







基于Python的豆瓣电影数据分析与可视化系统(获取方式访问文末官网)
项目简介
在大数据与人工智能技术迅速发展的背景下,我们精心打造了一款基于Python的豆瓣电影数据分析与可视化系统,旨在为电影爱好者与专业人士提供全方位、个性化的观影服务体验。如今,电影观赏的需求已经超越了单一的娱乐享受,用户越来越关注个性化推荐、深度解析与社区互动的综合体验。
该系统包括六大核心模块:数据采集、数据概览、电影检索、数据管理、词云分析和多维可视化,构建了一个全面的服务框架。首先,系统通过Python技术从豆瓣平台抓取丰富的电影信息(如影片详情、评分、评论、标签等),确保数据采集的精准与合规。
所有采集的数据经过整理和清洗后,系统自动生成简洁明了的数据概览报告,概述了包括平均评分、热门类型、高评分导演和演员等关键指标。用户还可以通过强大的搜索功能,基于影片名称、关键词、导演、演员、类型和上映年份等多维度条件,快速定位自己感兴趣的内容。
平台还提供电影数据的精细化管理功能,允许用户对已有数据进行编辑操作,便于个性化整理与长期跟踪。通过词云图技术,平台能动态展示电影标题、演员、评分、简介等文本数据中的高频词汇,直观呈现热门话题、明星影响力以及观众情感倾向等。
此外,系统集成了多种数据可视化工具,通过时间序列分析、地理分析、类型分析等多维度展示,全面解析和呈现电影数据。
技术栈
- 后端:Flask、PyMySQL、MySQL、urllib
- 前端:Jinja2、Jquery、Ajax、layui
- 数据可视化:Matplotlib、Pandas
开发环境
| 开发环境 | 版本/工具 |
|---|---|
| PYTHON | 3.6.8 |
| 开发工具 | PyCharm |
| 操作系统 | Windows 10 |
| 内存要求 | 8GB 以上 |
| 浏览器 | Firefox (推荐)、Google Chrome (推荐)、Edge |
| 数据库 | MySQL 8.0 (推荐) |
