






一:概念
生成对抗网络(GAN)是深度学习中一类比较大的家族,是一种无监督深度学习模型,通过计算机生成数据,由Ian J. Goodfellow等人于2014年提出。生成对抗网络的主要思想是:通过生成器(generator)与判别器(discriminator)不断对抗进行训练。最终使得判别器难以分辨生成器生成的数据(图片,音频等)和真实的数据。是训练过程中生成网络(生成器,generator)与判别网络(判别器,discriminator)不断对抗的过程。所以,对于生成对抗网络,我们最终的目标一般是得到生成器,因为训练结束后我们是需要得到神经网络创作出来的作品。生成对抗网络被认为是当前最具前景、最具活跃度的模型之一,目前主要应用于样本数据生成、图像生成、图像修复、图像转换、文本生成等方向。
GAN一般情况下可以看做是无监督学习,因为我们训练的数据只有真实的图片,并没有标签。这里使用的标签也仅仅是真实数据的"真"与生成器生成图片的"假"。
二、GAN基本原理
1. 构成
GAN由两个重要的部分构成:生成器(Generator,简写作G)和判别器(Discriminator,简写作D)。
生成器:通过机器生成数据,目的是尽可能“骗过”判别器,生成的数据记做G(z);生成器的输入数据是一组随机噪声X(简单理解就是一个随机向量, 或者说是随机数种子),生成器去学习一个映射F, 将随机噪声X映射为一个结果Y, 这个结果就是我们想要生成的图片,也就是通过学习来的F, 生成器能将一个随机向量的空间映射到训练数据的分布上, 通过一个随机向量能通过映射F生成一个符合训练数据分布的数据。
判别器:判断数据是真实数据还是「生成器」生成的数据,目的是尽可能找出「生成器」造的“假数据”。它的输入参数是x,x代表数据,输出D(x)代表x为真实数据的概率,如果为1,就代表100%是真实的数据,而输出为0,就代表不可能是真实的数据。判别器的输入数据是生成器的输出Y或是训练数据X, 判别器是一个分类器, 判断输入数据是来自生成器还是训练数据。
这样,G和D构成了一个动态对抗(或博弈过程),随着训练(对抗)的进行,G生成的数据越来越接近真实数据,D鉴别数据的水平越来越高。在理想的状态下,G可以生成足以“以假乱真”的数据;而对于D来说,它难以判定生成器生成的数据究竟是不是真实的,因此D(G(z)) = 0.5。训练完成后,我们得到了一个生成模型G,它可以用来生成以假乱真的数据。
训练目标
生成器尽量骗过判别器
判别器尽量区分数据来源
理想模型
生成器完全学习到了训练数据的分布
判别器输出恒为1/2
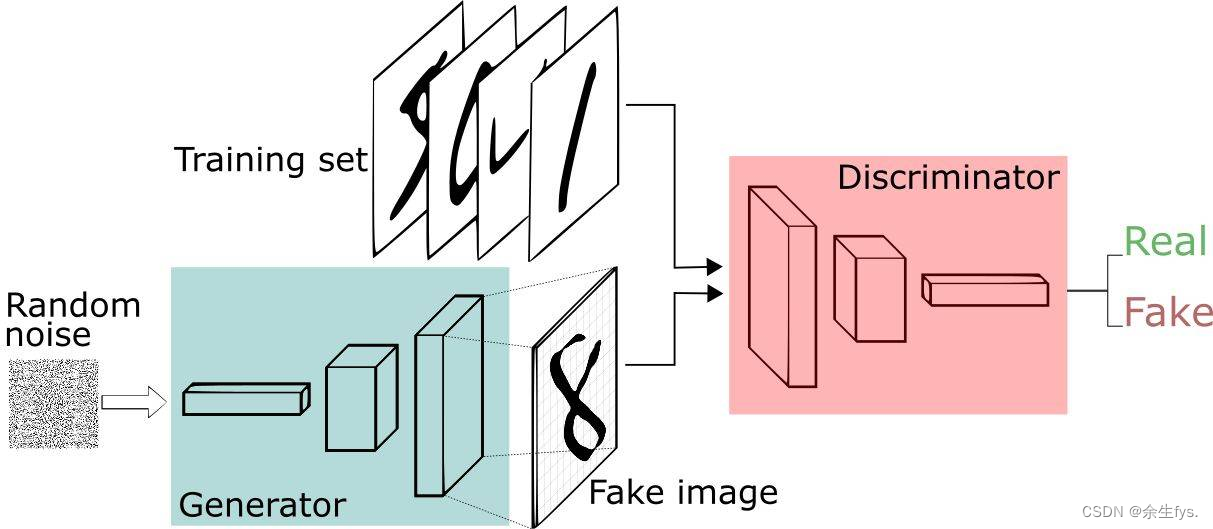
2. 训练过程
第一阶段:固定「判别器D」,训练「生成器G」。使用一个性能不错的判别器,G不断生成“假数据”,然后给这个D去判断。开始时候,G还很弱,所以很容易被判别出来。但随着训练不断进行,G技能不断提升,最终骗过了D。这个时候,D基本属于“瞎猜”的状态,判断是否为假数据的概率为50%。
第二阶段:固定「生成器G」,训练「判别器D」。当通过了第一阶段,继续训练G就没有意义了。这时候我们固定G,然后开始训练D。通过不断训练,D提高了自己的鉴别能力,最终他可以准确判断出假数据。
