






Apache Durid (HDFS 集群部署)
Apache Durid (HDFS 集群部署)
1. 分布式文件HDFS
1.1 HDFS简介
HDFS(Hadoop Distributed File System)是 Apache Hadoop 项目的一个子项目,它的设计初衷是为了能够支持高吞吐和超大文件读写操作
HDFS 源于 Google 在2003年10月份发表的GFS(Google File System)论文,HDFS(HadoopDistributed Filesystem)是一个易于扩展的分布式文件系统,运行在成百上千台低成本的机器上。
HDFS是一种能够在普通硬件上运行的分布式文件系统,它是高度容错的,适应于具有大数据集的应用程序,它非常适于存储大型数据 (比如 TB 和 PB)
HDFS使用多台计算机存储文件, 并且提供统一的访问接口, 像是访问一个普通文件系统一样使用分布式文件系统
1.1.1 HDFS发展历史
- Doug Cutting 在做 Lucene 的时候, 需要编写一个爬虫服务, 这个爬虫写的并不顺利, 遇到 了一些问题, 诸如: 如何存储大规模的数据, 如何保证集群的可伸缩性, 如何动态容错等
- 2013年的时候, Google 发布了三篇论文, 被称作为三驾马车, 其中有一篇叫做 GFS
- GFS是描述了 Google 内部的一个叫做 GFS 的分布式大规模文件系统, 具有强大的可伸缩性和容错
- Doug Cutting后来根据 GFS 的论文, 创造了一个新的文件系统, 叫做 HDFS
1.1.2 HDFS设计目标
- HDFS集群由很多的服务器组成,而每一个机器都与可能会出现故障。HDFS为了能够进行故障检测、快速恢复等。
- HDFS主要适合去做批量数据出来,相对于数据请求时的反应时间,HDFS更倾向于保障吞吐量。
- 典型的HDFS中的文件大小是GB到TB,HDFS比较适合存储大文件
- HDFS很多时候是以: Write-One-Read-Many来应用的,一旦在HDFS创建一个文件,写入完后就不需要修改了
1.2 HDFS应用场景
1.2.1 适合的应用场景
- 存储非常大的文件:这里非常大指的是几百M、G、或者TB级别,需要高吞吐量,对延时没有要求。
- 基于流的数据访问方式: 即一次写入、多次读取,数据集经常从数据源生成或者拷贝一次,然后在其上做很多分析工作 ,且不支持文件的随机修改。
- 正因为如此,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
- 运行于商业硬件上: Hadoop不需要特别贵的机器,可运行于普通廉价机器,可以处节约成本需要高容错性
- 为数据存储提供所需的扩展能力
1.2.2 不适合的应用场景
- 低延时的数据访问 对延时要求在毫秒级别的应用,不适合采用HDFS。HDFS是为高吞吐数据传输设计的,因此可能牺牲延时
- 大量小文件的元数据保存在NameNode的内存中, 整个文件系统的文件数量会受限于NameNode的内存大小。经验而言,一个文件/目录/文件块一般占有150字节的元数据内存空间。如果有100万个文件,每个文件占用1个文件块,则需要大约300M的内存。因此十亿级别的文件数量在现有商用机器上难以支持
- 多方读写,需要任意的文件修改HDFS采用追加(append-only)的方式写入数据。不支持文件任意offset的修改,HDFS适合用来做大数据分析的底层存储服务,并不适合用来做.网盘等应用,因为,修改不方便,延迟大,网络开销大,成本太高。
2. HDFS架构原理
2.1 HDFS架构剖析
2.1.1 HDFS整体概述
HDFS是Hadoop Distribute File System 的简称,意为:Hadoop分布式文件系统。
是Hadoop核心组件之一,作为大数据生态圈最底层的分布式存储服务而存在。HDFS解决的问题就是大数据如何存储,它是横跨在多台计算机上的文件存储系统并且具有高度的容错能力。
HDFS集群遵循主从架构。每个群集包括一个主节点和多个从节点。在内部,文件分为一个或多个块,每个块根据复制因子存储在不同的从节点计算机上。主节点存储和管理文件系统名称空间,即有关文件块的信息,例如块位置,权限等。从节点存储文件的数据块。主从各司其职,互相配合,共同对外提供分布式文件存储服务。当然内部细节对于用户来说是透明的。

2.2.2 角色介绍
2.2.2.1 概述
HDFS遵循主从架构。每个群集包括一个主节点和多个从节点
NameNode是主节点,负责存储和管理文件系统元数据信息,包括namespace目录结构、文件块位置信息等;
DataNode是从节点,负责存储文件具体的数据块,两种角色各司其职,共同协调完成分布式的文件存储服务。
SecondaryNameNode是主角色的辅助角色,帮助主角色进行元数据的合并。

2.2.2.2 Namenode
NameNode是Hadoop分布式文件系统的核心,架构中的主角色。
它维护和管理文件系统元数据,包括名称空间目录树结构、文件和块的位置信息、访问权限等信息。基于此,NameNode成为了访问HDFS的唯一入口。
内部通过内存和磁盘两种方式管理元数据。其中磁盘上的元数据文件包括Fsimage内存元数据镜像文件和edits log(Journal)编辑日志。
在Hadoop2之前,NameNode是单点故障。Hadoop 2中引入的高可用性。Hadoop群集体系结构允许在群集中以热备配置运行两个或多个NameNode。