| 数据库工具 | Navicat Premium 15 (推荐) |
| 项目框架 | FLASK |
功能模块
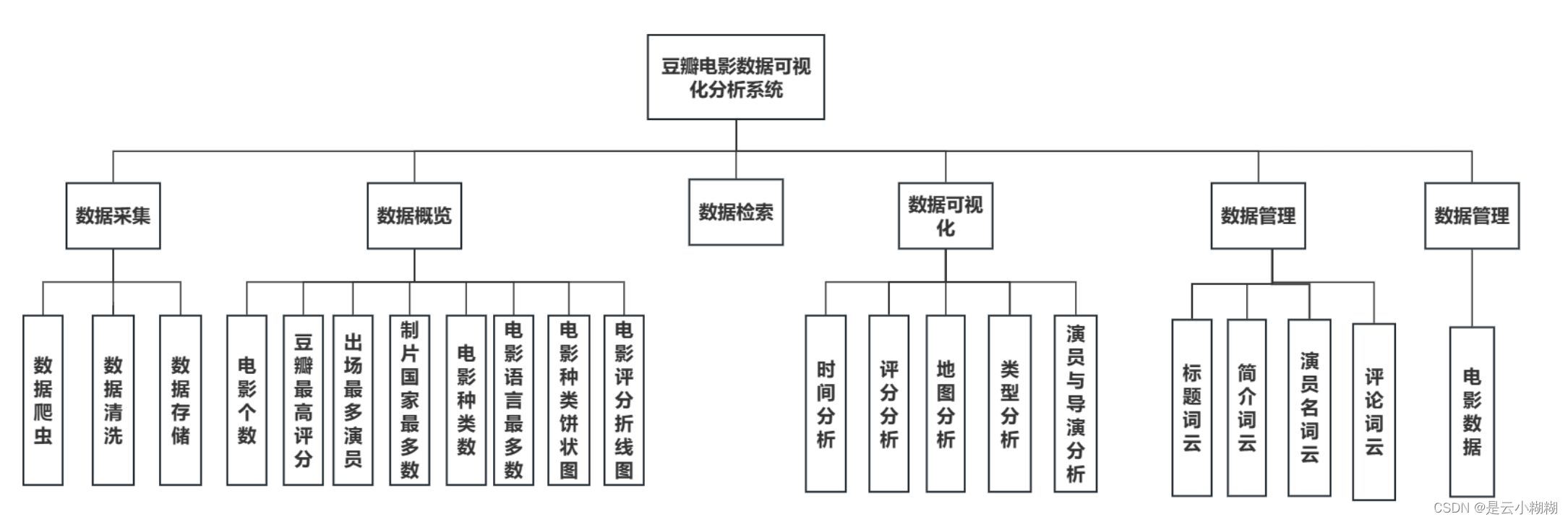
数据采集
通过Python编程技术抓取豆瓣电影数据,包括影片基本信息(如标题、年份、类型)、导演、演员、评分、评论、简介等多元信息。
数据概览
对采集的电影数据进行清洗和整合,平台自动生成数据概览报告,涵盖平均评分、最受欢迎类型、热门导演和演员等关键指标,帮助用户快速了解数据集的整体特征与市场趋势。
电影检索
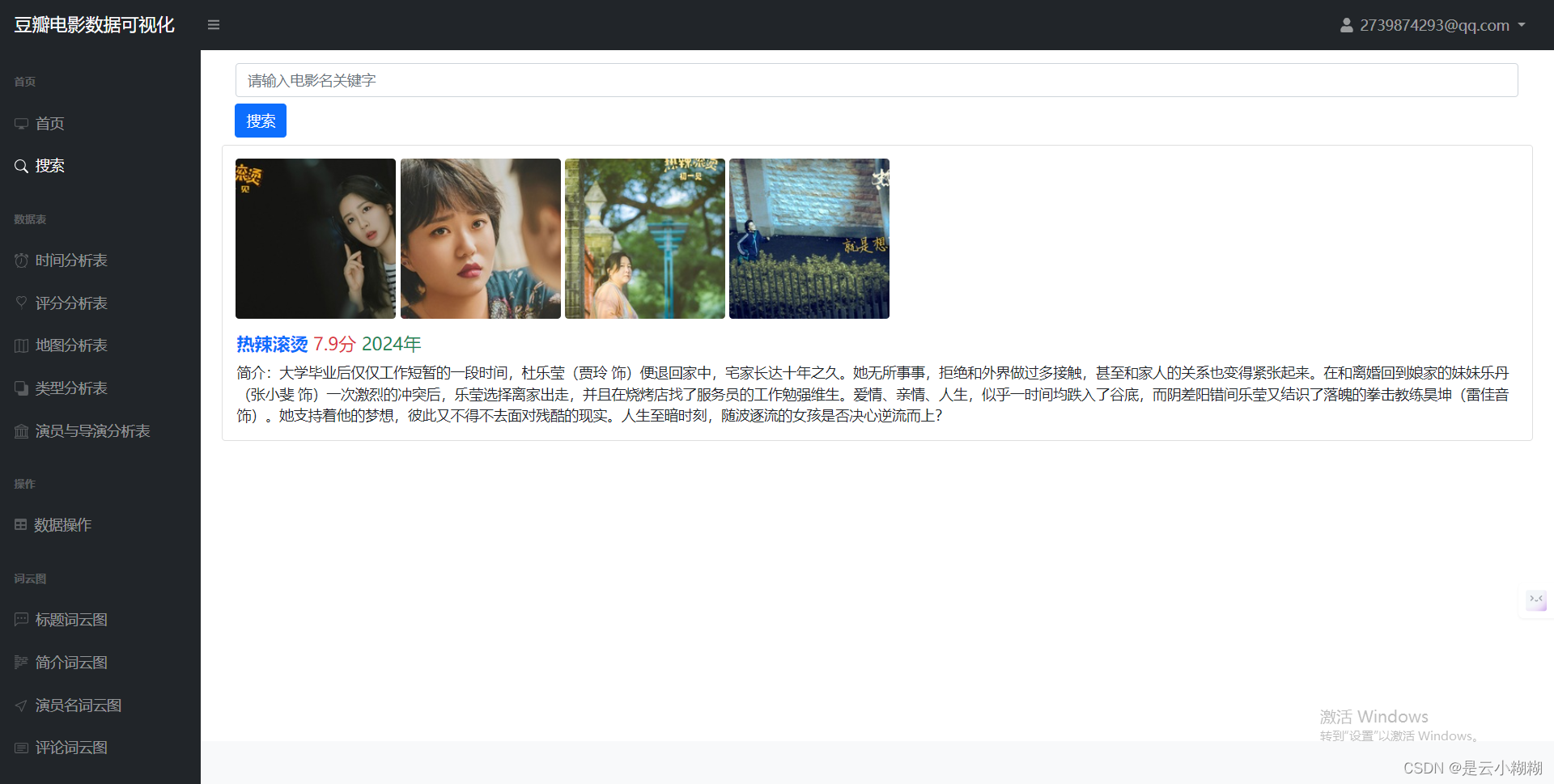
提供基于影片名称、关键词、导演、演员、类型、上映年份等条件的精确检索功能,满足用户的个性化需求。
数据管理
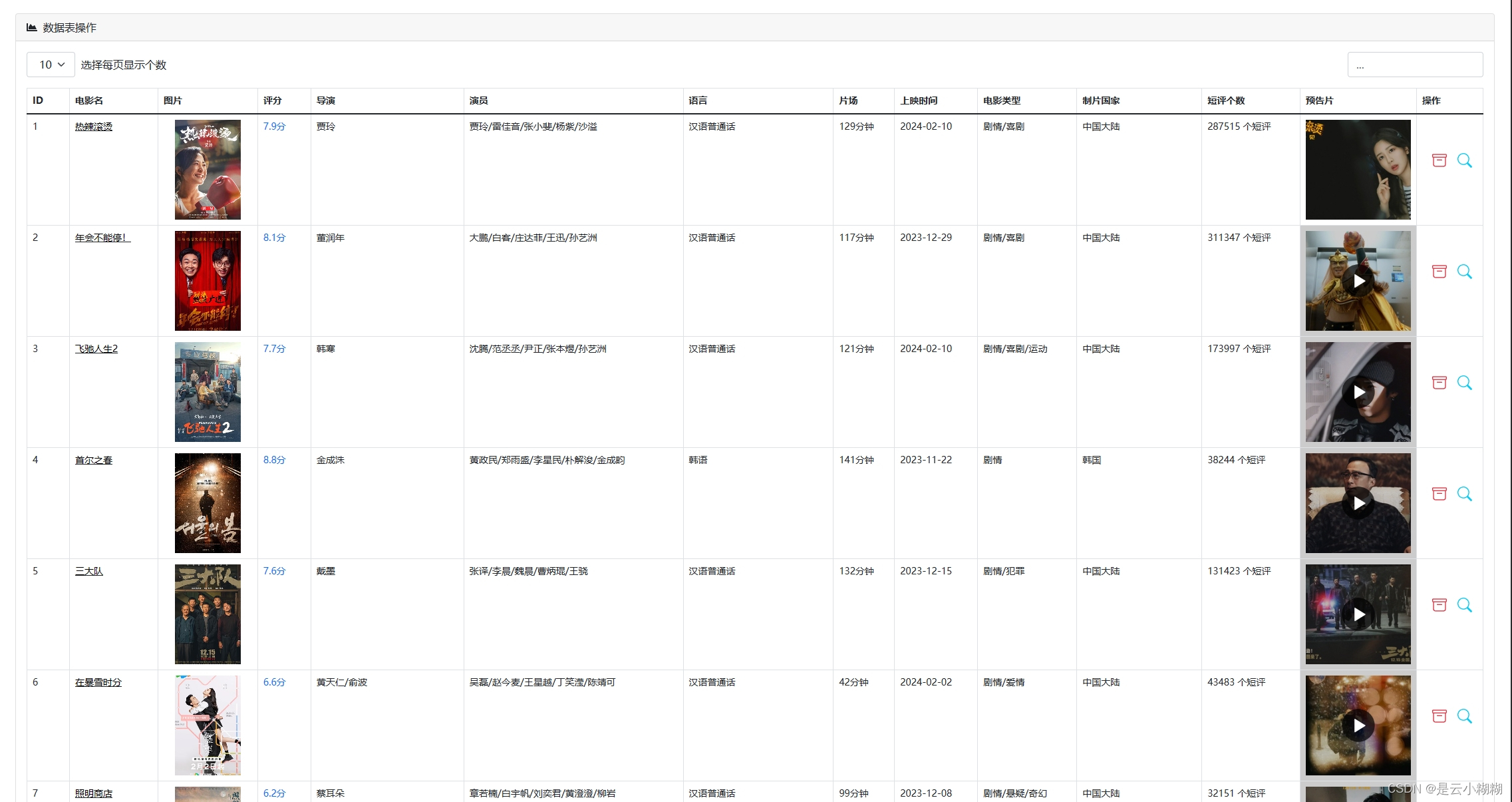
允许用户对采集的电影数据进行管理,如删除不需要的数据,以及对影片的图片、主演等属性进行编辑。
