







(已做)1、求出1 / 1 + 1 / 3 + 1 / 5……+1 / 99的和 (1分之一+1分之三+1分支5…)
方法1:
sum = 0
for s in range(1,101,2):
sum += 1/s
print(sum)

方法2:
i=1
sum=0
while i<=99:
sum+=1/i
i+=2
print(sum)

方法3:
list1 = [1/x for x in range(1, 100, 2)]
print(sum(list1))

(已做)2、用循环语句,计算2 - 10之间整数的循环相乘的值 (2345…10)
方法1:
n=2
x=1
while n<=5:
x*=n #x=x*n
print(x)
n+=1
print(x)

方法2:
sum=1
for i in range(2,11):
sum*=i #sum=sum*i
# print(sum)
print(sum)

方法3:
a=1
b=1
while a<10:
a+=1 #a=a+1
b*=a #b=b*a
print(b)

方法4:
sum=2
for i in range(3,11):
sum*=i #sum=sum*i
print(sum)
print(sum)

方法4:
sum = 1
n = int(input("Please input number :"))
for i in range(1,n+1):
sum*=i
print(sum )

(已做)3、用for循环打印九九乘法表

\t制表符
\n 换行符
end=’ ’ 不换行
\t :表示空4个字符,类似于文档中的缩进功能,相当于按一个Tab键。
\n :表示换行,相当于按一个 回车键
\n\t : 表示换行的同时空4个字符。
方法1:
for i in range(1,10):
for j in range(1,i+1):
print(‘%d*%d=%d’%(j,i,j*i),end=‘\t’)
print(‘’)

方法2:
for x in range(1, 10):
for y in range(1, x + 1):
print(f"{y} x {x} = {x * y}\t", end=“”)
print()

方法3:
for i in range(1, 10):
for j in range(1, i + 1):
print("{}x{}={}\t".format(j,i,i*j), end='')
print()

方法4:
控制行数
#控制行数
for i in range(1,10):
#控制数量
for j in range(1,i+1):
print(f'{i}x{j}={i*j}',end='\t')
print( ```)

