







一、hive简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
例如统计类需求,
(1)在hadoop体系下我们用MapReduce程序实现的,当需要些Mapper、Reducer和Driver三个类,并实现对应逻辑,相对频繁。
(2)在通过Hive SQL实现时,只需要一行就能实现,简单方便;例如:
select sum(power)from testTable group by mac;
二、Hive本质
Hive是一个Hadoop客户端,用于将HQL转化成MapReuce程序。
(1)hive的每张表的数据存储在HDFS
(2)hive分析数据底层的实现是MapReduce(也可以是Spark或者Tez)
(3)执行程序运行在yarn上
三、Hive架构原理
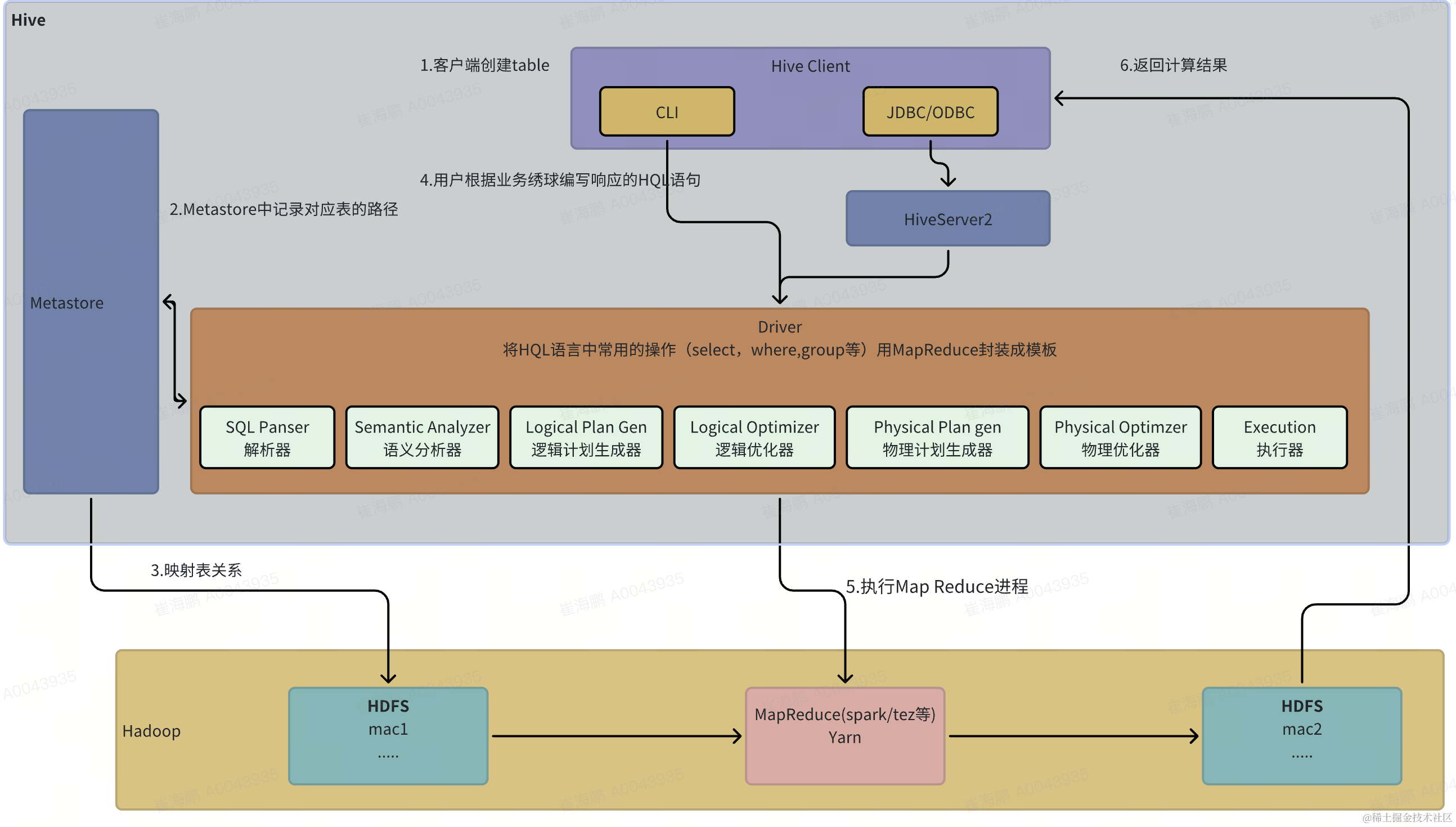
四、Hive的安装与元数据配置
1.下载地址:
http://archive.apache.org/dist/hive/
2.安装步骤:
(1)将apache-hive-3.1.3-bin.tar.gz上传到 Linux 服务器
(2)解压压缩包到指定的目录(自定义目录)
(3)添加环境变量到profile中;刷新配置文件
#HIVE_HOME
export HIVE_HOME=/{自定义的目录}
export PATH=$PATH:$HIVE_HOME/bin
(4)在mysql创建元数据库 metastore
(5)在$HIVE_HOME/conf目录汇总新建hive-site.xml文件,并添加以下配置
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
<!-- hive元数据存储版本的校验-->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive默认在HDFS的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>
(6)bin目录下执行改脚本,初始化元数据库
bin/schematool -dbType mysql -initSchema -verbose
3.验证元数据是否配置成功
(1)启动hive
cd $HIVE_HOME
bin/hive
(2)使用hive
show databases;
show tables;
create table test (id int,name string);
insert into test values(1,"ss");
select * from test;
(3)重新开启一个窗口,启动hive;若两个窗口同时都可以操作hive,都没有出现异常则说明配置成功
五、Hive服务部署
hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问hive数据功能
1.hiveserver2部署
1)hadoop端配置:
修改core-site.xml
cd $HADOOP_HOME/etc/hadoop
vim core-site.xml
添加如下配置:
<!--配置所有节点的用户都可作为代理用户-->
<property>
<name>hadoop.proxyuser.xxx.hosts</name>
<value>*</value>
</property>
<!--配置用户能够代理的用户组为任意组-->
<property>
<name>hadoop.proxyuser.xxx.groups</name>
<value>*</value>
</property>