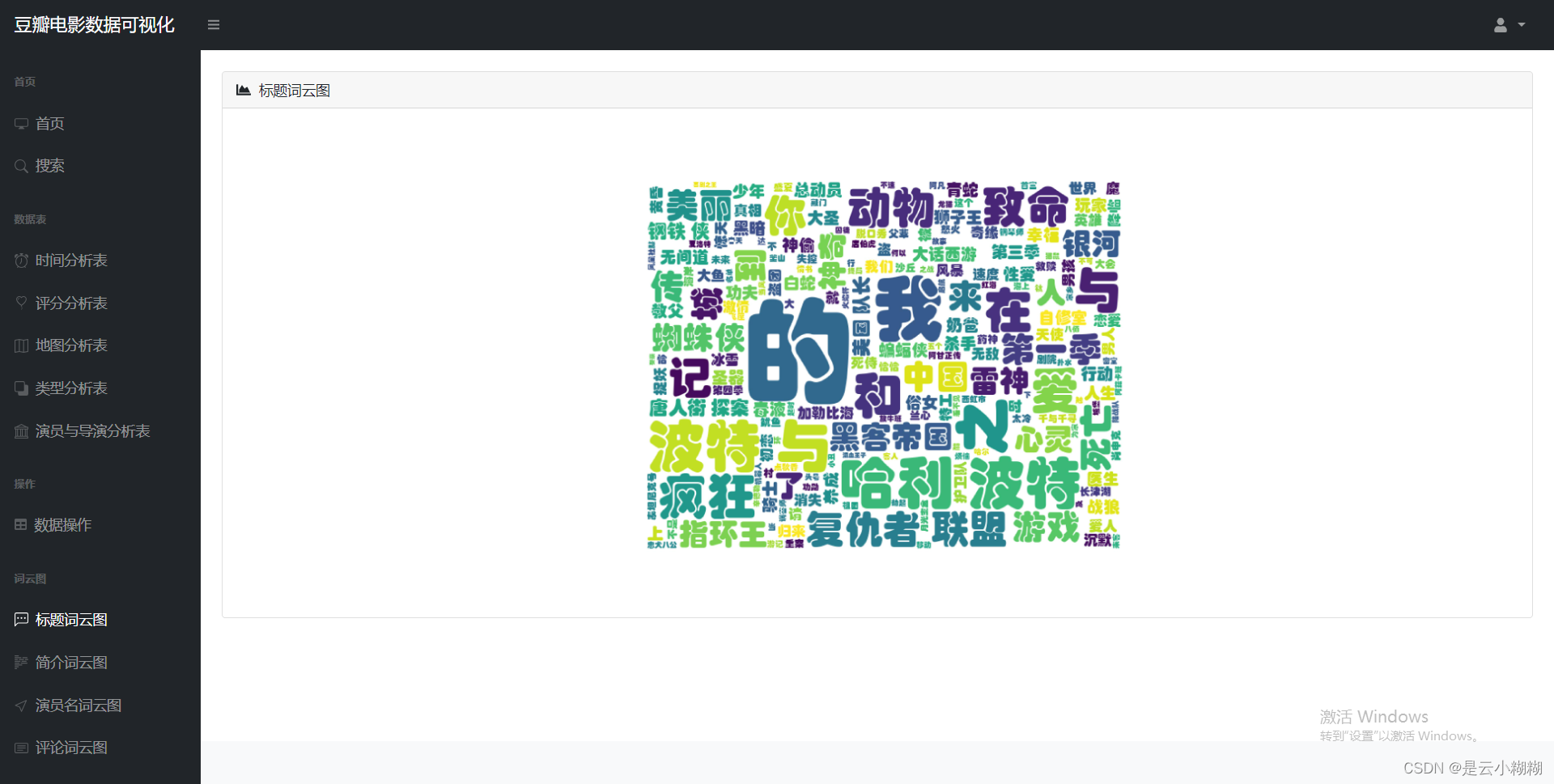
词云分析
使用词云图技术动态展示电影标题、演员、评分、简介等文本数据中的高频词汇,揭示观众关注的焦点和市场趋势。
数据可视化
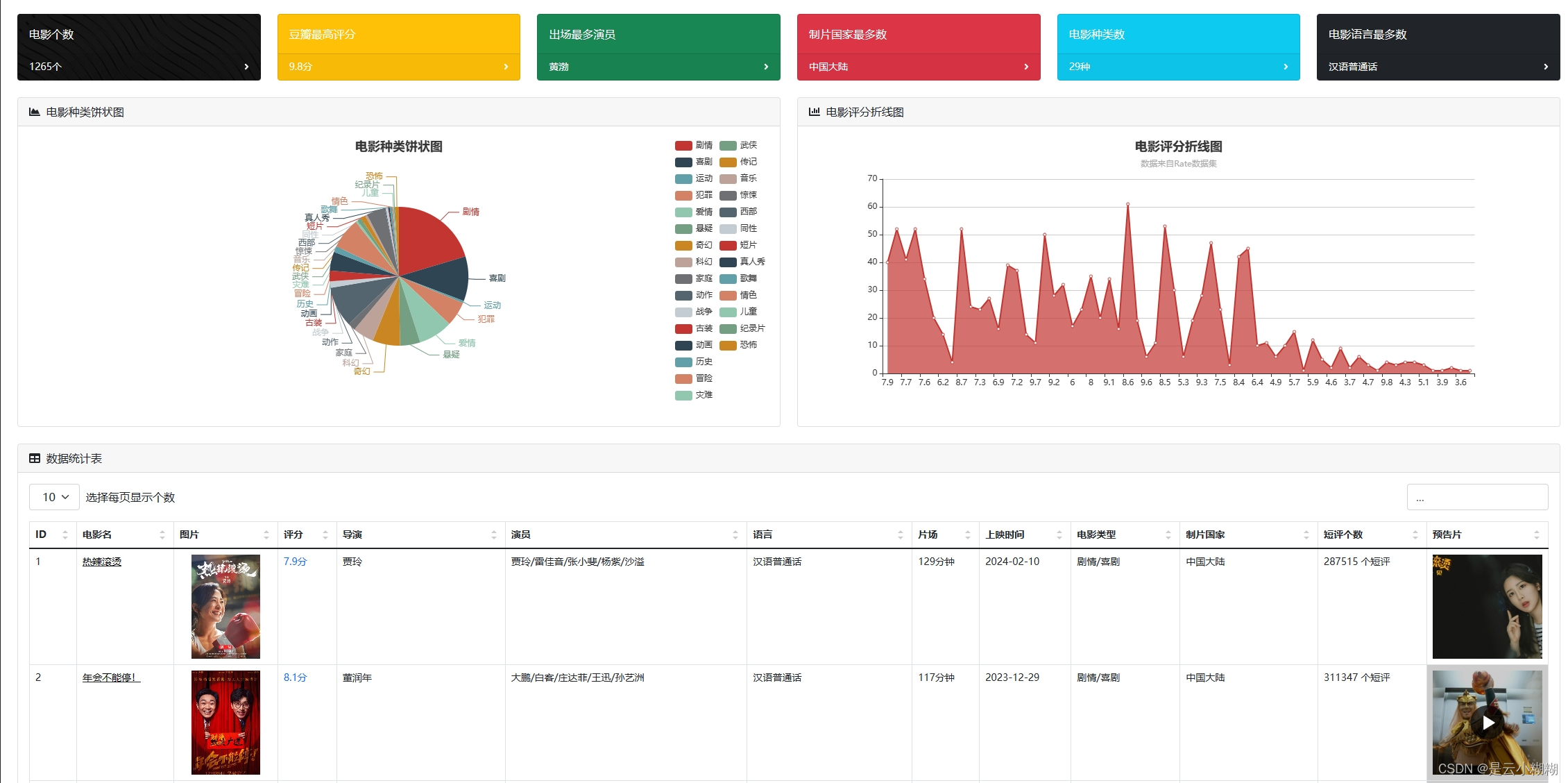
平台支持丰富的可视化图表,帮助用户从不同角度解析电影数据,包括时间序列分析、评分分析、类型分析、导演与演员分析等。
数据库设计
表名:comments
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int | 是 | 评论id |
| movieName | varchar | 否 | 电影名字 |
| commentContent | varchar | 否 | 电影评论 |
表名:movie
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int | 是 | 电影id |