重复第一阶段、第二阶段。通过不断的循环,「生成器G」和「判别器D」的能力都越来越强。最终我们得到了一个效果非常好的「生成器G」,就可以用它来生成数据。
整个训练的过程为:
(1).从高斯分布中采样一批次长度为n的噪声向量。
(2).利用(1)中噪声向量,使用generator生成假图像。
(3).从真实数据采一批次真实图像,与(2)中的假图像混合,做好标签,训练discriminator。
(4).再从高斯分布中采样长度为n的一批次噪声向量,标签为“True”,训练GAN,此时GAN中的discriminator参数不能更新,只训练generator。
(5).按指定轮数重复上述步骤。
3. GAN的损失函数
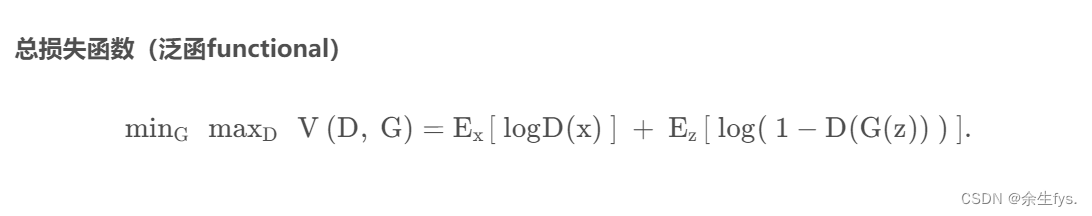
D:判别器 G:生成器 x:来自训练数据的样本数据 z: 随机噪声
说明:对于单个数据输入,输入数据来自训练数据x ,则D(x) = 1,输入数据来自生成器G( z ),则D( G( z ) ) = 0
判别器D的优化目标
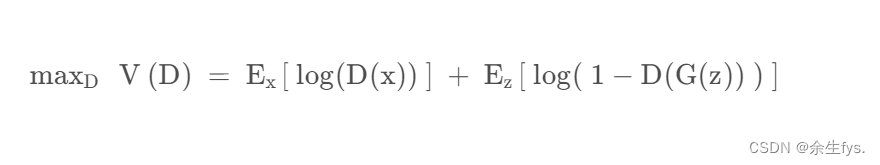
解释:
判别器越完美, 越能区分数据来源, 则第一个期望越接近0, 第二个期望越接近0
完美的判别器V(D)优化为0
生成器G的优化目标
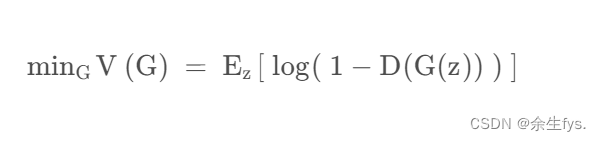
解释:
因为总损失函数中, 第一个期望不含G, 所以只用考虑第二个期望
生成器越完美, 越能骗过判别器, 第二个期望越接近负无穷
完美的生成器V(G)优化为负无穷
判别器的损失:
(1)判别器给真实图片打的分与其期望分数(1)的差距D_L1
(2)判别器给生成图片打的分与其期望分数(0)的差距D_L2
(3)则生成器的总损失为 D_L1 + D_L2
生成器的损失:
(1)生成图片与真实图片的差距
(2)实际上,将该差距转化为
生成器期望判别器给自己生成图片打多少分与实际判别器打多少分的差距
4. GAN的优缺点
(1)优点
能更好建模数据分布(图像更锐利、清晰);
理论上,GANs 能训练任何一种生成器网络。其他的框架需要生成器网络有一些特定的函数形式,比如输出层是高斯的;
无需利用马尔科夫链反复采样,无需在学习过程中进行推断,没有复杂的变分下界,避开近似计算棘手的概率的难题。
(2)缺点
模型难以收敛,不稳定。生成器和判别器之间需要很好的同步,但是在实际训练中很容易D收敛,G发散。D/G 的训练需要精心的设计。
模式缺失(Mode Collapse)问题。GANs的学习过程可能出现模式缺失,生成器开始退化,总是生成同样的样本点,无法继续学习。
原文链接:https://blog.csdn.net/qq_19300283/article/details/125734859
原文链接:https://blog.csdn.net/qq_15719613/article/details/134029786
原文链接:https://blog.csdn.net/weixin_60737527/article/details/127475864


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









