







 本文详细介绍了使用Scrapy框架爬取腾讯招聘网站工作岗位信息的过程,包括配置项目、解析数据、翻页处理和获取详情页信息。同时,文章还补充了古诗文网站的详情页抓取,验证数据是否在源码中,获取详情页地址并发起请求。此外,文章还涉及了Scrapy的相关设置、log管理和scrapyshell的使用。
本文详细介绍了使用Scrapy框架爬取腾讯招聘网站工作岗位信息的过程,包括配置项目、解析数据、翻页处理和获取详情页信息。同时,文章还补充了古诗文网站的详情页抓取,验证数据是否在源码中,获取详情页地址并发起请求。此外,文章还涉及了Scrapy的相关设置、log管理和scrapyshell的使用。
文章目录
第十八章 腾讯招聘案例
上节课我们学习了一个案例,操作了一下scrapy的流程,后面加了一个翻页处理。找到下一页的链接,找到链接之后生成一个scrapy.Request()对象,yield给引擎来处理。这是处理翻页的代码:
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
if next_href:
next_url = response.urljoin(next_href) # 补全url 补全 1 拼串 2 urljoin()
request = scrapy.Request(next_url)
yield request
但在这里还有些知识点需要补充。我们按住Ctrl点击Request方法,进去看一眼。
class Request(object_ref):
def __init__(self, url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None):
self._encoding = encoding # this one has to be set first
self.method = str(method).upper()
self._set_url(url)
self._set_body(body)
if not isinstance(priority, int):
raise TypeError(f"Request priority not an integer: {priority!r}")
self.priority = priority
if callback is not None and not callable(callback):
raise TypeError(f'callback must be a callable, got {type(callback).__name__}')
if errback is not None and not callable(errback):
raise TypeError(f'errback must be a callable, got {type(errback).__name__}')
self.callback = callback
self.errback = errback
self.cookies = cookies or {}
self.headers = Headers(headers or {}, encoding=encoding)
self.dont_filter = dont_filter
self._meta = dict(meta) if meta else None
self._cb_kwargs = dict(cb_kwargs) if cb_kwargs else None
self.flags = [] if flags is None else list(flags)
@property
def cb_kwargs(self):
if self._cb_kwargs is None:
self._cb_kwargs = {}
return self._cb_kwargs
@property
def meta(self):
if self._meta is None:
self._meta = {}
return self._meta
def _get_url(self):
return self._url
def _set_url(self, url):
if not isinstance(url, str):
raise TypeError(f'Request url must be str or unicode, got {type(url).__name__}')
s = safe_url_string(url, self.encoding)
self._url = escape_ajax(s)
if (
'://' not in self._url
and not self._url.startswith('about:')
and not self._url.startswith('data:')
):
raise ValueError(f'Missing scheme in request url: {self._url}')
url = property(_get_url, obsolete_setter(_set_url, 'url'))
def _get_body(self):
return self._body
def _set_body(self, body):
if body is None:
self._body = b''
else:
self._body = to_bytes(body, self.encoding)
body = property(_get_body, obsolete_setter(_set_body, 'body'))
@property
def encoding(self):
return self._encoding
def __str__(self):
return f"<{self.method} {self.url}>"
__repr__ = __str__
def copy(self):
"""Return a copy of this Request"""
return self.replace()
def replace(self, *args, **kwargs):
"""Create a new Request with the same attributes except for those
given new values.
"""
for x in ['url', 'method', 'headers', 'body', 'cookies', 'meta', 'flags',
'encoding', 'priority', 'dont_filter', 'callback', 'errback', 'cb_kwargs']:
kwargs.setdefault(x, getattr(self, x))
cls = kwargs.pop('cls', self.__class__)
return cls(*args, **kwargs)
@classmethod
def from_curl(cls, curl_command, ignore_unknown_options=True, **kwargs):
"""Create a Request object from a string containing a `cURL
<https://curl.haxx.se/>`_ command. It populates the HTTP method, the
URL, the headers, the cookies and the body. It accepts the same
arguments as the :class:`Request` class, taking preference and
overriding the values of the same arguments contained in the cURL
command.
Unrecognized options are ignored by default. To raise an error when
finding unknown options call this method by passing
``ignore_unknown_options=False``.
.. caution:: Using :meth:`from_curl` from :class:`~scrapy.http.Request`
subclasses, such as :class:`~scrapy.http.JSONRequest`, or
:class:`~scrapy.http.XmlRpcRequest`, as well as having
:ref:`downloader middlewares <topics-downloader-middleware>`
and
:ref:`spider middlewares <topics-spider-middleware>`
enabled, such as
:class:`~scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware`,
:class:`~scrapy.downloadermiddlewares.useragent.UserAgentMiddleware`,
or
:class:`~scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware`,
may modify the :class:`~scrapy.http.Request` object.