2.2.2.3 Datanode
DataNode是Hadoop HDFS中的从角色,负责具体的数据块存储。
DataNode的数量决定了HDFS集群的整体数据存储能力。通过和NameNode配合维护着数据块。

2.2.2.4 Secondarynamenode
除了DataNode和NameNode之外,还有另一个守护进程,它称为secondary NameNode。充当NameNode的辅助节点,但不能替代NameNode。 当NameNode启动时,NameNode合并Fsimage和edits log文件以还原当前文件系统名称空间。如果edits log过大不利于加载,Secondary NameNode就辅助NameNode从NameNode下载Fsimage文件和editslog文件进行合并。
2.3 HDFS重要特性
2.3.1 主从架构
HDFS采用master/slave架构。一般一个HDFS集群是有一个Namenode和一定数目的Datanode组成。
Namenode是HDFS主节点,Datanode是HDFS从节点,两种角色各司其职,共同协调完成分布式的文件存储服务。

2.3.2 分块机制
HDFS中的文件在物理上是分块存储(block)的,块的大小可以通过配置参数来规定,参数位于hdfs-default.xml中:dfs.blocksize。默认大小是128M(134217728)。

2.3.3 副本机制
为了容错,文件的所有block都会有副本。
每个文件的block大小(dfs.blocksize)和副本系数(dfs.replication)都是可配置的。应用程序可以指定某个文件的副本数目。副本系数可以在文件创建的时候指定,也可以在之后通过命令改变。
默认dfs.replication的值是3,也就是会额外再复制2份,连同本身总共3份副本。

2.3.4 Namespace
HDFS支持传统的层次型文件组织结构。用户可以创建目录,然后将文件保存在这些目录里
文件系统名字空间的层次结构和大多数现有的文件系统类似:用户可以创建、删除、移动或重命名文件。
Namenode负责维护文件系统的namespace名称空间,任何对文件系统名称空间或属性的修改都将
被Namenode记录下来。
HDFS会给客户端提供一个统一的抽象目录树,客户端通过路径来访问文件,形如:hdfs://namenode:port/dir-a/dir-b/dir-c/file.data。
2.3.5 元数据管理
在HDFS中,Namenode管理的元数据具有两种类型:
文件自身属性信息
文件名称、权限,修改时间,文件大小,复制因子,数据块大小。
文件块位置映射信息
记录文件块和DataNode之间的映射信息,即哪个块位于哪个节点上。
2.3.6 数据块存储
文件的各个block的具体存储管理由DataNode节点承担。每一个block都可以在多个DataNode上存储。

3. HDFS Web Interfaces
3.1 Web Interfaces介绍
除了命令行界面之外,Hadoop还为HDFS提供了Web用户界面。
用户可以通过Web界面操作文件系统并且获取和HDFS相关的状态属性信息。
HDFS Web地址是 http://IP:port/ ,默认端口号9870。

3.2 模块功能解读
Overview
Overview是总揽模块,默认的主页面。展示了HDFS一些最核心的信息。

Summary

NameNode Journal Status

** NameNode Storage**

DFS Storage Types

Datanodes
Datanodes模块主要记录了HDFS集群中各个DataNode的相关状态信息。

Datanode Volume Failures
此模块记录了DataNode卷故障信息。

Snapshot
Snapshot模块记录HDFS文件系统的快照相关信息,包括哪些文件夹创建了快照和总共有哪些快照。

Satartup progress
Startup Progress模块记录了HDFS集群启动的过程信息,执行步骤和每一步所做的事和用时。

3.3Utilities
Utilities模块算是用户使用最多的模块了,里面包括了文件浏览、日志查看、配置信息查看等核心功能。

Browse the file system
该模块可以说是我们在开发使用HDFS过程中使用最多的模块了,提供了一种Web页面浏览操作文件系统的能力,在某些场合下,比使用命令操作更加直观方便。

Logs、LogLevel


Configruation
该模块可以列出当前集群成功加载的所谓配置文件属性,可以从这里来进行判断用户所设置的参数属性是否成功加载生效,如果此处没有,需要检查配置文件或者重启集群加载。

4. HDFS读写流程
因为namenode维护管理了文件系统的元数据信息,这就造成了不管是读还是写数据都是基于NameNode开始的,也就是说NameNode成为了HDFS访问的唯一入口。入口地址是:http://nn_host:8020。
4.1 写数据流程

