







Chao Wang and Hui Jiang, Department of Electrical Engineering and Computer Science, Lassonde School of Engineering, York University, Explicit Utilization of General Knowledge in Machine Reading Comprehension
论文原文:https://arxiv.org/pdf/1809.03449v3.pdf
1 introduction
当前机器阅读理解模型 MRC 和人类行为之间的差距往往体现在:
- 缺少足够数据样例来训练:MRC 模型的训练需要大量的文本 passage,对应的问题 question,真实的答案 gold answer,对于抽取式问题甚至还需要答案提取的证据 span。但是对于人类而言,只需要比较少的例子即可以通过分析快速地学到更多的信息和解题方法。
- 对于噪声缺乏一定的鲁棒性:研究表明特意加入的噪音能够大大影响整体 MRC 模型的性能,而本文认为造成这一问题的主要原因是机器太过于依赖本身文本给定的信息,而人类可以利用常识来进行判断。
针对第二个问题举个例子:

facilitate 本身是 help 的同义词,而这一个同义词的关系并没有体现在文本中,也就是说如果机器只是阅读了 passage,它连 help 这个词都没见过,本身也就不会学习到 help 和 facilitate 之间的相关性
也就是说,如果此时能够让机器同时具有人类阅读时具有的常识(general knowledge),或许能够帮助机器更好地理解任务并给出解答。
想要让机器同时利用人的常识来进行阅读理解,此时主要目标为解决以下两个问题:
- 结合文章-问题对,提取出相关的常识信息:不能让机器为了解答一个问题学遍全世界所有的常识,故这里需要根据文章问题 pair 提取出可能帮助机器解答问题的相关的常识
- 利用常识并帮助标注答案span:也就是如何将外界学到的常识信息利用进入整个 MRC 模型中
第一个问题很好解决,本文利用 WordNet (Fellbaum, 1998) 作为外界知识库(这个东西可以简单地理解为一个同义词库)
第二个问题,当前常用的解决方式为:得到相关常识的向量标识(也就是编码到一个向量空间),再利用它丰富 word 级别的上下文语义表示,此时也就是将常识的信息和表示结合,再进行后续的 MRC 预测。但是注意到这样的方式本身是隐形的,也就是说我们很难知道这样被融入进去的表达能够怎样帮助我们最后的预测。
本文尝试提出一种能够帮助实现 于机器阅读理解中显式利用常识信息 的方法,主要贡献包括:
- 提出一种数据增强方法(data enrichment method):也就是利用 WordNet 提取出和当前 passage-question pair 相关的同义词用来完成某种程度上的数据增强
- 提出端到端的机器阅读理解模型 nowledge Aided Reader (KAR):显式利用提取出来的常识来帮助注意力机制部分的学习
2 Data Enrichment Method 数据增强方法
这里利用 WordNet 来实现数据增强,也就是主要采取同义词的信息来完成,目标为提取出同当前文章-问题对相关的外部知识信息,也就是外部知识和 passage-question pair 中 word 的语义联系
2.1 Semantic Relation Chain 语义关系链
WordNet 本身就是同义词库,但是注意到本身一个词在不同的应用场景下会存在不同的含义,自然也就存在不同的同义词。在 WordNet 中定义了共 16 种语义关系,以标注两个同义词确实为同义所需要的应用上下文环境。