To translate a cURL command into a Scrapy request,
you may use `curl2scrapy <https://michael-shub.github.io/curl2scrapy/>`_.
"""
request_kwargs = curl_to_request_kwargs(curl_command, ignore_unknown_options)
request_kwargs.update(kwargs)
return cls(**request_kwargs)
我们看init方法里面,第一个参数是url,这是我们熟悉的,后面还有一个参数是callback=None,这是一个回调函数,当我们想整个scrapy流程的时候,当我们的spider(爬虫程序)处理完了之后,通过爬虫中间件,假如你还有链接地址,这个链接地址又通过中间件给了引擎,由引擎再给调度器,调度器再给下载器,又走了这么一圈的流程。callback就是一个回调函数。怎么用呢,我们看这个代码:
next_href = response.xpath('//a[@id="amore"]/@href').extract_first()
if next_href:
next_url = response.urljoin(next_href) # 补全url 补全 1 拼串 2 urljoin()
# request = scrapy.Request(next_url)
# yield request
yield scrapy.Request(url=next_url,callback=self.parse
) # 后面加上了callback参数,调用了parse对象,就是把url又给了parse对象去处理。
我们把后两行的代码注释一下。后面是补全的代码。其实,后面的参数不加也可以,只不过加上逻辑看起来更清晰。我们在pipelines里面加两行代码“爬虫开始”,“爬虫结束”便于观察:
import json
class GswPipeline:
def open_spider(self,spider):
print('爬虫开始')
self.fp = open('gsw02.txt','w',encoding='utf-8') # 新建一个文本来验证结果
def process_item(self, item, spider):
item_json = json.dumps(dict(item),ensure_ascii=False)
self.fp.write(item_json+'\n')
return item
def close_spider(self,spider):
print('爬虫结束')
self.fp.close()
我们start运行一下:
D:\Python38\python.exe D:/work/爬虫/Day19/my_code/Demo/gsw/gsw/spiders/start.py
爬虫开始
爬虫结束
Process finished with exit code 0
目录里出现了新建的文件夹:
除了callback,后面还有一个meta=None。上次我们的古诗文案例里,如果我们还需要点击详情页,进入查看诗文详情,那么如果我们要爬取详情页的内容,就需要向详情页发起请求,我们就需要一个详情页的url。下面我们先暂时放下,我们先讲另一个案例。
1. 腾讯招聘案例
https://careers.tencent.com/search.html这是腾讯官网的招聘平台。
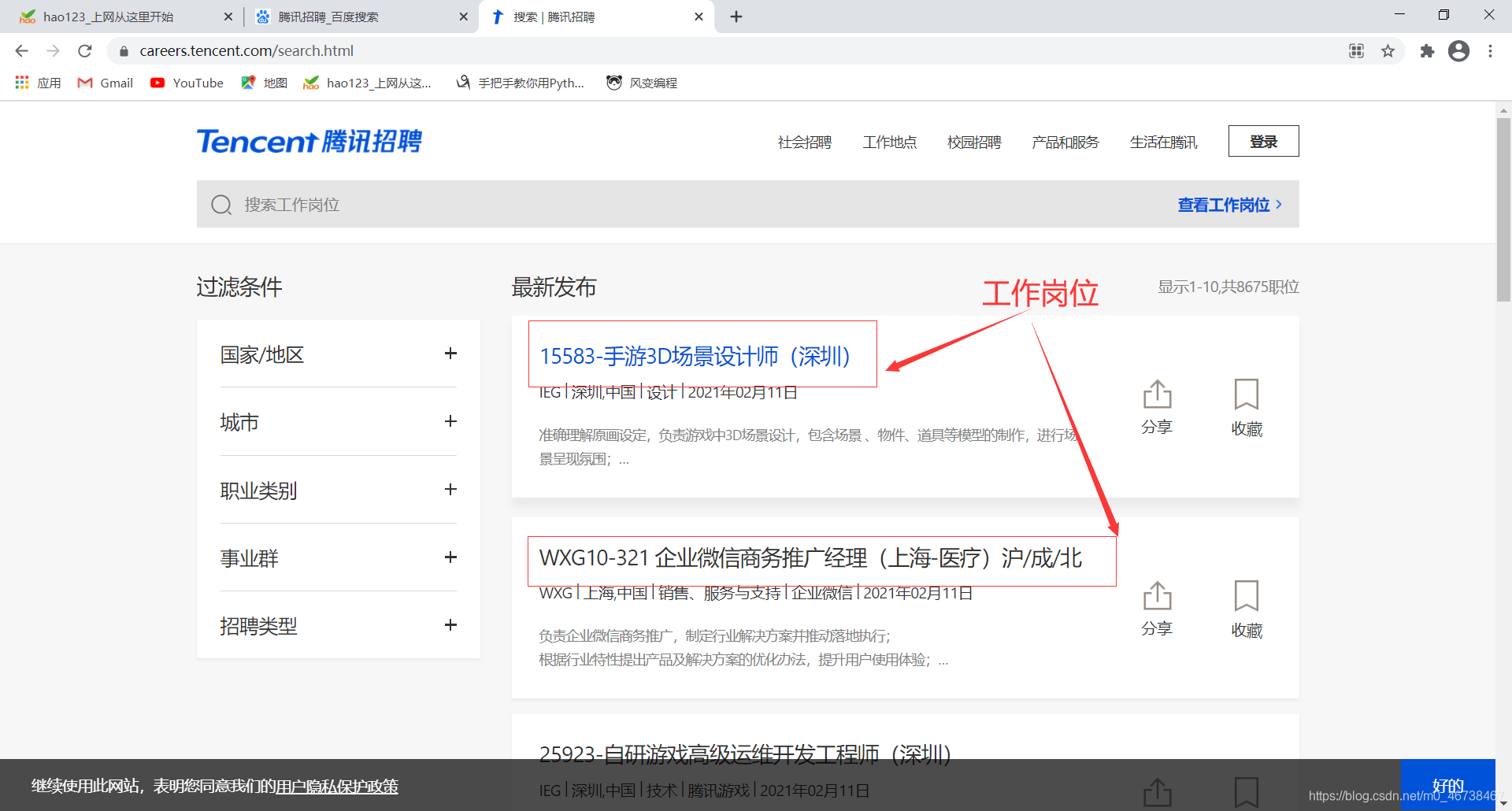
我们要爬取的是工作岗位信息。下面同样要做一个翻页的处理。
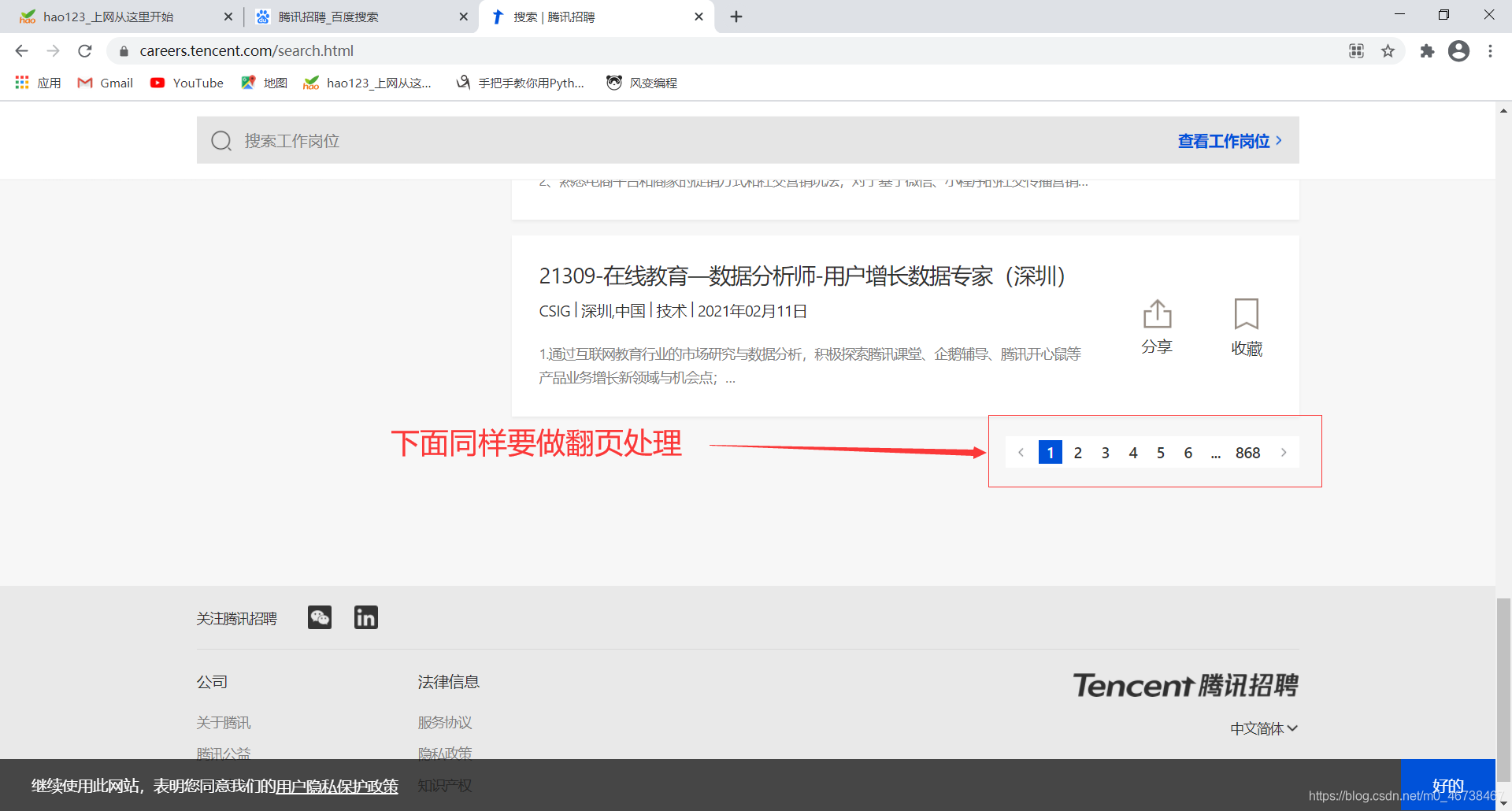
