






接上篇 Python 文件的读写
一、文件的序列化
上篇提到,f.write()函数只能将字符串(str)类型写入文件,但其他类型例如列表、字典等无法写入,需要提前转换再写入文件。一般不能直接用str强制转换数据类型,会导致数据的改变及不匹配等问题。
按照某种规则,把内存中的数据转换为字节序列,保存到文件中,就称作文件的序列化。Python提供了JSON模块来实现数据的序列化和反序列化。
序列化的两种方式:
- json.dumps()
import json
f = open("test.txt", "w")
list = ["zhangsan", "lisi", "wangwu"]
names = json.dumps(list)
f.write(names)
f.close()
- json.dump()
在将对象转换为字符串的同时,制定一个文件的对象,然后把转换后的字符串写入到改文件里。
import json
f = open("test.txt", "w")
list = ["zhangsan", "lisi", "wangwu"]
json.dump(list, f)
f.close()
二、反序列化
将json的字符串转化为一个python对象
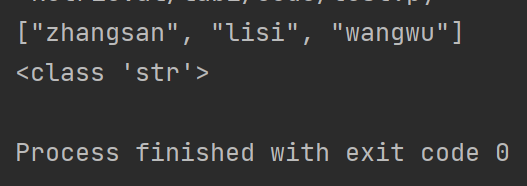
首先测试一下直接读取可不可以。
f = open("test.txt", "r")
content = f.read()
print(content)
print(type(content))
f.close()
可以看到虽然读取成功,但类型是str。但我们知道我们需要读取的应该是一个列表类型,所以需要反序列化。
反序列化的两种方式:
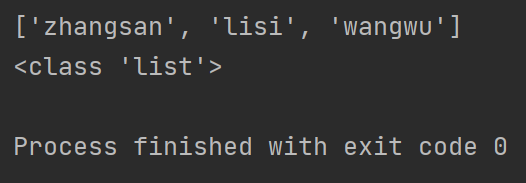
- json.loads()
import json
f = open("test.txt", "r")
content = f.read()
result = json.loads(content) # 将json字符串转化为python对象
print(result)
print(type(result))
f.close()
类型成功转换为了list
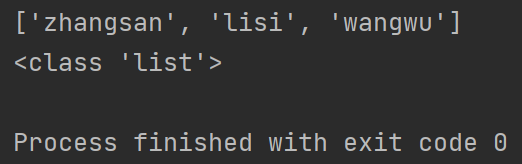
- json.load()
import json
f = open("test.txt", "r")
result = json.load(f) # 直接转换文件
print(result)
print(type(result))
f.close()
结果同样是list
总结
一般序列化用的比较多,用的最多的是json.dumps()
















 189
189











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











