







127.1 流程图
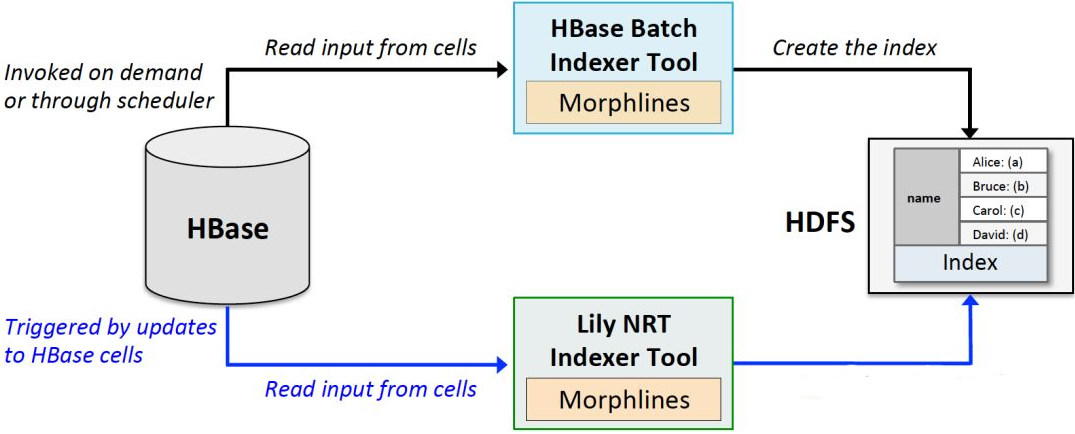
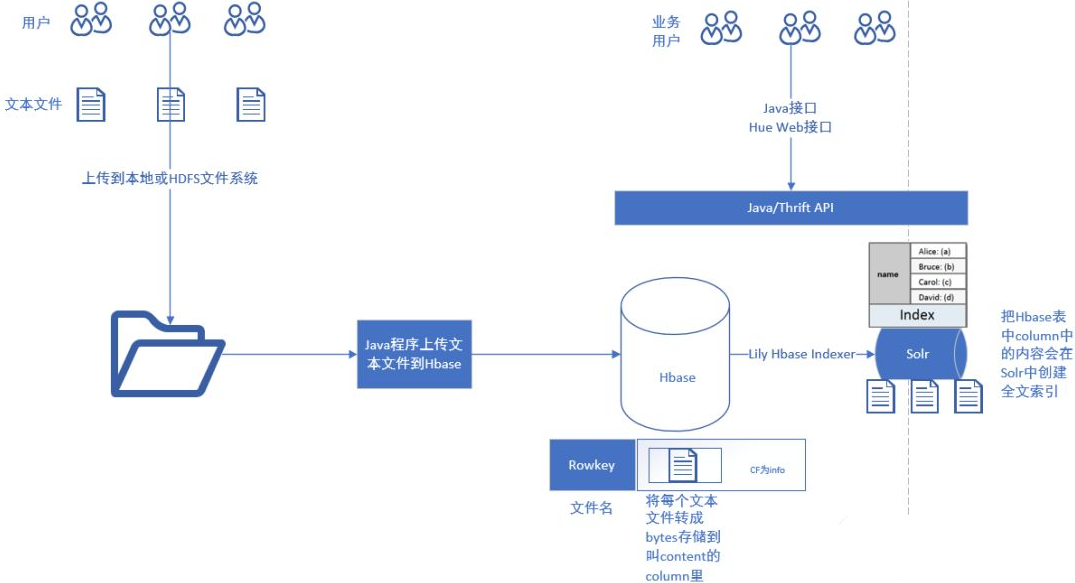
127.2 Solr中建立collection
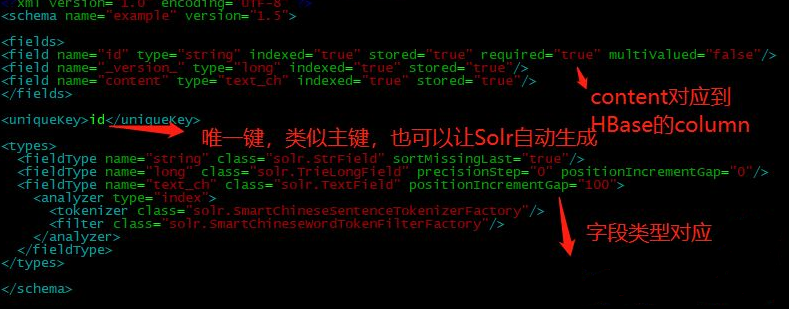
- Solr collection的schema文件建立
[root@ip-xxx-xx-x-xxx conf]# cat schema.xml
<?xml version="1.0" encoding="UTF-8" ?>
<schema name="example" version="1.5">
<fields>
<field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false"/>
<field name="_version_" type="long" indexed="true" stored="true"/>
<field name="content" type="text_ch" indexed="true" stored="true"/>
</fields>
<uniqueKey>id</uniqueKey>
<types>
<fieldType name="string" class="solr.StrField" sortMissingLast="true"/>
<fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/>
<fieldType name="text_ch" class="solr.TextField" positionIncrementGap="100">
<analyzer type="index">
<tokenizer class="solr.SmartChineseSentenceTokenizerFactory"/>
<filter class="solr.SmartChineseWordTokenFilterFactory"/>
</analyzer>
</fieldType>
</types>
</schema>

https://repository.cloudera.com/artifactory/cdh-releases-rcs/org/apache/lucene/lucene-analyzers-smartcn/4.10.3-cdh5.14.2/
- collection的脚本
ZK="ip-xxx-xx-x-xxx.ap-southeast-1.compute.internal"
COLLECTION="collection1"
BASE=`pwd`
SHARD=3
REPLICA=1
echo "create solr collection"
rm -rf tmp/*
solrctl --zk $ZK:2181/solr instancedir --generate tmp/${COLLECTION}_configs
cp conf/schema.xml tmp/${COLLECTION}_configs/conf/
solrctl --zk $ZK:2181/solr instancedir --create $COLLECTION tmp/${COLLECTION}_configs
solrctl --zk $ZK:2181/solr collection --create $COLLECTION -s $SHARD -r $REPLICA
solrctl --zk $ZK:2181/solr collection --list
# ZK:Zookeeper的某台机器的hostname
# COLLECTION:需要建立的collection名字
# SHARD:需要建立的shard的数量
# REPLICA:副本数
- 执行
[root@ip-xxx-xx-x-xxx solr-hbase]# sh create.sh
create solr collection
Uploading configs from tmp/collection1_configs/conf to ip-172-31-5-171.ap-southeast-1.compute.internal:2181/solr. This may take up to a minute.
collection1 (2)
127.3 Morphline与Lily Indexer文件
- Morphline
morphlines : [
{
id : morphline1
importCommands : ["org.kitesdk.morphline.**", "com.ngdata.**"]
commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : "textinfo:content"
outputField : "content"
type : "string"
source : value
}]
}
}
]
}
]
- Lily Indexer
<?xml version="1.0"?>
<indexer table="TextHbase" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper" mapping-type="row" >
<!-- The relative or absolute path on the local file system to the morphline configuration file. -->
<!-- Use relative path "morphlines.conf" for morphlines managed by Cloudera Manager -->
<param name="morphlineFile" value="/root/solr-hbase/conf/morphlines.conf"/>
