






概述:
Volcano是华为开源的云原生组件,最核心的部分是提供了一款Kubernetes的调度器,这款调度器中gang调度策略是核心的核心,gang调度能保证一组Pod同时被调度成功,否则就都不调度,这个能力非常适合现在人工智能以及超算场景下分布式作业(协同工作)的概念。
Volcano调度器是核心,另外提供可一个controller,可以为人工智能和超算的框架创建一组Pod,Pod对上注入这些框架所需的环境变量,并声明使用volcano调度器所需的资源,这些封装简化了使用volcano调度和智算框架的使用。调度器是不可替代的,controller可以有其他开源项目Training-operator等可以替代。
直观上看Volcano运行起来的实例包括Volcano-scheduler(调度器),Volcano-controllers(vjob控制器),Volcano-admission(辅助调度器,在需要时自动补齐Pod的周边配置)
本文每节所讲解的顺序从应用入手再到原理,复杂度会逐节升高,读者可以自取所需,代码级别的东西不太理解也不影响对使用的理解。
Volcano和原生调度器的区别:
概述中有提到Volcano调度器中gang调度策略是核心的核心,gang调度能保证一组Pod同时被调度成功,否则就都不调度。这个能力具体是怎了做的?
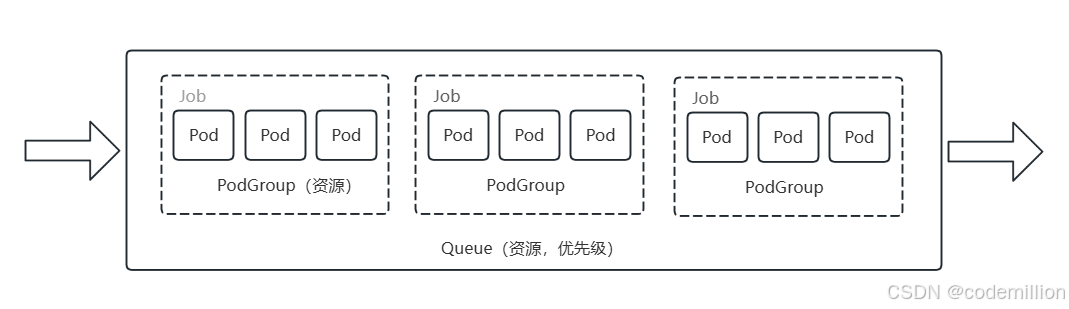
Volcano在原生调度之外增加了Queue和PodGroup的概念,用一副图来表达Queue PG和Pod的关系:
kubectl get crd |grep sched
podgroups.scheduling.volcano.sh 2024-06-21T08:36:50Z
queues.scheduling.volcano.sh 2024-06-21T08:36:50Z使用Volcano进行调度的Pod的特点,在Pod编排里声明schedulerName: volcano,在annotations里声明绑定的PodGroup,scheduling.k8s.io/group-name: my-group
Volcano中,将PodGroup相同的一组Pod看作Job,以Job为单元进行调度。PodGroup起到聚合一组Pod的作用,并限定Pod的资源,同时绑定Queue,PodGroup的声明如下:
apiVersion: scheduling.volcano.sh/v1beta1
kind: PodGroup
metadata:
name: my-podgroup
namespace: ns-29
spec:
minMember: 3 #声明podgroup内至少有3个Pod,这些Pod要一起调度
minResources:
cpu: 10 #至少要有20核128G的资源才够3个Pod调度
memory: 128Gi
queue: my-queue #podgroup绑定的queue名从声明中看下PodGroup把一组Pod聚合起来,并声明这组Pod所需资源的底线,这就把原来对Pod级别的调度,上升到了对一组Pod进行调度的抽象。
apiVersion: scheduling.volcano.sh/v1beta1
kind: Queue
metadata:
name: my-queue
spec:
capability: #my-queue的配额,当queue下Pod占用资源超这个上线,新Job将等候
cpu: '500'
memory: 1000Gi
guarantee: {}
reclaimable: false #一种抢占方式
weight: 1 #什么调度优先级Queue对Queue内PodGroup能用的资源上限做了约束,调度前先计算新增PodGroup的资源不会超过Queue中Capability声明的上限,即可enqueue,之后再检查集群内实际资源是否够调度。所以Queue中设置的资源可以做超卖的用途。
总结下,Queue和PodGroup是Volcano和原生调度器不同的地方,通过Queue和PodGroup,Volcano可以实现对一组Pod进行同时调度。
