







直播音视频流(小解)
1.基础背景知识
2.视音频编码封装过程
3.对比sdl等视音频播放库
4.对比ffmeg
5.rtmp rtsp hls简介
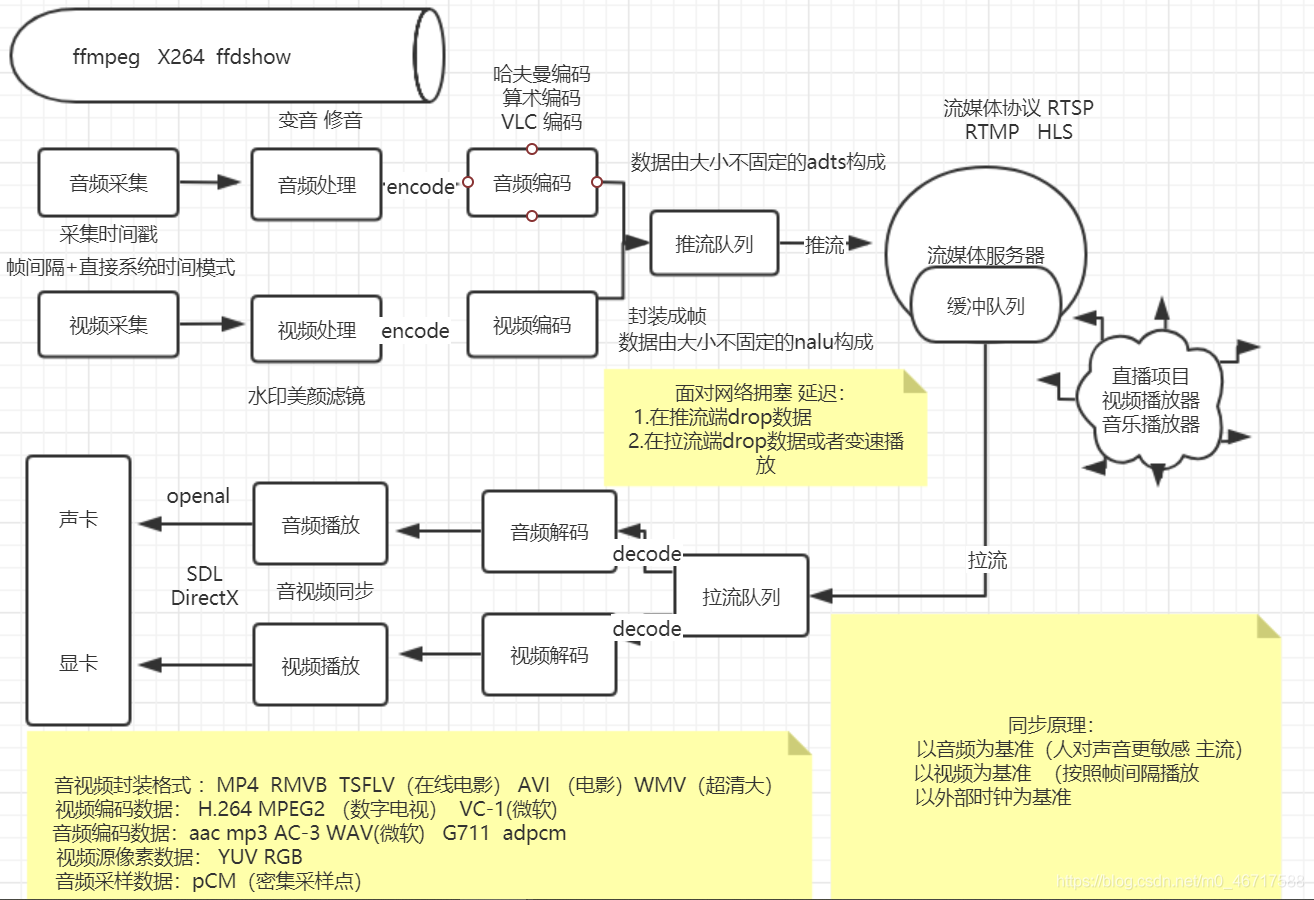
下面是系统框架图
基础知识:我们肉眼可见的流畅度为25帧每秒每一帧有很多很像素组成
所以每帧图像视作一个三维矩阵—RGB
分辨率:即一个平面内像素的数量。通常表示成宽*高
将视频定义为在单位时间内连续的 n 帧,这可以视作一个新的维度,n 即为帧率,若单位时间为秒,则等同于 FPS (每秒帧数 Frames Per Second)。
利用视觉特性:和区分颜色相比,我们区分亮度要更加敏锐。时间上的重复:一段视频包含很多只有一点小小改变的图像。图像内的重复:每一帧也包含很多颜色相同或相似的区域。(YUV)
I 帧(帧内编码,关键帧) 是一个自足的帧。它不依靠任何东西来渲染,I 帧与静态图片相似。第一帧通常是 I 帧,但我们将看到 I 帧被定期插入其它类型的帧之间。
P 帧(预测)P 帧利用了一个事实:当前的画面几乎总能使用之前的一帧进行渲染。例如,在第二帧,唯一的改变是球向前移动了。仅仅使用(第二帧)对前一帧的引用和差值,我们就能重建前一帧
编码方式可以分为帧内编码和帧间编码。
内编码方式:
即只利用了单帧图像内的空间相关性,对冗余数据进行编码,达到压缩效果,而没有利用时间相关性,不使用运动补偿。所以单靠自己,便能完整解码出一帧画面。
帧间编码:
由于视频的特性,相邻的帧之间其实是很相似的,通常是运动矢量的变化。利用其时间相关性,可以通过参考帧运动矢量的变化来预测图像,并结合预测图像与原始图像的差分,便能解码出原始图像。所以,帧间编码需要依赖其他帧才能解码出一帧画面。
由于编码方式的不同,视频中的画面帧就分为了不同的类别,其中包括:I 帧、P 帧、B 帧。
I 帧(Intra coded frames):
I 帧图像采用帧I 帧使用帧内压缩,不使用运动补偿,由于 I 帧不依赖其它帧,可以独立解码。I 帧图像的压缩倍数相对较低,周期性出现在图像序列中的,出现频率可由编码器选择。
