







鉴于单位需要大量的文献类得数据进行分析处理,又让我重新拿起了爬虫的技术开发,时隔两年,再次接触爬虫发现技术的迭代更新已经是日新月异,所以又要开始新的一轮学习之路,正好借此机会,再对新的技术的认知下,我整理了该文档,希望能把爬虫的技术重新支起一个架构,能让自己的技术更加成熟,整体的爬取代码经过必要数据的脱敏后可通过网址查看。
1. 关于解析html页面中的js、css和图片等文件内容的下载
1.1. 同步加载、异步加载、延迟加载和预加载
同步加载:在同步加载中,浏览器会等待服务器响应,只有当响应完成才会继续执行后续的代码。同步加载通常用于关键资源,因为它们需要尽快加载以优化用户体验。但是,由于同步加载会阻塞浏览器,因此不推荐用于大型资源。
异步加载:在异步加载中,浏览器不会等待服务器响应,而是继续执行后续的代码。当服务器响应可用时,异步加载会通过回调函数或Promise等方式通知浏览器进行处理。异步加载不会阻塞浏览器,因此通常用于大型资源或非关键资源。
延迟加载:延迟加载又称为懒加载,是一般对于图片、视频等大型资料的一种处理方式,在这些情况下,浏览器只加载用户当前可见的资源,其他资源则在需要时异步加载。延迟加载可以减少页面加载时间,提高用户体验。
预加载:为了保证显示的效果和交互性,一般会将首页等内容设置为预加载模式,可以提前展示部分的加载数据信息,获得好的响应度。
本次实验项目中涉及到了关于下载html页面中的图片、js文件和css文件格式设置等信息,使用同步加载过程中经常会因为等待解析下载文件过程中出现网络卡顿或者程序的阻塞延迟,并增加了对单条数据的爬取速度,故采用异步下载的方式进行解决
1.2. python的异步下载并发
在python中,进行异步下载并发操作可以使用多种方法,包括使用asyncio库、aiohttp库或concurrent.futures模块。
1.2.1. 可以尝试使用异步下载并发的场景
- 网页爬虫:
-
- 异步下载可以快速抓取网页数据,同时处理多个URL。
- API调用:
-
- 当需要从多个服务或API获取数据时,异步请求可以减少等待时间。
- 文件下载:
-
- 对于大量文件或大文件的下载,异步操作可以提高下载效率。
- 实时数据处理:
-
- 在需要实时处理数据流的应用中,如股票市场数据,异步下载可以确保数据的即时性。
- 社交媒体监控:
-
- 监控多个社交媒体平台的更新,异步下载可以及时获取信息。
- 内容分发网络(CDN):
-
- 异步下载可以提高内容分发的效率和速度。
1.2.2. asyncio和aiohttp库结合的并发请求代码
import aiohttp
import asyncio
async def download_file(session, url):
async with session.get(url) as response:
return await response.read()
async def main(urls):
async with aiohttp.ClientSession() as session:
tasks = [download_file(session, url) for url in urls]
files = await asyncio.gather(*tasks)
# 处理下载的文件内容
...
# 要下载的URL列表
urls = ["http://example.com/file1", "http://example.com/file2", ...]