则此时可以将 WordNet 中的语义关系看作语义关系链的形式,比如词汇 A 通过关系种类 1 与词汇 B 相连,而词汇 B 通过关系种类 2 与词汇 C 相连,通过不同的链的类型,不同的词汇可以连成语义关系链的形式。
对于词汇 A 的同义词集,此时还有词可能和 A 是通过多跳的形式相连的,这些词可能和 A 也存在一定的潜在关系。这里将两个不同的词之间通过多种不同的语义关系相连的路径定义为语义关系链,并将其中一个词作为一个 hop 看待(类似于 图 的形式)
2.2 Inter-word Semantic Connection 单词间语义联系
注意到本身利用同义词信息来进行数据增强的重点问题就是在考察当前的两个问题之间到底有没有语义联系。考虑单词 w,此时 WordNet 会给出它的同义词集合 S w S_w Sw,这里使用 S w ∗ S_w^* Sw∗ 来表示单词 w 的扩充同义词集合(extended synsets),集合包括所有可以通过上面定义的语义关系链和单词 w 相连的单词。
但是注意到如果此时不加限制可能整个 WordNet 中的词汇都能够相连,故在此设定超参数 κ ∈ N \kappa \in N κ∈N 来规定所有可以被加入 S w ∗ S_w^* Sw∗ 的单词涉及的最大跳数,这里对于 0 跳的时候,S* 也就是 Sw
注意这里不对当前连接不同单词之间的 relation 的类型加限制,只要是相连了就行
2.3 General Knowledge Extraction 常识提取
此时根据给定的 passage-question pair 来抽取相关的常识:
此时认为所有和当前 passage 的词汇存在一定同义词关系的词汇都是我想要学习的外部常识。令任意一个词汇 w,则此时我想要抽取集合 E w E_w Ew,包含所有 和词汇 w 存在同义词关系的 passage 中的词汇在 passag 中的位置信息:
- 这里只是抽取位置信息,也就是找到所有和当前词汇 w 存在同义词关系的,且在 passage 中的词汇,且记录它们的位置信息。注意如果此时 w 词本身也在 passage 中,略过它自己在 passage 中的信息。
- 利用规定了最大 hop 的超参数 κ 来控制此时抽取的数量,也就是说只有文章中的词汇 y 本身在当前词汇 w 的 κ-hop 内,才记录 y 在 passage 中的位置信息
3 Knowledge Aided Reader 模型介绍
3.1 overview
先来看看整体的模型结构:
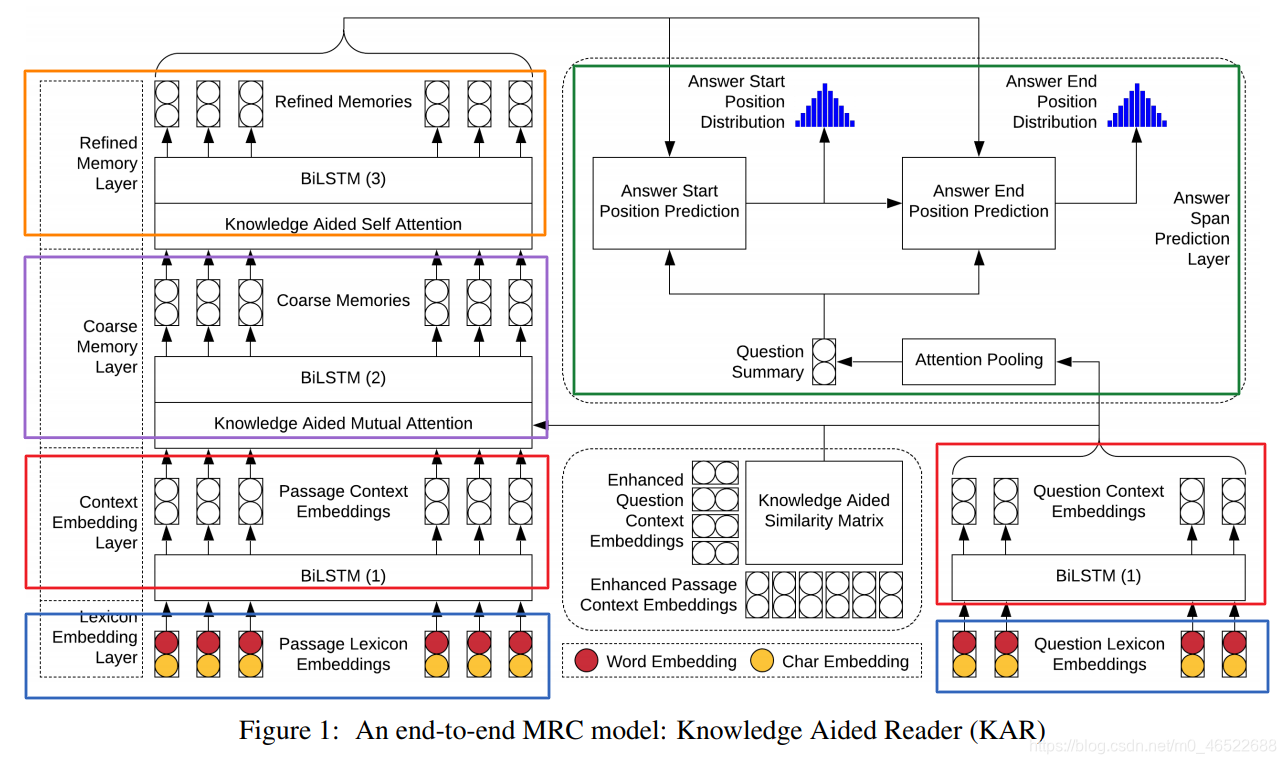
注意这里还是 attention 主导的模型,主要包括两种:
- mutual attention:主要目标是将问题表示和文章表示融合,可以得到经过了问题表示融合的文章表示(question-aware passage representation),这一步也是传统的 MRC 会处理的
- self-attention:通过(经过了问题表示融合的文章表示)与自己的自注意力模块得到最后的最终文章表示
而整个文章的创新点便在于 利用了前面抽取出的外部知识(常识)来辅助上述的注意力机制,与一般的直接将外部知识 embedding 和当前文章表示 embedding 进行融合的方式,这里针对外部知识的应用方式是显式的。
定义:
- P = { p 1 , . . . , p n } ; Q = { q 1 , . . . , q m }
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









