






链路调用过程追踪主要分为以下几个步骤:
1)请求到来后,生成一个全局traceId,通过traceId可以串联起整个调用链,一个traceId代表一次请求。
2)除了traceId外,还需要生成spanId用于记录调用关系。每个服务会记录下parentId和spanId,通过他们可以构造出一个完整的调用链。
3)一个没有parentId的span成为root span,是调用链入口。
4)整个调用过程中的每个请求都要透传traceId和spanId。
5)每个服务将该次请求附带的traceId和附spanId作为parentId记录下来,并且将自己生成的spanId也记录下来。
6)要查看某次完整的调用链只要根据traceId查出所有调用记录,然后通过parentId和spanId构造出整个调用关系。
7)对调用链数据采集,对各应用中的日志数据进行采集。
8)对调用链数据存储及查询,对采集到的数据进行存储,由于日志数据量很大,不仅要能对其存储,还需要能快速查询。
目前主流APM系统对比:
CAT(开源): 由国内美团点评开源的,基于 Java 语言开发,目前提供 Java、C/C++、Node.js、Python、Go 等语言的客户端,监控数据会全量统计。国内很多公司在用,例如美团点评、携程、拼多多等。CAT 需要开发人员手动在应用程序中埋点,对代码侵入性比较强。
Zipkin(开源): 由 Twitter 公司开发并开源,Java 语言实现。侵入性相对于 CAT 要低一点,需要对web.xml 等相关配置文件进行修改,但依然对系统有一定的侵入性。Zipkin 可以轻松与 Spring Cloud 进行集成,也是 Spring Cloud 推荐的 APM 系统。
Pinpoint(开源): 韩国团队开源的 APM 产品,运用了字节码增强技术,只需要在启动时添加启动参数即可实现 APM 功能,对代码无侵入。目前支持 Java 和 PHP 语言,底层采用 HBase 来存储数据,探针收集的数据粒度非常细,但性能损耗较大,因其出现的时间较长,完成度也很高,文档也较为丰富,应用的公司较多。
SkyWalking(开源): 国人开源的产品,2019 年 4 月 17 日 SkyWalking 从 Apache 基金会的孵化器毕业成为顶级项目。目前SkyWalking支持 Java、.Net、Node.js 等探针,数据存储支持MySQL、ElasticSearch等。
还有很多不开源的APM系统,例如,淘宝鹰眼、Google Dapper 等等。
Vivo调用链agent的原理及实现(侧重埋点和数据采集):
调用链内部有两个非常核心的概念,分别是trace和span,都源自最初google介绍dapper的文章,无论是国内大厂的调用链产品还是开源调用链的实现,领域模型一般都借鉴了这两个概念,因此如果想很好理解调用链,这两个概念首先需要有清晰的理解:我们用traceId标志具体某一次请求调用,当然traceId是分布式唯一的,它串联了整个链路,后文中会介绍traceId的生成规则。注意,相同业务逻辑的请求调用,可以理解为发起调用的入口是同一个接口。由于程序逻辑中存在if/else等分支结构,某一次调用不能完整反映出一个trace链路,只有相同业务逻辑的多次请求调用触达的链路,合成后才算是一个完整的trace链路。例如一次请求从手机端发起,路由到后端后首先由nginx转发给服务A来处理,服务A先从数据库里查询数据,简单处理后继续向服务B发起请求,服务B处理完成将结果返回给A,最终手机端成功接收到响应,整个过程是同步处理的。
Span:一次调用会产生多个span,这些span组成一个不完整的trace;span需要标注本次调用所在调用链路(即span数据中要有traceId信息),以及其所在链路中的层级;spanId同一层级原子自增,跨层级将拼接“.”以及子序列;例如上图中span 1.1和1.2属同一层级,span 1与1.1或者1.2是跨层级;B与D之间的通信是rpc调用,这个过程有4个步骤:B发起调用,接着D接收到请求,然后D将结果返回给B,然后B接收到D的响应。这4个步骤组成一个完整的span,所以B和D各只有这个span的一半,因此spanId需要跨进程传递,后面将介绍如何传递。
