







数据结构知识点总结笔记
第一章:数据结构绪论
数据结构的基本概念
数据:是指能够被计算机识别、存储和加工处理的信息载体。
数据元素:数据的基本单位,可以由若干个数据项组成,数据项是构成数据的不可分割的最小标识单位。
数据对象:相同性质的数据元素的集合,是数据的一个子集。
数据类型:一个值的集合和定义在这个集合上的一组操作的总成。
数据类型又分为原子类型,结构类型。
原子类型:值不可分解。
结构类型:值由若干成分按某种结构组成,可以分解。
抽象数据类型:通常由用户定义,用以表示应用问题的数据模型以及定义在该模型上的一组操作。
抽象数据类型(ADT):一个数学模型以及定义在该模型上的一组操作。其定义只与逻辑特性有关,通常采用(数据对象,数据关系,基本操作集)这样的三元来表示抽象数据类型。
ADT=<D,S,P> D为数据对象,S是D上的关系集,P是对D的基本操作集。
说明:类似于面向对象程序中“类”的概念,是用户根据实际应用抽象出来的模型。
数据结构 :相互之间存在的一种或多种特定关系的数据元素的集合,包括:逻辑结构,存储结构和数据的运算。
数据的三要素 :逻辑结构,物理结构,数据元素。
逻辑结构的含义:从具体问题抽象出来的数学模型,它与数据的存储无关,简称数据结构(狭义),数据的逻辑结构可以一个二元组来描述。
date_structrue=<D,S> D为数据元素的有限集,S为D上的关系的有限集。
存储结构(物理结构)含义:数据结构在计算机中的标识(又称映像),数据的逻辑结构在计算机存储器中的实现。
数据的逻辑结构在计算机中的表示,称此为物理结构,或称存储结构。
2种基本结构:顺序存储结构和链式存储结构
数据的运算(算法)含义:检索、排序、插入、删除、修改等…
算法:算法是描述计算机解决给定问题的操作过程,即为决解某一特定问题而由若干条指令组成的有穷序列。
算法的5大特性:
有穷性:执行了有限条指令后一定要终止。
确定性:每步定义都是确切的,无歧义的。
可行性:即算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
输入:有 0个 或者 多个 输入。
输出:有 1个 或者 多个 输出(处理结果)
算法的效率分析:
事后统计法:收集该算法实际的执行时间和实际占用空间的统计资料。
事前分析估算法:在算法运行之前分析该算法的时间复杂度和空间复杂度,来判断算法的效率。
时间复杂度分析:
一个算法的执行时间等于所有语句执行时间的总和;
一条语句执行的时间为该语句的执行次数(频度)与该语句执行一次所需时间的乘积,即一个算法耗费的时间=所有语句的频次之和
定义:一般情况下,算法中基本操作重复执行的次数是问题规模n的某个函数,算法时间量度记作T(n)=O(f(n))
说明:
1.“O”的形式定义为:若f(n)是正整数n的一个函数,则T(n)=O(f(n))表示存在一个正的常数M,使得当n>=n₀ 时,都满足|T(n)|<=M|f(n)|,也就是只求出f(n)的最高阶,忽略其低阶项和常系数。
2.一个没有循环的算法中基本运算次数与问题规模无关,记作O(1),也称常数阶。
3.一个只有一重循环的算法中,基本运算次数与问题规模n的呈线性线性增大关系,记作O(n),也称为线性阶。
常见函数的时间复杂度按数量递增排列及增长率:
常数阶 O(1)<对数阶 O(log₂n)<线性阶 O(n)<线性对数阶 O(nlog₂n)<平方阶 O(n²)<立方阶 O(n³)<k次方阶 O(nᵏ)<指数阶 O(2ⁿ)<阶乘阶 O(n!)
第二章:线性表
线性表的类型定义:
线性表是n(n>0)个相同类型数据元素构成的有限序列,其中n为线性表的长度。
说明:
1.n定义为表的长度,当n=0时,为空表。
2.在非空的线性表中,记为(a₁,a₂,a₃…aₘ₋₁,aₘ)有且仅有一个开始结点a₁和一个终端结点aₙ,其余内部结点aₘ(2<=m<=n-1)都有且仅有一个直接前趋aₘ₋₁和一个直接后继aₘ₊₁。
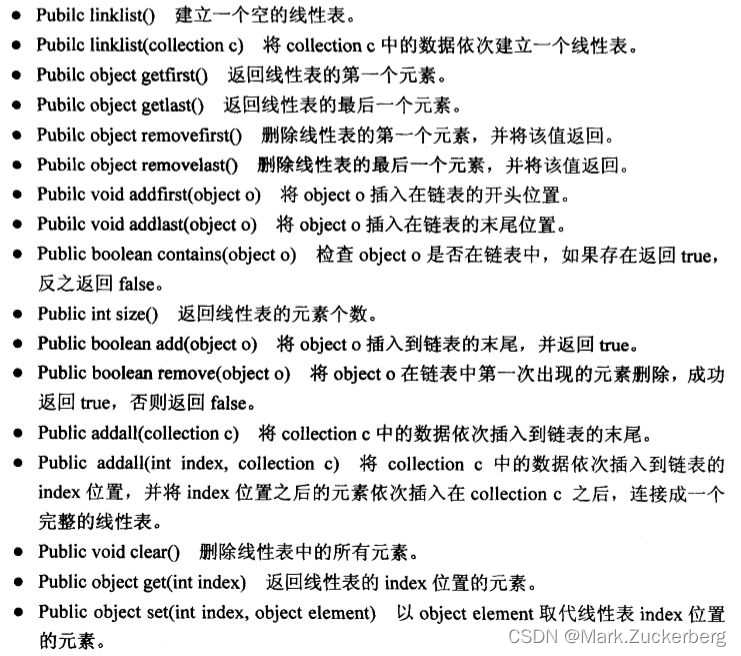
线性表的基本操作:

线性表的顺序表示和实现:
线性表的顺序存储结构:用一组地址连续的存储单元依次存储线性表的元素。
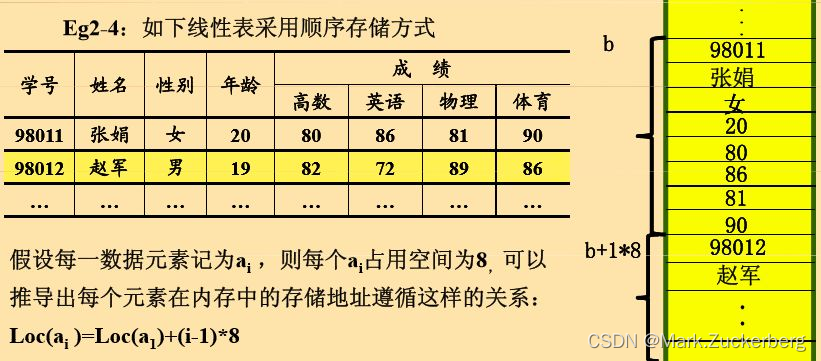
线性表的顺序存储,也称为向量存储,又可以说是一维数组存储。线性表中结点存放的物理顺序与逻辑顺序完全一致,它叫向量存储。

线性表顺序存储结构在 插入或删除 数据元素时比较繁琐,但是它比较适合存取 数据元素。
线性表的插入操作:在第i个元素之前插入一个元素时,需将第n至第i(共n-i+1)个元素向后移动一个位置。

线性表的删除操作:删除第i个元素时需将从第i+1至第n(共n-i)个元素一次向前移动一个位置

线性表的链式表示和实现
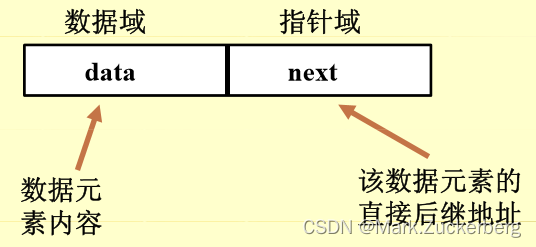
用一组任意的存储单元(可能不连续)存储线性表的数据元素。
在链式存储结构中,每个存储结点不仅包含数据元素本身的信息,还必须包含每个元素之间逻辑关系的信息,即包含直接后继结点的地址信息(指针域)。
逻辑顺序与物理顺序有可能不一致;属于顺序存取的存储结构,即存取每个元素必须从第一个元素开始遍历,直到找到需要访问的元素,所以所花时间不一定相等。
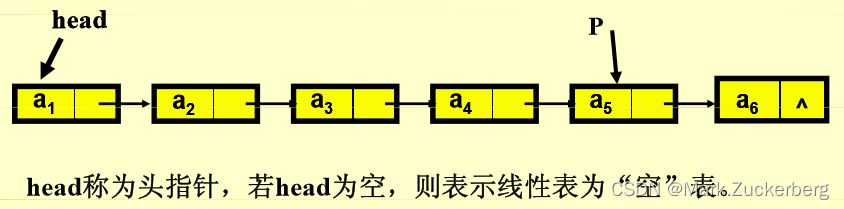
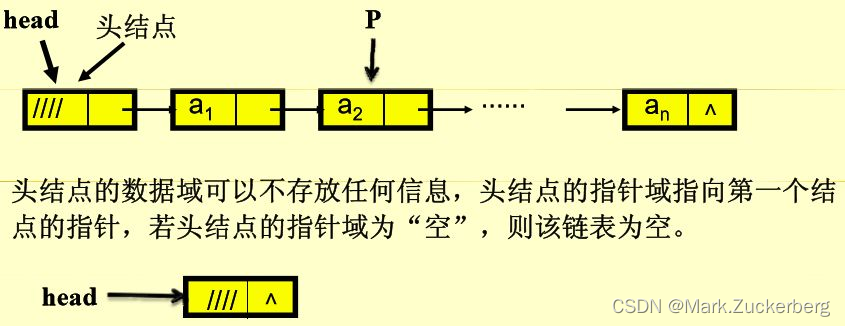
链表的创建方式

