







介绍图的关键的搜索算法之前,先简单介绍下图论中图的概念,矩阵理论中的邻接矩阵和邻接表。
1 基本概念
1.1 图
1.1.1 定义
定义:图(graph)是由一些点(vertex)和这些点之间的连线(edge)所组成的;其中,点通常被成为"顶点(vertex)",而点与点之间的连线则被成为"边或弧"(edege)。通常记为,G=(V,E)。
1.1.2 种类
根据边是否有方向,将图可以划分为:无向图和有向图。
1.无向图
无向图的所有的边都是不区分方向的。G0=(V1,{E1})。其中,
(01) V1={A,B,C,D,E,F}。 V1表示由"A,B,C,D,E,F"几个顶点组成的集合。
(02) E1={(A,B),(A,C),(B,C),(B,E),(B,F),(C,F), (C,D),(E,F),(C,E)}。 E1是由边(A,B),边(A,C)…等等组成的集合。其中,(A,C)表示由顶点A和顶点C连接成的边。
2.有向图
有向图的所有的边都是有方向的! G2=(V2,{A2})。其中,
(01) V2={A,C,B,F,D,E,G}。 V2表示由"A,B,C,D,E,F,G"几个顶点组成的集合。
(02) A2={<A,B>,<B,C>,<B,F>,<B,E>,<C,E>,<E,D>,<D,C>,<E,B>,<F,G>}。 E1是由矢量<A,B>,矢量<B,C>…等等组成的集合。其中,矢量<A,B)表示由"顶点A"指向"顶点C"的有向边。
1.1.3 比较
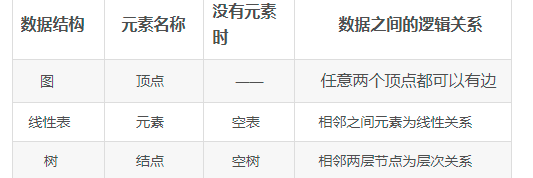
线性表中每个数据只有一个直接前驱和一个直接后驱;
树形结构中每个数据只有一个直接前驱,可以有多个直接后驱;
图形结构中结点的关系是任意的。
1.1.4 基本定义
简单图:在图中,如果不存在顶点到其自身的边,且同一边不重复出现,则称这样的图为简单图。以下都不是简单图。
第一个在顶点A和D之间, 除了之前那张图片上的一条边之外, 又多了一条边, 多出来的这条边称之为 平行边(parallel)
第二个在顶点A, 存在一个边, 这种边称之为 自环边(self-loop)
因此, 拥有自环边或平行边的图不是简单图.

无向完全图:在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完权图,含有n个顶点的无向完全图有n*(n-1)/2条边。
有向完全图:在有向图中,如果任意两个顶点都存在方向互为相反的两条弧,则称该图为无向完全图,含有n*(n-1)条边。
带权图:有些图的边或弧带有与它相关的值,我们称之为权,带权图称之为网。
子图:设有两个图G1=(V1,E1) , G2=(V2,E2) ,如果V2∈V1,且E2∈E1,则称G2是G1的子图,下图中,后面的几个图都是前面的图的子图

顶点 (Vertex): 组成图最小的元素, 顶点可以包含数据. 一个图可以有多个顶点,在图结构中不准没有顶点,顶点之间的逻辑关系用边来表示。
边 (Edge): 一般来说, 边连接着两个顶点, 因此一个图中也可以存在多条边
入边出边:在有向图中,除了邻接点之外;还有"入边"和"出边"的概念。
顶点的入边,是指以该顶点为终点的边。而顶点的出边,则是指以该顶点为起点的边。