P 帧(Predicted frames):
P 帧采用帧间编码方式,即同时利用了空间和时间上的相关性。P 帧图像只采用前向时间预测,可以提高压缩效率和图像质量。P 帧图像中可以包含帧内编码的部分,即 P 帧中的每一个宏块可以是前向预测,也可以是帧内编码。
B 帧(Bi-directional predicted frames):
B 帧图像采用帧间编码方式,且采用双向时间预测,可以大大提高压缩倍数。也就是其在时间相关性上,还依赖后面的视频帧,也正是由于 B 帧图像采用了后面的帧作为参考,因此造成视频帧的传输顺序和显示顺序是不同的。
也就是说,一个 I 帧可以不依赖其他帧就解码出一幅完整的图像,而 P 帧、B 帧不行。P 帧需要依赖视频流中排在它前面的帧才能解码出图像。B 帧则需要依赖视频流中排在它前面或后面的I/P帧才能解码出图像。
对于I帧和P帧,其解码顺序和显示顺序是相同的,但B帧不是,如果视频流中存在B帧,那么就会打算解码和显示顺序。
正因为解码和显示的这种非线性关系,所以需要DTS、PTS来标识帧的解码及显示时间。
时间戳DTS、PTS (实现视音频同步)
DTS(Decoding Time Stamp):即解码时间戳,这个时间戳的意义在于告诉播放器该在什么时候解码这一帧的数据。
PTS(Presentation Time Stamp):即显示时间戳,这个时间戳用来告诉播放器该在什么时候显示这一帧的数据。
当视频流中没有 B 帧时,通常 DTS 和 PTS 的顺序是一致的。但如果有 B 帧时,就回到了我们前面说的问题:解码顺序和播放顺序不一致了,即视频输出是非线性的。
比如一个视频中,帧的显示顺序是:I B B P,因为B帧解码需要依赖P帧,因此这几帧在视频流中的顺序可能是:I P B B,这时候就体现出每帧都有 DTS 和 PTS 的作用了。DTS 告诉我们该按什么顺序解码这几帧图像,PTS 告诉我们该按什么顺序显示这几帧图像
视频压缩标准:
计算每秒 30 帧,每像素 24 bit,分辨率是 480x240 的视频需要多少带宽吗?没有压缩时是 82.944 Mbps 只能靠视频编解码器。怎么做?