4.1.1 写入方式

4.1.1.1 管道传输
Pipeline,中文翻译为管道,这是HDFS在上传文件写数据过程中采用的一种数据传输方式。
客户端将数据块写入第一个数据节点,第一个数据节点保存数据之后再将块复制到第二个数据节点,后者保存后将其复制到第三个数据节点。通俗描述pipeline的过程就是:Client->A->B->C
为什么datanode之间采用pipeline线性传输,而不是一次给三个datanode拓扑式传输呢?因为数据以管道的方式,顺序的沿着一个方向传输,这样能够充分利用每个机器的带宽,避免网络瓶颈和高延迟时的连接,最小化推送所有数据的延时。
在线性推送模式下,每台机器所有的出口宽带都用于以最快的速度传输数据,而不是在多个接受者之间分配宽带。
4.1.1.2 ACK确认
ACK (Acknowledge character)即是确认字符,在数据通信中,接收方发给发送方的一种传输类控制字符。表示发来的数据已确认接收无误。在pipeline管道传输数据的过程中,传输的反方向会进行ACK校验,确保数据传输安全。
4.1.2 具体流程
- HDFS客户端通过对DistributedFileSystem 对象调用create()请求创建文件。
- DistributedFileSystem对namenode进行RPC调用,请求上传文件。namenode执行各种检查判断:目标文件是否存在、父目录是否存在、客户端是否具有创建该文件的权限。检查通过,namenode就会为创建新文件记录一条记录。否则,文件创建失败并向客户端抛出一个IOException。
- DistributedFileSystem为客户端返回FSDataOutputStream输出流对象。由此客户端可以开始写入数据。FSDataOutputStream是一个包装类,所包装的是DFSOutputStream。
- 在客户端写入数据时,DFSOutputStream将它分成一个个数据包(packet 默认64kb),并写入一个称之为数据队列(data queue)的内部队列。DFSOutputStream有一个内部类做DataStreamer,用于请求NameNode挑选出适合存储数据副本的一组DataNode。这一组DataNode采用pipeline机制做数据的发送。默认是3副本存储。
- DataStreamer将数据包流式传输到pipeline的第一个datanode,该DataNode存储数据包并将它发送到pipeline的第二个DataNode。同样,第二个DataNode存储数据包并且发送给第三个(也是最后一个)DataNode。
- DFSOutputStream也维护着一个内部数据包队列来等待DataNode的收到确认回执,称之为确认队列(ack queue),收到pipeline中所有DataNode确认信息后,该数据包才会从确认队列删除。
- 客户端完成数据写入后,将在流上调用close()方法关闭。该操作将剩余的所有数据包写入DataNode pipeline,并在联系到NameNode告知其文件写入完成之前,等待确认。
- 因为namenode已经知道文件由哪些块组成(DataStream请求分配数据块),因此它仅需等待最小复制块即可成功返回。
- 数据块最小复制是由参数dfs.namenode.replication.min指定,默认是1.
4.1.3 默认3副本存储策略
默认副本存储策略是由BlockPlacementPolicyDefault指定。策略如下:

- 第一块副本:优先客户端本地,否则随机
- 第二块副本:不同于第一块副本的不同机架。
- 第三块副本:第二块副本相同机架不同机器。
4.2 读数据流程

4.2.1 具体流程
- 客户端通过调用DistributedFileSystem对象上的open()来打开希望读取的文件。
- DistributedFileSystem使用RPC调用namenode来确定文件中前几个块的块位置。对于每个块,namenode返回具有该块副本的datanode的地址,并且datanode根据块与客户端的距离进行排序。注意此距离指的是网络拓扑中的距离。比如客户端的本身就是一个DataNode,那么从本地读取数据明显比跨网络读取数据效率要高。
- DistributedFileSystem将FSDataInputStream(支持文件seek定位读的输入流)返回到客户端以供其读取数据。FSDataInputStream类转而封装为DFSInputStream类,DFSInputStream管理着datanode和namenode之间的IO。
- 客户端在流上调用read()方法。然后,已存储着文件前几个块DataNode地址的DFSInputStream随即连接到文件中第一个块的最近的DataNode节点。通过对数据流反复调用read()方法,可以将数据从DataNode传输到客户端。
- 当该块快要读取结束时,DFSInputStream将关闭与该DataNode的连接,然后寻找下一个块的最佳datanode。这些操作对用户来说是透明的。所以用户感觉起来它一直在读取一个连续的流。
- 客户端从流中读取数据时,块是按照打开DFSInputStream与DataNode新建连接的顺序读取的。它也会根据需要询问NameNode来检索下一批数据块的DataNode位置信息。一旦客户端完成读取,就对FSDataInputStream调用close()方法。
- 如果DFSInputStream与DataNode通信时遇到错误,它将尝试该块的下一个最接近的DataNode读取数据。并将记住发生故障的DataNode,保证以后不会反复读取该DataNode后续的块。此外,DFSInputStream也会通过校验和(checksum)确认从DataNode发来的数据是否完整。如果发现有损坏的块,DFSInputStream会尝试从其他DataNode读取该块的副本,也会将被损坏的块报告给namenode 。
4.3 角色职责概述
4.3.1 Namenode职责
- NameNode是HDFS的核心,集群的主角色,被称为Master。
- NameNode仅存储管理HDFS的元数据:文件系统namespace操作维护目录树,文件和块的位置信息。
- NameNode不存储实际数据或数据集。数据本身实际存储在DataNodes中。
- NameNode知道HDFS中任何给定文件的块列表及其位置。使用此信息NameNode知道如何从块中构建文件。
- NameNode并不持久化存储每个文件中各个块所在的DataNode的位置信息,这些信息会在系统启动时从DataNode汇报中重建。
- NameNode对于HDFS至关重要,当NameNode关闭时,HDFS / Hadoop集群无法访问。
- NameNode是Hadoop集群中的单点故障。
- NameNode所在机器通常会配置有大量内存(RAM)。
4.3.2 Datanode职责
- DataNode负责将实际数据存储在HDFS中。是集群的从角色,被称为Slave。
- DataNode启动时,它将自己发布到NameNode并汇报自己负责持有的块列表。
- 根据NameNode的指令,执行块的创建、复制、删除操作。
- DataNode会定期(dfs.heartbeat.interval配置项配置,默认是3秒)向NameNode发送心跳,如果NameNode长时间没有接受到DataNode发送的心跳, NameNode就会认为该DataNode失效。
- DataNode会定期向NameNode进行自己持有的数据块信息汇报,汇报时间间隔取参数dfs.blockreport.intervalMsec,参数未配置的话默认为6小时.
- DataNode所在机器通常配置有大量的硬盘空间。因为实际数据存储在DataNode中。
5. HDFS基准测试
实际生产环境当中,hadoop的环境搭建完成之后,第一件事情就是进行压力测试,测试Hadoop集群的读取和写入速度,测试网络带宽是否足够等一些基准测试。
5.1 测试写入速度
向HDFS文件系统中写入数据,10个文件,每个文件10MB,文件存放到/benchmarks/TestDFSIO中
5.1.1 执行测试命令
hadoop jar /usr/local/hadoop/hadoop-3.2.2/share/hadoop/mapreduce/hadoop- mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -write -nrFiles 10 - fileSize 10MB