例如,上面有向图中的A和D是邻接点;<A,D>是A的出边,还是D的入边。
邻接点(Adjacency Vertex): 一条边上的两个顶点叫做邻接点,例如图中顶点0的相邻顶点是{1, 3}。

度: 在无向图中,某个顶点的度是邻接到该顶点的边(或弧)的数目。 例如,上面无向图中顶点6的度是2。
入度出度:在有向图中。 某个顶点的入度,是指以该顶点为终点的边的数目。而顶点的出度,则是指以该顶点为起点的边的数目。 顶点的度=入度+出度。
例如,上面有向图中,顶点A的入度是2,出度是1;顶点A的度=1+2=3。
路径:如果顶点(Vm)到顶点(Vn)之间存在一个顶点序列。则表示Vm到Vn是一条路径。
路径长度:路径中"边的数量"。
简单路径:序列中顶点(若一条路径上顶点)不重复出现,则是简单路径。
回路或者环(cycle):若路径的第一个顶点和最后一个顶点相同,则是回路。
简单回路:第一个顶点和最后一个顶点相同,其它各顶点都不重复的回路则是简单回路。
连通图:对无向图,任意两个顶点之间都存在一条无向路径,则称该无向图为连通图。 对有向图而言,若图中任意两个顶点之间都存在一条有向路径,则称该有向图为强连通图。
连通分量:在无向图中,如果不是任意两个顶点之间都连通,将其中的极大连通子图称为连通分量:
a 首先要是子图,并且子图是连通的
b 连通子图含有极大顶点数
c 具有极大顶点数的连通子图包含依附于这些顶点的所有边
强连通图:在有向图中,如果对于每一对顶点vi和vj,从vi到vj和从vj到vi都有路径,则称该图为强连通图;
强连通分量:否则,将其中的极大连通子图称为强连通分量。
连通图的生成树是一个极小的连通子图,它含有图中的全部的n个点,但只有足以构成一棵树的n-1条边。
1.1.5 图的表示
邻接矩阵
邻接表
1.2 生成树
如果一个有向图恰好有一个顶点的入度为0,其余顶点的入度为1,则是一棵有向树。一个有向图的生成森林由若干棵有向树组成,含有图中所有顶点,但只有足以构成若干棵不相交的有向树的弧。下图中图2、3【有向树】构成了图1【有向图】的生成森林。
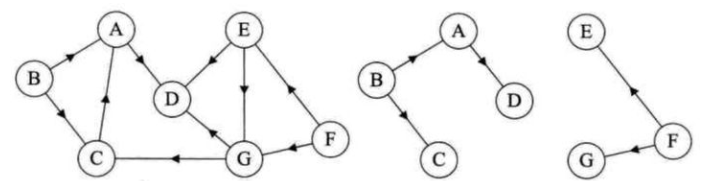
权值总和最小的生成树称为最小生成树。
构造最小生成树的方法:最初生成树为空,即没有一个结点和一条边,首先选择一个顶点作为生成树的根,然后每次从不在生成树中的边中选择一条权值尽可能小的边,为了保证加入到生成树中的边不会造成回路,与该边邻接的两个顶点必须一个已经在生成树中,一个则不在生成树中,若网中有n个顶点(这里考虑的网是一个连通无向图),则按这种条件选择n-1边就可以得到这个网的最小生成树了。详细的过程可以描述为:设置2个集合,U集合中的元素是在生成树中的结点,V-U集合中的元素是不在生成树中的顶点。首先选择一个作为生成树根结点的顶点,并将它放入U集合,然后在那些一端顶点在U集合中,而另一端顶点在V-U集合中的边中找一条权最小的边,并把这条边和那个不在U集合中的顶点加入到生成树中,即输出这条边,然后将其顶点添加到U集合中,重复这个操作n-1次。
1.3 邻接矩阵

邻接矩阵是指用矩阵来表示图。它是采用矩阵来描述图中顶点之间的关系(及弧或边的权)。
我们可以使用一张表来表示上面的图,1 -> 2 就表示 1,如果没有指向关系的就为 0.
