







- 环境介绍
- 非Kerberos环境
- CM和CDH均为:5.15
- 准备环境
- Spark2Streaming示例
- pom.xml依赖
# 使用maven创建scala语言的spark2demo工程
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-spark2_2.11</artifactId>
<version>1.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.6.0-cdh5.14.2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>2.2.0.cloudera2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.2.0.cloudera2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.11</artifactId>
<version>2.2.0.cloudera2</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.11</artifactId>
<version>2.2.0.cloudera2</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
- properties配置文件
# 在resources下创建0294.properties配置文件
kafka.brokers=cdh02.fayson.com:9092,cdh03.fayson.com:9092,cdh04.fayson.com:9092
kafka.topics=kafka_kudu_topic
kudumaster.list=cdh01.fayson.com,cdh02.fayson.com,cdh03.fayson.com
- scala类
# 创建Kafka2Spark2Kudu.scala类
package com.cloudera.streaming.nokerberos
import java.io.{File, FileInputStream}
import java.util.Properties
import org.apache.commons.lang.StringUtils
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.kudu.client.CreateTableOptions
import org.apache.kudu.spark.kudu.KuduContext
import org.apache.log4j.{Level, Logger}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.types.{StringType, StructField, StructType}
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, HasOffsetRanges, KafkaUtils, LocationStrategies}
import scala.util.parsing.json.JSON
import scala.collection.JavaConverters._
object Kafka2Spark2Kudu {
Logger.getLogger("com").setLevel(Level.ERROR) //设置日志级别
var confPath: String = System.getProperty("user.dir") + File.separator + "conf/0294.properties"
/**
* 建表Schema定义
*/
val userInfoSchema = StructType(
// col name type nullable?
StructField("id", StringType , false) ::
StructField("name" , StringType, true ) ::
StructField("sex" , StringType, true ) ::
StructField("city" , StringType, true ) ::
StructField("occupation" , StringType, true ) ::
StructField("tel" , StringType, true ) ::
StructField("fixPhoneNum" , StringType, true ) ::
StructField("bankName" , StringType, true ) ::
StructField("address" , StringType, true ) ::
StructField("marriage" , StringType, true ) ::
StructField("childNum", StringType , true ) :: Nil
)
/**
* 定义一个UserInfo对象
*/
case class UserInfo (
id: String,
name: String,
sex: String,
city: String,
occupation: String,
tel: String,
fixPhoneNum: String,
bankName: String,
address: String,
marriage: String,
childNum: String
)
def main(args: Array[String]): Unit = {
//加载配置文件
val properties = new Properties()
val file = new File(confPath)
if(!file.exists()) {
System.out.println(Kafka2Spark2Kudu.getClass.getClassLoader.getResource("0294.properties"))
val in = Kafka2Spark2Kudu.getClass.getClassLoader.getResourceAsStream("0294.properties")
properties.load(in);
} else {
properties.load(new FileInputStream(confPath))
}
val brokers = properties.getProperty("kafka.brokers")
val topics = properties.getProperty("kafka.topics")
val kuduMaster = properties.getProperty("kudumaster.list")
println("kafka.brokers:" + brokers)
println("kafka.topics:" + topics)
println("kudu.master:" + kuduMaster)
if(StringUtils.isEmpty(brokers)|| StringUtils.isEmpty(topics) || StringUtils.isEmpty(kuduMaster)) {
println("未配置Kafka和KuduMaster信息")
System.exit(0)
}
val topicsSet = topics.split(",").toSet
val spark = SparkSession.builder().appName("Kafka2Spark2Kudu-nokerberos").config(new SparkConf()).getOrCreate()
val ssc = new StreamingContext(spark.sparkContext, Seconds(5)) //设置Spark时间窗口,每5s处理一次
val kafkaParams = Map[String, Object]("bootstrap.servers" -> brokers
, "auto.offset.reset" -> "latest"
, "key.deserializer" -> classOf[StringDeserializer]
, "value.deserializer" -> classOf[StringDeserializer]
, "group.id" -> properties.getProperty("group.id")
)
val dStream = KafkaUtils.createDirectStream[String, String](ssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe[String, String](topicsSet, kafkaParams))
//引入隐式
import spark.implicits._
val kuduContext = new KuduContext(kuduMaster, spark.sparkContext)
//判断表是否存在
if(!kuduContext.tableExists("user_info")) {
println("create Kudu Table :{user_info}")
val createTableOptions = new CreateTableOptions()
createTableOptions.addHashPartitions(List("id").asJava, 8).setNumReplicas(3)
kuduContext.createTable("user_info", userInfoSchema, Seq("id"), createTableOptions)
}
dStream.foreachRDD(rdd => {
//将rdd数据重新封装为Rdd[UserInfo]
val newrdd = rdd.map(line => {
val jsonObj = JSON.parseFull(line.value())
val map:Map[String,Any] = jsonObj.get.asInstanceOf[Map[String, Any]]
new UserInfo(
map.get("id").get.asInstanceOf[String],
map.get("name").get.asInstanceOf[String],
map.get("sex").get.asInstanceOf[String],
map.get("city").get.asInstanceOf[String],
map.get("occupation").get.asInstanceOf[String],
map.get("mobile_phone_num").get.asInstanceOf[String],
map.get("fix_phone_num").get.asInstanceOf[String],
map.get("bank_name").get.asInstanceOf[String],
map.get("address").get.asInstanceOf[String],
map.get("marriage").get.asInstanceOf[String],
map.get("child_num").get.asInstanceOf[String]
)
})
//将RDD转换为DataFrame
val userinfoDF = spark.sqlContext.createDataFrame(newrdd)
kuduContext.upsertRows(userinfoDF, "user_info")
})
ssc.start()
ssc.awaitTermination()
}
}
- mvn命令
# 使用mvn命令编译工程,注意由于是scala工程编译时mvn命令要加scala:compile
mvn clean scala:compile package
# 将编译好的spark2-demo-1.0-SNAPSHOT.jar包及配置文件上传至服务器
# 0294.properties配置文件内容