<!-- The optional morphlineId identifies a morphline if there are multiple morphlines in morphlines.conf -->
<!-- <param name="morphlineId" value="morphline1"/> -->
</indexer>
###127.4 全文索引批量建立
- 下载中文分词的jar包
https://repository.cloudera.com/artifactory/cdh-releases-rcs/org/apache/lucene/lucene-analyzers-smartcn/4.10.3-cdh5.14.2/
- 分发到Solr和YARN服务相关的目录
[root@ip-xxx-xx-x-xxx solr-hdfs]# cp lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar /opt/cloudera/parcels/CDH/lib/hadoop-yarn
[root@ip-xxx-xx-x-xxx solr-hdfs]# cp lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
- 分发到集群
[root@ip-xxx-xx-x-xxx shell]# sh bk_cp.sh node.list /opt/cloudera/parcels/CDH/lib/hadoop-yarn/lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar /opt/cloudera/parcels/CDH/lib/hadoop-yarn
lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar
[root@ip-xxx-xx-x-xxx shell]# sh bk_cp.sh node.list /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib/lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
- 索引脚本
COLLECTION='collection1'
ZK='ip-172-31-5-38.ap-southeast-1.compute.internal'
echo 'Delete previous docs...'
solrctl collection --deletedocs $COLLECTION
echo 'Lily HBase MapReduce indexing...'
config="/etc/hadoop/conf.cloudera.yarn"
parcel="/opt/cloudera/parcels/CDH"
jar="$parcel/lib/hbase-solr/tools/hbase-indexer-mr-*-job.jar"
hbase_conf="/etc/hbase/conf/hbase-site.xml"
opts="'mapred.child.java.opts=-Xmx1024m'"
log4j="$parcel/share/doc/search*/examples/solr-nrt/log4j.properties"
zk="$ZK:2181/solr"
libjars="lib/lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar"
export HADOOP_OPTS="-Djava.security.auth.login.config=conf/jaas.conf"
hadoop --config $config jar $jar --conf $hbase_conf --libjars $libjars -D $opts --log4j $log4j --hbase-indexer-file conf/indexer-config.xml --verbose --go-live --zk-host $zk --collection $COLLECTION
- 运行
[root@ip-xxx-xx-x-xxx solr-hbase]# sh batch.sh
Delete previous docs...
Lily HBase MapReduce indexing...
0 [main] INFO org.apache.solr.common.cloud.SolrZkClient - Using default ZkCredentialsProvider
21 [main] INFO org.apache.solr.common.cloud.ConnectionManager - Waiting for client to connect to ZooKeeper
25 [main-SendThread(ip-172-31-5-38.ap-southeast-1.compute.internal:2181)] WARN org.apache.zookeeper.ClientCnxn - SASL configuration failed: javax.security.auth.login.LoginException: Zookeeper client cannot authenticate using the 'Client' section of the supplied JAAS configuration: 'conf/jaas.conf' because of a RuntimeException: java.lang.SecurityException: java.io.IOException: conf/jaas.conf (No such file or directory) Will continue connection to Zookeeper server without SASL authentication, if Zookeeper server allows it.