const graph = [
[0, 0, 0, 0],
[0, 0, 1, 0],
[0, 0, 0, 0],
[0, 0, 1, 0]
]
邻接链表对于边密集的图十分有用,基本上整个二维数组都存放了这个图的所有信息,而且使用数组访问每边条都很快:graph[1][2]。但是如果边很少,稀疏图就性能会大打折扣了。而且空间上使用的复杂度是 O(n * n)。
1.有向图的邻接矩阵
具有n个顶点的有向图可以用一个n×n的方形矩阵表示。假设该矩阵的名称为M,则当是该有向图中的一条弧时,M[i,j]=1;否则M[i,j]=0。第i个顶点的出度为矩阵中第i行中"1"的个数;入度为第i列中"1"的个数,并且有向图弧的条数等于矩阵中"1"的个数。
2.无向图的邻接矩阵
具有n个顶点的无向图也可以用一个n×n的方形矩阵表示。假设该矩阵的名称为M,则当(vi,vj)是该无向图中的一条边时,M[i,j]=M[j,i]=1;否则,M[i,j]=M[j,j]=0。第i个顶点的度为矩阵中第i 行中"1"的个数或第i列中"1"的个数。图中边的数目等于矩阵中"1"的个数的一半,这是因为每条边在矩阵中描述了两次。
#define MAX_VERTEX_NUM 20
typedef struct graph{
Elemtype elem[MAX_VERTEX_NUM][MAX_VERTEX_NUM];
int n;
}Graph;
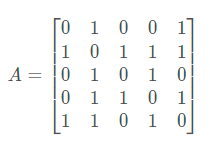
//图的矩阵实现
typedef struct MGRAPH{
nodes int[]; //节点
edges int[][]; //边
}mGraph;
1.4 邻接表
邻接表是图的一种链式存储表示方法。缺点是不方便判断两个顶点之间是否有边,但是相对邻接矩阵来说更省空间。
const graph = {
1: [],
2: [3],
3: [],
4: [3]
}
和邻接矩阵相反,邻接链表对于稀疏图十分友好,空间复杂度为 O(n + m)
1.邻接表(无向图)
边结点的结构为:
adjvex是该边或弧依附的顶点在数组中的下标,next是指向下一条边或弧结点的指针
elem是顶点内容,firstedge是指向第一条边或弧结点的指针。
#define MAX_VERTEX_NUM 30//最大顶点个数
typedef char Elemtype;
typedef struct EdgeLinklist{//边结点
int adjvex;// 该边所指向的顶点的位置[0,1,3]而这"0,1,3"分别对应"A,B,D"的序号,"A,B,D"都是C的邻接点。就是通过这种方式记录图的信息的
struct EdgeLinklist* next;//指向下一条弧的指针
}EdgeLinklist;
typedef struct VexLinklist{//邻接表顶点Node
Elemtype elem;//顶点信息[C]
EdgeLinklist* firstedge;//指向第一条依附该顶点的弧
}VexLinklist,AdjList[MAX_VERTEX_NUM];
(1) 创建有向图邻接表
void Create_adj(AdjList adj,int n){//adj: 含有MAX_VERTEX_NUM个元素的结构体数组。
for(i=0;i<n;i++){//初始化顶点数组
scanf(&adj.elem);
adj.firstedge=NULL;
}
scanf(&i,&j);//输入弧
while(i){
EdgeLinklist* s=(EdgeLinklist*)malloc(sizeof(EdgeLinklist));//创建新的弧结点
s->adjvex=j-1;//当前弧节点i的一个邻接点j
s->next=adj[i-1].firstedge;//将新的弧结点插入到相应的位置
adj[i-1].firstegde=s;
scanf(&i,&j);//输入下一条弧
}
}
(2)创建无向图的邻接表
void Create_adj(AdjList adj,intn){
for(i=0;i<n;i++){//初始化邻接表
scanf(&adj.elem);
adj.firstedge=NULL;
}
scanf(&i,&j);//输入边
while(i){
EdgeLinklist* s1=(EdgeLinklist*)malloc(sizeof(EdgeLinklist));
s1->adjvex=j-1;
s2=(EdgeLinklist*)malloc(sizeof(EdgeLinklist));
s2->adjvex=i-1;
s1->next=adj[i-1].firstedge;
adj[i-1].firstegde=s1;
s2->next=adj[j-1].firstedge;
adj[j-1].firstegde=s2;
scanf(&i,&j);
}
}
实例:
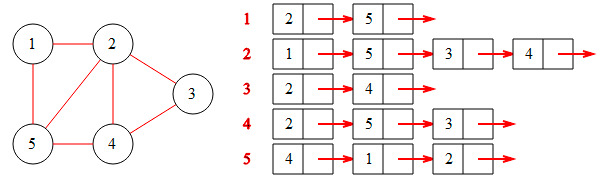