5.1.2 查看监控
我们可以看到Hadoop启动了一个MapReduce作业来运行benchmark测试
http://192.168.64.174:8088/

查看写入速度

我们看到目前在虚拟机上的IO吞吐量约为:0.1MB/s
5.2 测试读取速度
测试hdfs的读取文件性能,在HDFS文件系统中读入10个文件,每个文件10M
5.2.1 执行命令
hadoop jar /usr/local/hadoop/hadoop-3.2.2/share/hadoop/mapreduce/hadoop- mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -read -nrFiles 10 - fileSize 10MB

5.2.2 查看监控
同样,Hadoop也会启动一个MapReduce程序来进行测试。
http://192.168.64.174:8088/

** 查看读取速度**

我们看到目前在虚拟机上的IO吞吐量约为:4.26MB/s
5.3 清除测试数据
测试期间,会在HDFS集群上创建 /benchmarks目录,测试完毕后,我们可以清理该目录。
5.3.1 查看benchmarks
hdfs dfs -ls -R /benchmarks

5.3.2 执行清理
hadoop jar /usr/local/hadoop/hadoop-3.2.2/share/hadoop/mapreduce/hadoop- mapreduce-client-jobclient-3.2.2-tests.jar TestDFSIO -clean

查看benchmarks
删除命令会将 /benchmarks目录中内容删除
hdfs dfs -ls -R /benchmarks

6. 准备工作
6.1 JDK安装
参考上文JDK安装
6.2 ZK集群搭建
6.2.1 下载zk安装包
下载zk安装包
wget -P /usr/local/zookeeper https://mirrors.bfsu.edu.cn/apache/zookeeper/zookeeper-3.7.0/apache-zookeeper- 3.7.0-bin.tar.gz
解压文件
tar -zxvf apache-zookeeper-3.7.0-bin.tar.gz
创建目录
在zk包下新建data、logs目录
cd /usr/local/zookeeper/apache-zookeeper-3.7.0-bin
mkdir {data,logs}
配置hosts映射
以配置可以忽略
vi /etc/hosts
192.168.64.174 hadoop01
192.168.64.175 hadoop02
192.168.64.176 hadoop03
修改zk配置文件
cd /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/conf
# 复制一份zoo.cfg
cp zoo_sample.cfg zoo.cfg
# 编辑zoo.cfg
vi zoo.cfg
编辑 zoo.cfg,并配置以下内容
dataDir=/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/data
dataLogDir=/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/logs
server.1=hadoop01:2881:3881
server.2=hadoop02:2881:3881
server.3=hadoop03:2881:3881
复制到其他机器
使用scp命令将配置好的zk复制到其他机器
scp -r /usr/local/zookeeper root@192.168.64.175:/usr/local/
scp -r /usr/local/zookeeper root@192.168.64.176:/usr/local/
配置myid
到三台服务器配置不同的myid
** hadoop01配置**
echo 1 > /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/data/myid
hadoop02配置
echo 2 > /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/data/myid
hadoop03配置
echo 3 > /usr/local/zookeeper/apache-zookeeper-3.7.0-bin/data/myid
启动zk
三台机器都需要启动
/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh start
/usr/local/zookeeper/apache-zookeeper-3.7.0-bin/bin/zkServer.sh status

安装prel环境
yum install perl gcc kernel-devel
7. 集群搭建
7.1 下载发行版
首先,下载并解压缩发布安装包。最好首先在单台计算机上执行此操作,因为您将编辑配置,然后将修改后的配置分发到所有服务器上。
7.1.1 查找安装包
可以到 Apache Durid 官网下载最新的安装包