| directors | varchar | 导演名 | |
| year | varchar | 年份 | |
| types | varchar | 类型 | |
| country | varchar | 国家 | |
| lang | varchar | 语言 | |
| time | varchar | 上映时间 | |
| movieTime | varchar | 时长 | |
| comment_len | varchar | 评论人数 | |
| starts | varchar | 评分 | |
| summary | varchar | 简介 | |
| comments | text | 评论 | |
| imgList | varchar | 图片链接 | |
| movieUrl | varchar | 视频链接 | |
| detailLink | varchar | 详细链接 |
表名:user
| 字段名称 | 数据类型 | 是否必填 | 注释 |
|---|---|---|---|
| id | int | 是 | 用户id |
| movieName | varchar | 否 | 电影名字 |
| commentContent | varchar | 否 | 电影评论 |
功能实现
电影检索模块
@app.route("/search/<int:searchId>",methods=['GET','POST'])
def search(searchId):
email = session['email']
allData = getAllData()
data = []
if request.method == 'GET':
if searchId == 0:
return render_template(
'search.html',
idData=data,
email=email
)
for i in allData:
if i[0] == searchId:
data.append(i)
return render_template(
'search.html',
data=data,
email=email
)
else:
searchWord = dict(request.form)['searchIpt']
def filter_fn(item):
if item[3].find(searchWord) == -1:
return False
else:
return True
data = list(filter(filter_fn, allData))
return render_template(
'search.html',
data=data,
email=email
)
配套论文目录

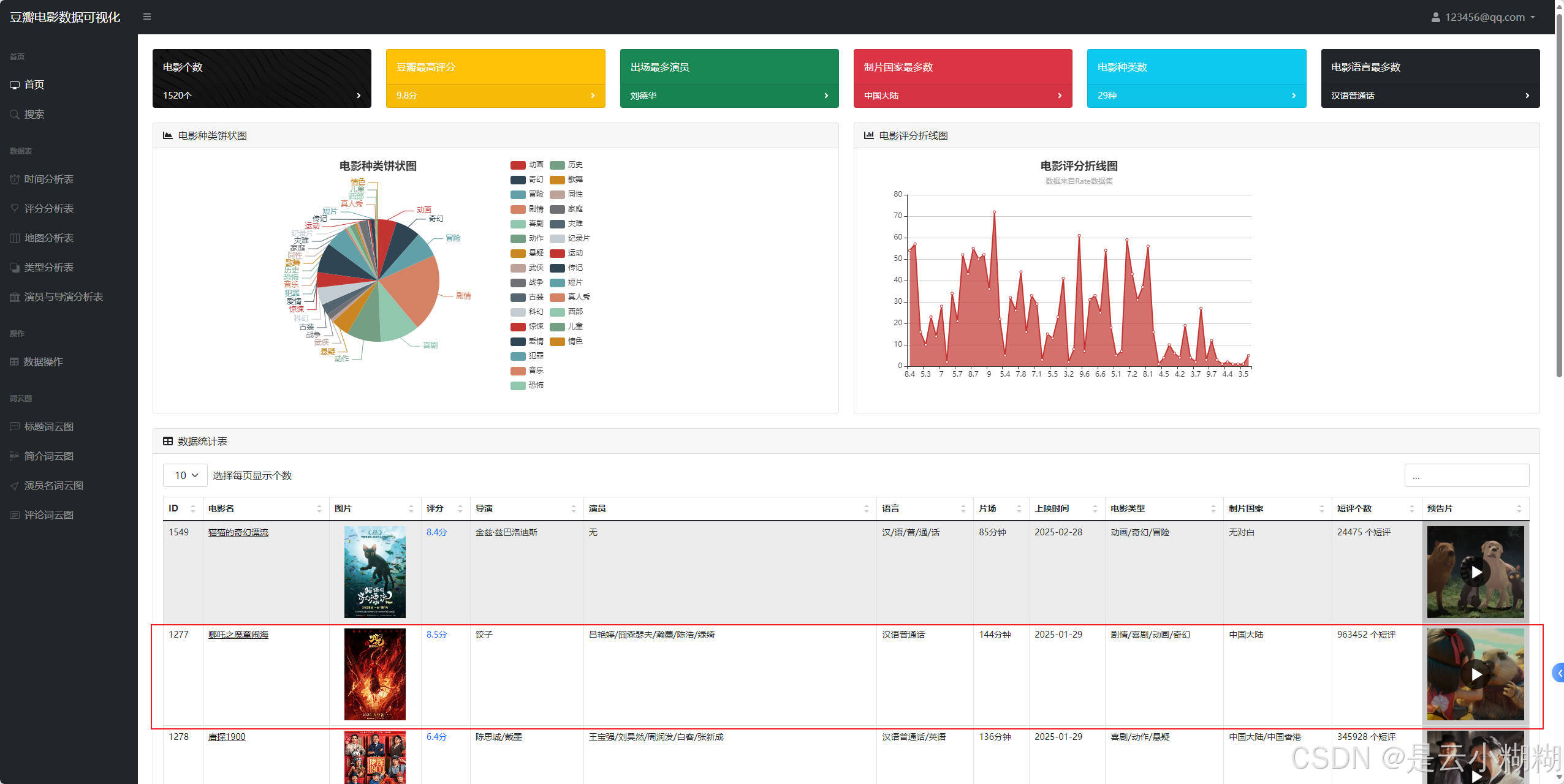
运行截图
最新首页:
登录首页:
注册页面:
功能菜单:
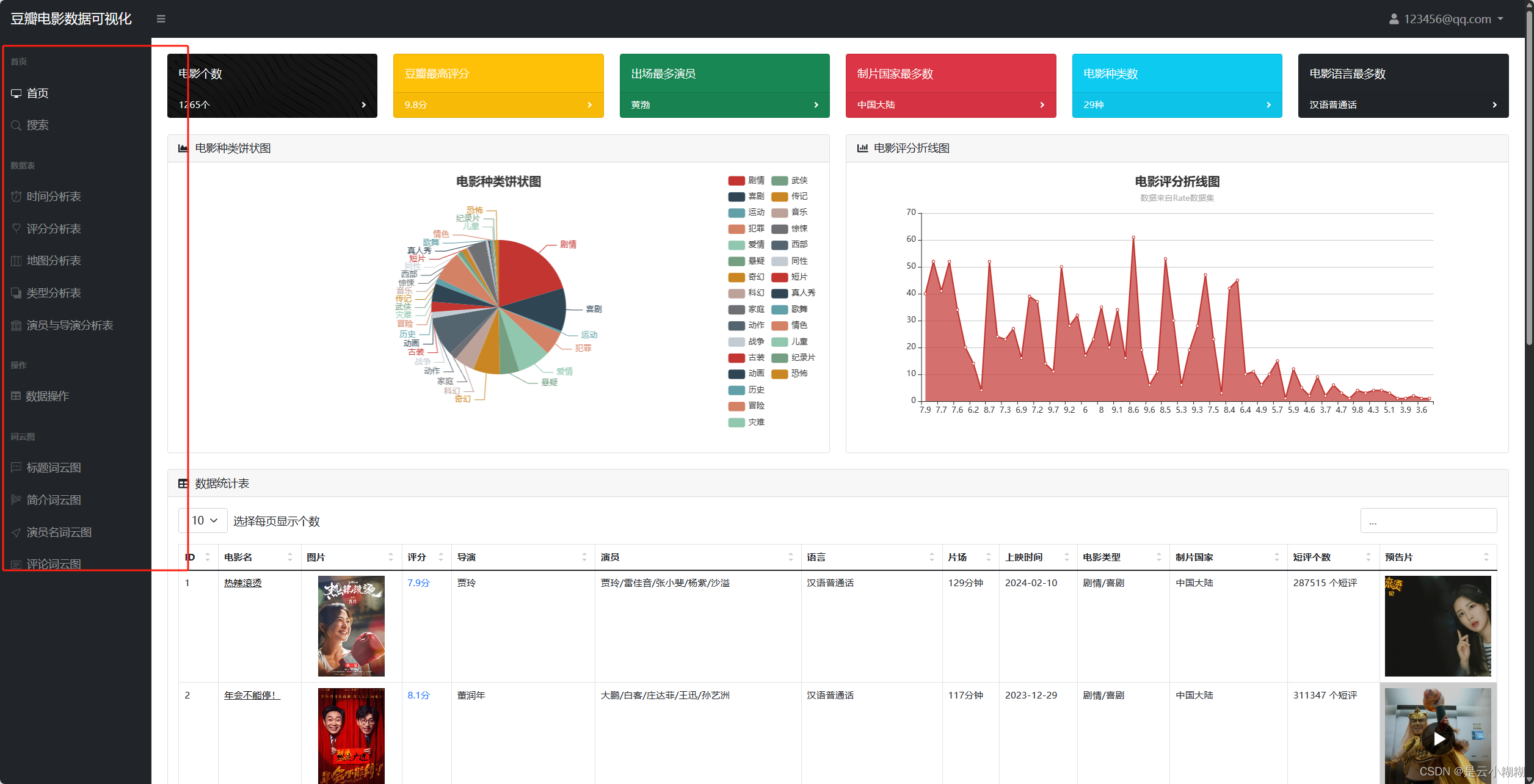