拓展:
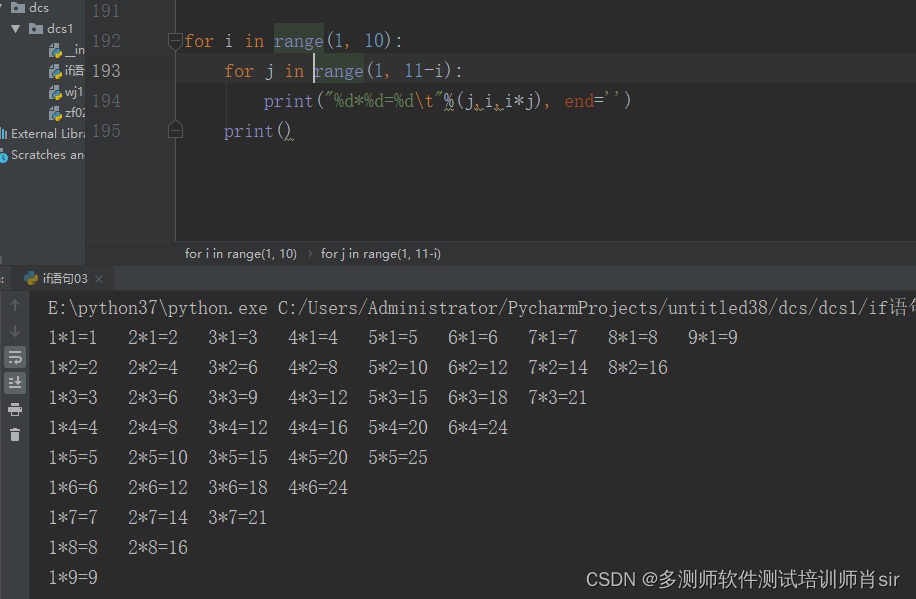
案例1
for i in range(1, 10):
for j in range(1, 11-i):
print("%d*%d=%d\t"%(j,i,i*j), end='')
print()
(已做)4、求每个字符串中字符出现的个数如:helloworld
方法1:
s=‘hellworld’
#print(set(s)) #通过集合去重
for i in set(s):
print(i,s.count(i))
方法2:
a=‘helloworld’
c={} #字典中的键是不重复
for i in a :
c[i]=a.count(i)
print©
方法3:
str1 = ‘helloworld’
s = {}
for i in str1:
if i in s:
s[i] += 1
else:
s[i] = 1
print(s)
方法4:
s=‘helloworld’
print({i:s.count(i) for i in s})
(已做)5、实现把字符串str = "duoceshi"中任意字母变为大写(通过输入语句来实现)
方法1:
str=‘duoceshi’
a=input(‘输入任意字母’)
for i in a:
s=i.upper()
str=str.replace(a,s)
print(str)
方法2:
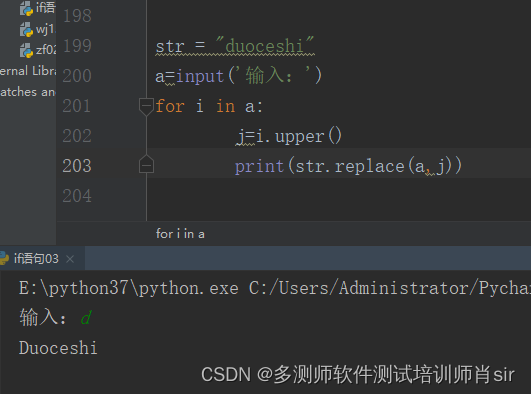
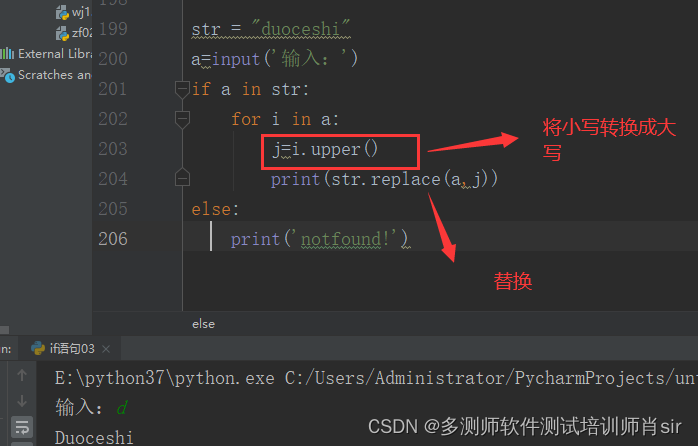
str = "duoceshi"
a=input('输入:')
if a in str:
for i in a:
j=i.upper()
print(str.replace(a,j))
else:
print('notfound!')
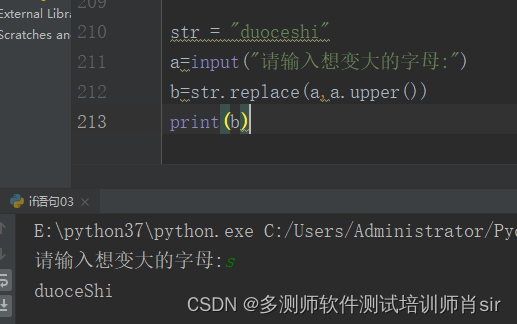
方法3:
str = "duoceshi"
a=input("请输入想变大的字母:")
b=str.replace(a,a.upper())
print(b)
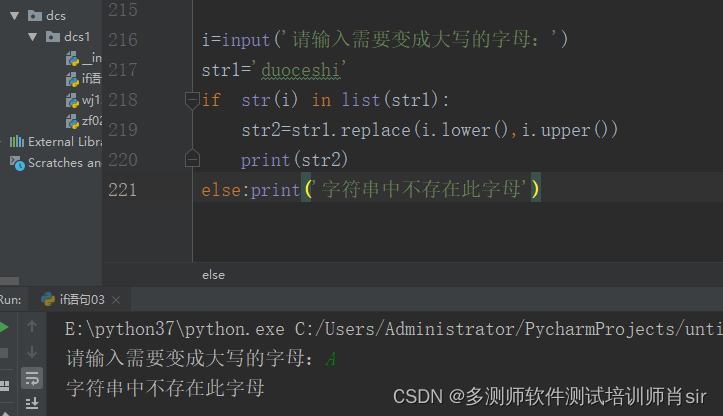
方法4:
i=input('请输入需要变成大写的字母:')
str1='duoceshi'
if str(i) in list(str1):
str2=str1.replace(i.lower(),i.upper())
print(str2)
else:print('字符串中不存在此字母')
方法5:
str = "duoceshi"
name=input("请输入变大字母:")
for i in list(str):
if name==i:
print(str.replace(i,str[str.index(i)].upper()),end="")
方法6:
```python
s='duoceshi'
a = input('请输入要变为大写的字母:')
if a not in s:
print('请输入正确的字母:')
else:
for i in a:
a2=i.upper()
s2=s.replace(a,a2)
print(s2)
方法6:
str = "duoceshi"
a = input("请输入字母:")
while a in str:
str = str[:str.find(a)] + a.upper() + str[str.find(a) + 1:]
print(str)

6、分别打印100以内的所有偶数和奇数并存入不同的列表当中
方法1:
list2 = [x for x in range(1, 101, 2)]
list3 = [y for y in range(2, 101, 2)]
print(list2)
print(list3)

方法2:
a=list(range(1,100,2))
b=list(range(0,100,2))
print(a)
print(b)

方法3:
a=[]
b=[]
for i in range(1,101,2):
a.append(i)
for j in range(2,101,2):
b.append(j)
print(a)

方法4:
listq=[]
listo=[]
for x in range(1,101):
if x%2==0:
listo.append(x)
else:
