




 本文详细介绍了Selenium WebDriver,它是Selenium 2的核心特性,提供了一套跨平台、语言无关的API用于控制浏览器。内容涵盖WebDriver的安装、元素定位方法如id、name、class name、tag name、xpath和css选择器,以及如何进行点击、输入、导航等操作。此外,文章还讲解了如何处理弹窗、下拉框、上传文件等复杂场景。
本文详细介绍了Selenium WebDriver,它是Selenium 2的核心特性,提供了一套跨平台、语言无关的API用于控制浏览器。内容涵盖WebDriver的安装、元素定位方法如id、name、class name、tag name、xpath和css选择器,以及如何进行点击、输入、导航等操作。此外,文章还讲解了如何处理弹窗、下拉框、上传文件等复杂场景。
这里写目录标题
1.selenium介绍
参考添加链接描述
Selenium是针对Web应用的开源自动化测试工具,通过编写模拟用户操作的脚本,它会打开浏览器对Web应用进行黑盒测试。可以方便的用于功能测试、兼容性测试、 稳定性测试及并发测试。Selenium由IDE、Remote Control(简称RC)、WebDriver、Grid四个工程组成:
1、Selenium IDE
是一个用于录制/回放测试脚本的Firefox附加组件。
2、Selenium RC
RC由Server和Client组成两部分组成,Server负责加载/关闭浏览器以及作为HTTP代理来访问Web应用,Clinet支持多种编程语言和测试框架(TestNG、JUnit、NUnit等)。
3、Selenium WebDriver
WebDriver作为Selenium2的核心特性提供比RC更简洁易用的API,是官方推荐的RC替代方案。可以更好的支持动态网页,不需要再额外启动一个独立的Server。
4、Selenium Grid
是Selenium的一个扩展工具,可以很方便地同时在多台机器上和异构环境中并行运行多个RC或WebDriver用例。
2.selenium优点
3.webdriver 简介
- webdriver这是Selenium2 核心特性。Webdriver供了web自动化的各种语言调用接口库。
- “WebDriver”顾名思义就是“Web浏览器驱动”,它专注于解决如何通过外部命令(通常为测试用例)操作浏览器的问题。
-
- WebDriver规范定义一组与平台、语言无关的接口(API),包括发现和操作页面上的元素以及控制浏览器行为,主要用于支持Web应用的自动化测试。
- Webdriver是通过各种浏览器的驱动(web driver)来驱动浏览器的。
4.webdriver 常用api
4.1 api 脚本
# coding = utf-8(可加可不加,一般加上防止乱码)
from selenium import webdriver #使用selenium库的WebDriver里的函数,要先把包导入
import time
driver = webdriver.Chrome() #导入使用浏览器的驱动
time.sleep(3)
driver.get("http://www.baidu.com")
time.sleep(3)
driver.find_element_by_id("kw").send_keys("selenium") #使用id定位
time.sleep(3)
driver.find_element_by_id("su").click()
driver.quit() #不仅退出窗口,而且关闭整个webdriver,释放连接,quit是更加彻底的close
driver.close() #关闭当前浏览器窗口
4.2元素的定位
常用的元素
id(唯一)
name
class name
tag name
xpath(唯一)
css selector(唯一)
link text
partial link text
以百度为例,Chorme浏览器中打开百度,,定位输入框和百度一下按钮,(右击,点击检查)

1.定位输入框

2.定位“百度一下按钮”