H.261 诞生在 1990(技术上是 1988),被设计为以 64 kbit/s 的数据速率工作。它已经使用如色度子采样、宏块,等等理念。在 1995 年,H.263 视频编解码器标准被发布,并继续延续到 2001 年。
在 2003 年 H.264/AVC 的第一版被完成。在同一年,一家叫做 TrueMotion 的公司发布了他们的免版税有损视频压缩的视频编解码器,称为 VP3。在 2008 年,Google 收购了这家公司,在同一年发布 VP8。在 2012 年 12 月,Google 发布了 VP9,市面上大约有 3/4 的浏览器(包括手机)支持。
AV1 是由 Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel, Cisco 等公司组成的开放媒体联盟(AOMedia)设计的一种新的视频编解码器,免版税,开源。第一版 0.1.0 参考编解码器发布于 2016 年 4 月 7 号。
DTS 和 PTS
DTS(Decoding Time Stamp, 解码时间戳),表示压缩帧的解码时间。
PTS(Presentation Time Stamp, 显示时间戳),表示将压缩帧解码后得到的原始帧的显示时间。
音频中 DTS 和 PTS 是相同的。视频中由于 B 帧需要双向预测,B 帧依赖于其前和其后的帧,因此含 B 帧的视频解码顺序与显示顺序不同,即 DTS 与 PTS 不同。当然,不含 B 帧的视频,其 DTS 和 PTS 是相同的
第一步 - 图片分区
第一步是将帧分成几个分区,子分区甚至更多。
微小移动的部分使用较小的分区,而在静态背景上使用较大的分区
第二步 - 预测
一旦我们有了分区,我们就可以在它们之上做出预测。对于帧间预测,我们需要发送运动向量和残差;至于帧内预测,我们需要发送预测方向和残差。
第三步 - 转换
在我们得到残差块(预测分区-真实分区)之后,我们可以用一种方式变换它,这样我们就知道哪些像素我们应该丢弃,还依然能保持整体质量。这个确切的行为有几种变换方式。
将像素块转换为相同大小的频率系数块。
压缩能量,更容易消除空间冗余。
可逆的,也意味着你可以还原回像素。
第四步 - 量化
当我们丢弃一些系数时,在最后一步(变换),我们做了一些形式的量化。这一步,我们选择性地剔除信息(有损部分)或者简单来说,我们将量化系数以实现压缩。
第五步 - 熵编码
(无损压缩算法都是熵编码算法)
熵编码就是根据数据中不同字符出现的概率,用不同长度的编码来表示不同字符。出现概率越高的字符,则用越短的编码表示;出现概率低的字符,可以用比较长的编码表示
在我们量化数据(图像块/切片/帧)之后,我们仍然可以以无损的方式来压缩它。有许多方法(算法)可用来压缩数据。
VLC 编码
我们压缩 eat符号流,假设我们为每个字符花费 8 bit,在没有做任何压缩时我们将花费 24 bit。但是在这种情况下,我们使用各自的代码来替换每个字符,我们就能节省空间
第一步是编码字符 e 为 10,第二个字符是 a,追加(不是数学加法)后是 [10][0],最后是第三个字符 t,最终组成已压缩的比特流 [10][0][1110] 或 1001110,这只需 7 bit(比原来的空间少 3.4 倍)。
算术编码
让我们假设我们有一个符号流:a, e, r, s 和 t,它们的概率由下表所示。
aerst概率0.30.30.150.050.2考虑到这个表,我们可以构建一个区间,区间包含了所有可能的字符,字符按出现概率排序。

让我们编码 eat 流,我们选择第一个字符 e 位于 0.3 到 0.6 (但不包括 0.6)的子区间,我们选择这个子区间,按照之前同等的比例再次分割。

让我们继续编码我们的流 eat,现在使第二个 a 字符位于 0.3 到 0.39 的区间里,接着再次用同样的方法编码最后的字符 t,得到最后的子区间 0.354 到 0.372。
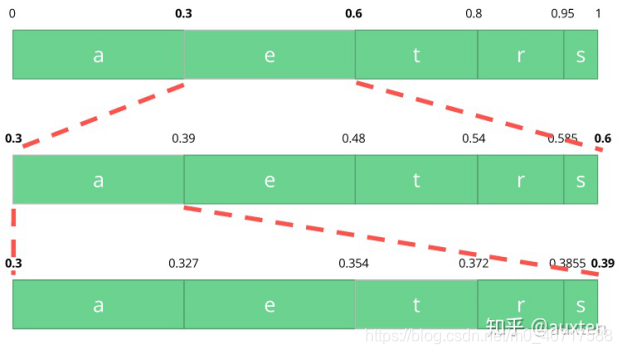