listq.append(x)
print("奇数的集合为:",listq)
print("偶数的集合为:",listo)

方法5:
list1 = []
list2 = []
a = 1
while a < 101:
if a % 2 == 0:
list1.append(a)
else:
list2.append(a)
a += 1
print(list1)
print(list2)

7、请写一段Python代码实现删除一个list = [1, 3, 6, 9, 1, 8]# 里面的重复元素(用多种方法)
方法1:
list = [1, 3, 6, 9, 1, 8]
s=[]
for i in list:
if i not in s:
s.append(i)
print(s)

方法2 : 利用字典的唯一性去重
list1= [1, 3, 6, 9, 1, 8]
print(list(dict.fromkeys(list1).keys()))
备注:fromkeys()方法是用于创建一个新字典,
lis = [1, 3, 6, 9, 1, 8]
dict={}
b=dict.fromkeys(lis)
a=b.keys()
print(list(a))

方法3:利用set集合去重
list1= [1, 3, 6, 9, 1, 8]
k=set(list1)
print(k)

方法4:利用count方法统计并删除
lis = [1, 3, 6, 9, 1, 8]
for i in lis:
if lis.count(i)>1:
lis.remove(i)
print(lis) #[3, 6, 9, 1, 8]

方法5:
list1 = [1, 3, 6, 9, 1, 8]
list2 = []
for i in list1:
if list2.__contains__(i):
continue
else:
list2.append(i)
print(list2)

8、将字符串类似:“k:1|k3:2|k2:9” 处理成key:value或json格式,比如{“k”: “1”, “k3”: “2”}
方法1:
str1="k:1|k1:2|k2:3|k3:4"
list1=str1.split("|")
print(list1) #['k:1', 'k1:2', 'k2:3', 'k3:4']
d=dict()
for i in list1:
c=i.split(':')
print(c)
d[c[0]]=c[1]
print(d) #{'k': '1', 'k1': '2', 'k2': '3', 'k3': '4'}

方法2:zd={}
for i in a:
i=i.split(‘:’)
zd.setdefault(i[0],i[1])
print(zd)

方法3:
str="k:1|k3:2|k2:9"
list1=str.split("|")
dict1={}
for k in list1:
key,value=k.split(":")
dict1[key]=value
print(dict1)

方法4:
str1="k:1|k1:2|k2:3|k3:4"
list1=str1.split("|")
print(list1) #['k:1', 'k1:2', 'k2:3', 'k3:4']
d=dict()
for i in list1:
key=i.split(":")[0]#
value=eval(i.split(":")[1])
d[key]=value
print(d)

9、把字符串user_controller转换为驼峰命名UserController大驼峰在java用作变量命名(前英文为大写后英文为小写)
小驼峰:作为变量命名
方法1:
a='user_controller'
s,y=a.split("_")
b=a.split('_')
print(b) #['user', 'controller']
print(b[0].title()+b[1].title()) #UserController

方法2:
a='user_controller'
s,y=a.split("_")
b=a.split('_')
print(b) #['user', 'controller']
print(b[0].capitalize()+b[1].capitalize()) #UserController

方法3:
str1='user_controller'
s=str1.split('_')
m=""
for i in s:
x=i.capitalize()
m+=x
print(m)

方法4:
str='user_controller'
str1=str.title().split('_')
print(''.join(str1))
10、给一组无规律的数据从大到小或从小到大进行排序如:list = [2, 6, 9, 10, 18, 15, 1]
方法1: sort 升序
list = [2, 6, 9,10, 18, 15, 1]
list.sort()
print(list)

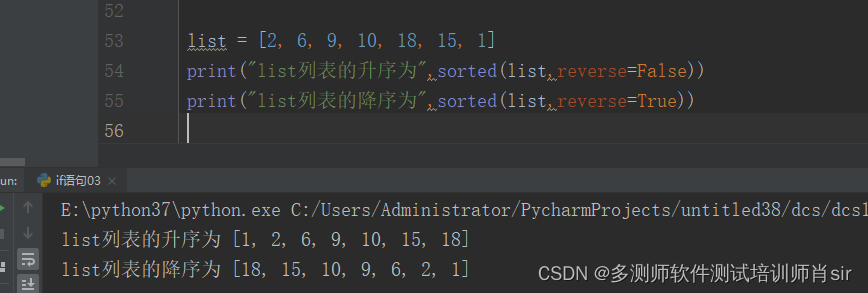
方法2:
list = [2, 6, 9, 10, 18, 15, 1]
print("list列表的升序为",sorted(list,reverse=False))
print("list列表的降序为",sorted(list,reverse=True))
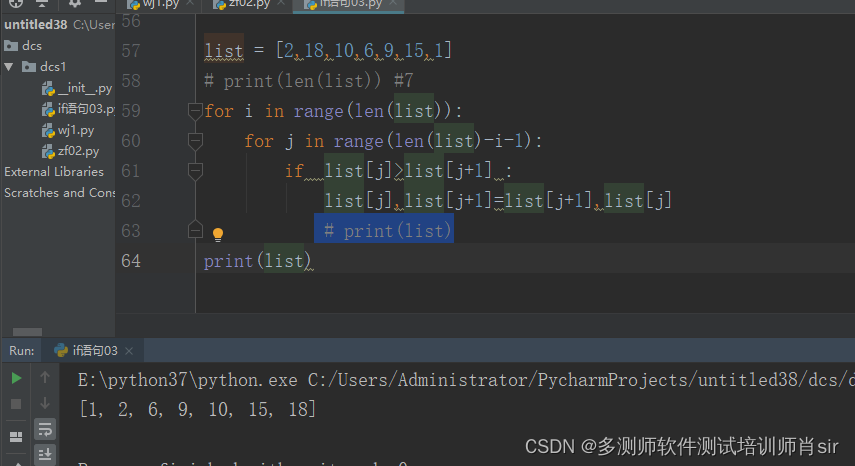
方法3:
list = [2, 6, 9,10, 18, 15, 1]
for i in range(0,len(list)-1):
for j in range(0,len(list)-1):
if list[j]>list[j+1]:
list[j],list[j+1]=list[j+1],list[j]
print(list)
方法4;
冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。
它重复地走访过要排序的数列,一次比较两个元素,
如果他们的顺序错误就把他们交换过来。
走访数列的工作是重复地进行直到没有再需要交换,
也就是说该数列已经排序完成。
这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端。
def bubbleSort(arr):
n = len(arr)
# 遍历所有数组元素
for i in range(n):
Last i elements are already in place
for j in range(0, n - i - 1):
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j]
arr = [64, 34, 25, 12, 22, 11, 90]
bubbleSort(arr)
print(“排序后的数组:”)
for i in range(len(arr)):
print(“%d” % arr[i])
11、分析以下数字的规律, 1 1 2 3 5 8 13 21 34用Python语言编程实现输出 (斐波那契数列,兔子)
案例1:
list=[1,1]
for i in range(10):
list.append(list[-1]+list[-2])
#print(list)
print(list)
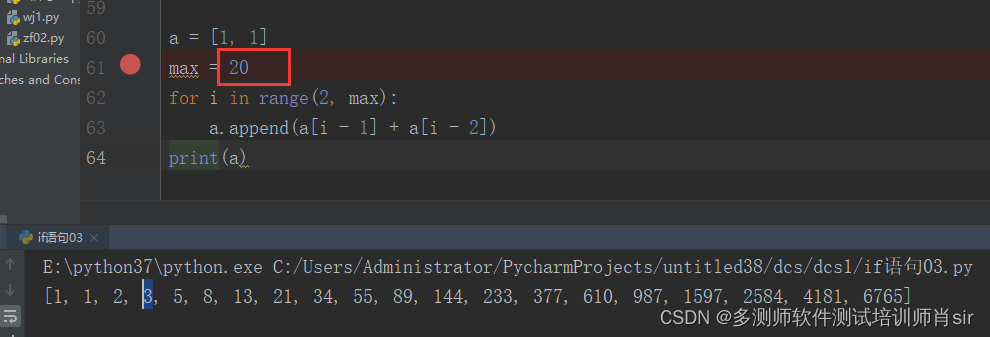
案例2:
a=[]
for i in range(10):
if i0 or i1 :
a.append(1)
else:
a.append(a[i-1]+a[i-2])
print(a)
#分析题目:根据规律 1+1=2 2+1=3 2+3=5 3+5=8…
#此为斐波那契数列 (考试题非常多次题目)
方法3:
a=0
b=1
for i in range(10):
sum=a+b
a=b
b=sum
print (a,end=",")
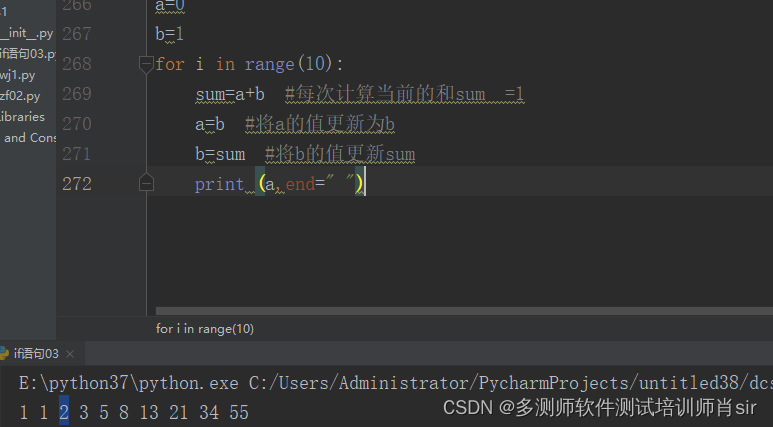
a=0
b=1
for i in range(10):
sum=a+b #每次计算当前的和sum =1
a=b #将a的值更新为b
b=sum #将b的值更新sum
print (a,end=" ")
方法四:
```python
a, b = 1, 1
print(a,end= ",")
print(b,end=",")
for _ in range(10): # 输出 7 个数字,已经打印了前两个数字
a, b = b, a + b # 更新 a 和 b 的值
#交换两个变量的值,执行中,变量a将变为原来变量b的值,而变量b将变为原来变量a+b的值
print(b,end=" ,")