按照以往的逻辑,我们先搞定一页,然后再做翻页处理。上一次,我们是通过生成scrapy.Request对象yield给引擎来处理的。这个案例我们该怎么做呢?如果我们右键检查翻页按钮的话得到的是这个东西:
这个再用原来的思路显然是行不通的,没有url。
我们多点击几页,找一下url的规律:
# https://careers.tencent.com/search.html 第一页
# https://careers.tencent.com/search.html?index=2 第二页
# https://careers.tencent.com/search.html?index=3 第三页
# https://careers.tencent.com/search.html?index=4 第四页
实际上index=1时就是第一页。不过我们还需要弄清楚,我们要的数据在不在数据源码中,如果不在,及时我们发起了请求,也得不到结果。于是我们右键网页,选择源码,我们Ctrl+F调出搜索栏,搜索一个页面上显示的岗位,比如:15583-手游3D场景设计师(深圳)
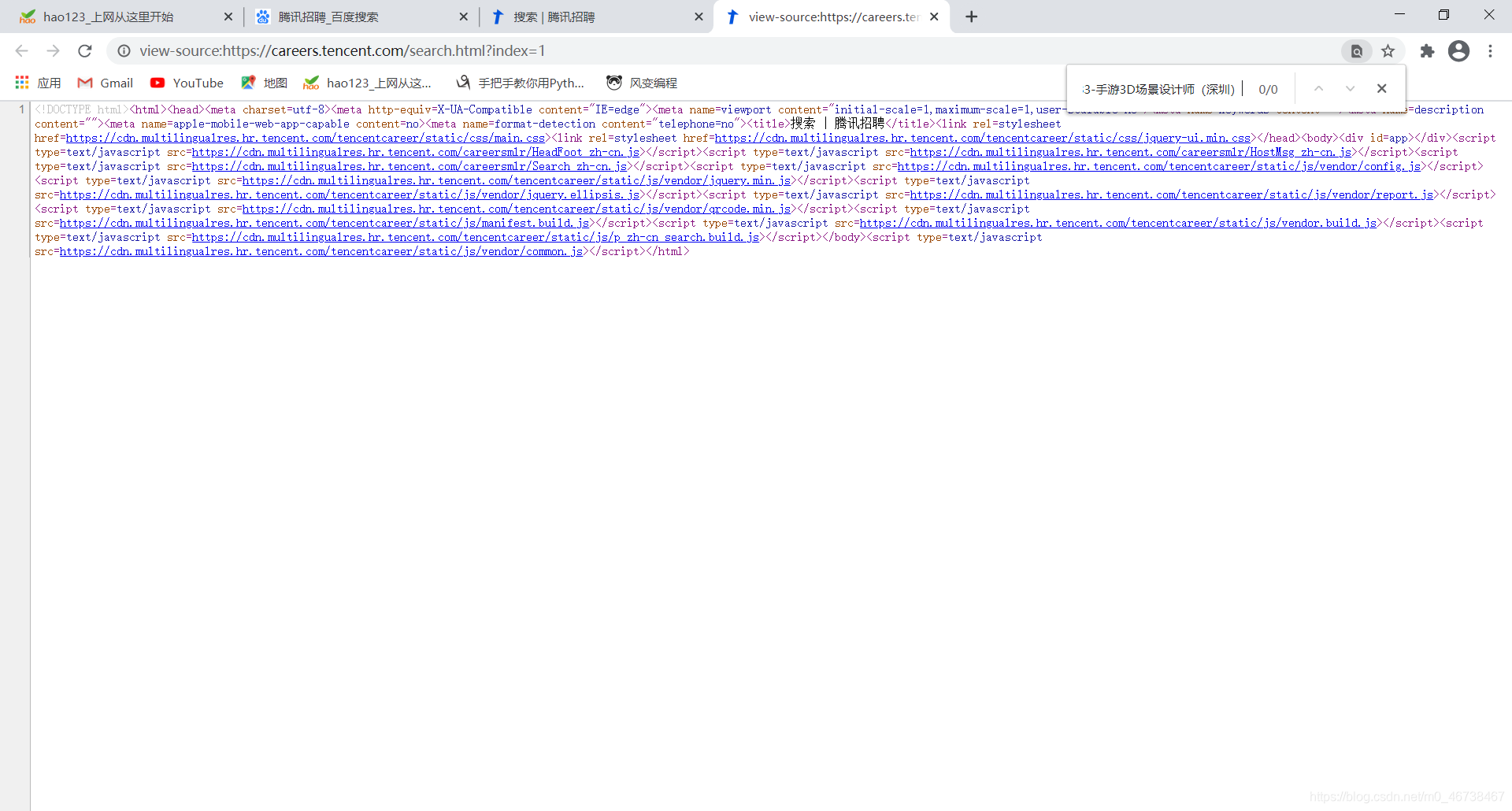
很遗憾,没有。而且我们看到,这个源码的数据很少。说明很多数据都是后来加载的。
如果嫌这个没有说服力,我们可以右键,检查,在第一个请求中查看response.Ctrl+F调出搜索:
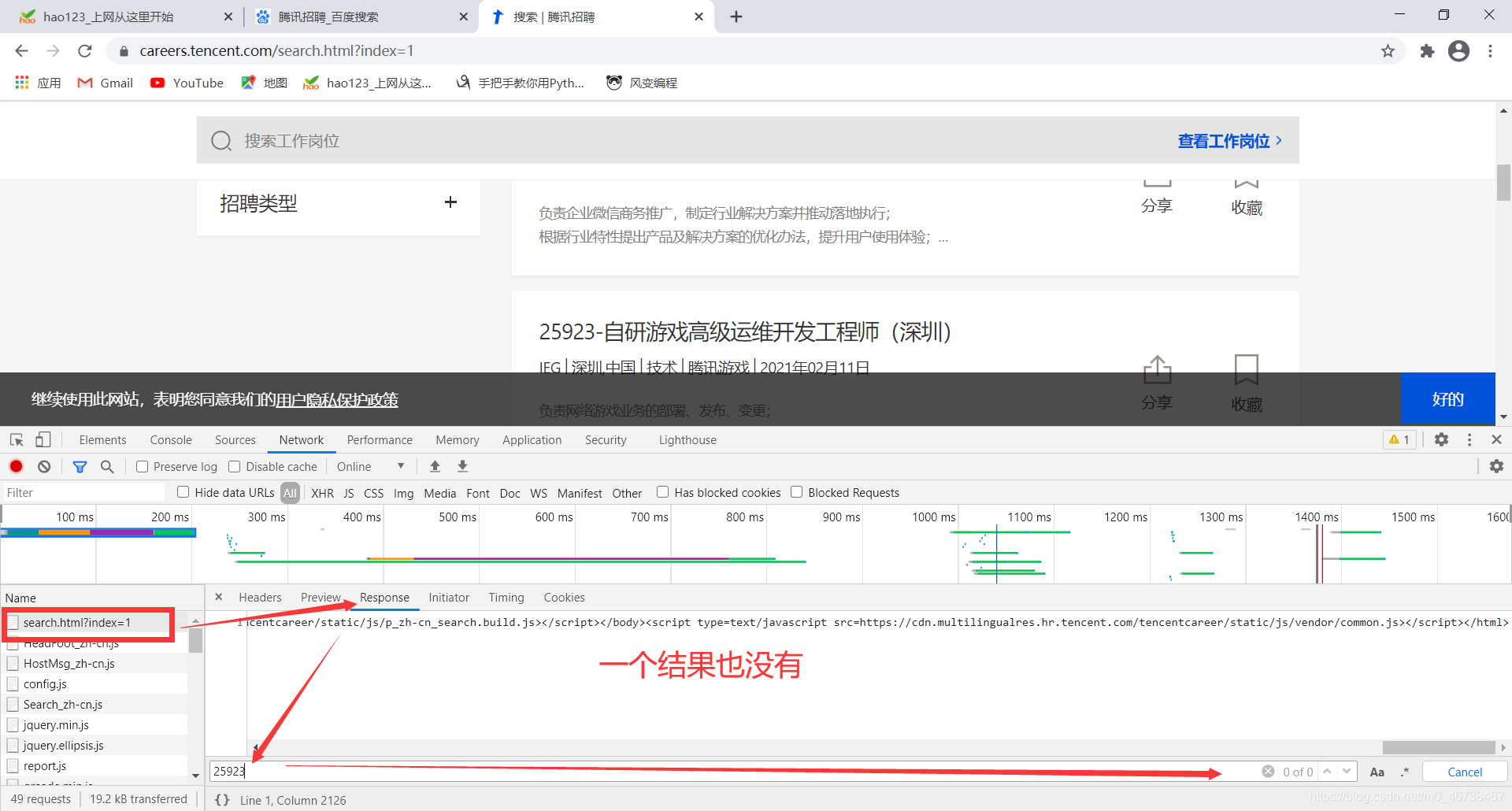
我们输入了页面中的一个内容,却一个结果也没有发现。这证明,这些数据是动态数据。处理方法是两种方式。一,selenium。二,分析数据接口。直接在XHR里面去找。
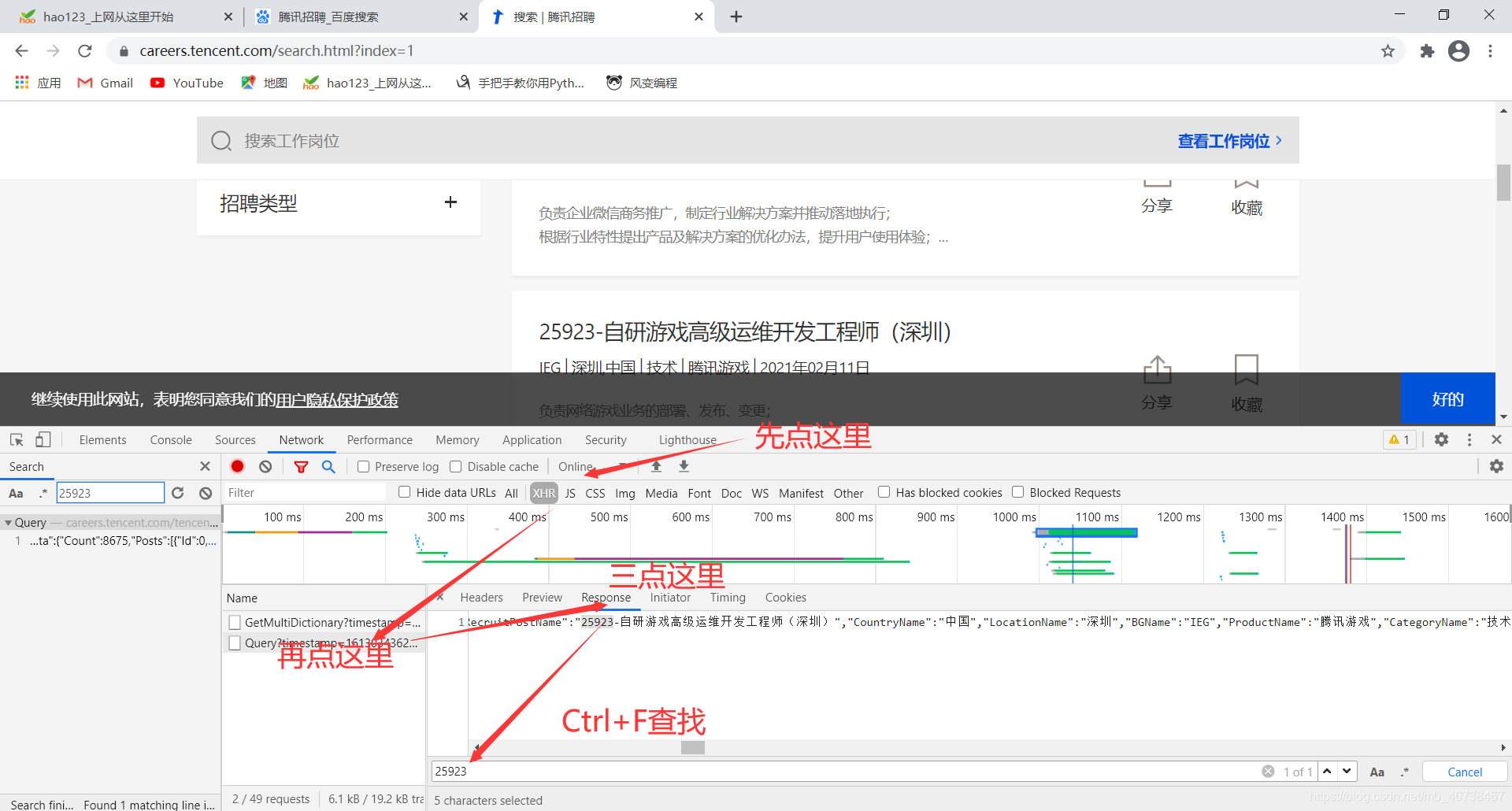
我们发现了结果。
