







为什么使用ConcurrentHashMap
JDK7多线程下对HashMap添加数据时,如果满足扩容条件进行扩容时,此时会产生并发死链问题,(采用头插法的原因)
JDK8多线程环境下能安全扩容,但也会有数据丢失的问题
ConcurrentHashMap 的实现原理(JDK1.7)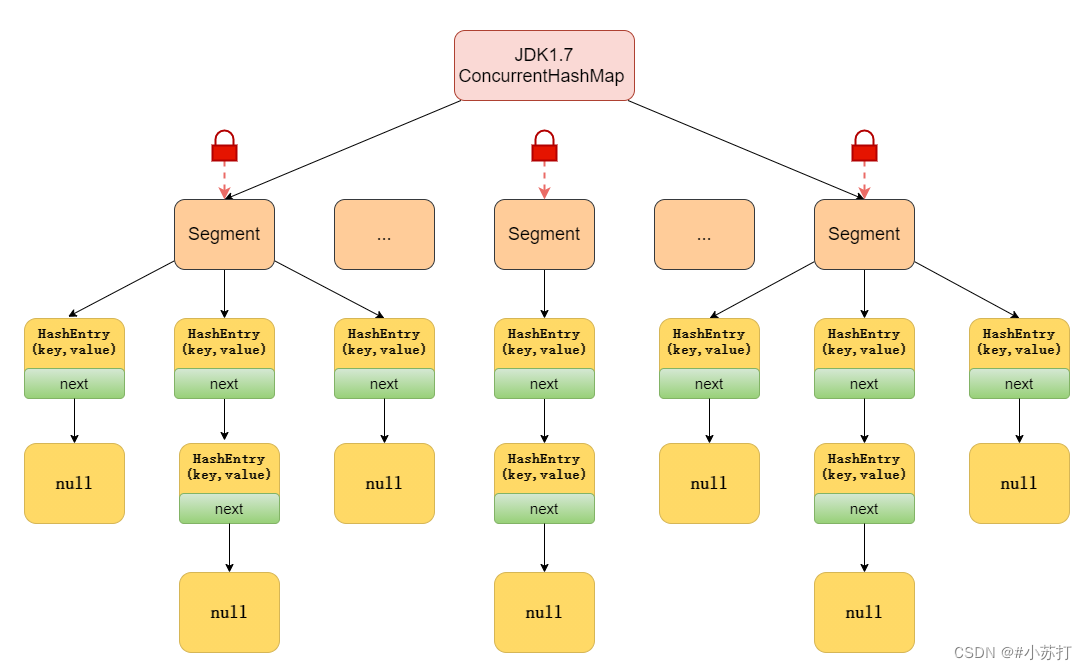
JDK1.7 中的 ConcurrentHashMap 是由 Segment 数组结构和 HashEntry 数组结构组成,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),同时对Segment加锁,每个小数组有 n 个 HashEntry 组成,
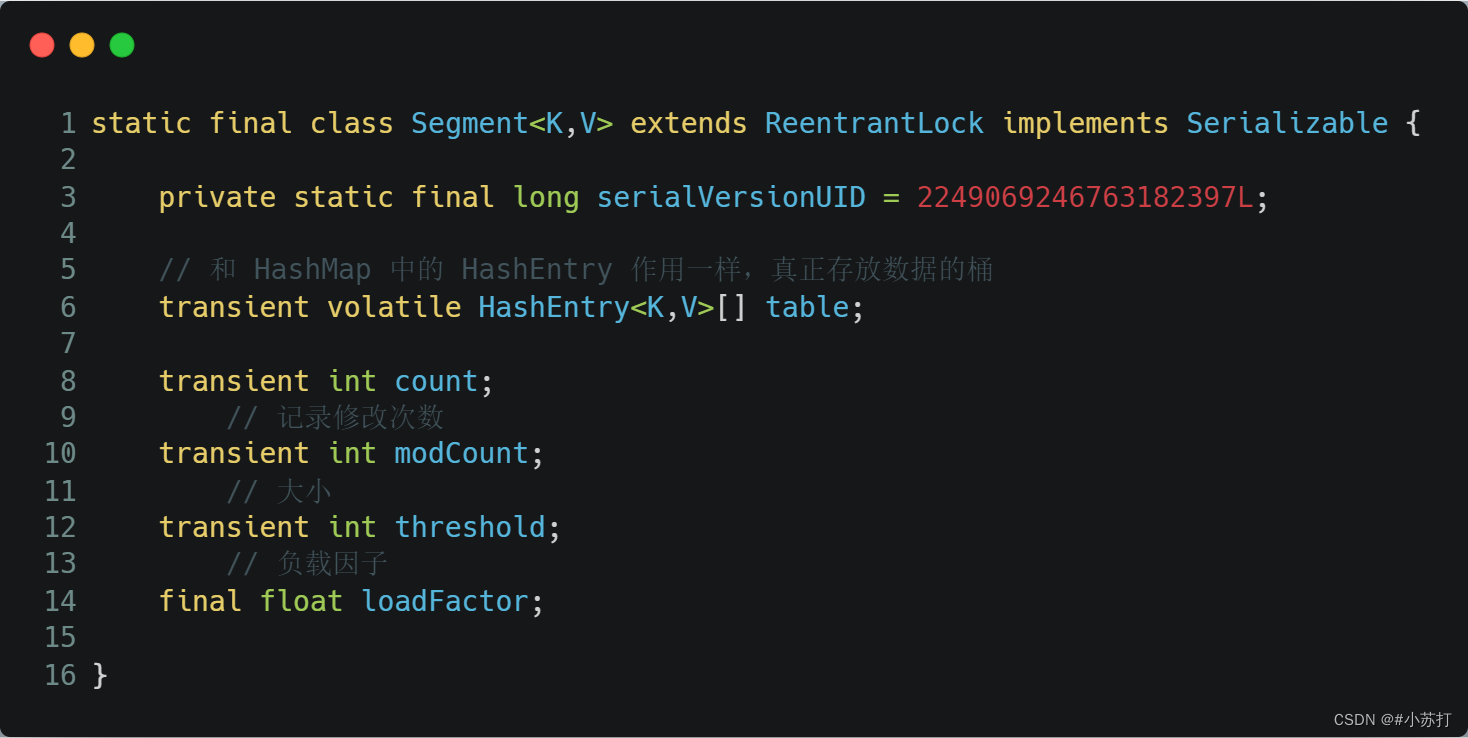
Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下:
Segment 继承了 ReentrantLock,所以 Segment 是一种可重入锁,扮演锁的角色。Segment 默认为 16,也就是并发度为 16。