在新的下载源中,复制下载连接,在linux中使用 wget 命令下载

下载安装包
wget -P /usr/local/druid https://mirrors.bfsu.edu.cn/apache/druid/0.21.1/apache- druid-0.21.1-bin.tar.gz
解压安装包
tar -zxvf apache-druid-0.21.0-bin.tar.gz
** 查看目录文件**
cd apache-druid-0.21.0
ll
在安装包中有以下文件
- LICENSE 和 NOTICE 文件
- bin/* - 启停等脚本
- conf/druid/cluster/* - 用于集群部署的模板配置
- extensions/* - Druid核心扩展
- hadoop-dependencies/* - Druid Hadoop依赖
- lib/* - Druid核心库和依赖
- quickstart/* - 与快速入门相关的文件
我们主要是编辑 conf/druid/cluster/ 中的文件
7.2 配置数据存储
公共配置在conf/druid/_common,我们需要编辑common.runtime.properties文件 ,下面主要是我们修改的重要配置,其它配置保留默认即可:
找到配置文件
vi /usr/local/druid/apache-druid-
0.21.0/conf/druid/cluster/_common/common.runtime.properties
配置启动扩展
配置两个启动加载的扩展。一个是HDFS存储,一个是MySQL元数据 ,一个是kafka的服务
druid.extensions.loadList=["druid-hdfs-storage","mysql-metadata-storage","druid- kafka-indexing-service"]
配置MySQL驱动
wget https://dev.mysql.**加粗样式**com/get/Downloads/Connector-J/mysql-connector-java-
5.1.46.tar.gz
tar -zxf mysql-connector-java-5.1.46.tar.gz
cd mysql-connector-java-5.1.46/
mv mysql-connector-java-5.1.46-bin.jar /usr/local/druid/apache-druid-
0.21.0/extensions/mysql-metadata-storage/
配置Zookeeper地址
druid.zk.service.host=hadoop01:2181,hadoop02:2181,hadoop03:2181
druid.zk.paths.base=/druid
配置 Metastore存储信息
元数据存储是Apache Druid的一个外部依赖。Druid使用它来存储系统的各种元数据,但不存储实
际的数据。下面有许多用于各种目的的表。
Derby是Druid的默认元数据存储,但是它不适合生产环境。MySQL和PostgreSQL是更适合生产的
元数据存储
初始化MySQL
注意:mysql需要提前安装好,并且数据库druid要提前创建好并且指定utf-8编码;
-- create a druid database, make sure to use utf8mb4 as encoding
CREATE DATABASE druid DEFAULT CHARACTER SET utf8 COLLATE utf8_general_ci;
-- create a druid user
CREATE USER 'druid'@'%' IDENTIFIED BY 'diurd';
-- grant the user all the permissions on the database we just created
GRANT ALL PRIVILEGES ON druid.* TO 'druid'@'%';
配置Metastore
# For MySQL (make sure to include the MySQL JDBC driver on the classpath):
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://172.16.44.47:3306/druid
?characterencoding=utf-8
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=druid
配置深度存储
Apache Druid不提供的存储机制,深度存储是存储段的地方。
深度存储基础结构定义了数据的持久性级别,只要Druid进程能够看到这个存储基础结构并获得存
储在上面的段,那么无论丢失多少Druid节点,都不会丢失数据。如果段在深度存储层消失了,则这些段
中存储的任何数据都将丢失。
本地挂载
本地装载也可用于存储段。这使得您可以使用本地文件系统或任何可以在本地挂载的东西,如
NFS、Ceph等来存储段。这是默认的深度存储实现。
配置文件配置
druid.storage.type=hdfs
druid.storage.storageDirectory=hdfs://hadoop01:9000/druid/segments
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=hdfs://hadoop01:9000/druid/indexing-logs
复制hadoop文件
因为我们会使用到hdfs作为底层存储所以我们需要告知druid hadoop集群的相关信息,所以我们
需要把hadoop相关的配置文件复制到conf/druid/_common/目录中,需要用到 hdfs-site.xml,
core-site.xml,mapred-site.xml,yarn-site.xml四个配置文件
\cp -f /usr/local/hadoop/hadoop-3.2.2/etc/hadoop/core-site.xml ./
\cp -f /usr/local/hadoop/hadoop-3.2.2/etc/hadoop/mapred-site.xml ./
\cp -f /usr/local/hadoop/hadoop-3.2.2/etc/hadoop/hdfs-site.xml ./
\cp -f /usr/local/hadoop/hadoop-3.2.2/etc/hadoop/yarn-site.xml ./