其左侧为图的示意图,右侧为图的邻接链表。红字表示节点序号,链表结构:
package main
import "fmt"
type Node struct{
value int; //节点为int型
};
type Graph struct{
nodes []*Node
edges map[Node][]*Node //邻接表示的无向图
}
其中,map为键值索引类型,其定义格式为map[],为键,为值。在图结构中,map[Node][]*Node表示一个Node对应一个Node指针所组成的数组。
//增加节点
//可以理解为Graph的成员函数
func (g *Graph) AddNode(n *Node) {
g.nodes = append(g.nodes, n)
}
//增加边
func (g *Graph) AddEdge(u, v *Node) {
g.edges[*u] = append(g.edges[*u],v) //u->v边
g.edges[*v] = append(g.edges[*v],u) //u->v边
}
//打印图
func (g *Graph) Print(){
//range遍历 g.nodes,返回索引和值
for _,iNode:=range g.nodes{
fmt.Printf("%v:",iNode.value)
for _,next:=range g.edges[*iNode]{
fmt.Printf("%v->",next.value)
}
fmt.Printf("\n")
}
}
func initGraph() Graph{
g := Graph{}
for i:=1;i<=5;i++{
g.AddNode(&Node{i,false})
}
//生成边
A := [...]int{1,1,2,2,2,3,4}
B := [...]int{2,5,3,4,5,4,5}
g.edges = make(map[Node][]*Node)//初始化边
for i:=0;i<7;i++{
g.AddEdge(g.nodes[A[i]-1], g.nodes[B[i]-1])
}
return g
}
func main(){
g := initGraph()
g.Print()
}
1.5 图的搜索
较为广泛的搜索算法:深度优先算法 (DFS) 和广度优先算法 (BFS)
两个算法的时间复杂度都为 O(m + n)。

2 广度优先遍历BFS
2.1 算法描述
广度优先搜索算法是从根节点开始,沿着树的宽度遍历树的节点。如果所有节点均被访问,则算法中止。借助广度优先搜索算法,可以让你找出两样东西之间的最短距离。
2.2 算法步骤
从一个节点开始,不同的是它会先搜索完该节点的子节点,再往下一层搜索。
a .首先选择一个顶点作为起始顶点,并将其染成灰色,其余顶点为白色。
b. 将起始顶点放入队列中。
c. 从队列首部选出一个顶点,并找出所有与之邻接的顶点,将找到的邻接顶点放入队列尾部,将已访问过顶点涂成黑色,没访问过的顶点是白色。如果顶点的颜色是灰色,表示已经发现并且放入了队列,如果顶点的颜色是白色,表示还没有发现
d. 按照同样的方法处理队列中的下一个顶点。
基本就是出队的顶点变成黑色,在队列里的是灰色,还没入队的是白色。
用一副图来表达这个流程如下:
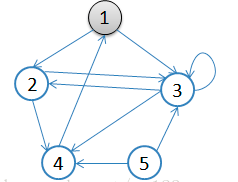
1.初始状态,从顶点1开始,队列={1}
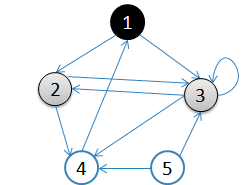
2.访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}
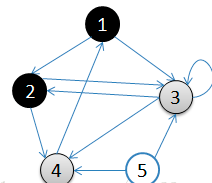
3.访问2的邻接顶点,2出队,4入队,队列={3,4}
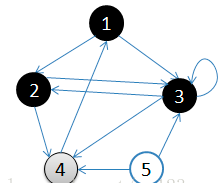
4.访问3的邻接顶点,3出队,队列={4}
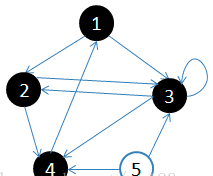
5.访问4的邻接顶点,4出队,队列={ 空}
从顶点1开始进行广度优先搜索:
初始状态,从顶点1开始,队列={1}
访问1的邻接顶点,1出队变黑,2,3入队,队列={2,3,}
访问2的邻接顶点,2出队,4入队,队列={3,4}
访问3的邻接顶点,3出队,队列={4}
访问4的邻接顶点,4出队,队列={ 空}
顶点5对于1来说不可达。代码如下:
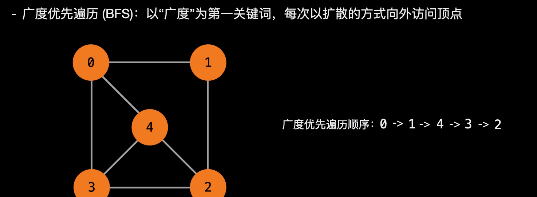
注:BFS方法遍历顺序不唯一。
let reached = []
function bfs() {
let queue = new Queue()
reached.push(s)
queue.push(s)
while (!queue.isEmpty()) {
let node = queue.dequeue()