# 运行主函数
asyncio.run(main(urls))aiohttp 是一个异步的 HTTP 客户端/服务器框架,用于 Python 中的异步网络编程。使用 aiohttp 时,你可以调用多种方法来处理 HTTP 请求和响应。
客户端方法
aiohttp.ClientSession():创建一个新的客户端会话。这是发起请求之前必须的步骤。
session.get(url):发起一个 GET 请求。
session.post(url, data):发起一个 POST 请求,通常包含请求体(如表单数据或 JSON 数据)。
session.put(url, data):发起一个 PUT 请求。
session.delete(url):发起一个 DELETE 请求。
session.head(url):发起一个 HEAD 请求,只请求页面的头部信息。
session.options(url):发起一个 OPTIONS 请求,获取资源的有效请求方法和通信协议。
session.patch(url, data):发起一个 PATCH 请求。
客户端属性和方法
response.status:获取响应的状态码。
response.headers:获取响应的 HTTP 头。
response.text():读取响应的内容作为字符串。
response.json():如果响应是 JSON 格式,这个方法会解析 JSON 并返回一个 Python 字典。
response.read():读取响应的原始字节数据。
response.close():关闭响应。
异常处理
aiohttp.ClientError:捕获客户端请求过程中可能出现的错误。
aiohttp.HttpProcessingError:捕获 HTTP 处理错误,如超时或连接错误。
会话管理
session.close():关闭客户端会话,释放资源。
使用上下文管理器 (async with):使用 async with aiohttp.ClientSession() as session: 可以自动管理会话的创建和关闭。
使用该方法应用到本项目爬虫中,我们将对html页面中的所有的js、css以及图片进行下载爬取
import aiohttp
import asyncio
from bs4 import BeautifulSoup
async def download_resource(session, url, folder):
try:
async with session.get(url) as response:
if response.status == 200:
file_path = f"{folder}/{url.split('/')[-1]}"
with open(file_path, 'wb') as f:
f.write(await response.read())
print(f"Downloaded {url}")
else:
print(f"Failed to download {url}")
except Exception as e:
print(f"Error downloading {url}: {e}")
async def main(urls, folder):
async with aiohttp.ClientSession() as session:
tasks = []
for url in urls:
soup = BeautifulSoup(await session.get(url).text(), 'html.parser')
for link in soup.find_all('a', href=True):
resource_url = link['href']
if resource_url.endswith(('.js', '.css', '.png', '.jpg', '.jpeg', '.gif')):
full_url = aiohttp.helpers.urljoin(url, resource_url)
tasks.append(download_resource(session, full_url, folder))
await asyncio.gather(*tasks)
# 要下载资源的 URL 列表
urls = ["http://example.com"]
# 保存下载资源的文件夹
folder = "downloaded_resources"