** 完整配置**
druid.extensions.loadList=["druid-hdfs-storage","mysql-metadata-storage",druid-
kafka-indexing-service]
#
# Hostname
#
druid.host=localhost
#
# Logging
#
# Log all runtime properties on startup. Disable to avoid logging properties on
startup:
druid.startup.logging.logProperties=true
#
# Zookeeper
#
#druid.zk.service.host=localhost
#druid.zk.paths.base=/druid
druid.zk.service.host=hadoop01:2181,hadoop02:2181,hadoop03:2181
druid.zk.paths.base=/druid
#
# Metadata storage
#
# For Derby server on your Druid Coordinator (only viable in a cluster with a
single Coordinator, no fail-over):
#druid.metadata.storage.type=derby
#druid.metadata.storage.connector.connectURI=jdbc:derby://localhost:1527/var/dru
id/metadata.db;create=true
#druid.metadata.storage.connector.host=localhost
druid.metadata.storage.connector.port=1527
# For MySQL (make sure to include the MySQL JDBC driver on the classpath):
druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://172.16.44.47:3306/druid
?characterencoding=utf-8
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=druid
# For PostgreSQL:
#druid.metadata.storage.type=postgresql
#druid.metadata.storage.connector.connectURI=jdbc:postgresql://db.example.com:54
32/druid
#druid.metadata.storage.connector.user=...
#druid.metadata.storage.connector.password=...
#
# Deep storage
#
# For local disk (only viable in a cluster if this is a network mount):
#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
# For HDFS:
druid.storage.type=hdfs
druid.storage.storageDirectory=hdfs://hadoop01:9000/druid/segments
# For S3:
#druid.storage.type=s3
#druid.storage.bucket=your-bucket
#druid.storage.baseKey=druid/segments
#druid.s3.accessKey=...
#druid.s3.secretKey=...
#
# Indexing service logs
#
# For local disk (only viable in a cluster if this is a network mount):
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
# For HDFS:
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=hdfs://hadoop01:9000/druid/indexing-logs
# For S3:
#druid.indexer.logs.type=s3
#druid.indexer.logs.s3Bucket=your-bucket
#druid.indexer.logs.s3Prefix=druid/indexing-logs
#
# Service discovery
#
druid.selectors.indexing.serviceName=druid/overlord
druid.selectors.coordinator.serviceName=druid/coordinator
#
# Monitoring
#
druid.monitoring.monitors=["org.apache.druid.java.util.metrics.JvmMonitor"]
druid.emitter=noop
druid.emitter.logging.logLevel=info
# Storage type of double columns
# ommiting this will lead to index double as float at the storage layer
druid.indexing.doubleStorage=double
#
# Security
#
druid.server.hiddenProperties=
["druid.s3.accessKey","druid.s3.secretKey","druid.metadata.storage.connector.pas
sword"]
#
# SQL
#
druid.sql.enable=true
#
# Lookups
#
druid.lookup.enableLookupSyncOnStartup=false
7.3 配置JVM
7.3.1 master配置
vi /usr/local/druid/apache-druid-0.21.0/conf/druid/cluster/master/coordinator- overlord/jvm.config
- -Xms 根据自己的电脑配置调
- -Xmx 根据自己的电脑配置调
- Duser.timezone 改为UTC+0800

7.3.2 query配置
配置broker-jvm
配置query节点的broker里面的jvm.properties
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/query/broker/jvm.config
- -Xms 根据自己的电脑配置调
- -Xmx 根据自己的电脑配置调
- Duser.timezone 改为UTC+0800

配置broker-runtime
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/query/broker/runtime.properties
druid.service=druid/broker
druid.plaintextPort=8082
# HTTP server settings
druid.server.http.numThreads=20
#如果代理从不处于高并发负载下(在这种情况下,快速处理收集的数据并释放所使用的内存),那么拥有大限
制并不一定是坏事
# HTTP client settings
#查询线程数
druid.broker.http.numConnections=50
druid.broker.http.maxQueuedBytes=10MiB
# Processing threads and buffers
druid.processing.buffer.sizeBytes=10MiB
#可用于合并查询结果的直接内存缓冲区数
druid.processing.numMergeBuffers=6
#并行处理segment的线程数 默认是(Number of cores - 1 (or 1))
druid.processing.numThreads=1
druid.processing.tmpDir=var/druid/processing
# Query cache disabled -- push down caching and merging instead
druid.broker.cache.useCache=false
druid.broker.cache.populateCache=false
配置router-jvm
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/query/router/jvm.config
- -Xms 根据自己的电脑配置调
- -Xmx 根据自己的电脑配置调
- Duser.timezone 改为UTC+0800
Data节点配置
配置historical-jvm
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/data/historical/jvm.config
- -Xms 根据自己的电脑配置调
- -Xmx 根据自己的电脑配置调
- Duser.timezone 改为UTC+0800

配置historical-runtime
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/data/historical/runtime.properties
druid.service=druid/historical
druid.plaintextPort=8083
# HTTP server threads
# HTTP请求的线程数 max(10, (Number of cores * 17) / 16 + 2) + 30
druid.server.http.numThreads=20
# Processing threads and buffers
druid.processing.buffer.sizeBytes=10MiB
druid.processing.numMergeBuffers=4
#可用于并行处理段的处理线程数 默认Number of cores - 1 (or 1)
druid.processing.numThreads=15
druid.processing.tmpDir=var/druid/processing
# Segment storage
# 段的缓存位置,及此目录可以缓存的大小 默认 300G
druid.segmentCache.locations=[{"path":"var/druid/segment-
cache","maxSize":"300g"}]
# Query cache
druid.historical.cache.useCache=true
druid.historical.cache.populateCache=true
druid.cache.type=caffeine
druid.cache.sizeInBytes=256MiB
配置middleManager-jvm
-Xms 根据自己的电脑配置调
-Xmx 根据自己的电脑配置调
Duser.timezone 改为UTC+0800
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/data/middleManager/jvm.config