for (let child of node.children) {
if (reached.indexOf(child) === -1) {
queue.push(child)
reached.push(child)
}
}
}
}
bfs(s)
console.log(reached)
2.3 代码实现
需要考虑节点是否被访问过,防止重复操作陷入死循环。
实现1
type Node struct{
value int;
searched bool;
}
type Graph struct{
nodes []*Node
edges map[*Node][]*Node //邻接表示的无向图
}
//增加边
func (g *Graph) AddEdge(u, v *Node) {
g.edges[u] = append(g.edges[u],v) //u->v边
g.edges[v] = append(g.edges[v],u) //u->v边
}
//打印图
func (g *Graph) Print(){
//range遍历 g.nodes,返回索引和值
for _,iNode:=range g.nodes{
fmt.Printf("%v:",iNode.value)
for _,next:=range g.edges[iNode]{
fmt.Printf("%v->",next.value)
}
fmt.Printf("\n")
}
}
func initGraph() Graph{
g := Graph{}
for i:=1;i<=9;i++{
g.AddNode(&Node{i,false})
}
//生成边
A := [...]int{1,1,2,2,2,3,4,5,5,6,1}
B := [...]int{2,5,3,4,5,4,5,6,7,8,9}
g.edges = make(map[*Node][]*Node)//初始化边
for i:=0;i<11;i++{
g.AddEdge(g.nodes[A[i]-1], g.nodes[B[i]-1])
}
return g
}
func (g *Graph) BFS(n *Node){
var adNodes[] *Node //存储待搜索节点
n.searched = true
fmt.Printf("%d:",n.value)
for _,iNode:=range g.edges[n]{
if !iNode.searched {
adNodes = append(adNodes,iNode)
iNode.searched=true
fmt.Printf("%v ",iNode.value)
}
}
fmt.Printf("\n")
for _,iNode:=range adNodes{
g.BFS(iNode)
}
}
func main(){
g := initGraph()
g.Print()
g.BFS(g.nodes[0])
}

实现2
package main
import "fmt"
func main() {
friendCircle := createFriendCircle()
breadthFirstSearch(friendCircle)
}
func personIsSeller(name string) bool {
return name[len(name)-1] == 'y'
}
func createFriendCircle() map[string][]string {
fc := make(map[string][]string)
fc["you"] = []string{"alice", "bob", "claire"}
fc["bob"] = []string{"anuj", "peggy"}
fc["alice"] = []string{"peggy"}
fc["claire"] = []string{"thom", "jonny"}
fc["anuj"] = []string{}
fc["peggy"] = []string{}
fc["thom"] = []string{}
fc["jonny"] = []string{}
return fc
}
func breadthFirstSearch(friendCircle map[string][]string) bool {
searchList := friendCircle["you"]
if len(searchList) == 0 {
return false
}
searched := make(map[string]bool)
for {
person := searchList[0]
searchList = searchList[1:]
_, found := searched[person]
if !found {
if personIsSeller(person) {
fmt.Println(person + " is a seller!")
