







使用Iris数据集训练第一个模型
本节将演示使用Azure机器学习Python SDK在单节点CPU上训练一个SVM模型,使用的框架为SKLearn,使用的数据集为 Iris数据集。整个过程都在Jupyter notebook中运行。
本节训练流程如下图所示,涉及到的 工作区、试验、计算集群、Azure机器学习studio等概念,如果不清楚,请查阅: Azure机器学习(理论篇)——Azure机器学习介绍。
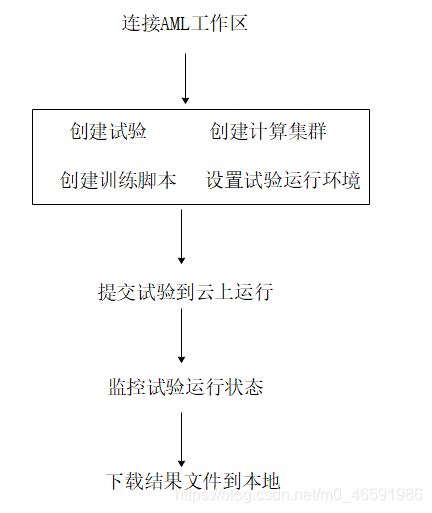
图1 使用Azure机器学习训练模型流程
一、使用前提
在开始本节内容之前,你需要:
- Azure 订阅和Azure机器学习工作区。创建方法:Azure机器学习(实战篇)——创建Azure机器学习服务
- 配置Azure机器学习开发环境。配置方法:Azure机器学习(实战篇)——配置 Azure 机器学习开发环境
查看Azure机器学习版本:
# Check core SDK version number
import azureml.core
print("SDK version:", azureml.core.VERSION)输出:
SDK version: 1.0.85二、连接和初始化工作区
整个训练过程都是在Azure机器学习工作区内开展的。所以第一步是要连接到工作区。如果还没有工作区,请先创建一个,创建步骤详见:Azure机器学习(实战篇)——创建Azure机器学习服务的第二部分。
使用以下代码连接到Azure机器学习工作区:
ws = Workspace.from_config('config.json')
print('Workspace name: ' + ws.name, 'Azure region: ' + ws.location,
'Subscription id: ' + ws.subscription_id, 'Resource group: ' + ws.resource_group, sep = '\n')'config.json’是存在本地的连接工作区的配置文件,该文件生成方法详见:Azure机器学习(实战篇)——配置 Azure 机器学习开发环境的第四部分。
输出:

三、创建试验
在当前工作区中创建一个试验,以便在该试验下训练模型。
试验是工作区下面的一个逻辑容器,它涵盖了每一次模型训练的运行记录和结果信息。
以下代码按名称从 Workspace 内部获取Experiment 对象,如果该名称不存在,则会创建新的 Experiment 对象
from azureml.core import Experiment
experiment_name = 'train_iris'
experiment = Experiment(ws, name=experiment_name)Workspace中创建成功的试验可以通过以下代码查看:
list_experiments = Experiment.list(ws)也可以在Azure机器学习studio中查看试验信息。
Azure机器学习studio是除Python SDK外使用Azure机器学习的另一种方式。更多关于Azure机器学习studio的介绍请查看Azure机器学习——创建Azure机器学习服务。
图2 在Azure机器学习studio中查看试验信息
四、创建计算资源
与本地训练不同,使用Azure机器学习可以利用云上的计算资源,将训练脚本提交到远程计算集群得到训练结果。
首先创建一个Azure机器学习托管的计算集群AmlCompute,该计算集群支持并行计算,在调参时候非常有用。
通过max_nodes和min_nodes定义集群中的最大和最小计算节点数目。代码中:
- vm_size=‘STANDARD_D2_V2’,表示计算集群中的节点是’STANDARD_D2_V2’规格的虚拟机,更多虚拟机规格请查看此链接。
- max_nodes=4,表示计算集群最大并行任务数为4;
- min_nodes=0,表示计算集群在没有任务时不会有节点运行,节约开销。
每个Azure订阅的计算集群节点数目都是有限制的,如果创建后的计算集群max_nodes没有达到目标节点数,那可能是已创建的计算集群用光了节点配额,你可以删除不用的计算集群或者申请更多的Azure计算集群节点配额。
from azureml.core.compute import ComputeTarget, AmlCompute
from azureml.core.compute_target import ComputeTargetException
# choose a name for your cluster
cluster_name = "cpu-cluster"
try:
compute_target = ComputeTarget(workspace=ws, name=cluster_name)
print('Found existing compute target')
except ComputeTargetException:
print('Creating a new compute target...')
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2',
min_nodes=0,
max_nodes=4)
# create the cluster
compute_target = ComputeTarget.create(ws, cluster_name, compute_config)
# can poll for a minimum number of nodes and for a specific timeout.
# if no min node count is provided it uses the scale settings for the cluster
compute_target.wait_for_completion(show_output=True, min_node_count=None, timeout_in_minutes=20)
# use get_status() to get a detailed status for the current cluster.
print(compute_target.get_status().serialize())计算集群创建成功后,可以在Azure机器学习studio中查看。