# 运行主函数
asyncio.run(main(urls, folder))1.2.3.小结
由于cnki文件爬虫下载需要保证在一个长周期的时间内持续执行,为了保证其稳定性能,笔者尝试使用异步下载的方式进行并发处理,极大的提高到了下载的稳定性,并将自动化的爬取数据成为可能。
2. 反爬机制下的两种滑动检验机制
2.1. 进入html页面进行访问时的滑动显示全文

这种是最为简单的滑动验证,只需要我们找到滑动的滑块元素的标签,并且根据页面窗口计算出所需要滑动的距离即可。
代码如下:
def slide_to_unlock(driver):
"""模拟滑块滑动的动作"""
try:
slider = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, '//*[@id="js-handler"]'))
)
action = ActionChains(driver)
action.click_and_hold(slider).perform()
action.move_by_offset(420, 0).perform()
action.release().perform()
except Exception as e:
logger.error(f"处理滑块时发生异常:{str(e)}")2.2. 长时间爬取时网站的异常检验的滑动验证
中国知网官方对长时间爬取后会对爬虫行为进行异常验证,这个时候所采用的是常见的空缺滑动对齐的方式
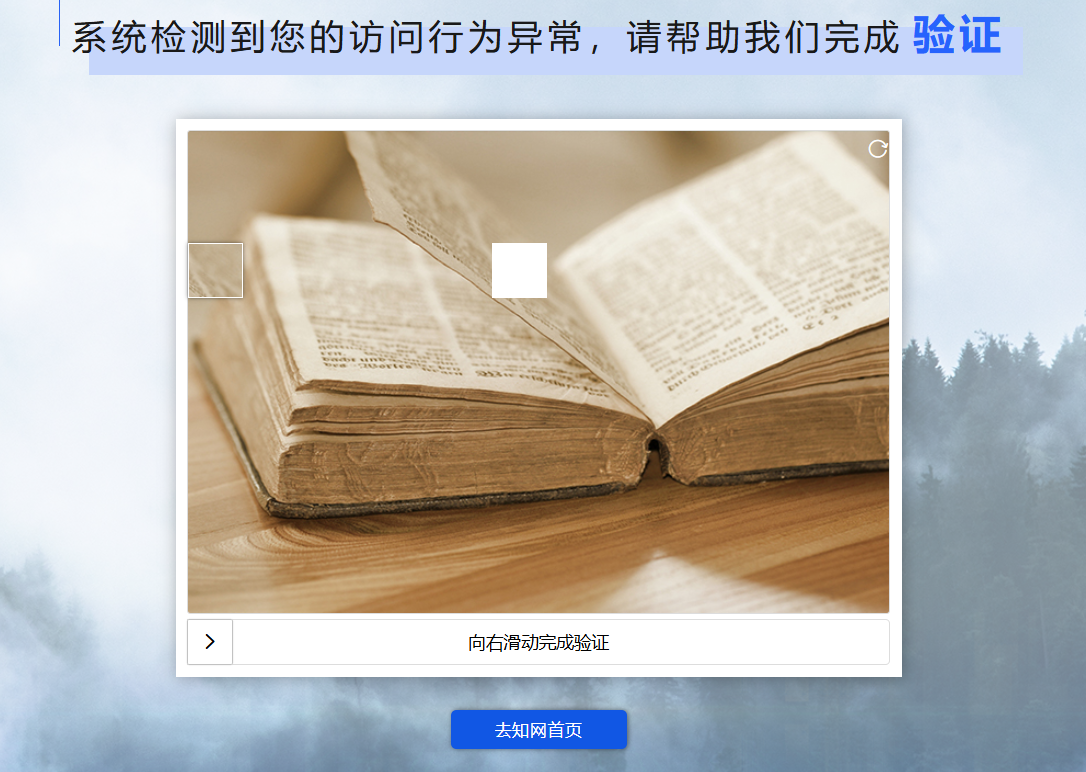
相较于目前更为复杂的反爬验证机制,以上这种爬取机制已经属于最为常规的方式,采用opencv进行检索前景图片以及后景图片即可。
from selenium import webdriver
from selenium.webdriver.edge.service import Service
from selenium.webdriver.edge.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import time
class SliderSolver:
def __init__(self, driver: webdriver.Edge):
self.driver = driver
def solve_slider_captcha(self):
try:
# 等待页面加载
time.sleep(5) # 根据实际情况调整等待时间
# 获取背景图和滑块图元素
background = self.driver.find_element(By.CSS_SELECTOR, '.verify-img-panel')
slider = self.driver.find_element(By.CSS_SELECTOR, '.verify-sub-block')
# 提取滑块的 CSS 样式
slider_style = self.driver.execute_script(
'return window.getComputedStyle(arguments[0]).getPropertyValue("background-position");', slider
)
slider_x = float(slider_style.split(' ')[0].replace('px', ''))
slider_y = float(slider_style.split(' ')[1].replace('px', ''))
# 计算滑块拖动的距离
drag_distance = -slider_x # 滑块需要向左拖动滑动的距离
# 执行滑动操作
action = ActionChains(self.driver)
action.click_and_hold(slider).move_by_offset(drag_distance, 0).release().perform()
# 等待验证结果
time.sleep(5) # 根据实际情况调整等待时间
except Exception as e:
print(f"解决滑块验证码时发生错误:{e}")
def check_and_solve_captcha(self):
# 检查是否存在滑块验证码元素
try:
if self.driver.find_elements(By.CSS_SELECTOR, '.verify-img-panel'):
self.solve_slider_captcha()