那既然数据不在第一个搜索结果里,我们就不能用上面的url作为起始url。而是在我们后面的XHR里面找到的那个“Query?timestamp。。。”里的url才可以作为起始url
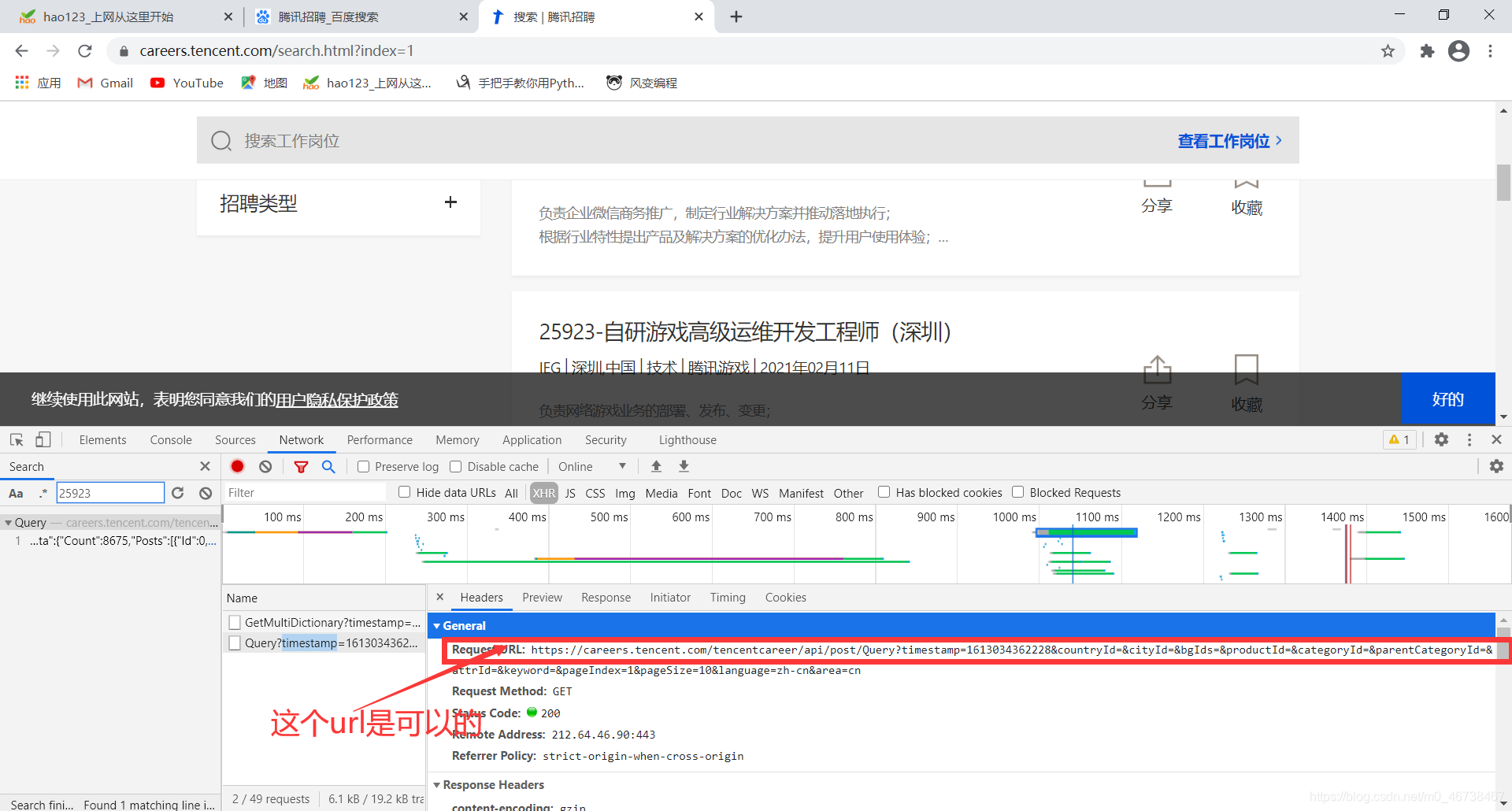
我们把这个url地址复制下来:
Request URL: https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1613034362228&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
我们再点开一页,找一下规律:
Request URL: https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1613035257107&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=2&pageSize=10&language=zh-cn&area=cn
我们很快发现了规律pageIndex=1的值在改变。只要动态替换这个值就可以了。好的,到此我们找到了。
2. 代码实现
创建项目:
D:\work\爬虫\Day20\my_code>scrapy startproject tencent
New Scrapy project 'tencent', using template directory 'd:\python38\lib\site-packages\scrapy\templates\project', created in:
D:\work\爬虫\Day20\my_code\tencent
You can start your first spider with:
cd tencent
scrapy genspider example example.com