- 调用链中数据采集
vivo调用链系统的定位是服务层监控,是vivo互联网监控体系中的重要一环。像服务异常、rpc调用耗时、慢sql等都是基本的监控点。如果埋点采集的数据需要满足调用耗时监控,那么至少在rpc调用及慢sql监控场景下,将以AOP的形式来实现埋点数据采集。vivo调用链Agent除了JVM的指标采集直接使用了java.lang.management.ManagementFactory外,其他都是以类似AOP的形式来实现的。
- 分布式ID(traceId)的生成规则
调用链中的traceId扮演着非常重要的角色,在上面的章节中提到了它用于串联多个进程间分散生成的span,除此之外,Agent端采样控制、入口服务识别、后端flink关键指标计算、用户查询完整调用链路、全局业务日志串联以及 Kafka、HBase和ES数据散列等都依赖于它。vivo 调用链系统traceId是长度为30的字符串,下图中我对有特殊含义的分段进行了着色。
0e34:16进制表示的Linux系统PID,用于单机多进程的区分,做到同一个机器不同的进程traceId不可能重复。c0a80001:16进制的ipv4的表示,可以识别生成这个traceId的机器ip,比如127.0.0.1的16进制表示过程为127.0.0.1->127 0 0 1->7f 00 00 01。d:代表着 vivo 内部的业务运行环境。一般我们会区分线下和线上环境,线下又可分开发、测试、压测等等环境,而这个 d 代表着某个线上的环境。1603075418361:毫秒时间戳。用于增加唯一性,可通过此读取入口请求发生的时间。0001:原子自增的ID,主要用于分布式ID增加唯一性,当前的设计可容忍单机每秒10000*1000=1千万的并发。
- 全链路数据传递能力
全链路数据传递能力是 vivo 调用链系统功能完整性的基石,也是Agent最重要的基础设施,前面提到过的spanId、traceId及链路标志等很多数据传递都依赖于全链路数据传递能力,系统开发中途由于调用链系统定位更加具体,当前无实际功能依赖于链路标志,本文将不做介绍。项目之初全链路数据传递能力,仅用于Agent内部数据跨线程及跨进程传递,当前已开放给业务方来使用了。
一般JDK中的ThreadLocal工具类用于多线程场景下的数据安全隔离,并且使用较为频繁,但是鲜有人使用过JDK 1.2即存在的InheritableThreadLocal,我也是从未使用过。
InheritableThreadLocal用于在通过new Thread()创建线程时将ThreadLocalMap中的数据拷贝到子线程中,但是我们一般较少直接使用new Thread()方法创建线程,取而代之的是JDK1.5提供的线程池ThreadPoolExecutor,而InheritableThreadLocal在线程池场景下就无能为力了。你可以想象下,一旦跨线程或者跨线程池了,traceId及spanId等等重要的数据就丢失不能往后传递,导致一次请求调用的链路断开,不能通过traceId连起来,对调用链系统来说是多么沉重的打击。因此这个问题必须解决。
其实跨进程的数据传递是容易的,比如http请求我们可以将数据放到http请求的header中,Dubbo 调用可以放到RpcContext中往后传递,MQ场景可以放到消息头中。而跨线程池的数据传递是无法做到对业务代码无侵入的,vivo调用链Agent是通过拦截ThreadPoolExecutor的加载,通过字节码工具修改线程池ThreadPoolExecutor的字节码来实现的,这个也是一般开源的调用链系统不具备的能力。
- javaagent 介绍
javaagent是一个JVM参数,调用链通过这个参数实现类加载的拦截,修改对应类的字节码,插入数据采集逻辑代码。开发javaagent应用需要掌握以下知识点:1、javaagent参数使用;2、了解JDK的Instrumentation机制( premain方法、 ClassFileTransformer接口)及MANIFEST.MF文件中关于Premain-Class参数配置;3、字节码工具的使用;4、类加载隔离技术原理及应用。