- 运行
# 使用spark2-submit命令向集群提交Spark2Streaming作业
spark2-submit --class com.cloudera.streaming.nokerberos.Kafka2Spark2Kudu \
--master yarn \
--deploy-mode client \
--executor-memory 2g \
--executor-cores 2 \
--driver-memory 2g \
--num-executors 2 \
spark2-demo-1.0-SNAPSHOT.jar

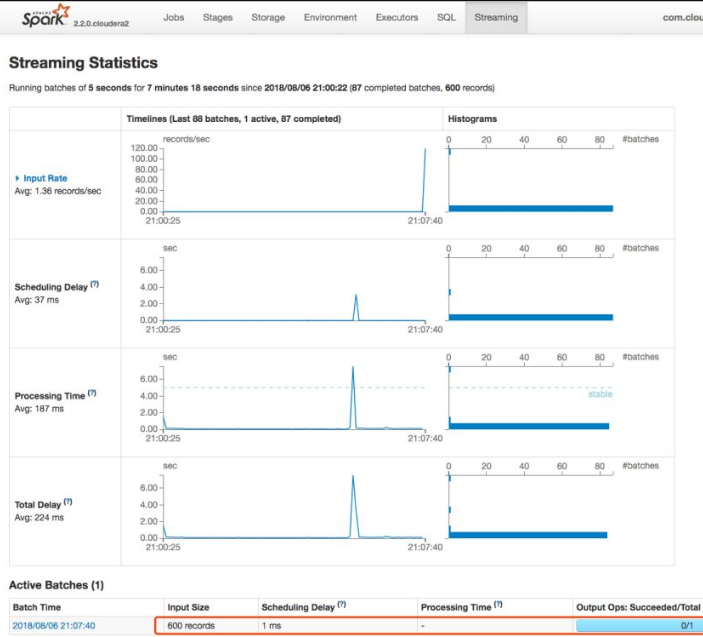

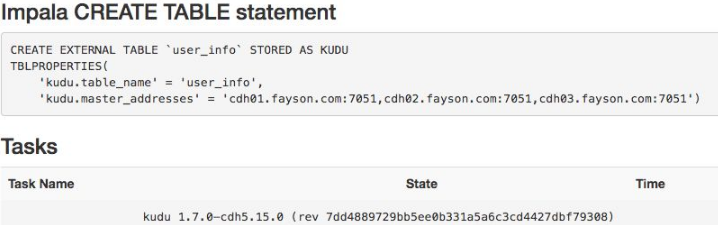
#找到Kudu向Impala的建表语句
CREATE EXTERNAL TABLE `user_info` STORED AS KUDU
TBLPROPERTIES(
'kudu.table_name' = 'user_info',
'kudu.master_addresses' = 'cdh01.fayson.com:7051,cdh02.fayson.com:7051,cdh03.fayson.com:7051')

大数据视频推荐:
CSDN
人工智能算法竞赛实战
AIops智能运维机器学习算法实战
ELK7 stack开发运维实战
PySpark机器学习从入门到精通
AIOps智能运维实战
大数据语音推荐:
ELK7 stack开发运维
企业级大数据技术应用
大数据机器学习案例之推荐系统
自然语言处理
大数据基础
人工智能:深度学习入门到精通















 3458
3458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