我们只需从最后的子区间 0.354 到 0.372 里选择一个数,让我们选择 0.36,不过我们可以选择这个子区间里的任何数。仅靠这个数,我们将可以恢复原始流 eat。就像我们在区间的区间里画了一根线来编码我们的流。
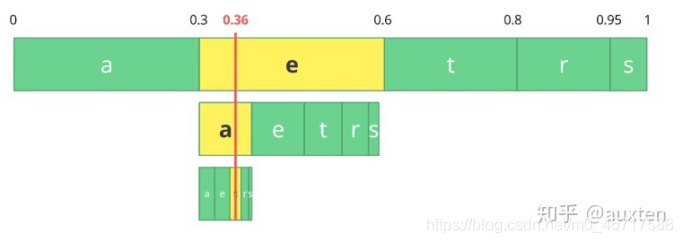
编码器和解码器都必须知道字符概率表,因此,你也需要传送这个表。
第六步 - 比特流格式
完成所有这些步之后,我们需要将压缩过的帧和内容打包进去。需要明确告知解码器编码定义,如颜色深度,颜色空间,分辨率,预测信息(运动向量,帧内预测方向),配置,层级,帧率,帧类型,帧号等等更多信息
帧间和帧内预测,转换,量化,熵编码和其它
HEVC(h.265) 比 AVC 有更大和更多的分区(和子分区)选项,更多帧内预测方向,改进的熵编码等,所有这些改进使得 H.265 比 H.264 的压缩率提升 50%。
音频处理 :经过 采样 量化 编码 压缩。这里就不做详细赘述。
SDL(Simple DirectMedia Layer)作为免费的跨平台多媒体应用编程接口,已经被人们广泛用于开发二维游戏,其优秀的消息框架支持、文件支持和声音支持都使得它能与微软DirectX匹敌。
现在很多game游戏里面,都采用 SDL+OpenGL ES 的模式来绘制3D界面。 可以让SDL使用OpenGL ES的函数接口来渲染3D。
SDL库的作用说白了就是封装了复杂的视音频底层操作,简化了视音频处理的难度。
SDL(Simple DirectMedia Layer)是一套开放源代码的跨平台多媒体开发库,使用C语言写成。SDL提供了数种控制图像、声音、输出入的函数,让开发者只要用相同或是相似的代码就可以开发出跨多个平台(Linux、Windows、Mac OS X等)的应用软件。目前SDL多用于开发游戏、模拟器、媒体播放器等多媒体应用领域。
虽然SDL时常被比较为‘跨平台的DirectX’,然而事实上SDL是定位成以精简的方式来完成基础的功能,它大幅度简化了控制图像、声音、输出入等工作所需撰写的代码。但更高级的绘图功能或是音效功能则需搭配OpenGL和OpenAL等API来达成。另外它本身也没有方便创建图形用户界面的函数。
SDL在结构上是将不同操作系统的库再包装成相同的函数,例如SDL在Windows平台上其实是DirectX的再包装,旧版本包装的是DirectX 5,现时的版本(SDL 1.2)则是DirectX 7。而在使用X11的平台上(包括Linux),SDL则是与Xlib库沟通来输出图像。
虽然SDL本身是使用C语言写成,但是它几乎可以被所有的编程语言所使用,例如:C++、Perl、Python(借由pygame库)、Pascal等等,甚至是Euphoria、Pliant这类较不流行的编程语言也都可行。
SDL库分为 Video、Audio、CD-ROM、Joystick 和 Timer 等若干子系统,除此之外,还有一些单独的官方扩充函数库。这些库由官方网站提供,并包含在官方文档中,共同组成了SDL的“标准库”:
SDL_image—支持时下流行的图像格式:BMP、PPM、XPM、 PCX、GIF、JPEG、PNG、TGA。
SDL_mixer—更多的声音输出函数以及更多的声音格式支持。
SDL_net—网络支持。
SDL_ttf—TrueType字体渲染支持。
SDL_rtf—简单的RTF渲染支持。
子系统
SDL将功能分成下列数个子系统(subsystem):
Video(图像)—图像控制以及线程(thread)和事件管理(event)。
Audio(声音)—声音控制
Joystick(摇杆)—游戏摇杆控制
CD-ROM(光盘驱动器)—光盘媒体控制
Window Management(视窗管理)-与视窗程序设计集成
Event(事件驱动)-处理事件驱动
一.ffmpeg (ffmpeg命令 和 ffmpeg编程)
