







论文解读:ACT-SQL: In-Context Learning for Text-to-SQL with Automatically-Generated Chain
1.主要贡献
论文主要提出ACT-SQL:自动根据问题和sql答案来构造从问题到答案的CoT(思考链),由于绝大多数开源数据集都不含CoT数据,但是CoT方法被证明可以有效指导模型理解原始问题,并按实例所示思考,可以有效的提升text2sql任务的准确率。
2.方法论:模式链接
1.链接列名和问题切片
在一个具体的数据样本中,给定问题 q = (q1, q2, ··· , q|q|) 和 SQL 查询 s,qi 表示问题句子中的第 i 个token。作者将 qi,j = (qi, qi+1, · · · , qj) 定义为原始问题的一个切片。作者首先枚举SQL查询s中出现的每一列[tab].[col],其中[tab]代表表名,[col]代表列名。对于每一列,作者使用合适的预训练模型来计算当前列和所有问题句切片之间的相似度得分。最相关的切片是:
arg
max
q
i
,
j
Sim
(
[
tab
]
.
[
col
]
,
q
i
,
j
)
\arg\max_{q_{i,j}} \text{Sim}([\text{tab}].[\text{col}], q_{i,j})
argqi,jmaxSim([tab].[col],qi,j)
其中 Sim 是相似度函数。
2.链接表名和问题切片
其次,作者枚举SQL查询中出现的每个表[tab]时,作者去除了列中出现的表,因为这些表在上个过程已添加到自动 CoT 提示中。对于每个表,作者还计算所有相似度分数并找出最相关的问题切片,即
arg
max
q
i
,
j
Sim
(
[
tab
]
,
q
i
,
j
)
\arg\max_{q_{i,j}} \text{Sim}([\text{tab}], q_{i,j})
argqi,jmaxSim([tab],qi,j)
链接该表及其最相关的问题切片,并将它们添加到自动 CoT 中。
3.链接结果和OpenAI官方推荐模版组合
把上面两步中,列名和原问题最相关的切片、表面和最相关的切片添加到CoT模版中,结果如下:

3.其他要点
1.实例如何选取(Exemplar Selection)
作者使用混合策略选择样本。具体来说,作者首先从训练数据集中随机选择 ns 个示例。这些数据集示例被称为静态示例。它们将在每个测试用例的上下文中使用。
对于每个特定的测试用例,作者从训练数据集再选nd个示例,这些数据集示例被称为动态示例,因为它们是根据当前测试用例的某些特征选择的。作者将当前测试用例的自然语言问题与训练数据集中的所有问题进行比较,使用合适的预训练模型计算相似度分数,然后选择排名靠前的训练数据集示例。
因此,每个测试用例总共有 ns + nd 个示例。
4.实验
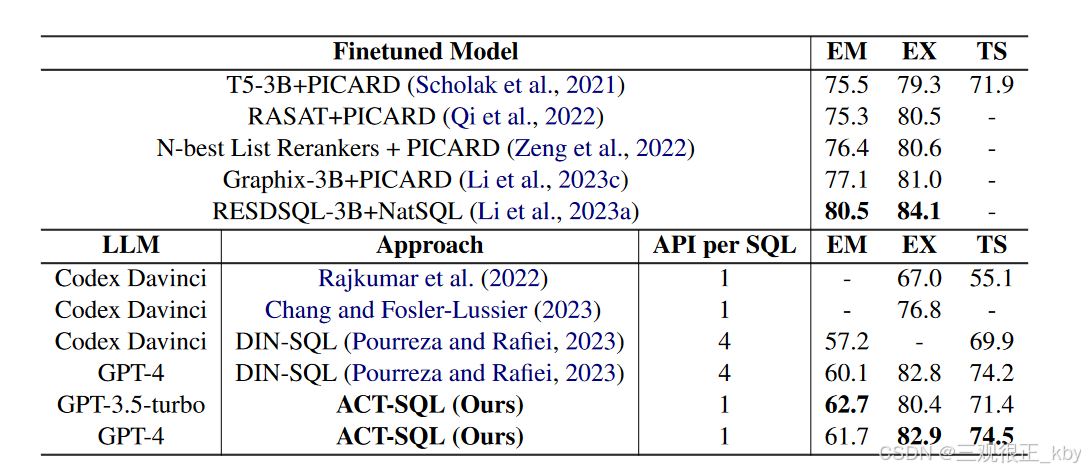
在spider数据集的测试集上面取得了SOTA表现,超过了所有的prompt 模型,也可以与微调模型媲美。但是在其他数据集上表现一般,在多轮对话中表现稍差。


















 1891
1891

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