首页可视化:
信息检索:
数据管理:
数据可视化:
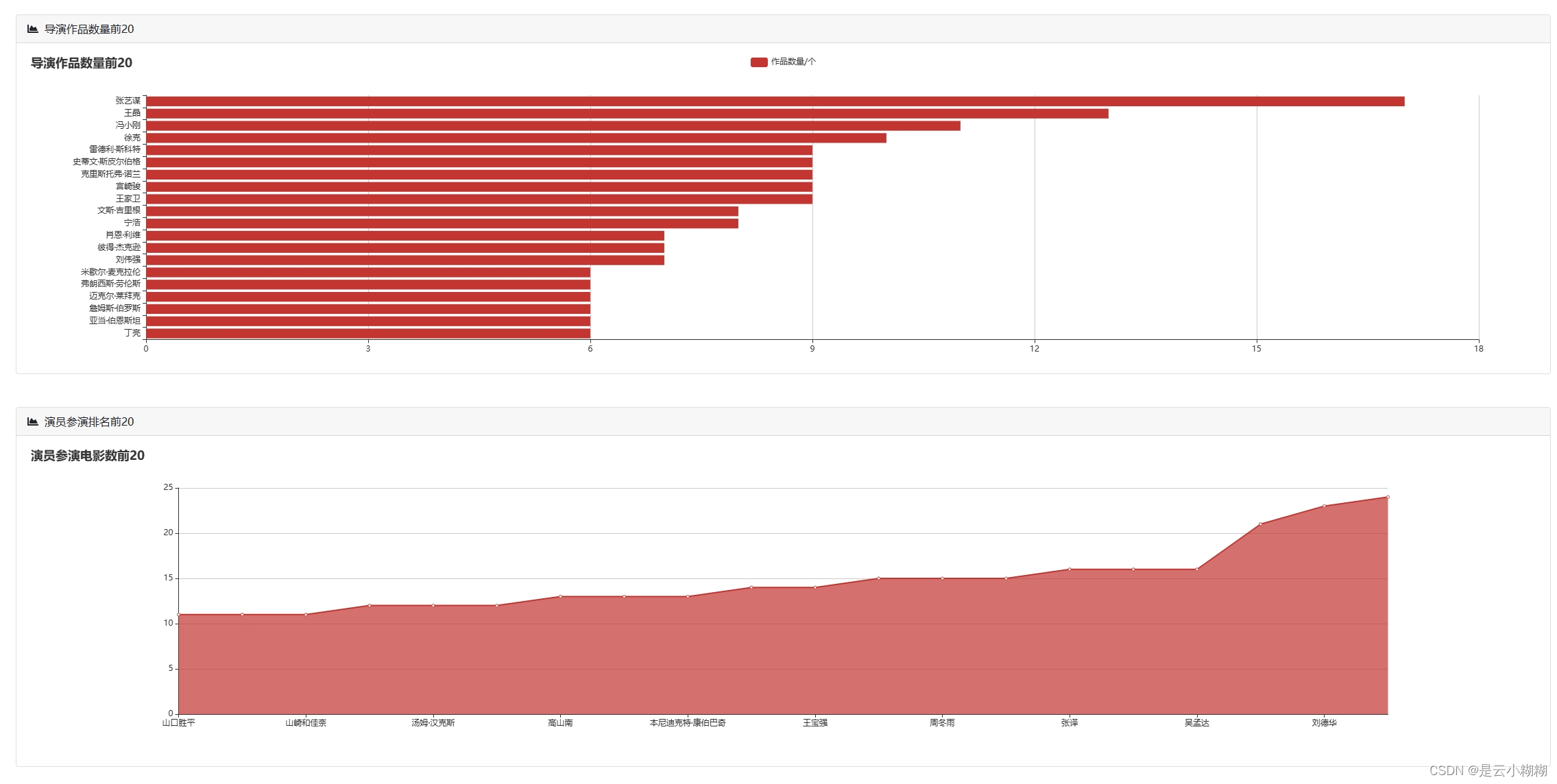
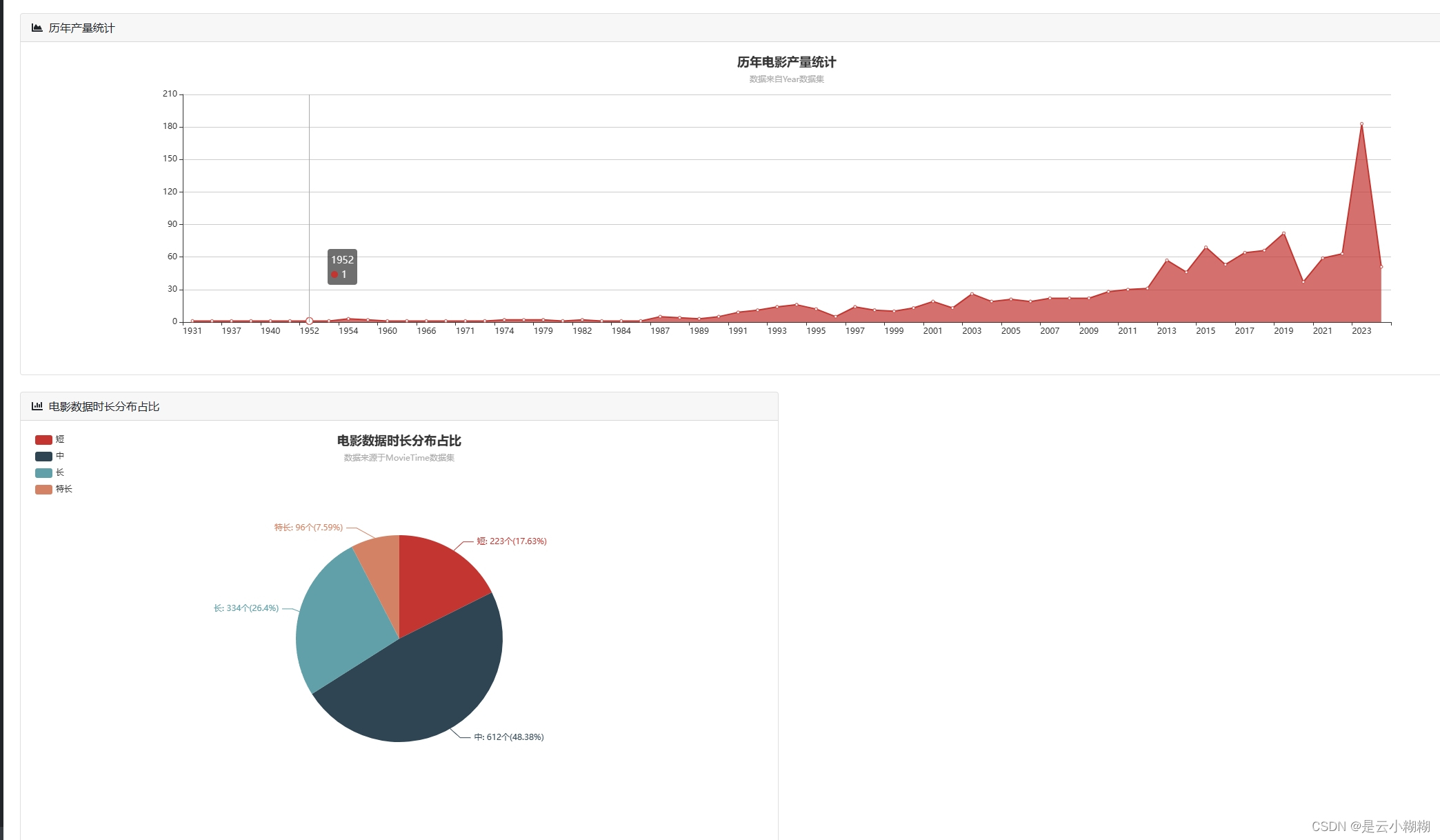
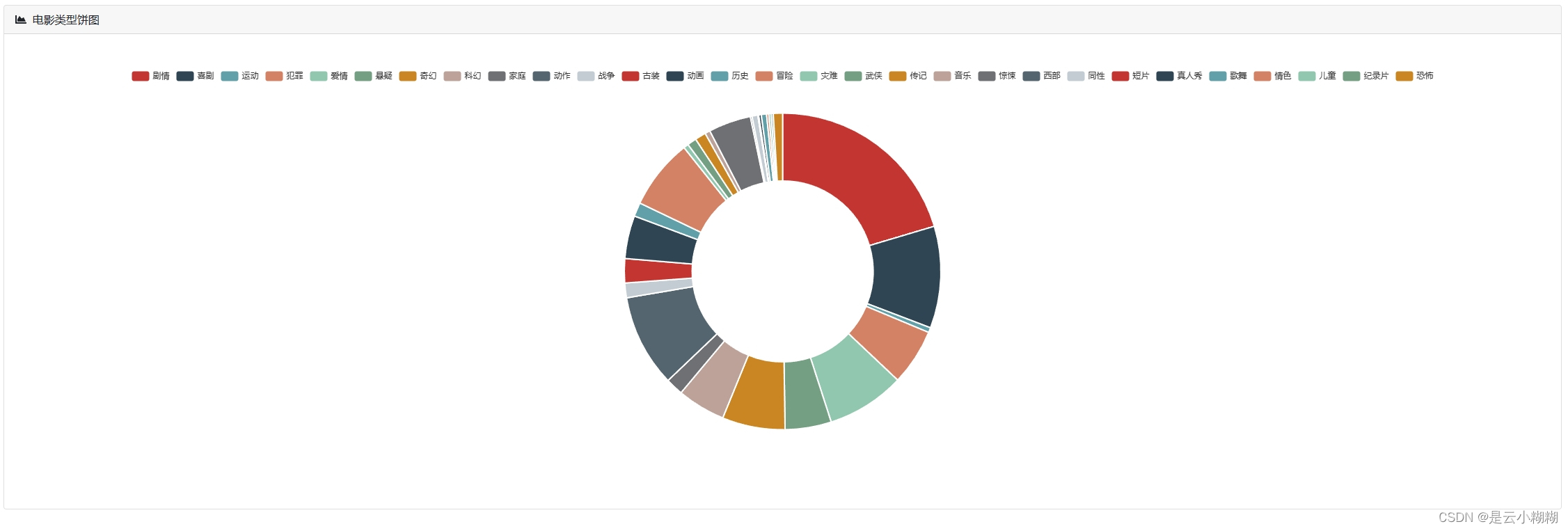
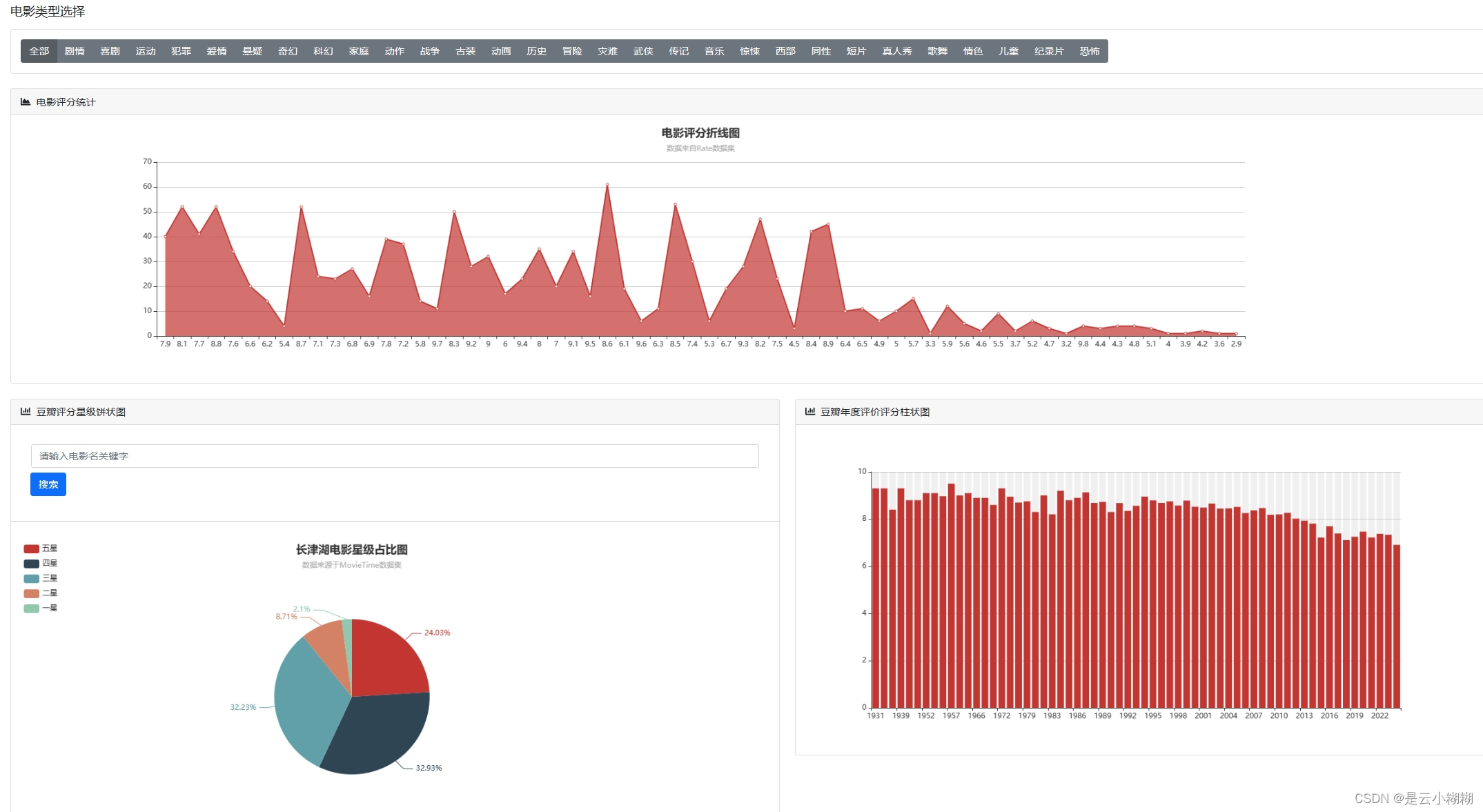
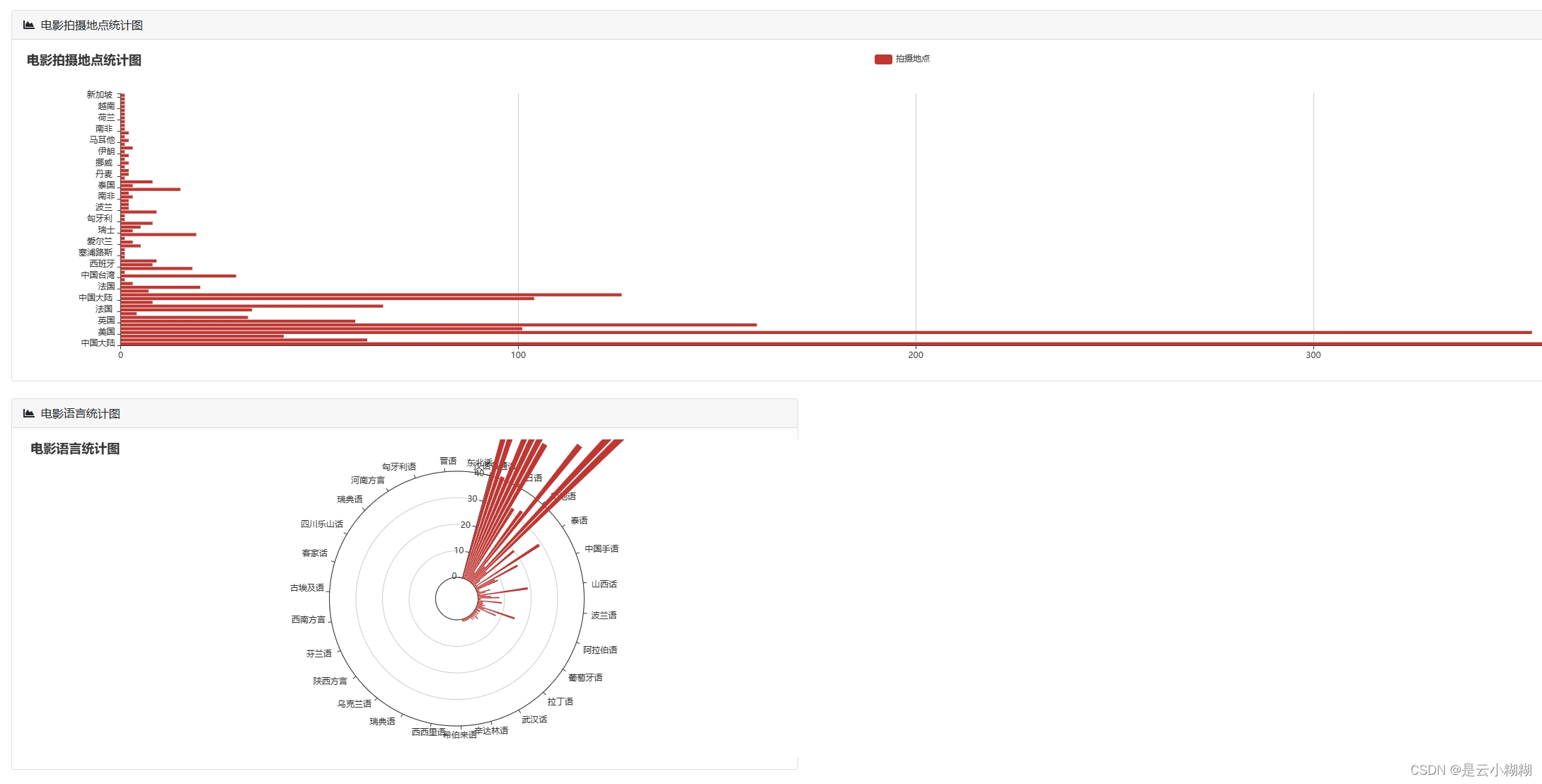
词云分析:


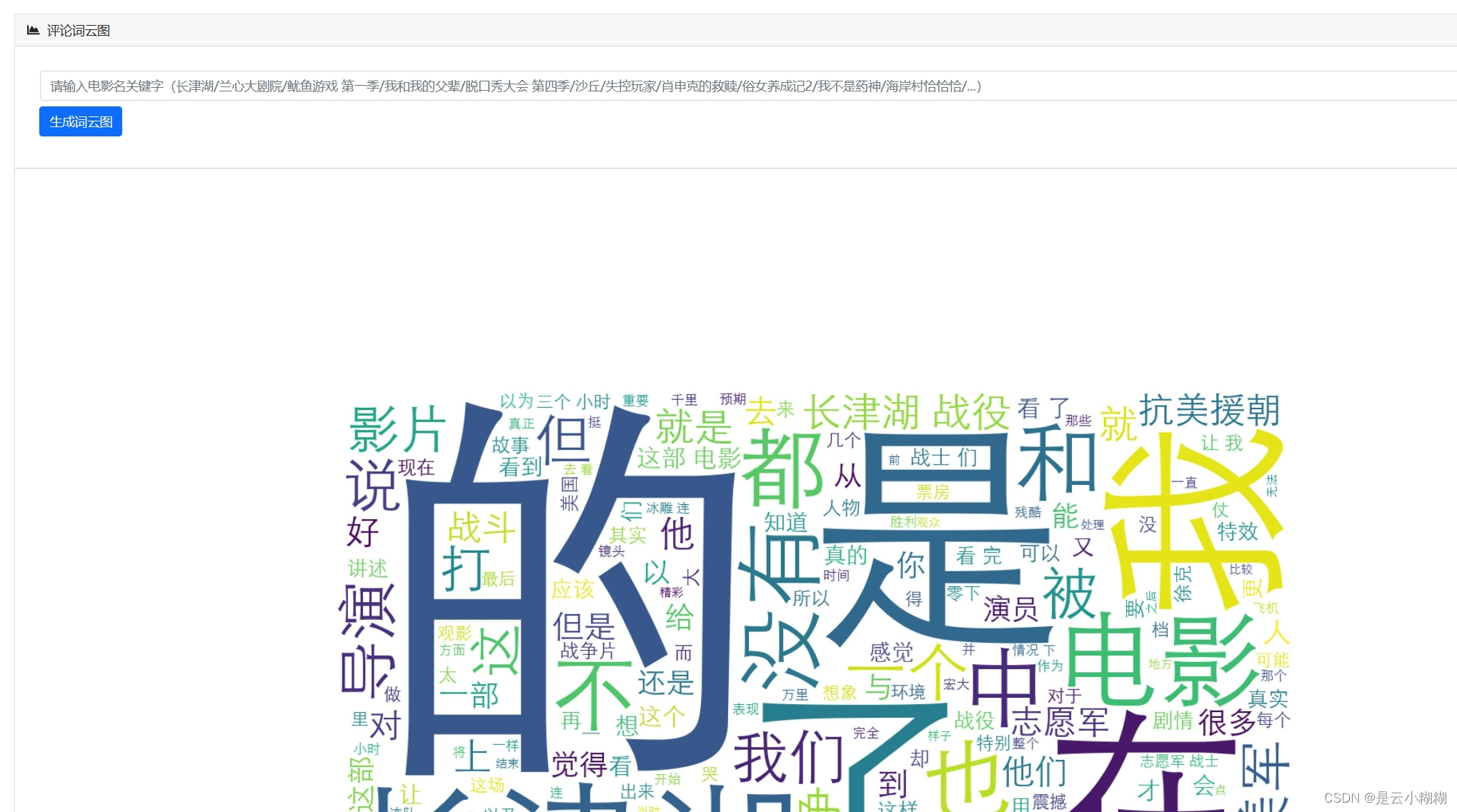
源码获取
源码、安装教程文档、项目简介文档以及其它相关文档已经上传到是云猿实战官网,可以通过下面官网进行获取项目!


















 302
302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