方法五:
def a(n):
if (n == 1) or (n == 2):
return 1
return a(n - 1) + a(n - 2)
print(a(3))

12、如有两个list:a =[‘a’,‘b’,‘c’,‘d’,‘e’]
b =[1,2,3,4,5] 将a中的元素作为key b中的元素作为value,将a,b合并为字典
方法1:使用了zip函数
list:a =[‘a’,‘b’,‘c’,‘d’,‘e’]
b =[1,2,3,4,5]
print(dict(zip(list,list2))) #{2: ‘a’, 6: ‘b’, 9: ‘c’}

方法2:
a=[‘a’,‘b’,‘c’,‘d’,‘e’]
b=[1,2,3,4,5]
dict1={}
for i in a:
for j in b:
if a.index(i)==b.index(j):
dict1.setdefault(i,j)
print(dict1)

13、有如下列表,统计列表中的字符串出现的次数
a = [‘apple’,‘banana’,‘apple’,‘tomao’,‘orange’,‘apple’,‘banana’,‘watermeton’]
方法1:
s={}
for i in a:
s[i]=a.count(i)
print(s)
(2)
list1=[‘apple’,‘banana’,‘apple’,‘tomao’,‘orange’,‘apple’,‘banana’,‘watermeton’]
a = { i:list1.count(i) for i in list1 }
print(a)