图3 在Azure机器学习studio中查看计算资源信息
五、创建运行脚本
首先在本地创建一个文件夹,用来保存脚本及其所依赖的文件。
import os
project_folder = './sklearn-iris'
os.makedirs(project_folder, exist_ok=True)运行脚本代码如下,将其保存到上述project_folder文件夹中:
import argparse
import os
# importing necessary libraries
import numpy as np
from sklearn import datasets
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import train_test_split
import joblib
from azureml.core.run import Run
run = Run.get_context()
def main():
parser = argparse.ArgumentParser()
parser.add_argument('--kernel', type=str, default='linear',
help='Kernel type to be used in the algorithm')
parser.add_argument('--penalty', type=float, default=1.0,
help='Penalty parameter of the error term')
args = parser.parse_args()
run.log('Kernel type', np.str(args.kernel))
run.log('Penalty', np.float(args.penalty))
# loading the iris dataset
iris = datasets.load_iris()
# X -> features, y -> label
X = iris.data
y = iris.target
# dividing X, y into train and test data
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
# training a linear SVM classifier
from sklearn.svm import SVC
svm_model_linear = SVC(kernel=args.kernel, C=args.penalty).fit(X_train, y_train)
svm_predictions = svm_model_linear.predict(X_test)
# model accuracy for X_test
accuracy = svm_model_linear.score(X_test, y_test)
print('Accuracy of SVM classifier on test set: {:.2f}'.format(accuracy))
run.log('Accuracy', np.float(accuracy))
# creating a confusion matrix
cm = confusion_matrix(y_test, svm_predictions)
print(cm)
os.makedirs('outputs', exist_ok=True)
# files saved in the "outputs" folder are automatically uploaded into run history
joblib.dump(svm_model_linear, 'outputs/model.joblib')
if __name__ == '__main__':
main()和本地训练不同的是,上述脚本从azureml.core.run导入了Run这个类,接下来使用了Run.get_context()这个方法,该方法可以记录训练中的日志信息,比如模型参数、模型精度等。等训练完成后,可以到Web页面查看这些参数的可视化结果。
运行(Run)
一个运行表示试验的单次试运行。 Run 是用来监视试运行的异步执行、存储试运行的输出、分析结果以及访问生成的项目的对象。 在试验代码内部使用 Run 可将模型指标和项目记录到运行历史记录服务。
Run的功能包括:
- 存储和检索模型指标与数据。
- 使用标记和子层次结构来轻松查找以往的运行。
- 注册已存储的模型文件用于部署。
- 存储、修改和检索运行的属性。
本节第七部分会通过提交 Experiment 对象来创建 Run 对象。 试验运行环境
设置试验Python环境
由于云上计算集群的节点是以docker容器的形式运行计算任务,而不同的试验任务会使用不同的Python环境和依赖。所以对每次试验运行,我们都要先定义一个Python环境,然后根据该环境创建docker镜像,计算节点再使用这些docker镜像初始化容器并执行计算。
一般来说,直接使用Azure机器学习Python SDK中现成的SKLearn、PyTorch和TensorFlow等框架提交试验任务,任务的Python环境都会自动配置好,基本不需要自行设置。但是在Mooncake上创建docker镜像时,因为网络原因conda和pip从默认源获取资源的速度非常慢,因此我们用下面的代码自己设置试验运行需要的依赖包和更新conda和pip的国内源。
更详细的介绍请参考:Azure机器学习(实战篇)——配置 Azure 机器学习Python环境
from azureml.core.environment import Environment
from azureml.core.conda_dependencies import CondaDependencies
# to install required packages
env = Environment('iris-env')
cd = CondaDependencies.create(pip_packages=['joblib==0.13.2','numpy==1.16.2','azureml-dataprep[pandas,fuse]>=1.1.14', 'azureml-defaults'],
conda_packages = ['scikit-learn==0.22.1'])
env.python.conda_dependencies = cd
env.docker.enabled = True
# Specify docker steps as a string. Alternatively, load the string from a file.
dockerfile = r"""
FROM mcr.microsoft.com/azureml/base:intelmpi2018.3-ubuntu16.04
RUN conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/mro/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/ && \
conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/bioconda/ && \
conda config --set show_channel_urls yes
RUN pip install -U pip
RUN pip config set global.index-url http://mirrors.aliyun.com/pypi/simple
RUN pip config set install.trusted-host mirrors.aliyun.com
RUN echo "Hello from custom container!"
"""
# Set base image to None, because the image is defined by dockerfile.
env.docker.base_image = None
env.docker.base_dockerfile = dockerfile
# Register environment to re-use later
env.register(workspace = ws)Scikit-learn估计器(Estimator)
由于使用SKLearn来训练模型,这里我们从azureml.train导入了SKLearn这个类。
Azure机器学习Python SDK集成了SKLearn、PyTorch、TensorFlow等常用的训练框架,为了方便管理各个训练框架及其依赖包的版本更新和设置运行环境,Azure机器学习将他们在SDK中以各自的名字分开包装,但都在azureml.train这个目录下。