结点类的定义:

单链表的基本操作
插入方式——头插法:

插入方式——尾插法:

查找运算——按序号查找:在链表中,即使知道被访问结点的序号i,也不能像顺序表中那么直接按序号i访问结点,而只能从链表的头指针排除法,顺着链域next逐个结点往下搜索,直至搜索到第i个结点为止。链表不是随机存取结构,只能顺序存取。

查找运算——按数值查找:

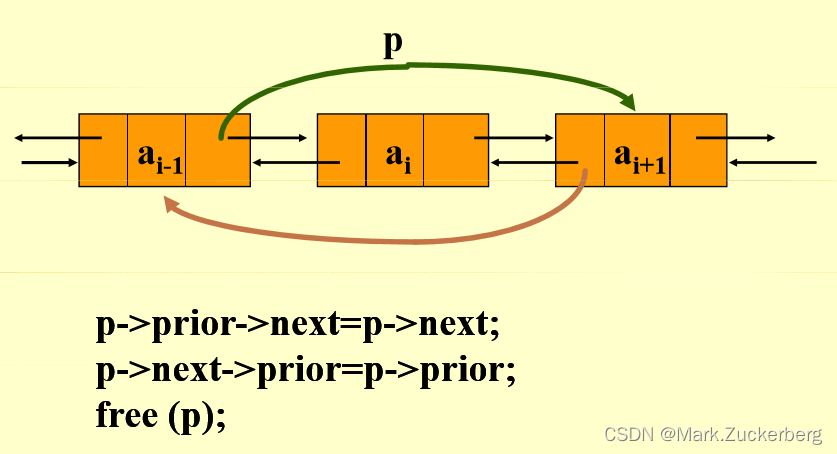
删除结点:将被删除结点的前驱指针连接被删除结点的后继指针

循环链表
表中尾结点的指针域指向头结点,形成一个环。从表中任意一个点出发都可以找到表中其他的结点。

循环链表的操作和线性链表的操作基本一致,但循环链表中没有NULL指针,故遍历操作时,终止条件不再是判断p或p.next是否为空,而是判断他们是否等于某一指定指针,如头指针或尾指针。
双向链表
双向链表是在单链表的每个结点里再增加一个指向其直接前驱的指针域prior。这样就形成了链表中有两个方向不同的链,故称为双向链表。

双线链表——头插法

双向链表——尾插法:

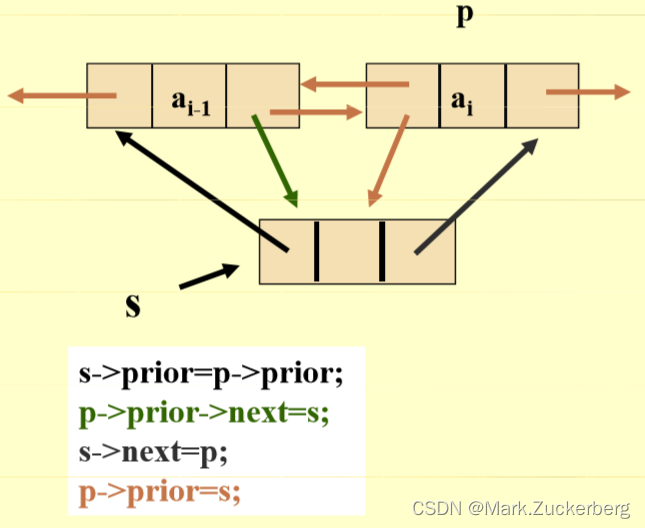
插入操作
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