- 各组件埋点详情
截止2019年底vivo调用链 Agent埋点覆盖的组件,及埋点的具体位置。
- 半自动化埋点能力介绍
经过对埋点能力较深的封装后,Agent中新增加一个组件的埋点是非常高效的,一般情况步骤如下:对需要埋点的第三方框架/组件核心逻辑执行流程进行debug,了解其执行过程,选定合适的aop逻辑切入点,切入点的选取要易于拿到span中各个字段的数据;创建埋点切面类,继承特定的父类,实现抽象方法,在方法中标注要切入埋点的方法,以及用于实现aop逻辑的interceptor;实现interceptor逻辑,在openSpan方法中获取部分数据,在closeSpan中完成剩余数据的获取;设置/控制interceptor逻辑所在类可以被Thread.currentThread().getContextClassLoader()这个类加载器加载到,然后打开此组件埋点逻辑生效的开关。
7、span数据流图
图中可以看出,在生成完整的(closeSpan()完成调用)半个(参考调用链入门之核心领域概念小节)span后,会首先缓存在ThreadLocal空间。在完成本线程全部逻辑处理后,执行finish()转储到disruptor,再由disruptor的消费者线程定时刷到kafka的客户端缓存,最终发送到kafka队列。
Agent的主要职责是埋点和数据采集,埋点理当是整个Agent中最为核心的逻辑,除了类隔离功能外,其他功能块都是可以直接去掉而不影响其他模块的功能,遵循了微内核应用架构模式。类加载隔离的控制目标是自己用到的三方包不与业务方的三方包因版本产生冲突,并且保证Agent中逻辑执行时不出现找不到类的问题。
要做好调用链系统的研发,显然是一个困难的工作,难点不仅仅在于 Agent 技术难点解决,也在于产品能力的决策与挖掘,在于怎样用最少的资源满足产品需求,更在于在有限资源前提下来做海量数据计算。
Tracing Skywalking
Skywalking是由国内开源爱好者吴晟(原OneAPM工程师,目前在华为)开源并提交到Apache孵化器的产品,它同时吸收了Zipkin/Pinpoint/CAT的设计思路,支持非侵入式埋点。是一款基于分布式跟踪的应用程序性能监控系统。另外社区还发展出了一个叫OpenTracing的组织,旨在推进调用链监控的一些规范和标准工作。Skywalking是一个可观测性分析平台和应用性能管理系统,它也是基于OpenTracing规范、开源的AMP系统。Skywalking提供分布式跟踪、服务网格遥测分析、度量聚合和可视化一体化解决方案。支持Java, .Net Core, PHP, NodeJS, Golang, LUA, c++代理。支持Istio +特使服务网格
1、Skywalking架构
SkyWalking 分为三个核心部分:Agent(探针)、OAP、UI 界面。
1)Agent(探针):Agent 运行在各个服务实例中,负责采集服务实例的 Trace 、Metrics 等数据,然后通过 gRPC 方式上报给 SkyWalking 后端。
2)OAP:SkyWalking 的后端服务,其主要责任有两个。
一个是负责接收 Agent 上报上来的 Trace、Metrics 等数据,交给 Analysis Core (涉及 SkyWalking OAP 中的多个模块)进行流式分析,最终将分析得到的结果写入持久化存储中。SkyWalking 可以使用 ElasticSearch、H2、MySQL 等作为其持久化存储,一般线上使用 ElasticSearch 集群作为其后端存储。
另一个是负责响应 SkyWalking UI 界面发送来的查询请求,将前面持久化的数据查询出来,组成正确的响应结果返回给 UI 界面进行展示。
- UI 界面:SkyWalking 前后端进行分离,该 UI 界面负责将用户的查询操作封装为 GraphQL 请求提交给 OAP 后端触发后续的查询操作,待拿到查询结果之后会在前端负责展示。
2、业务调用链路监控