方法2:
a = [‘apple’,‘banana’,'a
for i in set(a):
count=a.count(i)
print(i,count)
方法3:
a = [‘apple’,‘banana’,‘apple’,‘tomao’,‘orange’,‘apple’,‘banana’,‘watermeton’]
print({i:a.count(i) for i in a})
方法4:
a = [‘apple’,‘banana’,‘apple’,‘tomao’,‘orange’,‘apple’,‘banana’,‘watermeton’]
s={}
for i in a:
if i in s:
s[i]+=1
else:
s[i]=1
print(s)
方法5:
from collections import Counter
a= [‘apple’,‘banana’,‘apple’,‘tomao’,‘orange’,‘apple’,‘banana’,‘watermeton’]
count=Counter(a)
print(count)

方法6:
a = [‘apple’,‘banana’,‘apple’,‘tomao’,‘orange’,‘apple’,‘banana’,‘watermeton’]
b=set(a)
i=" "
for i in b:
print(i+“\t”+str(a.count(i)))

14、、列表推导式求出列表所有奇数并构造新列表 a =[1,2,3,4,5,6,7,8,9,10]
方法1:
list14=[1,2,3,4,5,6,7,8,9,10]
list15=[]
for i in list14:
if i%2==1:
list15.append(i)
print(list15)

(2)
a =[1,2,3,4,5,6,7,8,9,10]
b=[]
for x in a:
if x/2%1:
b.append(x)
print(b)

方法2:
f =[1,2,3,4,5,6,7,8,9,10]
print([i for i in f if i%2 != 0])
#[1, 3, 5, 7, 9]

15、有如下url地址, 要求实现截取出"?“号后面的参数, 并将参数以"key value"的键值形式保存起来, 并最终通过#get(key)的方式取出对应的value值。
#url地址如下:http://ip:port/extername/get_account_trade_record.json?page_size=20&page_index=1&user_id=203317&trade_type=0”
方法一:
a1=a.split(‘?’) #split分隔?返回列表,索引是0,1
print(a1)
a2=a1[1].split(‘&’) #根据列表中索引1,split分隔’&’
print(a2) #[‘\npage_size=20’, ‘page_index=1’, ‘user_id=203317’, ‘trade_type=0"
d={}
for i in a2:
k,v=i.split(’=‘)
d[k]=v
print(d.get(‘user_id’))
(2)
str1 = ‘http://ip:port/extername/get_account_trade_record.json?page_size=20&page_index=1&user_id=203317&trade_type=0’
str2 = str1.split(’?‘)
str3 = str2[1].split(’&‘)
dict1 = {}
for i in str3:
dict1.setdefault(i.split(’=‘)[0], i.split(’=')[1])
print(dict1)

2、
url = “http://ip:port/extername/get_account_trade_record.json?page_size=20&page_index=1&user_id=203317&trade_type=0”
a = url.find(‘?’)
str2 = url[a + 1:]
list2 = str2.split(‘&’)
dict1 = {}
for kv in list2:
kv = kv.split(‘=’)
key = kv[0]
value = kv[1]
dict1[key] = value
print(dict1)
list3 = dict1.get(‘page_size’, ‘’)
list4 = dict1.get(‘page_index’, ‘’)
list5 = dict1.get(‘user_id’, ‘’)
list6 = dict1.get(‘trade_type’, ‘’)
print(‘page_size’ + list3)
print(‘page_index’ + list4)
print(‘user_id’ + list5)
print(‘trade_type’ + list6)

案例:
from urllib.parse import parse_qs, urlparse
url = “http://ip:port/extername/get_account_trade_record.json?page_size=20&page_index=1&user_id=203317&trade_type=0”
parsed_url = urlparse(url)
params = parse_qs(parsed_url.query)
params_dict = {key: values[0] for key, values in params.items()}
print(params_dict)

方法4:
def dict0():
urla=“http://ip:port/extername/get_account_trade_record.json?page_size=20&page_index=1&user_id=203317&trade_type=0”
a=urla.split(“?”)[1]
dict1={}
list1=a.split(“&”)
for x in list1:
k=x.split(“=”)
dict1.setdefault(k[0],k[1])
return(dict1)
dict0()
def g(a):
dict2=dict0()
print(dict2.get(a))
g(‘page_size’)

方法5:
url = “http://ip:port/extername/get_account_trade_record.json?page_size=20&page_index=1&user_id=203317&trade_type=0”
a=url.find(‘?’)
list1=(url[a+1:].split(‘&’))
c=input(‘输入要取值的key:’)
print(list1)
dict1={}
for i in list1:
q,w=i.split(‘=’)
dict1[q]=w
print(dict1.get©)

















 793
793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