ffprobe用于探测媒体文件的格式以及详细信息,ffplay是一个播放媒体文件的工具,那么ffmpeg就是强大的媒体文件转换工具。它可以转换任何格式的媒体文件,并且还可以用自己的AudioFilter以及VideoFilter进行处理和编辑。ffmpeg是一套视频处理和存储等的技术方案,重点“开源”、“免费”,“最主流的视频处理技术方案”。
ffmpeg属于GPL或者LGPL,确切属于哪一种,要根据编译选项,因为它里面的库有些属于GPL的有些属于LGPL的,你编译的时候打开或者关闭这些库的选项,就决定了它属于哪一种。
二、Xvid
Xvid(旧称为XviD)是一个开放源代码的MPEG-4视频编解码器,它是基于OpenDivX而编写的。官方网站:www.xvid.org
三、X264
X264是一种免费的、具有更优秀算法的符合H.264/MPEG-4 AVC视频压缩编码标准格式的编码库。x264压缩出的视频文件在相同质量下要比xvid压缩出的文件要小,或者也可以说,在相同体积下比xvid压缩出的文件质量要好。它符合GPL(General Public License,是一份GNU通用公共授权)许可证。X264属于videolan开源工程的一部分。
采用CAVLC/CABAC多种算法编码
内置所有macroblock格式(16x16, 8x8, and 4x4 )
Inter P:所有的分割块(从16x16到4x4 )
Inter B:分割块从16x16到8x8
码率控制:恒定的分层编制,单次或多次的ABR压制,可选的VBV压制
场景剪切侦测
支持B-frame
能够任意编制B-frame命令行
无损模式
8x8和4x4的格式能够进行翻转或旋转
自定义精确的矩阵模板
可在多个CPU平行编码
隔行扫描
X264只提供编码,不提供解码。 解码部分需要FFMPEG完成;XVID有编解码部分,其中解码亦可以利用FFMPEG中的MPEG4完成解码。
四、ffdshow
ffdshow是对一些codec(ffmpeg, xvid, and other)的封装,封装成了DirectShow和VFW的标准组件。该库(软件)只能在windows平台运行,是属于GPL
比如对于xvid来讲,ffdshow是可以选择具体使用那个codec的,ffmpeg(libavcodec) or xvid。那么封装有没有额外的成本哪?有,但对大部分应用来讲,可以忽略不计。就如c++和c。
vfw和dshow里的CODEC分别是通过fourcc码和guid机制寻找的,可以在系统注册codec后调用,比自带编解码库形式更加统一,便于使用。此外,vfw和dshow是代表了两个微软不同时期的音视频处理封装库,里面包含了音视频驱动,音视频处理的一整套方案。
DirectShow是微软公司在ActiveMovie和Video for Windows的基础上推出的新一代基于COM的流媒体处理的开发包,与DirectX开发包一起发布。目前,DirectX最新版本为9.0。 DirectShow为多媒体流的捕捉和回放提供了强有力的支持。运用DirectShow,我们可以很方便地从支持WDM驱动模型的采集卡上捕获数据, 并且进行相应的后期处理乃至存储到文件中。这样使在多媒体数据库管理系统(MDBMS)中多媒体数据的存取变得更加方便。DirectShow是微软公司 提供的一套在Windows平台上进行流媒体处理的开发包,与DirectX开发包一起发布。运用DirectShow,我们可以很方便地从支持WDM驱动模型的采集卡上捕获数据,并且进行相应的后期处理乃至存储到文件中。它广泛地支持各种媒体格 式,包括Asf、Mpeg、Avi、Dv、Mp3、Wave等等,使得多媒体数据的回放变得轻而易举。另外,DirectShow还集成了DirectX 其它部分(比如DirectDraw、DirectSound)的技术,直接支持DVD的播放,视频的非线性编辑,以及与数字摄像机的数据交换。
五、CoreAVC
CoreCodec的CoreAVC高清H.264视频解码器是基于已经被用于AVCHD、蓝光光盘和HD-DVD中的MPEG-4 Part 10标准构建的。H.264是下一代的视频编码标准,而CoreAVC?是目前公认世界上最快的H.264软解码器。
