但应该不能解密
参考:利用ffmepg下载在线视频文件_科研咸鱼Pin的博客-CSDN博客_ffmpeg下载网页视频
主要在命令行中用这条指令
ffmpeg -protocol_whitelist "file,https,crypto,tcp,http,tls" -i index.m3u8 -c copy out.mp4
# index.m3u8就是传入的参数,out.mp4是输出的结果
使用异步下载视频,提高效率。TS流
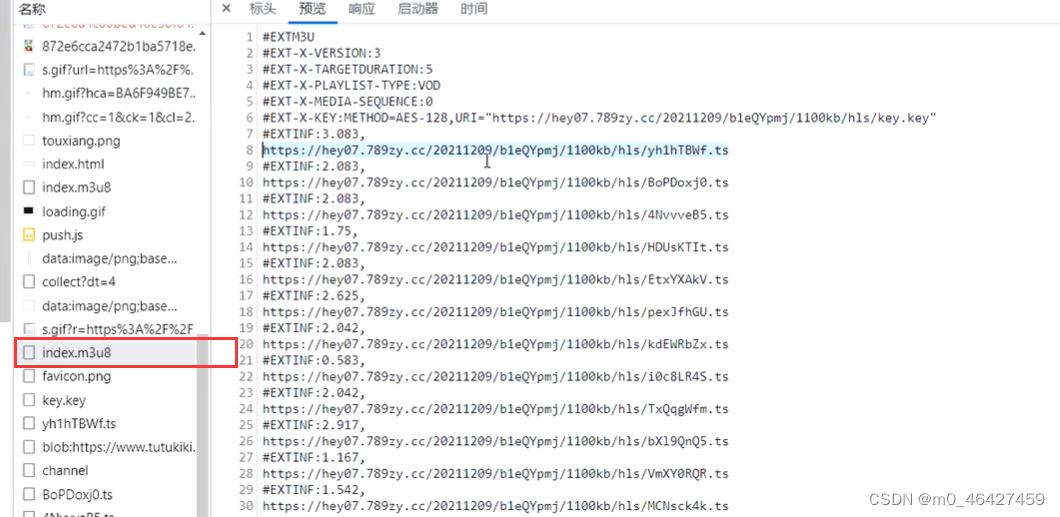
m3u8记录了很多ts流,每个ts就是一小片段的视频。同时上面还写了加密算法以及加密文件,直接下载一个ts是无法打开的,因为还要解密。
流程:
- 请求m3u8文件,拿到描述信息
- 提取ts文件
- 解密ts文件
- 合并ts文件,得到一个完整的视频
技术难点:
- 下载的TS需要解密
- 视频合并,需要按照m3u8的描述信息按顺序合并
这里要注意一点,Crypto这个包安装应该用:pip install pycryptodome
from Crypto.Util.Padding import pad
import asyncio,aiohttp,aiofiles
import os
import requests
from Crypto.Cipher import AES
def request():
# https://www.joonsen.com/vodplay/63111-1-1.html 提取的视频
res =requests.get("https://v4.cdtlas.com/20211209/b1eQYpmj/1100kb/hls/index.m3u8")
if res.status_code == 200:
with open('index.m3u8','w') as f:
f.write(res.text)
async def read():
# 从文件中提取ts的链接
with open('index.m3u8', mode='r', encoding='utf-8') as f:
task = [] # 异步任务列表
for index, line in enumerate(f): # index是为了标记ts文件的顺序
if line.startswith('#'):
continue
line = line.strip()
ts_name = "%(index)02d" % {'index': index} + '.ts' # 构造文件名
task.append(down_ts(line,ts_name))
await asyncio.wait(task)
async def down_ts(ts,name):
# 异步下载每一个ts文件,参数ts是ts文件的url,name是要保存的文件名
async with aiohttp.ClientSession() as session:
async with session.get(ts) as res:
if os.path.exists('ts1') is False: # 创建文件夹
os.mkdir('ts1')
async with aiofiles.open('./ts1/' + name, mode='wb') as f: # 写入内容,也是异步写入因为打开关闭文件可能会等待IO
await f.write(await res.content.read())
async def des_tsI():
# 异步解密所有ts文件
'''
from Crypto.Util.Padding import pad
encrypted_data = pad(encrypted_data, 16)
:return:
'''
try:
# 第一个参数key就是m3u8中记录的key文件中的秘钥,模式一般选CBC,IV则补齐16位
cipher = AES.new(b"04fff35febefbf9c", AES.MODE_CBC, IV=b'0000000000000000')
path = os.path.join(os.getcwd() , 'ts1') # 获取存放ts文件的文件夹的路径
for p in os.listdir(path): # 遍历所有ts文件
async with aiofiles.open(os.path.join(path,p),'rb') as file: # 异步读取ts文件
async with aiofiles.open('./news/' + p, "wb") as fp: # 异步保存文件
content = await file.read() # 读取时是个耗时任务,因此通过await挂起
# 获取长度,使用AES加密,加密字符串必须是16的倍数,不是16倍数可能报错,因为他是一个分组算法
encrypted_data_len = len(content)
# 判断当前的数据长度是不是16的倍数
if encrypted_data_len % 16 != 0:
# 把长度不是16的倍数的显示出来
# 补齐变为16的倍数
content = pad(content, 16)
plain_data = cipher.decrypt(content) # 补齐后再解密
if os.path.exists('news') is False: # 这里创建文件夹是不是应该放在前面?