except Exception as e:
print(f"检查滑块验证码时发生错误,不需要进行滑块验证:{e}")2.3. 补充当前常见的爬虫验证方式
2.3.1. 图片验证码的识别——采用OCR技术
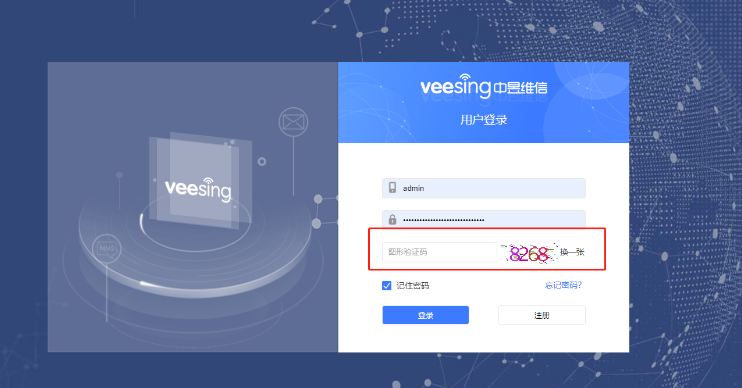
OCR(光学字符识别)使用Python的pytesseract库,这是一个流行的OCR工具,它封装了Google的Tesseract-OCR引擎。
以下是一个简单的OCR识别流程的代码示例,它可以用来识别普通文本图像中的字符。请注意,这个示例可能不适用于复杂或经过扭曲的验证码图像。
首先,确保你已经安装了pytesseract和Pillow(PIL的替代品)库,以及Tesseract-OCR引擎本身。在大多数Linux发行版中,你可以使用包管理器安装Tesseract-OCR。在Windows上,你可以从GitHub下载预编译的二进制文件。
代码如下:
pip install pytesseract pillowfrom PIL import Image
import pytesseract
# 配置Tesseract的安装路径(如果需要)
# pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe' # Windows示例
def ocr_image(image_path):
# 打开图像文件
image = Image.open(image_path)
# 使用pytesseract进行OCR
result = pytesseract.image_to_string(image, lang='chi_sim') # 对于中文使用'chi_sim',对于英文使用'eng'
# 返回识别的文本
return result
# 调用函数,传入图像路径
text_from_image = ocr_image('R-C.jpg')
print(text_from_image)3. 破除日历类组件的样式
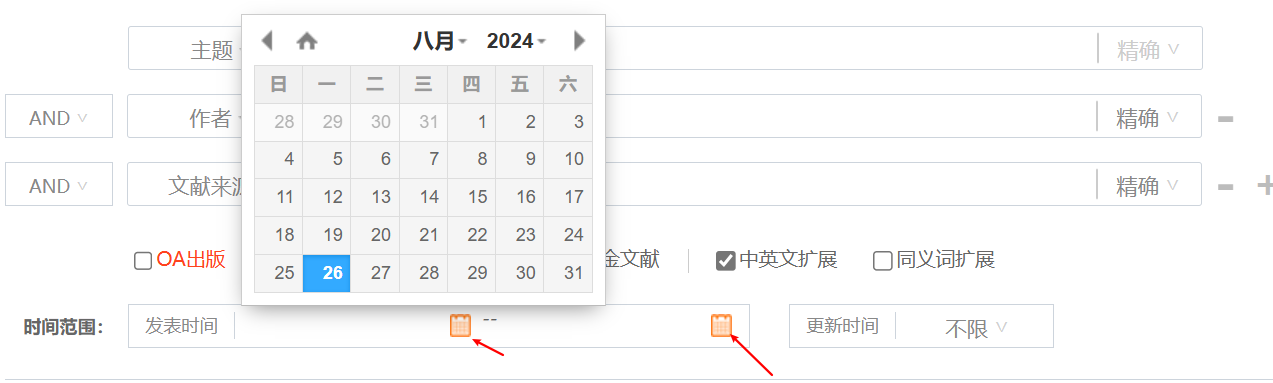
该类的日期型的组件,如果我们自己通过人工手动模拟的方式来点击的话就会很麻烦且复杂,通过检查工具我们可以看到该组件的属性如下:
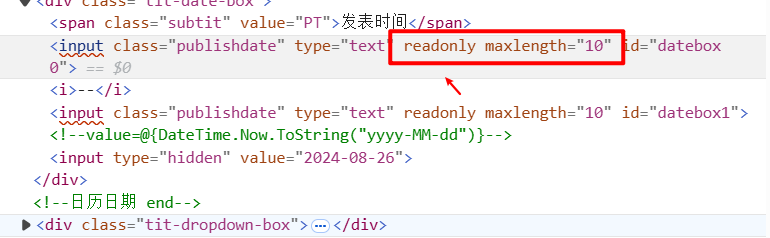
`readonly`属性在多个领域内扮演着重要的角色,它确保了数据的安全性和一致性。在编程中,它可以应用于变量或字段,防止它们被意外或恶意地修改。在用户界面设计中,如HTML表单元素,`readonly`属性允许用户查看但禁止编辑输入值,适用于展示预设信息的场景。在数据库管理中,某些关键字段可能被设置为只读,以维护数据的准确性。文件系统中,`readonly`权限意味着文件可以被读取但不能被更改,保护了文件的原始状态。此外,在API设计中,`readonly`端点仅允许数据检索,不允许数据更新或删除,确保了数据的稳定性。
但是我们可以将该属性破除,代码如下:
def set_date(self, datebox_id, date_str):
date_xpath = f'//*[@id="{datebox_id}"]'
element = WebDriverWait(self.driver, 10).until(
EC.element_to_be_clickable((By.XPATH, date_xpath)))
self.driver.execute_script(f"document.evaluate('{date_xpath}', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue.removeAttribute('readonly')")
element.send_keys(date_str)execute_script方法用于在浏览器中执行 JavaScript 代码。- 这段 JavaScript 代码使用
document.evaluate来找到与date_xpath匹配的元素,并使用singleNodeValue.removeAttribute('readonly')移除该元素的readonly属性,从而使日期框可以接受用户输入。

















 1074
1074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