接下来:
cd tencent
D:\work\爬虫\Day20\my_code>cd tencent
D:\work\爬虫\Day20\my_code\tencent>
接下来我们创建一个爬虫项目:
D:\work\爬虫\Day20\my_code\tencent>scrapy genspider hr tencent.com
Created spider 'hr' using template 'basic' in module:
tencent.spiders.hr
创建成功。
2.1 配置项目
我们双击一下hr项目,我们先把start_url改一下:
import scrapy
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1613034362228&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn
']
def parse(self, response):
pass
这样我们就可以拿到一个正确的response结果,我们进行解析就可以了。我们把拿到的字符串转成json数据:
import scrapy
import json
class HrSpider(scrapy.Spider):
name = 'hr'
allowed_domains = ['tencent.com']
start_urls = ['https://careers.tencent.com/tencentcareer/api/post/Query?timestamp=1613034362228&countryId=&cityId=&bgIds=&productId=&categoryId=&parentCategoryId=&attrId=&keyword=&pageIndex=1&pageSize=10&language=zh-cn&area=cn']
def parse(self, response):
data = json.loads(response.text)
print(data)
我们打开settings,加上LOG_LEVEL = ‘WARNING’
Robot = False
后面的headers打开,加上一个user-agent
然后再创建一个start文件
from scrapy import cmdline
cmdline.execute('scrapy crawl hr'.split())
我们直接start一下:
{'Code': 200, 'Data': {'Count': 8643, 'Posts': [{'Id': 0, 'PostId': '1316995743826845696', 'RecruitPostId': 67328, 'RecruitPostName': '33851-UE4海外项目技术支持工程师', 'CountryName': '中国', 'LocationName': '上海', 'BGName': 'IEG', 'ProductName': '', 'CategoryName': '技术', 'Responsibility': '参与管理中心与海外项目研发团队的技术相关沟通;\n与执行制作人紧密配合,与海外项目研发团队保持日常沟通,确保项目的技术层面工作健康推进,预警新产生的风险,协调内外部资源提供支持;\n做好海外项目研发团队阶段性提交版本和代码的整理工作,并提取能够横向分享的优秀内容,为各个研发团队提供更加全面的技术/系统/工具参考;\n参与建立管理中心独有的可共享资源库。', 'LastUpdateTime': '2021年02月12日', 'PostURL': 'http://careers.tencent.com/jobdesc.html?postId=1316995743826845696', 'SourceID': 1, 'IsCollect': False, 'IsValid': True}, {'Id': 0, 'PostId': '1328887379171221504', 'RecruitPostId': 68744, 'RecruitPostName': '17759-腾讯视频电商招商&供应链建设', 'CountryName': '中国', 'LocationName': '北京', 'BGName': 'PCG', 'ProductName': '', 'CategoryName': '产品', 'Responsibility': '主要负责公司直播带货BD品牌货品,搭建成熟的供应商体系; \n与商家沟通,商家异议处理,负责品牌的商务谈判和条款,维护好商家合作关系; \n确保直播前样品准备到位,完成相关流程等; \n配合供应相关部门的货品需求 ;\n可以根据商业化规则为节目定制特色商品并开发。\n', 'LastUpdateTime': '2021年02月12日', 'PostURL': 'http://careers.tencent.com/jobdesc.html?postId=1328887379171221504', 'SourceID': 1, 'IsCollect': False, 'IsValid': True}, {'Id': 0, 'PostId': '1328921972448436224', 'RecruitPostId': 68769, 'RecruitPostName': '17759-腾讯视频电商数据分析师', 'CountryName':  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