os.mkdir('news')
await fp.write(plain_data) # 写入也是个耗时操作,通过await挂起
except Exception as e:
print(e)
#合并的时候名字要有规律,从前往后排
def merge_file():
path = os.path.join(os.getcwd(), 'ts1')
# 第二种方式 构造合并
ts_file = os.listdir(path)
# 对视频进行排序,将文件名转成int再排序
ts_file.sort(key=lambda x: int(x.split('.')[0]))
shell_str = '+'.join(ts_file)
print(shell_str)
names = 'xxxx.mp4'
# # # 删除ts视频
strs = 'copy /b ' + shell_str + f' {names}' + '\n' + 'del *.ts'
# # # 不删除ts视频
# strs = 'copy /b ' + shell_str + f' {names}'
f = open('news/' + "combined.cmd", 'w') # 保存成cmd文件打开即可合并
f.write(strs)
f.close()
def run():
# 获取m3u8文件
request()
# 下载TS文件
asyncio.get_event_loop().run_until_complete(read())
# 解密操作
print('执行解密操作')
asyncio.get_event_loop().run_until_complete(des_tsI())
print('执行合并操作')
# 视频合并
merge_file()
if __name__ == '__main__':
run()
协程不需要等待,而线程需要等待该条执行完再进行下一条,协程通过再task任务收集器里面切换任务。
3.6 异步案例2
采集地址:百度小说
要求:使用协程方式写入,数据存放再mongo
pip3 install motor
该包是为了实现异步的mongodb
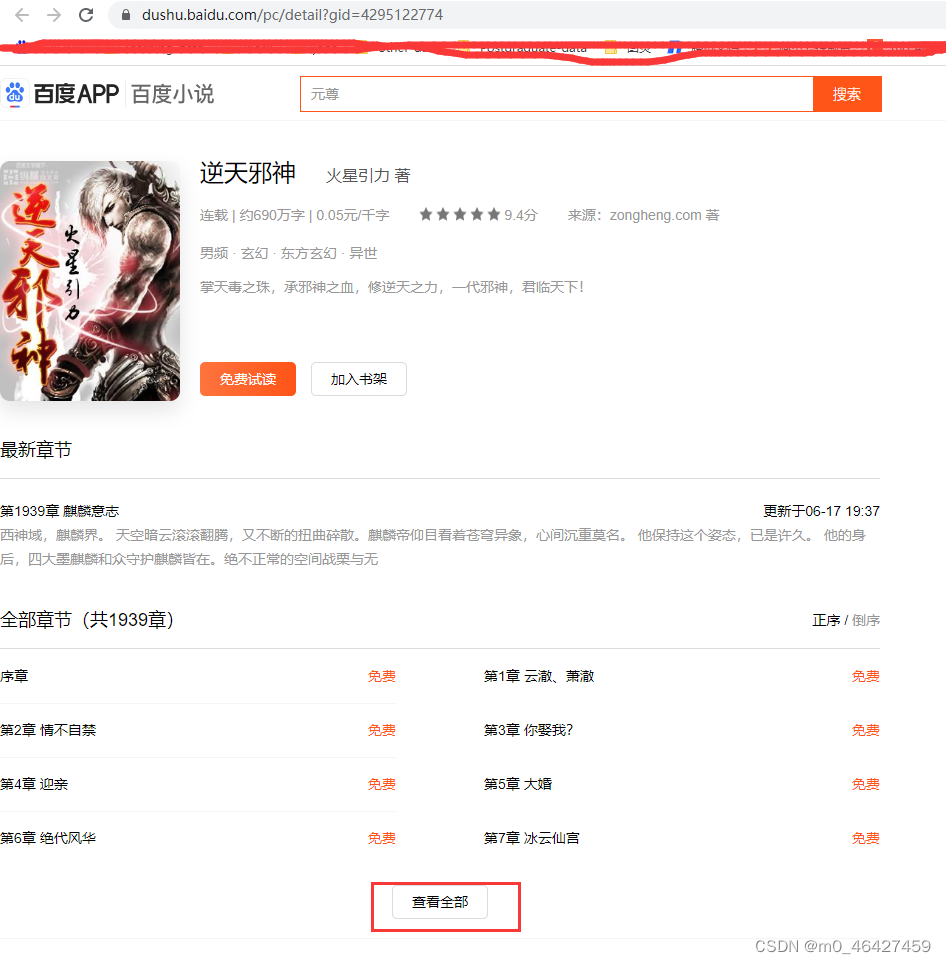
先分析
1、进入网站进行抓包,打开F12,点击查看全部。
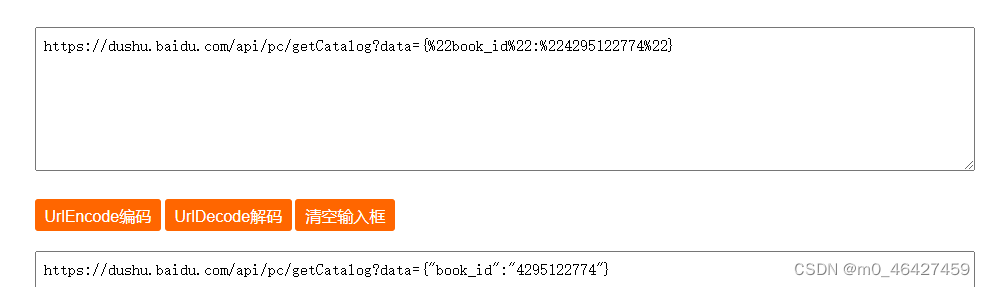
2、查看各个请求包的preview即可确定我们需要的目录数据在这个请求中:https://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%224295122774%22}
但是这里是编码过的,因此去http://www.urlencode.com.cn/进行解码,得到:
3、接下来进入任一个详情页,找到详情页的请求包:
同样进行解码,得到:

book_id就是这个小说的id,cid就是每章的id(在目录请求包中有记录)。
import requests
import asyncio, aiohttp, aiofiles
import pymongo
from motor.motor_asyncio import AsyncIOMotorClient
client = AsyncIOMotorClient('localhost', 27017)
db = client['spider']