简单介绍一下 Libyuv库是一个专门对YUV数据进行转换缩放旋转的库
YUV是Google已经开源了专门用于YUV数据的处理的库。它拥有如下特性
1、libYUV是一个开源的实现各种YUV,RGB色彩之间的转换、旋转、缩放
2、支持windows、linux系统,支持x86、arm架构
3、支持SSE、AVX、NEON加速,在编译时会根据硬件平台旋转使用的实现方式
在日常开发中,特别是在编解码的项目中,数据格式转换是很常见的,如YUV转RGB、YU12转I420、亦或者其他格式等等,我们常用的转换方式,要么使用Opencv的cvtColor(),要么使用FFmepg的sws_scale(),单帧图片进行转换还好,但如果我们在视频处理过程中使用,就会发现数据延迟,内存增长等各种问题,常见的处理方式是丢帧。
视频传输协议详解(RTMP、RTSP、HLS)
RTMP——Real Time Messaging Protocol(实时消息传输协议)
RTMP是由Adobe公司提出的,在互联网TCP/IP五层体系结构中应用层,RTMP协议是基于TCP协议的,也就是说RTMP实际上是使用TCP作为传输协议。TCP协议在处在传输层,是面向连接的协议,能够为数据的传输提供可靠保障,因此数据在网络上传输不会出现丢包的情况。不过这种可靠的保障也会造成一些问题,也就是说前面的数据包没有交付到目的地,后面的数据也无法进行传输。幸运的是,目前的网络带宽基本上可以满足RTMP协议传输普通质量视频的要求。
RTMP在TCP通道上一般传输的是flv 格式流
RTMP 握手分为简单握手和复杂握手,现在Adobe公司使用RTMP协议的产品应该用的都是复杂握手,这里不介绍,只说简单握手。 按照网上的说法RTMP握手的过程如下
1.握手开始于客户端发送C0、C1块。服务器收到C0或C1后发送S0和S1。
1.当客户端收齐S0和S1后,开始发送C2。当服务器收齐C0和C1后,开始发送S2。
2.当客户端和服务器分别收到S2和C2后,握手完成。
在实际工程应用中,一般是客户端先将C0, C1块同时发出,服务器在收到C1 之后同时将S0, S1, S2发给客户端。S2的内容就是收到的C1块的内容。之后客户端收到S1块,并原样返回给服务器,简单握手完成。按照RTMP协议个要求,客户端需要校验C1块的内容和S2块的内容是否相同,相同的话才彻底完成握手过程,实际编写程序用一般都不去做校验。
RTMP握手的这个过程就是完成了两件事:1. 校验客户端和服务器端RTMP协议版本号,2. 是发了一堆数据,猜想应该是测试一下网络状况,看看有没有传错或者不能传的情况。
2. RTMP 分块
创建RTMP连接算是比较难的地方,开始涉及消息分块(chunking)和 AFM(也是Adobe家的东西)格式数据的一些东西。
RTMP传输的数据的基本单元为Message,但是实际上传输的最小单元是Chunk(消息块),因为RTMP协议为了提升传输速度,在传输数据的时候,会把Message拆分开来,形成更小的块,这些块就是Chunk。
Message结构分析
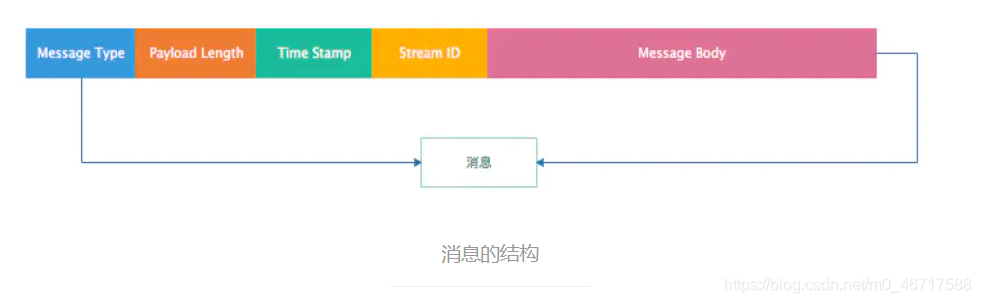
1.Message Type:它是一个消息类型的ID,通过该ID接收方可以判断接收到的数据的类型,从而做相应的处理。Message Type ID在1-7的消息用于协议控制,这些消息一般是RTMP协议自身管理要使用的消息,用户一般情况下无需操作其中的数据。Message Type ID为8,9的消息分别用于传输音频和视频数据。Message Type ID为15-20的消息用于发送AMF编码的命令,负责用户与服务器之间的交互,比如播放,暂停等。
2.Playload Length: 消息负载的长度,即音视频相关信息的的数据长度,4个字节
3.TimeStamp:时间戳,3个字节。