return true
} else {
searchList = append(searchList, friendCircle[person]...)
searched[person] = true
}
}
if len(searchList) == 0 {
break
}
}
return false
}
实现3
package main
import (
"golang.org/x/net/html"
"net/http"
"fmt"
"log"
)
// 广度优先搜索
func BreadthFistSearch(f func(url string)[]string, workList []string) {
seen := make(map[string]bool)
for len(workList) > 0{
items := workList
workList = nil
for _,item := range items{
if !seen[item]{
seen[item] = true
workList = append(workList, f(item)...)
}
}
}
}
func main() {
var getURL func(url string) []string
getURL = func(url string) []string {
fmt.Println(url)
list,err := Extract(url) //提取指定url页面的所有超链接
if err != nil{
log.Println(err)
}
return list
}
BreadthFistSearch(getURL, []string{"http://www.ahfesco.com.cn"})
}
func IterateHtmlNode(n *html.Node, pre, post func(n *html.Node)) {
if pre != nil {
pre(n)
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
IterateHtmlNode(c, pre, post)
}
if post != nil {
post(n)
}
}
func Extract(url string)([]string ,error) {
var resp,err = http.Get(url)
if err != nil{
return nil, err
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK{
return nil, fmt.Errorf("getting %s: %s", url, resp.Status)
}
doc,err := html.Parse(resp.Body)
if err !=nil {
return nil,fmt.Errorf("parsing %s as HTML: %v", url, err)
}
var links []string
visitNode := func(n *html.Node){
if n.Type == html.ElementNode && n.Data == "a"{
for _,a := range n.Attr{
if a.Key != "href" {
continue
}
link,err := resp.Request.URL.Parse(a.Val)
if err != nil {
continue
}
links = append(links, link.String())
}
}
}
IterateHtmlNode(doc, visitNode, nil)
return links, nil
}
3 深度优先遍历DFS
3.1 算法描述
深度优先算法的思路是从一个节点开始搜索下去,一条路走到黑。如果发现走不通了,就往回一个节点,从那个节点继续往下走。
3.2 算法步骤
从图中某顶点v出发:
a.访问顶点v;
b.依次从v的未被访问的一个邻接点出发,对图进行深度优先遍历,遍历该节点的所有节点以及子节点直至图中和v有路径相通的顶点都被访问;
c.若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
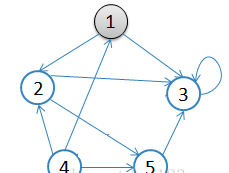
1.从v = 1开始出发,先访问顶点1
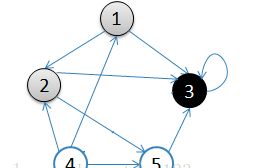