2.1、通过给服务添加探针并产生实际的调用之后,我们可以通过Skywalking的前端UI查看服务之间的调用关系。我们简单模拟一次服务之间的调用。本地搭建了网关、用户、认证3个服务,服务之间简单的通过Feign Client 来模拟远程调用。从图中可以看到:有3个服务节点:pscp-user& pscp-uaa & pscp-zuul-gateway,有一个数据库节点:localhost【mysql】,一个系统的拓扑图让我们清晰的认识到系统之间的应用的依赖关系以及当前状态下的业务流转流程。点击节点,可以看到更详细的信息。
2.2、全局监测
2.3、全链路性能追踪
3、SkyWalking 特点:
1)多语言自动探针,支持 Java、.NET Code 等多种语言。
2)为多种开源项目提供了插件,为 Tomcat、 HttpClient、Spring、RabbitMQ、MySQL 等常见基础设施和组件提供了自动探针。
3)微内核 + 插件的架构,存储、集群管理、使用插件集合都可以进行自由选择。
支持告警。
优秀的可视化效果。
- 管理系统间的复杂调用链路数据(图数据库):
- 技术背景:
图数据库是以点、边为基础存储单元,以高效存储、查询图数据为设计原理的数据管理系统。图数据库的概念:图:一组点和边的集合,”点“表示实体,”边“表示实体间的关系。在图数据库中,数据间的关系和数据同样重要,他们被作为数据的一部分存储起来,这样图数据库就能够快速响应复杂的关联查询。图数据库可以直观地可视化关系,是存储、查询、分析高度互联的最优办法。图数据库属于非关系型数据库(NoSQL)。图数据库把数据间的关系作为数据的一部分进行存储,关联上可添加标签、方向、属性,这就是图数据库的性能优势所在。
图处理技术解决了当今宏观业务的一个大趋势:利用高度连接的数据中复杂、动态的关系来产生洞察力和竞争优势。相比关系数据库,图数据库是表示和查询连接数据的最佳方式。随着近几年的快速发展,通用的图数据库已经逐步成熟,基于图数据库的应用如知识图谱、风险防控、智能物联网在金融、电信、公共安全、医疗等行业快速落地,并形成了较好的应用效果。 传统的关系型数据库在处理这些关联数据时,大量的连接操作造成性能成指数级下降;而 NoSQL 数据库(图数据库以外)采用的数据结构和分布式架构,更适合离散、关联关系弱的数据存储管理。图数据库中丰富的关系表示,完整的事务支持,提供了高效的关联查询和完备的实体信息。图数据库以图论为理论基础,使用图模型,将关联数据的实体作为顶点(vertex)存储,关系作为边(edge)存储,解决了数据复杂关联带来的严重随机访问问题。可以更加形象地展示出不同系统之间的调用关系。
目前,各种图数据库产品百花齐放,也因为数据存储和处理的方式不同,不同类型的图数据库产品特点迥异。所以,在实际工作和研究中,要结合自身实际情况,选择最适合自己的图数据库。
- 技术选择:Nebula Graph数据库
Nebula Graph 是一款开源的、分布式的、易扩展的原生图数据库,能够承载数千亿个点和数万亿条边的超大规模数据集,并且提供毫秒级查询。Nebula Graph 是由杭州悦数科技有限公司自主研发的开源图数据库,安全可控,其核心代码采用 Apache 2.0 协议开源。Nebula Graph 可灵活加载不同数据源的数据,支持 Spark、Flink、HBase 等多种周边大数据生态。它是世界上唯一能够容纳千亿个顶点和万亿条边,并提供毫秒级查询延时的图数据库解决方案。腾讯、美团、京东科技和快手等大型互联网科技公司都已经在生产环境使用 Nebula Graph 来提高他们的图数据处理能力。
在实时推荐场景,Nebula Graph 图数据库可以很好地帮助企业应对业务数据逻辑复杂且高度关联、保证实时遍历查询性能、业务数据量迅速增加等挑战
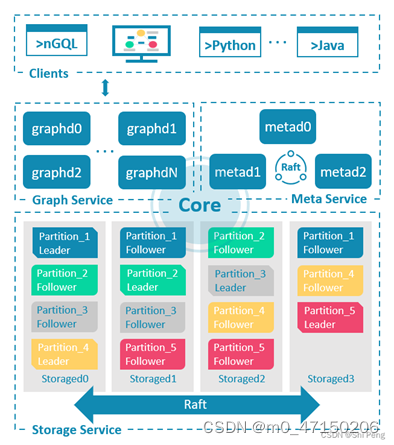
2.1架构设计
Nebula Graph 由三种服务构成:Graph 服务、Meta 服务和 Storage 服务,是一种存储与计算分离的架构。每个服务都有可执行的二进制文件和对应进程,用户可以使用这些二进制文件在一个或多个计算机上部署 Nebula Graph 集群。
Query Service:查询引擎部分,提供查询服务;主要功能就是解析nGQL,生成优化后的执行计划,组成action算子链提交执行!
