









 该研究提出了一种新的无监督方法,用于在社交媒体上进行冒犯性言论的去毒。通过结合协作分类器、注意力机制和循环一致性损失,该模型在非平行数据集上训练,旨在将冒犯性言论转化为非冒犯性言论,同时保持原始语义。实验结果显示,模型在内容保留和风格迁移准确性上优于现有方法,但在语言流畅度(PPL)方面稍逊一筹。消融实验强调了注意力机制和反向迁移的重要性。然而,该方法对隐性偏见的攻击性语言处理效果不佳。
该研究提出了一种新的无监督方法,用于在社交媒体上进行冒犯性言论的去毒。通过结合协作分类器、注意力机制和循环一致性损失,该模型在非平行数据集上训练,旨在将冒犯性言论转化为非冒犯性言论,同时保持原始语义。实验结果显示,模型在内容保留和风格迁移准确性上优于现有方法,但在语言流畅度(PPL)方面稍逊一筹。消融实验强调了注意力机制和反向迁移的重要性。然而,该方法对隐性偏见的攻击性语言处理效果不佳。
Fighting Offensive Language on Social Media with Unsupervised Text Style Transfer

会议:ACL2018
任务:言论去毒/文本风格迁移
原文:链接
Abstract
本文针对言论去毒任务(即把社交媒体上的冒犯性言论改述为非冒犯性言论),提出了一个新的方法:连接一个协作性的分类器、注意力机制和循环一致性损失,在非平行数据集上训练一个编码器、解码器框架。在Twitter和Reddit数据上的实验结果表明,本文的方法在三个量化指标中的两个方面优于最先进的文本风格迁移模型,并能够产生可靠的非攻击性迁移句子。
Motivation
由于该任务暂时不存在对应的攻击性-非攻击性平行数据集,因此,开发无监督的方法尤为重要。对于使用非平行数据集的文本风格迁移任务,存在两大挑战。(a)没有ground truth,无法使用极大似然估计来训练编码器-解码器框架;(b)迁移后的文本难以保留好原始语义。针对挑战(a),使用一个单协同分类器,来代替常用的对抗判别器;针对挑战(b),使用注意力机制结合循环一致性损失。
Main idea and Framework
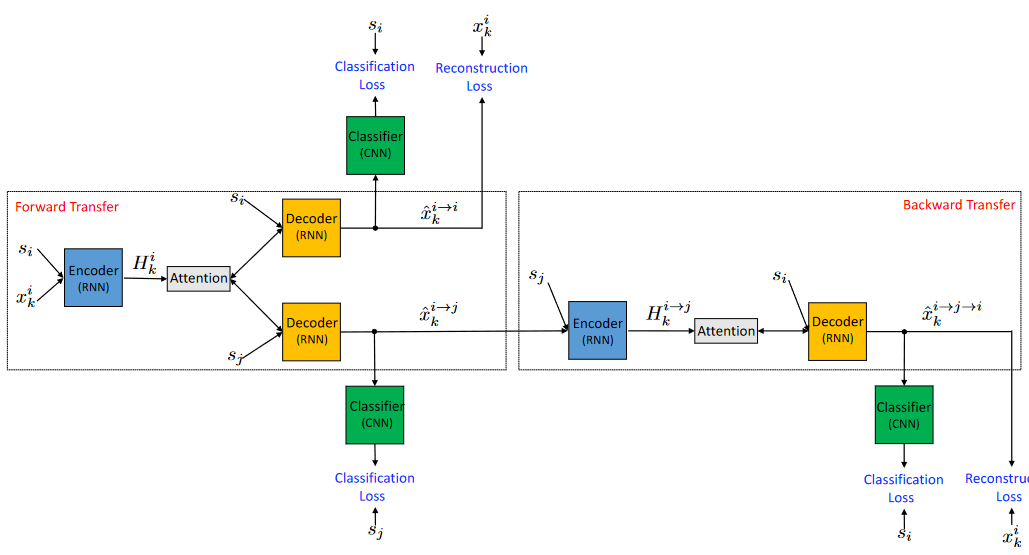
模型框架图如图所示,为了表述清楚,图中使用了多个模块来表示Encoder、Decoder、Classifier,但是实际上都只有一个。模型结构方面主要以GRU构成的编码器-解码器、CNN分类器、注意力机制组成。
记 x k i x_k^i xki为非平行语料库中具有风格 s i s_i si的第 k k k个句子。 E ( x k i , s i ) = H k i E(x_k^i,s_i)=H_k^i E(xki,si)=Hki表示编码器将原始句子 x k i x_k^i xki和初始风格 s i s_i si作为输入并输出隐藏向量 H k i H_k^i Hki。 G ( H k i , s j ) = x ^ k i → j G(H^i_k, s_j)=\hat{x}_k^{i→j} G(Hki,sj)=x^ki→j表示将隐藏向量 H k i H_k^i Hki和目标风格 s j s_j sj作为输入,并输出能够保留原始输入句子 k k k的语义且风格由 s i s_i si迁移为 s j s_j sj的句子。并且,在解码器中,隐藏向量 H k i H_k^i Hki将通过一个注意力机制来提高生成质量。
由CNN构成的分类器,以解码生成的句子作为输入,并输出在风格样式标签上的概率分布,表示为: C ( x ^ k i − > j ) = P C ( s j ∣ x ^ k i − > j ) C(\hat{x}_k^{i->j})=PC(s_j|\hat{x}_k^{i->j}) C(x^ki−>j)=PC(sj∣x^ki−>j)。
- 总的来说,模型的输入是风格为 s i s_i si的句子 x k i x_k^i xki,通过Encoder-Decoder结构生成两种风格的句子 x ^ k i → i \hat{x}_k^{i→i} x^ki→i和 x ^ k i → j \hat{x}_k^{i→j} x^ki→j,然后通过一个风格分类器计算它们的分类损失,且对于 x ^ k i → i \hat{x}_k^{i→i} x^ki→i,以自编码方式计算器重构损失,对于 x ^ k i → j \hat{x}_k^{i→j} x^ki→j,使用相同的结构再次进行风格转换,即反向迁移,生成 x ^ k i → j − > i \hat{x}_k^{i→j->i} x^ki→j−>i,计算其重构损失。
Details
Forward Transfer
-
Reconstruction Loss.