4.Stream ID:消息的唯一标识。拆分消息成Chunk时添加该ID,从而在还原时根据该ID识别Chunk属于哪个消息。
5.Message Body:消息体,承载了音视频等信息。
消息块(Chunk)
消息块结构
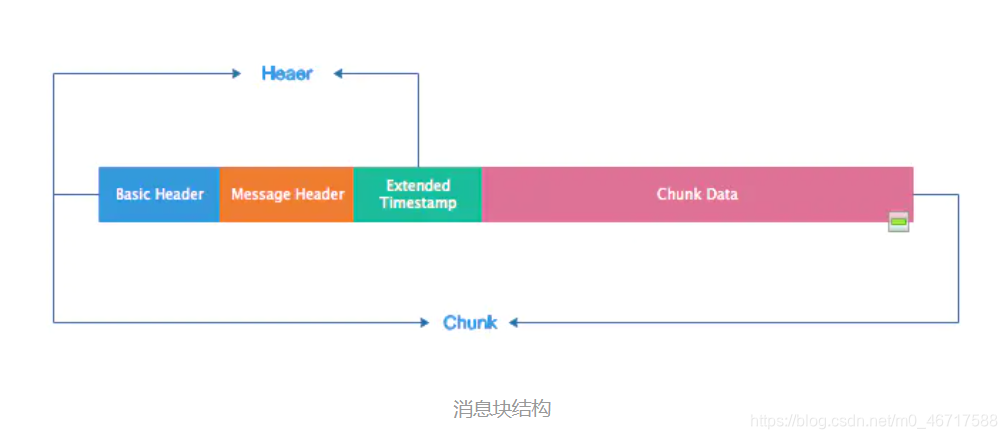
通过上图可以看出,消息块在结构上与与消息类似,有Header和Body。
1.Basic Header:基本的头部信息,在头部信息里面包含了chunk stream ID(流通道Id,用来标识指定的通道)和chunk type(chunk的类型)。
2.Message Header:消息的头部信息,包含了要发送的实际信息(可能是完整的,也可能是一部分)的描述信息。Message Header的格式和长度取决于Basic Header的chunk type。
3.Extended TimeStamp:扩展时间戳。
4.Chunk Data:块数据。
RTMP在传输数据的时候,发送端会把需要传输的媒体数据封装成消息,然后把消息拆分成消息块,再一个一个进行传输。接收端收到消息块后,根据Message Stream ID重新将消息块进行组装、组合成消息,再解除该消息的封装处理就可以还原出媒体数据。由此可以看出,RTMP收发数据是以Chunk为单位,而不是以Message为单位。需要注意的是,RTMP发送Chunk必须是一个一个发送,后面的Chunk必须等前面的Chunk发送完成。
WebRTC
WebRTC,名称源自网页即时通信(英语:Web Real-Time Communication)的缩写,是一个支持网页浏览器进行实时语音对话或视频对话的API。它于2011年6月1日开源并在Google、Mozilla、Opera支持下被纳入万维网联盟的W3C推荐标准
为什么要使用转I420
1.Camera预览格式:NV21、YV12 ,默认是NV21 格式
2.H264编码必须要用 I420格式的YUV420
YUV420的几种格式
NV12,NV21,YV12,I420都属于YUV420,但是YUV420 又分为YUV420P,YUV420SP,P与SP区别就是,前者YUV420P UV顺序存储,而YUV420SP则是UV交错存储,这是最大的区别,具体的yuv排序就是这样的:
I420: YYYYYYYY UU VV ->YUV420P
YV12: YYYYYYYY VV UU ->YUV420P
NV12: YYYYYYYY UVUV ->YUV420SP
NV21: YYYYYYYY VUVU ->YUV420SP
RTSP
RTSP(Real Time Streaming Protocol)是TCP/UDP协议体系中的一个应用层协议,由哥伦比亚大学, 网景和RealNetworks公司提交的IETF RFC标准.该协议定义了一对多应用程序如何有效地通过IP网络传输多媒体数据。RTSP在体系结构上位于RTP和RTCP之上,它使用TCP或者RTP完成数据传输,目前市场上大多数采用RTP来传输媒体数据。
一次基本的RTSP操作过程:
首先,客户端连接到流服务器并发送一个RTSP描述命令(DESCRIBE)。
流服务器通过一个SDP描述来进行反馈,反馈信息包括流数量、媒体类型等信息。
客户端再分析该SDP描述,并为会话中的每一个流发送一个RTSP建立命令(SETUP),RTSP建立命令告诉服务器客户端用于接收媒体数据的端口。流媒体连接建立完成后,
客户端发送一个播放命令(PLAY),服务器就开始在UDP上传送媒体流(RTP包)到客户端。 在播放过程中客户端还可以向服务器发送命令来控制快进、快退和暂停等。
最后,客户端可发送一个终止命令(TERADOWN)来结束流媒体会话。
