






关于mongodb的学习
下载完mongodb后配置完环境变量一切准备就绪后
在所创建的目录下 cmd后输入mongod启动数据库

之后再cmd一次
输入mongo打开数据库

基础指令:
查看所有数据库show dbs

创建数据库 use xxx xxx指数据库名
创建后若创建的数据库内没有数据show dbs 是显示不出来的
这时候需要插入数据
db.xxx.insert({“name”:“www”})

删除数据库
先切换想要删除的数据库use xxx
再执行删除指令db.dropDatabase()

创建集合 先进入选择的数据库ues xxx
执行db.createCollection(“ttt”)
创建了ttt的集合在xxx数据内
可设置参数
db.createCollection(“ttt”, { capped : true, autoIndexId : true, size :
6142800, max : 10000 } )
capped:如果为 true,则创建固定集合。固定集合是指有着固定大小的集合,当达到最大值时,它会自动覆盖最早的文档。
当该值为 true 时,必须指定 size 参数。
autoIndexId:如为 true,自动在 _id 字段创建索引。默认为 false。
size:为固定集合指定一个最大值,即字节数。
如果 capped 为 true,也需要指定该字段。
max:指定固定集合中包含文档的最大数量。
show collections查看已有集合


一般直接插入文档即:db.xxx.insert({“name”:“www”})就直接创建了集合
删除集合 先进入所需要删除集合的数据库use xxx
再执行db.集合名.drop()

插入文档进入数据库use xxx
后执行db.集合名.insert(document)或db.集合名.save(document)语句
save():如果 _id 主键存在则更新数据,如果不存在就插入数据。该方法新版本中已废弃,可以使用 db.collection.insertOne() 或 db.collection.replaceOne() 来代替。
insert(): 若插入的数据主键已经存在,则会抛 org.springframework.dao.DuplicateKeyException 异常,提示主键重复,不保存当前数据
db.collection.insertOne()用法 :
db.collection.insertOne(
,
{
writeConcern:
}
)
db.collection.insertMany() 用法:
db.collection.insertMany(
[ <document 1> , <document 2>, … ],
{
writeConcern: ,
ordered:
}
)
document:要写入的文档。
writeConcern:写入策略,默认为 1,即要求确认写操作,0 是不要求。
ordered:指定是否按顺序写入,默认 true,按顺序写入。
db.collection.insertOne()与db.collection.insertMany() 的区别:一个为插入一个新文档一个为插入多个文档

更新文档 先进入数据库Ues xxx
在执行db.collection.update(
,
,
{
upsert: ,
multi: ,
writeConcern:
}
)
query : update的查询条件,类似sql update查询内where后面的。
update : update的对象和一些更新的操作符(如
,
,
,inc…)等,也可以理解为sql update查询内set后面的
upsert : 可选,这个参数的意思是,如果不存在update的记录,是否插入objNew,true为插入,默认是false,不插入。
multi : 可选,mongodb 默认是false,只更新找到的第一条记录,如果这个参数为true,就把按条件查出来多条记录全部更新。
writeConcern :可选,抛出异常的级别。

删除文档 先进入所选数据库use xxx
再执行db.col.remove(数据)
2.6版本后:
db.collection.remove(
,
{
justOne: ,
writeConcern:
}
)
query :(可选)删除的文档的条件。
justOne : (可选)如果设为 true 或 1,则只删除一个文档,如果不设置该参数,或使用默认值 false,则删除所有匹配条件的文档。
writeConcern :(可选)抛出异常的级别
实例:

注意:如果是创建的固定集合的话,是无法使用remove做改变
固定集合是指带指定参数的
例:

查询文档 进入所选数据库use xxx
执行 db.集合名.find(可带参数查询)为空即查询所有文档
如果你需要以易读的方式来读取数据,可以使用 pretty() 方法
db.集合名.find().pretty()
也可以在find()做数据筛选即给查询数据限制条件 像SQL语句中的where
by是等于 $lt是小于 $lte是小于等于 $gt是大于 $gte是大于等于 $ne是不等于

还可以复合条件
MongoDB AND 条件
MongoDB 的 find() 方法可以传入多个键(key),每个键(key)以逗号隔开,即常规 SQL 的 AND 条件。
db.tea.find({key1:value1, key2:value2}).pretty()
MongoDB OR 条件
db.tea.find({$or: [{key1: value1}, {key2:value2}]}).pretty()
上句表达的意思是 在tea集合中查询key1为value1或者key2为value2得文档
and与or联合使用
db.tea.find({“age”: {$gt:23}, $or: [{“name”: “ni”},{“age”: 25}]}).pretty()

$type操作符
可查询文档中符合类型得匹配操作

实例

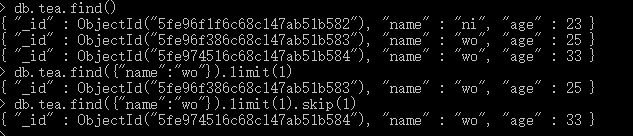
MongoDB Limit() 方法
即查询中限制查询结果得条数
db.集合名.find().limit(所需条数)

MongoDB Skip() 方法
我们除了可以使用limit()方法来读取指定数量的数据外,还可以使用skip()方法来跳过指定数量的数据,skip方法同样接受一个数字参数作为跳过的记录条数。
db.集合名.find().limit(所需条数).skip(跳转到第几条) skip()默认数值为0
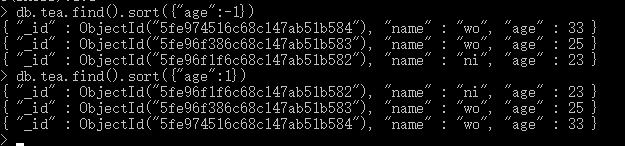
MongoDB sort() 方法
在 MongoDB 中使用 sort() 方法对数据进行排序,sort() 方法可以通过参数指定排序的字段,并使用 1 和 -1 来指定排序的方式,其中 1 为升序排列,而 -1 是用于降序排列
db.集合名.find().sort({KEY:1})
MongoDB 索引
索引通常能够极大的提高查询的效率,如果没有索引,MongoDB在读取数据时必须扫描集合中的每个文件并选取那些符合查询条件的记录。
这种扫描全集合的查询效率是非常低的,特别在处理大量的数据时,查询可以要花费几十秒甚至几分钟,这对网站的性能是非常致命的。
索引是特殊的数据结构,索引存储在一个易于遍历读取的数据集合中,索引是对数据库表中一列或多列的值进行排序的一种结构
db.集合名.createIndex(keys, options)
注意在 3.0.0 版本前创建索引方法为 db.collection.ensureIndex(),之后的版本使用了 db.collection.createIndex() 方法,ensureIndex() 还能用,但只是 createIndex() 的别名。


MongoDB 聚合
MongoDB 中聚合(aggregate)主要用于处理数据(诸如统计平均值,求和等),并返回计算后的数据结果。
有点类似 SQL 语句中的 count(*)。
aggregate() 方法
db.集合名.aggregate(AGGREGATE_OPERATION)
















 1517
1517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