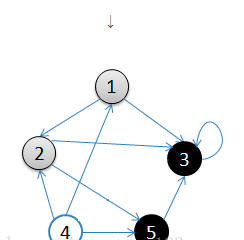
2.按深度优先搜索递归访问v的某个未被访问的邻接点2,顶点2结束后,应该访问3或5中的某一个,这里为顶点3,此时顶点3不再有出度,因此回溯到顶点2,再访问顶点2的另一个邻接点5,由于顶点5的唯一一条边的弧头为3,已经访问了,所以此时继续回溯到顶点1,找顶点1的其他邻接点。
实际上树不管是前序遍历,还是中序遍历,亦或是后序遍历,都属于深度优先遍历。

注:DFS方法顺序并不唯一。
伪代码如下:
// To find vertices reachable from s
/**
* 最终返回值
* 防止使用多次 DFS 算法
* 避免死循环
* Good, worst case analysis
*/
let reached = []
function dfs(node) {
reached.push(node)
for (let child of node.children) {
if (reached.indexOf(child) === -1) {
recurse(child)
}
}
}
dfs(source)
console.log(reached)
3.3 代码实现
递归实现1
func (g *Graph) DFS(){
for _,iNode:=range g.nodes{
if !iNode.searched{
iNode.searched = true
fmt.Printf("%v->",iNode.value)
g.visitNode(iNode)
fmt.Printf("\n")
g.DFS()
}
}
}
func (g *Graph) visitNode(n *Node){
for _,iNode:= range g.edges[n]{
if !iNode.searched{
iNode.searched = true
fmt.Printf("%v->",iNode.value)
g.visitNode(iNode)
return
}
}
}
func main(){
g := initGraph()
g.nodes[0].searched = true
fmt.Printf("%v->",g.nodes[0].value)
g.DFS(g.nodes[0])
}
非递归实现2
对于每个节点来说,先遍历当前节点,然后把右节点压栈,再压左节点(这样弹栈的时候会先拿到左节点遍历,符合深度优先遍历要求)。
弹栈,拿到栈顶的节点,如果节点不为空,重复步骤 1, 如果为空,结束遍历。

/**
* 使用栈来实现 dfs
* @param root
*/
public static void dfsWithStack(Node root) {
if (root == null) {
return;
}
Stack<Node> stack = new Stack<>();
// 先把根节点压栈
stack.push(root);
while (!stack.isEmpty()) {
Node treeNode = stack.pop();
// 遍历节点
process(treeNode)
// 先压右节点
if (treeNode.right != null) {
stack.push(treeNode.right);
}
// 再压左节点
if (treeNode.left != null) {
stack.push(treeNode.left);
}
}
}
4 算法对比
深度优先遍历用的是栈,而广度优先遍历要用队列来实现
1.深度优先搜索与广度优先搜索算法有何区别
| 说明 | DFS | BFS |
|---|---|---|
| 特征 | 不全部保留结点,扩展完的结点从数据存储结构栈中弹出删去,一般在数据栈中存储的结点数为树的深度,因此它占用空间较少 | 一般需存储产生的所有结点,占用的存储空间要大 |
| 注意事项 | 结点较多场景,可能DFS会超时【因为结束的条件和时间不同。BFS最先搜索到满足条件的就是最短的路径,所以可以直接return结果;DFS则需要遍历所有的可能情况,比较每一种情况是否是最短路径。】 | 考虑溢出和节省内存空间的问题,无回溯 |
| 实现方式 | 栈【递归】 :整个过程可以想象成一个倒立的树形:1、把根节点压入栈中。2、每次从栈中弹出一个元素,搜索所有在它下一级的元素,把这些元素压入栈中。并把这个元素记为它下一级元素的前驱。 | 队列:每次从队列的头部取出一个元素,查看这个元素所有的下一级元素,把它们放到队列的末尾。并把这个元素记为它下一级元素的前驱 |