图4 Azure机器学习Python SDK中集成的训练框架
使用以下代码设置SKLearn训练环境:
from azureml.train.sklearn import SKLearn
script_params = {
'--kernel': 'linear',
'--penalty': 1.0,
}
# 如果使用的其他训练框架,用图4中对应的训练框架替换SKLearn即可
estimator = SKLearn(source_directory=project_folder,
script_params=script_params,
compute_target=compute_target,
entry_script='train_iris.py',
environment_definition=env
)SKLearn参数:
- source_directory是之前创建的本地文件夹。
- script_params是脚本的参数,这里我们定义了SVM的核函数和惩罚项,这两个最终会传递到训练脚本的。
- compute_target是本次训练用到的计算集群。这里我们用云上的计算集群,但你也可以选择其他计算目标类型,例如 Azure Vm,甚至是本地计算机。
- entry_script是训练模型的脚本的相对路径。
- Azure机器学习每次训练模型时都会创建docker容器来执行具体的计算,environment_definition表示创建docker容器时需要的镜像文件,该镜像文件定义了试验运行的Python环境等信息。
七、提交试验
运行以下代码将试验提交到云上进行计算:
run = experiment.submit(estimator)可以从studio中查看试验运行状态,每次运行都会生成一个运行id。
一次试验可能有很多次运行(run),通过以下代码可以查看试验的每次运行 ID:
list_runs = experiment.get_runs()
for run in list_runs:
print(run.id)
图5 试验运行正在启动
点击此次运行id,能够看到:
- 此次运行的详细信息:运行状态、计算目标、运行id等。
- 指标:模型的参数和评价指标。
- 输出+日志:可以看到训练的输出文件和日志文件,包括docker镜像的创建日志、模型训练日志和报错信息等。

图6 试验运行详细信息
提交试验后,试验会进入“正在准备”状态,此阶段主要是docker镜像的创建。准备完成后,训练进入“已排队”状态。这是因为我们上面将计算集群的min_nodes设置为0,此时计算集群中没有节点在运行。计算集群接收到试验任务后,会逐渐启动试验所需要的计算节点,如下图所示:

图7 计算节点正在启动
计算节点启动成功后运行试验任务:

图8 计算节点正在运行
八、监控试验运行状态
我们既可以在像上面一样在studio中监控试验运行,也可以通过代码来查看试验运行状态。
使用以下代码可以在Jupyter widget中每隔10到15秒钟更新一次试验运行状态。
from azureml.widgets import RunDetails
RunDetails(run).show(show_output=True)使用wait_for_completion来打印试验运行日志信息:
# specify show_output to True for a verbose log
run.wait_for_completion(show_output=True) 
图9 通过代码来查看试验运行状态
查看模型度量值:
run.get_metrics()输出:
{'Kernel type': 'linear', 'Penalty': 1.0, 'Accuracy': 0.9736842105263158}九、下载结果文件到本地
你可以在studio上查看和下载模型的日志文件和输出文件:

图10 试验的输出和日志文件
也可以使用代码查看和下载以上文件:
# 列出与运行关联的文件。
results=run.get_file_names()
print(results)输出:
['azureml-logs/20_image_build_log.txt',
'azureml-logs/55_azureml-execution-tvmps_5d3bd6fb3f0ce51a329072c77079624c7f9603f03ff6433284889b08a2756847_d.txt',
'azureml-logs/65_job_prep-tvmps_5d3bd6fb3f0ce51a329072c77079624c7f9603f03ff6433284889b08a2756847_d.txt',
'azureml-logs/70_driver_log.txt',
'azureml-logs/75_job_post-tvmps_5d3bd6fb3f0ce51a329072c77079624c7f9603f03ff6433284889b08a2756847_d.txt',
'azureml-logs/process_info.json',
'azureml-logs/process_status.json',
'logs/azureml/138_azureml.log',
'logs/azureml/job_prep_azureml.log',
'logs/azureml/job_release_azureml.log',
'outputs/model.joblib']下载上面outputs文件下的所有文件到本地目录:
for file in results:
if file.startswith('outputs'):
run.download_files(prefix='outputs', output_directory='./outputs/')prefix表示需要下载的文件夹,output_directory是本地文件夹。
更多Run相关的用法请参考Run class。
十、总结
本节使用Azure机器学习创建了一个SVM模型,演示了Azure机器学习训练模型的一般步骤。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