<!--配置用户能够代理的用户为任意用户-->
<property>
<name>hadoop.proxyuser.xxx.users</name>
<value>*</value>
</property>
2)Hive端配置:
在hive-site.xml中添加如下配置信息
vim hive-site.xml
<!-- 指定hiveserver2连接的host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定hiveserver2连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
3)测试
(1)启动hiveserver2
bin/hive --service hiveserver2
(2)使用命令行客户端beeline进行远程访问
启动beeline
bin/beeline -u jdbc:hive2://hadoop102:10000 -n xxx
看到如下信息
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.3)
Driver: Hive JDBC (version 3.1.3)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.3 by Apache Hive
0: jdbc:hive2://hadoop:10000>
2.metastore部署
独立部署模式:
首先保证metastore服务的配置文件 hive-site.xml包含连接元数据库所需的参数:
<!-- jdbc连接的URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc连接的Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc连接的username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc连接的password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
其次保证hiveserver2和每个hive cli的配置文件hive-site.xml中包含访问metastore服务所需的以下参数:
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop:9083</value>
</property>
主机名需要改为metastore服务所在节点,端口号无需修改
测试:
启动metastore
hive --service metastore
重新启动客户端 并执行查询语句 若访问整张说明配置成功
六、Hive使用技巧
1.hive常用交互命令
1)表创建,并插入一条数据
hive (default)> create table test(id int,mac string);
OK
Time taken: 1.291 seconds
hive (default)> insert into table test values(1,"123");
hive (default)> select * from test;
OK
test.id test.mac
1 123
Time taken 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 797
797











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