配置middleManager-runtime
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/data/middleManager/runtime.properties
druid.service=druid/middleManager
druid.plaintextPort=8091
# Number of tasks per middleManager
# 可以创建的最大任务数
druid.worker.capacity=4
# Task launch parameters
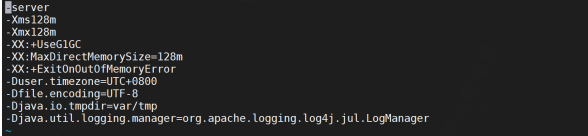
druid.indexer.runner.javaOpts=-server -Xms128m -Xmx128m -
XX:MaxDirectMemorySize=128m -Duser.timezone=UTC -Dfile.encoding=UTF-8 -
XX:+ExitOnOutOfMemoryError -
Djava.util.logging.manager=org.apache.logging.log4j.jul.LogManager
druid.indexer.task.baseTaskDir=var/druid/task
# HTTP server threads
#HTTP请求的线程数 两个大小相等的HTTP线程池 一个是 Overlord Indexer 的通信 一个处理所有其他
HTTP请求 公式 max(10, (Number of cores * 17) / 16 + 2) + 30
druid.server.http.numThreads=20
# Processing threads and buffers on Peons
# peons的设置 内存计算方式与middlemanager的计算一致 druid.processing.buffer.sizeBytes
* (druid.processing.numMergeBuffers + druid.processing.numThreads + 1)
druid.indexer.fork.property.druid.processing.numMergeBuffers=2
druid.indexer.fork.property.druid.processing.buffer.sizeBytes=10MiB
druid.indexer.fork.property.druid.processing.numThreads=1
# Hadoop indexing
druid.indexer.task.hadoopWorkingPath=var/druid/hadoop-tmp
7.4 启动集群
复制节点
将对应的节点复制到需要的地方
scp -r /usr/local/druid/ root@192.168.64.175:/usr/local/
scp -r /usr/local/druid/ root@192.168.64.176:/usr/local/
修改druid.host
修改配置文件中的druid.host为当前服务器的host,注意三台服务器都需要修改
vi /usr/local/druid/apache-druid- 0.21.0/conf/druid/cluster/_common/common.runtime.properties

启动集群
druid集群的启动,进入安装目录
cd /usr/local/druid/apache-druid-0.21.0
启动master节点
在192.168.64.175执行
nohup ./bin/start-cluster-master-no-zk-server > master.log & tail -f master.log

启动query节点
在192.168.64.176执行
nohup ./bin/start-cluster-query-server > query.log & tail -f query.log

启动data节点
在192.168.64.177执行
nohup ./bin/start-cluster-data-server > data.log & tail -f data.log

访问
http://192.168.64.177:8888

8. 架构设计
Druid有一个多进程、分布式的架构,该架构设计为云友好且易于操作。每个Druid进程都可以独立
配置和扩展,在集群上提供最大的灵活性。这种设计还提供了增强的容错能力:一个组件的中断不会立
即影响其他组件。
Druid是微服务架构,可以理解为一个拆解成多个服务的数据库。Druid的每一个核心服务
(ingestion(摄入服务),querying(查询服务),和coordination(协调服务))都可以单独部署或联合部署在
商业硬件上。
Druid清晰的命名每一个服务,以确保运维人员可以根据使用情况和负载情况很好地调整相应服务
的参数。例如,当负载需要时,运维人员可以给数据摄入服务更多的资源而减少数据查询服务的资源。
Druid可以独立失败而不影响其他服务的运行。

8.1 进程与服务
Druid有若干不同类型的进程
8.1.1 Coordinator
进程管理集群中数据的可用性
Druid Coordinator程序主要负责段管理和分发。更具体地说,Druid Coordinator进程与Historical
进程通信,根据配置加载或删除段。Druid Coordinator负责加载新段、删除过时段、管理段复制和平衡
段负载。
Druid Coordinator定期运行,每次运行之间的时间是一个可配置的参数。每次运行Druid
Coordinator时,它都会在决定要采取的适当操作之前评估集群的当前状态。与Broker和Historical进程
类似,Druid Coordinator维护了一个用于当前集群信息的Zookeeper集群连接。Coordinator还维护到
数据库的连接,该数据库包含有关可用段和规则的信息。可用段存储在段表中,并列出应加载到集群中
的所有段。规则存储在规则表中,并指示应如何处理段。
8.1.2 Overlord
进程控制数据摄取负载的分配
Overlord进程负责接收任务、协调任务分配、创建任务锁并将状态返回给调用方。Overlord可以配
置为本地模式运行或者远程模式运行(默认为本地)。在本地模式下,Overlord还负责创建执行任务的
Peon, 在本地模式下运行Overlord时,还必须提供所有MiddleManager和Peon配置。本地模式通常用
于简单的工作流。在远程模式下,Overlord和MiddleManager在不同的进程中运行,您可以在不同的服
务器上运行每一个进程。如果要将索引服务用作所有Druid索引的单个端点,建议使用此模式。
8.1.3 Broker
进程处理来自外部客户端的查询请求
在分布式的Druid集群中,Broker是一个查询的路由进程。Broker了解所有已经发布到ZooKeeper
的元数据,了解在哪些进程存在哪些段,然后将查询路由到以便它们可以正确命中的进程。Broker还将
来自所有单个进程的结果集合并在一起。在启动时,Historical会在Zookeeper中注册它们自身以及它们
所服务的段。
8.1.4 Router
进程是一个可选进程,可以将请求路由到Brokers、Coordinators和Overlords
Router是一个可选的和实验性的特性,因为它在Druid集群架构中的推荐位置仍在不断发展。然
而,它已经在生产中经过了测试,并且承载了强大的Druid控制台,所以您应该放心地部署它。
Apache Druid Router用于将查询路由到不同的Broker。默认情况下,Broker根据 规则 设置路由
查询。例如,如果将最近1个月的数据加载到一个 热集群 中,则可以将最近一个月内的查询路由到一组
专用的Broker,超出此范围的查询将路由到另一组Broker。该设置的主要功能是为了提供查询隔离,以便
对较重要数据的查询不会受到对较不重要数据的查询的影响。
8.1.5 Historica
进程存储可查询的数据
每个Historical都保持与Zookeeper的持续连接,并监视一组可配置的Zookeeper路径以获取新的段
信息。Historical不直接与Coordinator通信,而是依赖Zookeeper进行协调。
8.1.6 MiddleManager
进程负责摄取数据
MiddleManager进程是执行提交的任务的工作进程。MiddleManager将任务转发给运行在不同jvm
中的Peon。我们为每个任务设置单独的jvm的原因是为了隔离资源和日志。每个Peon一次只能运行一个
任务,但是,一个MiddleManager可能有多个Peon
8.2 服务类型
Druid进程可以按照您喜欢的任何方式部署,但是为了便于部署,我们建议将它们组织成三种服务
器类型