Storage Service:存储引擎部分,基于RocksDb开发的分布式底层存储,用来持久化存储图数据;
Meta Service:元数据管理服务,主要用于图库集群元数据的管理;注意,如果该服务不可用,会导致整体图库的不可用,所以建议集群部署,提高可用性。
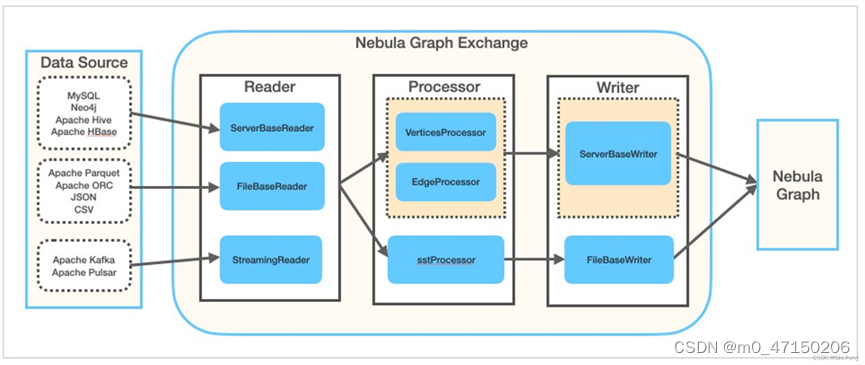
2.2 Nebula Exchange
Nebula Exchange用于把spark中的多种不同格式的数据迁移到nebula graph中,支持批量数据和流式数据的迁移。
Exchange工具由Reader、Processor、Writer三部分组成:
1、Reader:读取不同来源的数据,返回DataFrame
2、Processor:遍历DataFrame每行,根据配置文件中fields的映射关系,按列名获取对应的值。
3、Writer:在遍历指定批处理的行数后,Writer将这些批处理的数据一次性写入到nebula graph中
Exchange适用场景
1)来自Kafka, Pulsar的流式数据
2)从关系型数据库(如MySQL)或分布式文件系统(如HDFS)中获取的批式数据,如某个时间段的数据
3)要将大批量生成Nebula Graph能识别的SST文件,再导入到Nebula Graph数据库
4)需要导出Nebula Graph中保存的数据。
Exchange的优点:
1)支持多种来源的数据导入到nebula
2)支持不同来源的数据转为SST文件后导入
3)支持SSL加密
4)支持断点续传(目前仅Neo4j数据迁移时支持断点续传)
5)异步操作:在数据源中生成一条插入语句,发给graph服务,最后再执行插入操作
6)支持同时导入多个tag和edge type,不同tag和edge type可以是不同数据来源或格式
7)可使用spark中的累加器统计插入操作成功和失败的次数
8)采用HOCON(Human-Optimized Config Object Notation)配置文件格式,具有面向对象风格。
通过为期一个月的实习,我学习到了许多之前没有接触到的新技术,包括数据链路追踪技术以及图数据库技术,了解了这些技术可以运用到银行的信息系统中进行复杂关系的治理,可以大大减轻运维人员的压力。首先我想要感谢我的指导老师张志伟老师,在老师的指导帮助下,我顺利开展了对本课题的调研工作,同时也要感谢开发一部给了我一个锻炼自己磨砺自己的机会,在这次实习中,给我最大的收获是我觉得很多工作需要我去探索和探讨,要不怕吃苦、用于激流勇进,有的工作虽然单调重复,但这是磨砺意志的有效方法,我会告诫自己要认真完成,对每项工作都看做是公司对自己的一次考核,做到每一件事的过程中遇到困难一定要不放弃。虽然我的工作是课题调研,可能与我想象中实际开发的工作有点差别,但是我觉得调研工作是必不可少的,只有在调研好目前的技术路线我们才能去实际开发运用。我还要感谢我的同事们,当我遇到苦难时总会给予我帮助,在实习的一个月中,我收获了也成长了,这将是我人生中一段十分宝贵的经历,我也希望可以将来留在开发一部与各位老师们成为同事,在开发一部继续发挥自己的作用。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









