







目录
为什么要有分区表?
将表的数据以查询维度为依据分文件夹管理 , 当根据这个维度查询的时候减少数据的检索范围
比如有一个log表 所有的日志数据在log表目录下 ,假如想查20201130日的数据 , 只能遍历所有的数据
有了分区表以后 数据就可以以日期为维度 为文件夹存储对应日期的数据 假如想查20201130日的数据直接从对应的文件夹下读取数据
静态分区
简介
文件中存储的是指定规则的数据 比如 a.log中存储的就是20201130的数据
直接创建一个分区叫20201130 将数据直接load到目录下
条件
1)前提有静态数据
2)创建分区表
3)将静态数据导入到指定的分区中
一级静态分区
hsql演示
1. 有静态数据
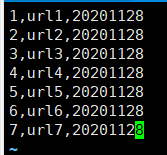
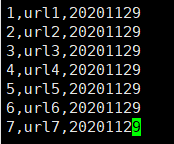
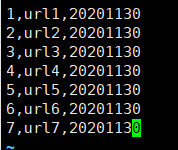
2. 创建分区表
create table tb_log (
log_id string ,
url string ,
ct string
)
partitioned by(dt string) -- 指定分区字段
row format delimited fields terminated by ',';3. 将静态数据导入到指定的分区中
load data local inpath "/data/20201128.log" into table tb_partition_log partition(dt='20201128') ;
load data local inpath "/data/20201129.log" into table tb_partition_log partition(dt='20201129') ;
load data local inpath "/data/20201130.log" into table tb_partition_log partition(dt='20201130') ;创建多级分区表
1.
年月日三级分区 -----
create table tb_partition_log3(
log_id string ,
url string ,
ct string
)
partitioned by(y string,m string , d string) -- 指定分区字段 2个
row format delimited fields terminated by ',' ;2.
load data local inpath '/log/log/20190911.log' into table tb_partition_log3 partition(y='2019' , m='09' , d='11');
load data local inpath '/log/log/20191011.log' into table tb_partition_log3 partition(y='2019' , m='10' , d='11');
load data local inpath '/log/log/20201010.log' into table tb_partition_log3 partition(y='2020' , m='10' , d='10');
load data local inpath '/log/log/20201011.log' into table tb_partition_log3 partition(y='2020' , m='10' , d='11');
load data local inpath '/log/log/20201128.log' into table tb_partition_log3 partition(y='2020' , m='11' , d='28');
load data local inpath '/log/log/20201129.log' into table tb_partition_log3 partition(y='2020' , m='11' , d='29');
load data local inpath '/log/log/20201130.log' into table tb_partition_log3 partition(y='2020' , m='11' , d='30');动态分区
简介
比如a.log中既有20201130数据 又有20201129数据 还有20191111的数据
只能根据日期字段的值创建分区 将对应的数据分配指定的分区
步骤
1) 建普通表
2) 导入数据
3) 分区表
4) 开启动态分区支持
5) 通过select insert的方式导入数据
hsql操作
1. 建普通表
- 数据
user.log
1,lisi,Shanghai
2,ycy,Shanghai
3,ym,Beijing
4,Yangzi,Beijing
5,Yangguo,shenzhen
6,mayun,shenzhen
7,mbg,Shanghai
8,marong,shenzhen
create table tb_user_log(
uid int ,
name string ,
city string
)
row format delimited fields terminated by ',' ;2.导入数据
load data local inpath "/log/user/user_log/" into table tb_user_log ;select * from tb_user_log ;
+------------------+-------------------+-------------------+
| tb_user_log.uid | tb_user_log.name | tb_user_log.city |
+------------------+-------------------+-------------------+
| 1 | lisi | Shanghai |
| 2 | ycy | Shanghai |
| 3 | ym | Beijing |
| 4 | Yangzi | Beijing |
| 5 | Yangguo | shenzhen |
| 6 | mayun | shenzhen |
| 7 | mbg | Shanghai |
| 8 | marong | shenzhen |
+------------------+-------------------+-------------------+
8 rows selected (0.165 seconds)
3. 分区表
CREATE TABLE tb_dynamic_partition_user_log(
id int ,
name string ,
city string
)
partitioned by(p_city string) ;4. 开启动态分区支持
set hive.exec.dynamic.partition=true ;
set hive.exec.dynamic.partition.mode=nonstrick;5. 通过select insert的方式导入数据
insert into tb_dynamic_partition_user_log partition(p_city)
select uid , name , city , city as p_city from tb_user_log ;- 创建成功

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