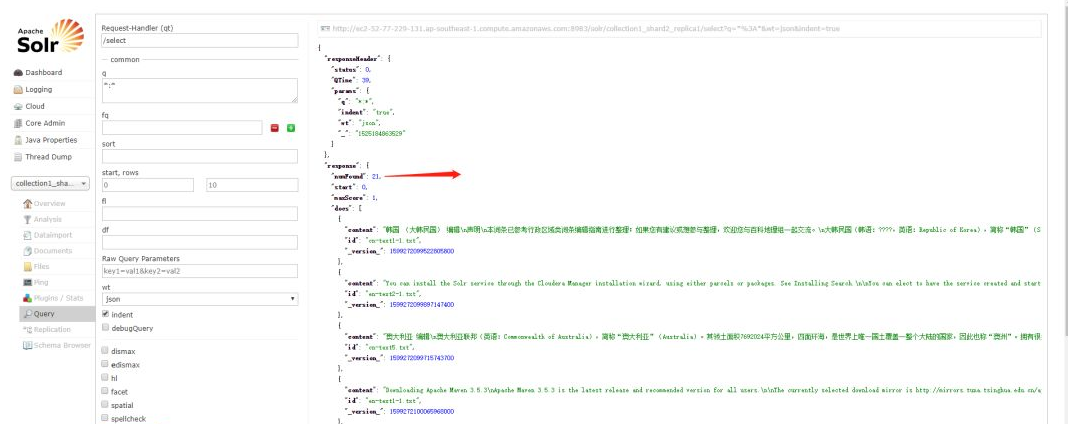
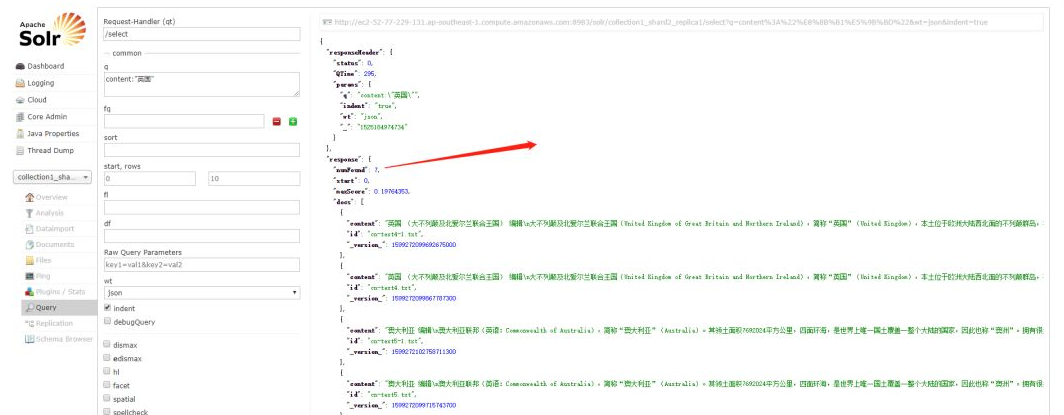
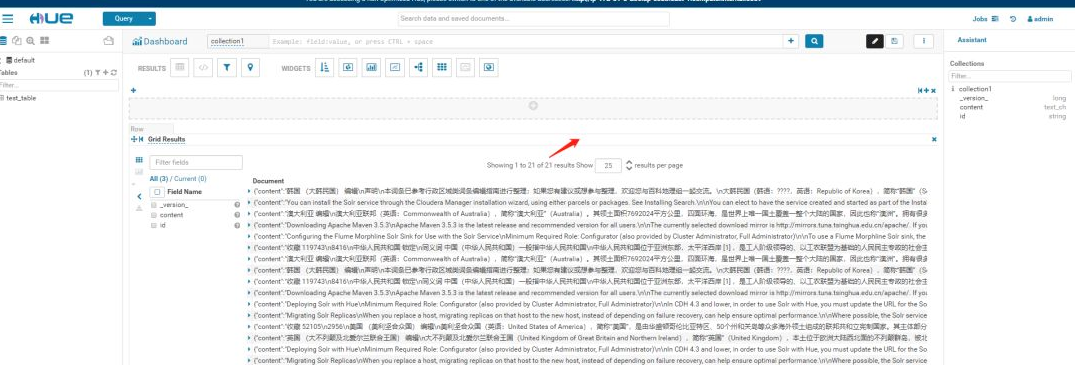
- 在Solr和Hue界面中查询


大数据视频推荐:
CSDN
人工智能算法竞赛实战
AIops智能运维机器学习算法实战
ELK7 stack开发运维实战
PySpark机器学习从入门到精通
AIOps智能运维实战
大数据语音推荐:
ELK7 stack开发运维
企业级大数据技术应用
大数据机器学习案例之推荐系统
自然语言处理
大数据基础
人工智能:深度学习入门到精通















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