8.2.1 Master服务
Master服务管理数据的摄取和可用性:它负责启动新的摄取作业并协调下面描述的"Data服务"上
数据的可用性。
在Master服务中,功能分为两个进程:Coordinator和Overlord。
Coordinator进程
Druid Coordinator程序主要负责段管理和分发。
更具体地说,Druid Coordinator进程与Historical进程通信,根据配置加载或删除段。Druid
Coordinator负责加载新段、删除过时段、管理段复制和平衡段负载。
Druid Coordinator定期运行,每次运行之间的时间是一个可配置的参数。每次运行Druid
Coordinator时,它都会在决定要采取的适当操作之前评估集群的当前状态。与Broker和Historical进程
类似,Druid Coordinator维护了一个用于当前集群信息的Zookeeper集群连接。Coordinator还维护到
数据库的连接,该数据库包含有关可用段和规则的信息。可用段存储在段表中,并列出应加载到集群中
的所有段。规则存储在规则表中,并指示应如何处理段。
Overlord进程
Overlord进程负责接收任务、协调任务分配、创建任务锁并将状态返回给调用方。
Overlord可以配置为本地模式运行或者远程模式运行(默认为本地)。在本地模式下,Overlord还
负责创建执行任务的Peon, 在本地模式下运行Overlord时,还必须提供所有MiddleManager和Peon配
置。本地模式通常用于简单的工作流。在远程模式下,Overlord和MiddleManager在不同的进程中运
行,您可以在不同的服务器上运行每一个进程。如果要将索引服务用作所有Druid索引的单个端点,建议
使用此模式。
8.2.2 Query服务
Query服务提供用户和客户端应用程序交互,将查询路由到Data服务或其他Query服务(以及可选
的代理Master服务请求),在Query服务中,功能上分为两个进程:Broker和Router。
Broker进程
在分布式的Druid集群中,Broker是一个查询的路由进程。
Broker从外部客户端接收查询并将这些查询转发到Data服务器, 当Broker接收到子查询的结果时,
它们会合并这些结果并将其返回给调用者。用户通常查询Broker,而不是直接查询Data服务中的
Historical或MiddleManager进程。
Broker了解所有已经发布到ZooKeeper的元数据,了解在哪些进程存在哪些段,然后将查询路由到
以便它们可以正确命中的进程。Broker还将来自所有单个进程的结果集合并在一起。在启动时,
Historical会在Zookeeper中注册它们自身以及它们所服务的段。
Router进程
Router进程是可选的进程,相当于是为Druid Broker、Overlord和Coordinator提供一个统一的API
网关。Router是可选的,因为也可以直接与Druid的Broker、Overlord和Coordinator。
Router还运行着Druid控制台,一个用于数据源、段、任务、数据进程(Historical和
MiddleManager)和Coordinator动态配置的管理UI。用户还可以在控制台中运行SQL和本地Druid查
询。
8.2.3 Data服务
Data服务执行摄取作业并存储可查询数据。
在Data服务中,根据功能被分为两个进程:Historical和MiddleManager。
Historical进程
每个Historical都保持与Zookeeper的持续连接,并监视一组可配置的Zookeeper路径以获取新的
段信息。Historical不直接与Coordinator通信,而是依赖Zookeeper进行协调。
Historical 进程是处理存储和查询"Historical"数据(包括系统中已提交足够长时间的任何流数据)
的工作程序。Historical进程从深层存储下载段并响应有关这些段的查询,他们不接受写操作。
MiddleManager进程
MiddleManager 进程处理将新数据摄取到集群中的操作, 他们负责读取外部数据源并发布新的Druid段















 2614
2614











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