4.2.1 id 和name
输入框:
定位百度一下按钮:
4.2.1.1 id
from selenium import webdriver
import time
##获取浏览器的驱动
driver=webdriver.Chrome()
##打开百度网页
driver.get("https://www.baidu.com")
##id
driver.find_element_by_id("kw").send_keys("张艺兴") #定位到输入框
driver.find_element_by_id("su").click()#定位到“百度一下按钮”
time.sleep(5)
driver.close()
4.2.1.1 name
from selenium import webdriver
import time
##获取浏览器的驱动
driver=webdriver.Chrome()
##打开百度网页
driver.get("https://www.baidu.com")
#name
driver.find_element_by_name("wd").send_keys("孙一宁")
driver.find_element_by_id("su").click()
time.sleep(5)
driver.close()
4.2.2 class name 和tag name
输入框:
定位百度一下按钮:
从输入框de 信息中,我们看到,不只有id和name两个属性,还有class name
和tag name(标签名)
input 就是一个标签的名字(但不唯一),可以通过find_element_by_tag_name(“input”) 来定位。
class=“s_ipt”,通过find_element_by_class_name(“s_ipt”)定位。
4.2.2.1 通过 class name
from selenium import webdriver
import time
driver = webdriver.Chrome()
driver.get("https://www.baidu.com/")
# 3.通过class name定位
driver.find_element_by_class_name("s_ipt").send_keys("张杰")
time.sleep(6)
driver.find_element_by_class_name("bg_s_btn").click()
time.sleep(6)
driver.quit()
4.2.2.2 通过 tag name
tag name 指标签名字,像input button 等,一般情况下不唯一
4.2.1 css定位 和xpath
-
CSS(Cascading Style Sheets)是一种语言,它被用来描述HTML 和XML 文档的表现。 CSS
-
使用选择器来为页面元素绑定属性。这些选择器可以被selenium 用作另外的定位策略。
-
CSS 的比较灵活可以选择控件的任意属性,上面的例子中:
find_element_by_css_selector("#kw") -
CSS的获取可以用chrome的F12开发者模式中Element-右键-copy-copy selector来获取
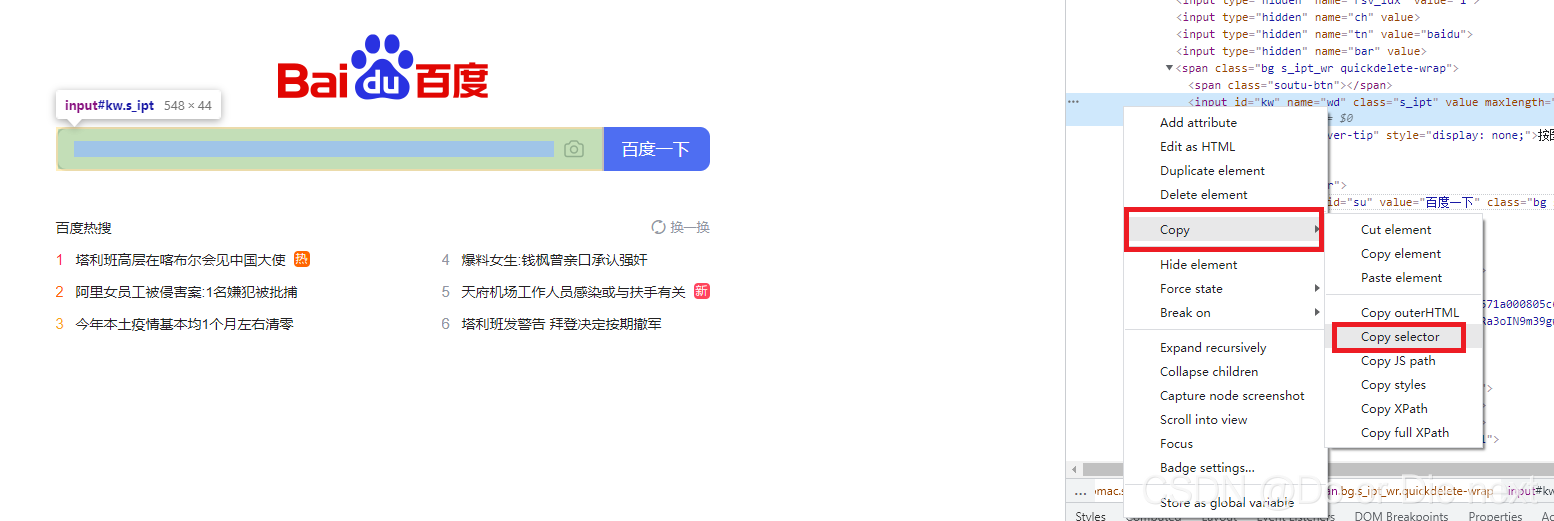
from selenium import webdriver
import time
driver = webdriver.Firefox()
driver.get("https://www.baidu.com/")
# 4.通过CSS定位,通过检查元素定位到对应行,右击点击复制选择css选择器
driver.find_element_by_css_selector("#kw").send_keys("张艺兴")
time.sleep(6)
driver.find_element_by_css_selector("#su").click()
time.sleep(6)
driver.quit()
4.2.2.2 通过 xpath
XPath 是一种在XML 文档中定位元素的语言。因为HTML 可以看做XML 的一种实现,所以selenium 用户可是使用这种强大语言在web 应用中定位元素。
XPath 扩展了上面id 和name 定位方式,提供了很多种可能性。
在元素的定位行,右击选择copy,进行xpath的复制

from selenium import webdriver
import time
##获取浏览器的驱动
driver=webdriver.Chrome()
##打开百度网页
driver.get("https://www.baidu.com")
driver.find_element_by_xpath("//*[@id='kw']" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 749
749

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