存放元素的 HashEntry,也是一个静态内部类,主要的组成如下:
其中,用 volatile 修饰了 HashEntry 的数据 value 和 下一个节点 next,保证了多线程环境下数据获取时的可见性!
ConcurrentHashMap 的实现原理(JDK1.8)
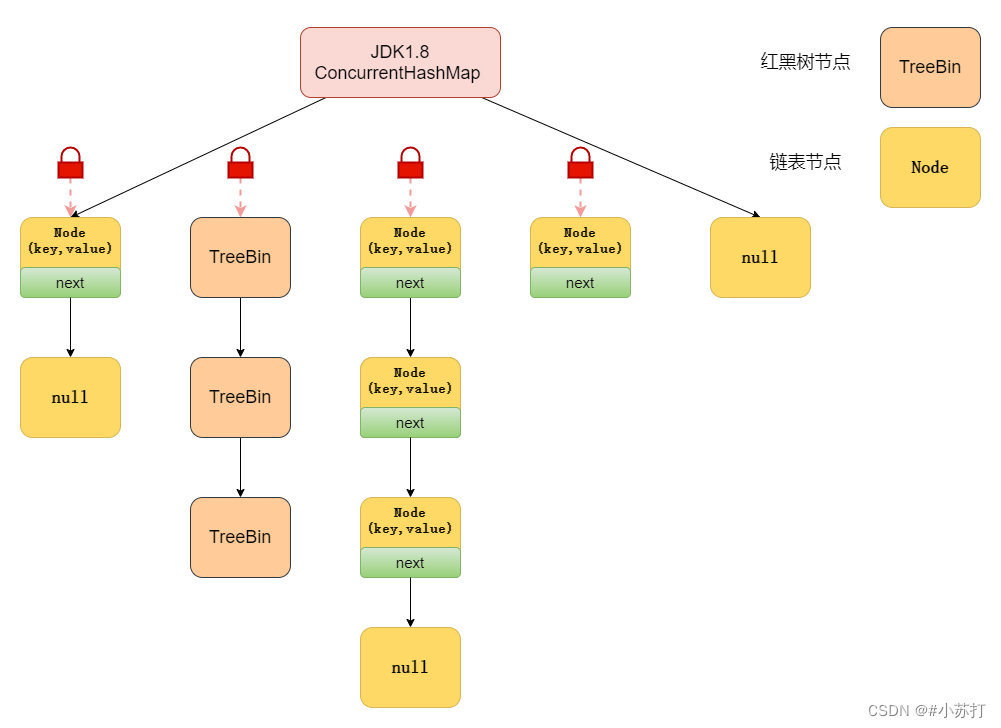
在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的Node数组+链表+红黑树结构;在锁的实现上,采用CAS
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4827
4827

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