| 性质 | 搜索是以接近起始状态的程序依次扩展状态的DFS的重要点在于状态回溯 | 1)新加入的结点到根的距离一定大于等于队列中排在它前面的结点。也就是说,BFS天然地带有路径长度的信息,可以依次搜索到走一步可到达的点,走两步可到达的点,走三步可到达的点 2)搜索是以接近起始状态的程序依次扩展状态的 3)只对每个节点访问一遍 3)BFS关键点是状态的选取和标记 |
| 适用 | 找距离某一点的最短路,但路径不唯一,最先搜索到满足条件的就是最短的路径,大范围的查找出现 “最短”、“最少”类似字眼的可以优先考虑 | 目的性强的查找与搜索问题:能找出解就行,是否可达问题 |
2.回溯与分支限界法
回溯法以深度优先的方式搜索解空间树T,而分支限界法则以广度优先或以最小耗费优先的方式搜索解空间树T。由于它们在问题的解空间树T上搜索的方法不同,适合解决的问题也就不同。一般情况下,回溯法的求解目标是找出T中满足约束条件的所有解的方案,而分支限界法的求解目标则是找出满足约束条件的一个解,或是在满足约束条件的解中找出使用某一目标函数值达到极大或极小的解,即在某种意义下的最优解。相对而言,分支限界算法的解空间比回溯法大得多, 因此当内存容量有限时,回溯法成功的可能性更大。

在处理最优问题时,采用穷举法、回溯法或分支限界法都可以通过利用当前最优解和上界函数加速。仅就对限界剪支的效率而言,优先队列的分支限界法显然要更充分一些。在穷举法中通过上界函数与当前情况下函数值的比较可以直接略过不合要求的情况而省去了更进一步的枚举和判断;回溯法则因为层次的划分,可以在上界函数值小于当前最优解时,剪去以该结点为根的子树,也就是节省了搜索范围;分支限界法在这方面除了可以做到回溯法能做到的之外,同时若采用优先队列的分支限界法,用上界函数作为活结点的优先级,一旦有叶结点成为当前扩展结点,就意味着该叶结点所对应的解即为最优解,可以立即终止其余的过程。在前面的例题中曾说明,优先队列的分支限界法更象是有选择、有目的地进行深度优先搜索,时间效率、空间效率都是比较高的。
3.动态规划与搜索算法
撇开时空效率的因素不谈,在解决最优化问题的算法中,搜索可以说是“万能”的。所以动态规划可以解决的问题,搜索也一定可以解决。动态规划要求阶段决策具有无后向性,而搜索算法没有此限止。
动态规划是自底向上的递推求解,而无论深度优先搜索或广度优先搜索都是自顶向下求解。利用动态规划法进行算法设计时,设计者在进行算法设计前已经用大脑自己构造好了问题的解空间,因此可以自底向上的递推求解;而搜索算法是在搜索过程中根据一定规则自动构造,并搜索解空间树的。由于在很多情况下,问题的解空间太复杂用大脑构造有一定困难,仍然需要采用搜索算法。
另外动态规划在递推求解过程中,需要用数组存储有关信息,而数组的下标只能是整数,所以要求问题中相关的数据必须为整数,对于这类信息非整数或不便于转换为整数的问题,同样需要采用搜索算法。
一般说来,动态规划算法在时间效率上的优势是搜索无法比拟的,但动态规划总要遍历所有的状态,而搜索可以排除一些无效状态。更重要的是搜索还可以剪枝,可能剪去大量不必要的状态,因此在空间开销上往往比动态规划要低很多。如何协调好动态规划的高效率与高消费之间的矛盾呢?有一种折衷的办法就是记忆化搜索算法
记忆化限界搜索算法在求解时,还是按着自顶向下的顺序,但是每求解一个状态,就将它的解保存下来,以后再次遇到这个状态的时候,就不必重新求解了。这种方法综合了搜索和动态规划两方面的优点,因而还是很有实用价值的。记忆化限界搜索。它以搜索算法为核心,只不过使用“记录求过的状态”的办法,来避免重复搜索,这样,记忆化搜索的每一步,也可以对应到动态规划算法中去。记忆化搜索有优化方便、调试容易、思维直观的优点,但是效率上比循环的动态规划差一个常数,但是时间和空间复杂度是同一数量级的(尽管空间上也差一个常数,那就是堆栈空间)。当n比较小的时候,我们可以忽略这个常数,从而记忆化搜索可以和动态规划达到完全相同的效果。
更多:https://blog.csdn.net/a2217018103/article/details/90678830
https://www.cnblogs.com/alantu2018/p/8464612.html















 1424
1424











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