collection = db['novel']
headers = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.100 Safari/537.36'
}
b_id = '4295122774'
url = 'https://dushu.baidu.com/api/pc/getCatalog?data={"book_id":"' + b_id + '"}'
import json, os, re
def validateTitle(title):
# 去除字符串特殊符号使用
rstr = r"[\/\\\:\*\?\"\<\>\|]" # '/\:*?"<>|'
new_title = re.sub(rstr, "", title)
return new_title
async def download(cid, b_id, title):
data = {
"book_id": b_id,
"cid": f"{b_id}|{cid}",
"need_bookinfo": 1
}
data = json.dumps(data)
url = 'https://dushu.baidu.com/api/pc/getChapterContent?data={}'.format(data)
async with aiohttp.ClientSession(headers=headers) as session:
async with session.get(url) as resp:
dic = await resp.json()
# 异步写入文件
# print(title)
content = {
'title': title,
'content': dic['data']['novel']['content']
}
await save_data(content)
async def save_data(data):
if data:
return await collection.insert_one(data)
async def getCat(url):
# 抓取目录页,提取得到所有章节的cid和标题,将其加入异步任务
res = requests.get(url, headers=headers)
dic = res.json()
# 提取ID + 章节信息
tasks = []
for a in dic['data']['novel']['items']:
title = a['title']
cid = a['cid']
# 准备异步任务
tasks.append(download(cid, b_id, title))
await asyncio.wait(tasks)
if __name__ == '__main__':
# getCat(url)
asyncio.run(getCat(url))
# asyncio.get_event_loop().run_until_complete(getCat(url))3.7 并发请求限制
异步的请求还是太快,后面应该考虑限制一下速度。可以参考:Python异步请求【限制并发量】 - 宝山方圆 - 博客园
aiohttp使用代理IP,查看方法源码就好了。



















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