由上图可以看出,RTSP处于应用层,而RTP/RTCP处于传输层。RTSP负责建立以及控制会话,RTP负责多媒体数据的传输。而RTCP是一个实时传输控制协议,配合RTP做控制和流量监控。封装发送端及接收端(主要)的统计报表。这些信息包括丢包率,接收抖动等信息。发送端根据接收端的反馈信息做响应的处理。RTP与RTCP相结合虽然保证了实时数据的传输,但也有自己的缺点。最显著的是当有许多用户一起加入会话进程的时候,由于每个参与者都周期发送RTCP信息包,导致RTCP包泛滥(flooding)。
简单的RTSP消息交互过程
C表示RTSP客户端,S表示RTSP服务端
第一步:查询服务器端可用方法
C->S OPTION request //询问S有哪些方法可用
S->C OPTION response //S回应信息的public头字段中包括提供的所有可用方法
第二步:得到媒体描述信息
C->S DESCRIBE request //要求得到S提供的媒体描述信息
S->C DESCRIBE response //S回应媒体描述信息,一般是sdp信息
第三步:建立RTSP会话
C->S SETUP request //通过Transport头字段列出可接受的传输选项,请求S建立会话
S->C SETUP response //S建立会话,通过Transport头字段返回选择的具体转输选项,并返回建立的Session ID;
第四步:请求开始传送数据
C->S PLAY request //C请求S开始发送数据
S->C PLAY response //S回应该请求的信息
第五步: 数据传送播放中
S->C 发送流媒体数据 // 通过RTP协议传送数据
第六步:关闭会话,退出
C->S EARDOWN request //C请求关闭会话
S->C TEARDOWN response //S回应该请求
上述的过程只是标准的、友好的rtsp流程,但实际的需求中并不一定按此过程。 其中第三和第四步是必需的!第一步,只要服务器和客户端约定好有哪些方法可用,则option请求可以不要。第二步,如果我们有其他途径得到媒体初始化描述信息(比如http请求等等),则我们也不需要通过rtsp中的describe请求来完成。
HLS —— HTTP Live Streaming
HTTP Live Streaming(缩写是HLS)是一个由苹果公司提出的基于Http协议的的流媒体网络传输协议。是苹果公司QuickTime X和iPhone软件系统的一部分。它的工作原理是把整个流分成一个个小的基于HTTP的文件来下载,每次只下载一些。当媒体流正在播放时,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。在开始一个流媒体会话时,客户端会下载一个包含元数据的extended M3U (m3u8)playlist文件,用于寻找可用的媒体流。
HLS协议的优点:
1.跨平台性:支持iOS/Android/浏览器,通用性强。
2.穿墙能力强:由于HLS是基于HTTP协议的,因此HTTP数据能够穿透的防火墙或者代理服务器HLS都可以做到,基本不会遇到被防火墙屏蔽的情况。
3.切换码率快(清晰度):自带多码率自适应,客户端可以选择从许多不同的备用源中以不同的速率下载同样的资源,允许流媒体会话适应不同的数据速率。客户端可以很快的选择和切换码率,以适应不同带宽条件下的播放。
3.负载均衡:HLS基于无状态协议(HTTP),客户端只是按照顺序使用下载存储在服务器的普通TS文件,做负责均衡如同普通的HTTP文件服务器的负载均衡一样简单。
HLS的缺点:
1.实时性差:苹果官方建议是请求到3个片之后才开始播放。所以一般很少用HLS做为互联网直播的传输协议。假设列表里面的包含5个 ts 文件,每个 TS 文件包含5秒的视频内容,那么整体的延迟就是25秒。苹果官方推荐的ts时长时10s,所以这样就会大改有30s(n x 10)的延迟。
2.文件碎片化严重:对于点播服务来说, 由于 TS 切片通常较小, 海量碎片在文件分发, 一致性缓存, 存储等方面都有较大挑战.














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