当 i = j i=j i=j时,可以视编码器为一个自编码器,使用交叉熵损失。
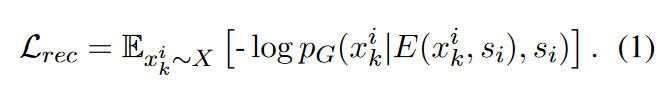
-
Classification Loss.
对于编码器-解码器来说,这个损失提供了关于当前生成器将语句转换为新风格的有效性的反馈。对于分类器,它从生成的数据中提供一个额外的训练信号,使分类器能够在半监督的状态下进行训练。
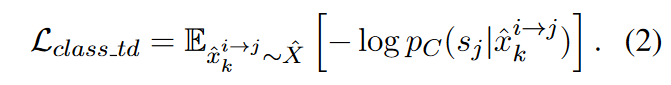
-
Classification Loss - Original Data.
为了保证分类的准确率,使用监督学习的方式在原始数据集上训练一个分类器。
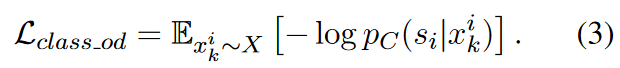
Backward Transfer
-
Reconstruction Loss.
即循环一致性(cycle consistency)损失,通过将迁移后的句子再次迁移回原风格,这相当于是对生成句子添加隐式的限制以提高内容保存度。
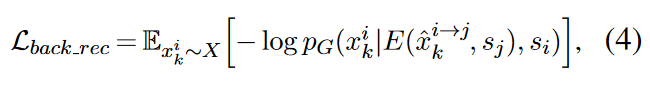
-
Classification Loss.
为保证反向迁移,使用正确的风格标签计算其交叉熵损失。
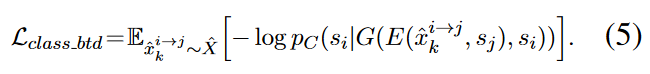
- 最终的参数由最小化上述损失的联合损失得到。
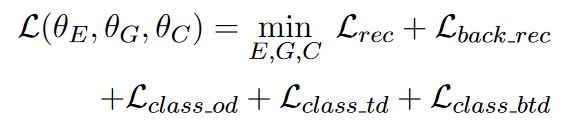
Experiments
- Contrast experiment and Analysis
baseline:Shen et al. Style transfer from non-parallel text by cross-alignment.NIPS2017
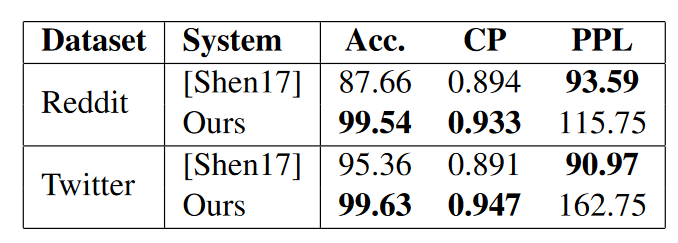
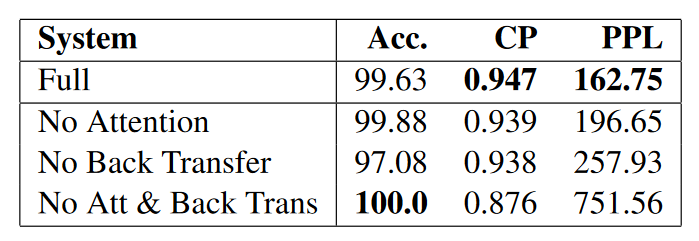
实现结果表明,在风格迁移准确度Acc和内容保存度CP上,本文的模型超越baseline,但是在PPL上比baseline要差一些。
这说明,反向迁移损失和注意力机制的使用使得本文的模型在精确替换非攻击词的同时,能够很好地保留原句内容。由于模型趋于使用诸如“big”这类相同简单的非攻击性词来替换攻击性词,产生了许多不寻常和意想不到的句子,而使得句子不那么流畅,造成较高的PPL值。
- Ablation experiment and Analysis
本文还进行了消融实验,实验结果如下图所示。可以看到注意力机制和反向迁移模块起着至关重要的作用。特别是当同时去掉这两个模块时,即使Acc达到了100%,但是其他CP和PPL大大降低。
这种行为的发生是由于解码器在将一个句子从一种风格迁移到另一种风格时不得不进行权衡,解码器必须在转换为正确的风格和生成高质量的句子之间保持适当的平衡。这些指标中的每一个都可以很容易地单独实现,例如,复制整个输入句子将给出低PPL和良好的CP,但Acc低,另一方面,输出单个关键字可以给出高Acc,但高PPL和低CP。虽然分类损失引导解码器生成属于目标风格的句子,但反向迁移损失和注意力机制鼓励解码器从输入句子复制单词。当反向迁移损失和注意力都被移除时,鼓励模型只满足迁移步骤中的分类要求。
- Discuss
值得注意的是,目前的无监督文本风格迁移方法只能很好地处理攻击性语言问题为词法的情况,仅仅改变/删除少量的单词就可以解决这个问题。本实验的模型在攻击性地使用通常不具有攻击性的词汇的隐式偏向的情况下是无效的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