Volcano调度器的框架:
Volcano调度器的框架中最重要的概念是actions和plugings,actions和plugings都可以通过配置ConfigMap灵活插拔,这是共同点;不同点:actions是流程,Volcano内会按照流程运行,每个流程内会调用一些钩子函数,这些钩子函数就会调用有实现这些钩子的plugin完成特定功能。
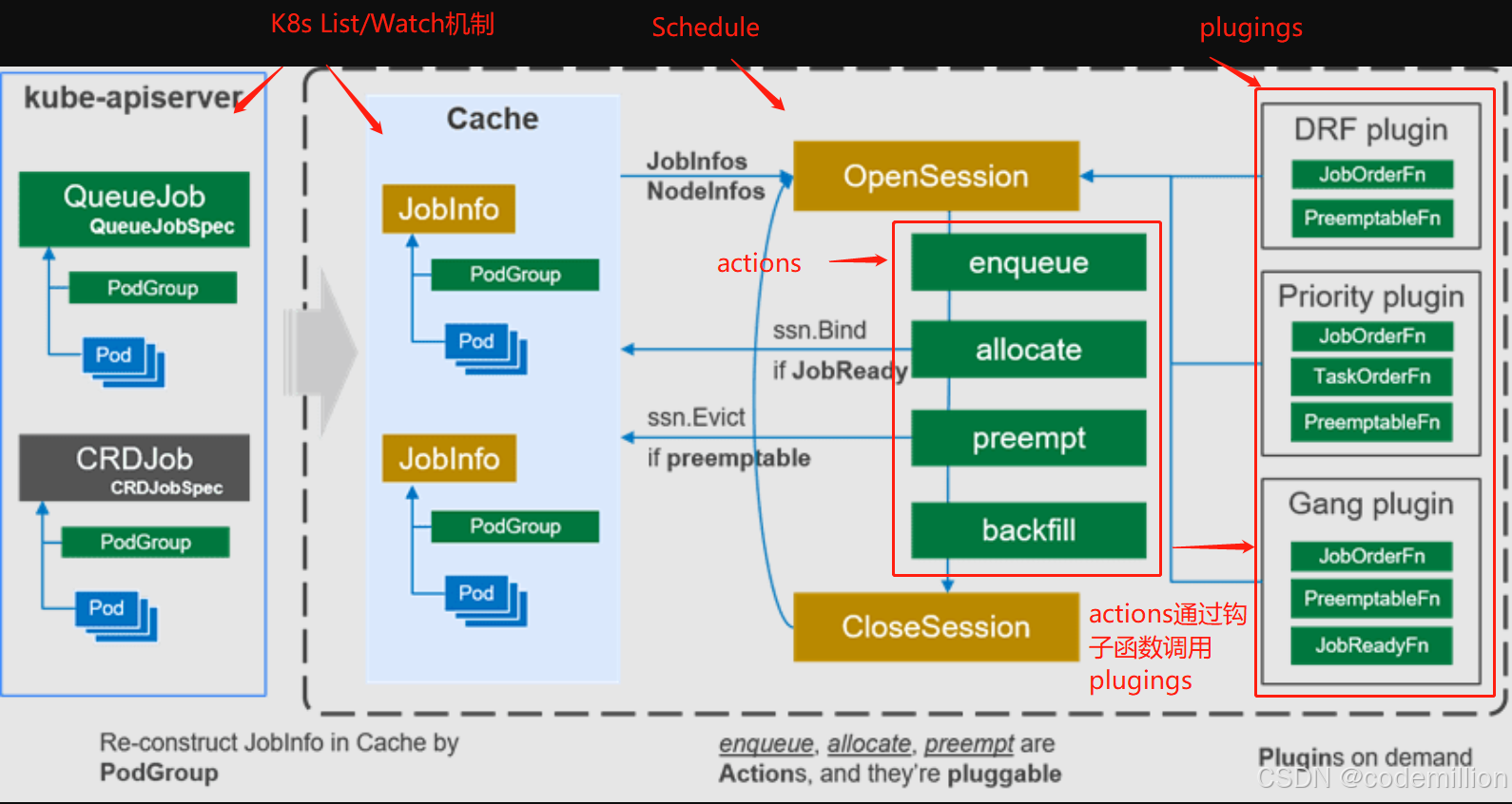
actions流程有6个可选流程:enqueue allocate backfill preempt relcaim shuffle
- enqueue:这个 action 目的是更新一次集群的可提供的资源和待调度 job 的状态,如果 job 里面所有的 task 所需要的资源比集群空余资源小,就会把 job.PodGroup.Status.Phase 从 PodGroupPending 置为 PodGroupInqueue。从这里可以看出 volcano 是以 job 为单位进行调度准入的。
- allocate:这个 action 是调度的的主逻辑,对应 kube-scheduler 的调度和绑定这两步。不过,这里以 task 为单位进行,也是通过预选(PredicateNodes),优选(PrioritizeNodes)的步骤筛选合适的 node,然后对 task 和 node 进行绑定。
- preempt:抢占 actions 是可选的,不过跟 kube-scheduler 的抢占不同的是,不会抢占已经调度完成的 tasks,只会尝试从其他调度队列中的 jobs 或者是同一调度队列的 jobs 中抢占资源(根据 jobs 的优先级抢占)。如果希望抢占已经调度的资源,可以开启另外一个 action reclaim ,会尝试抢占其他低优先级队列中的已经调度 jobs 的资源。
- backfill:对那些没有声明request资源的Pod进行调度,如果没有backfill那么没有什么request资源的Pod就不会被调度起来。
6个流程看着有点多,但是通常用的就3个,enqueue,allocate,backfill,而其中核心的就前2个流程。代码目录volcano/pkg/scheduler/actions
这里整理了一些enqueue和allocate的钩子函数:
| actions | 钩子函数 |
| enqueue | QueueOrderFn JobEnqueued |
| allocate | QueueOrderFn jobValidFns predicateFn overusedFns TaskOrderFn PrePredicateFn PredicateNodes BestNodeFn BatchNodeOrderFn NodeOrderMapFn NodeOrderReduceFn BestNodeFn |
enqueue,allocate这些actions通过以上钩子函数调用各plugings,可以看一个钩子函数QueueOrderFn的例子:
func (ssn *Session) QueueOrderFn(l, r interface{}) bool {
for _, tier := range ssn.Tiers {
for _, plugin := range tier.Plugins { //遍历插件
if !isEnabled(plugin.EnabledQueueOrder) {
continue
}
qof, found := ssn.queueOrderFns[plugin.Name] //找插件的queueOrderFns
if !found {
continue
}
if j := qof(l, r); j != 0 { //如果插件有该函数则执行插件函数
return j < 0
}
}
}
// If no queue order funcs, order queue by CreationTimestamp first, then by UID.
lv := l.(*api.QueueInfo)
rv := r.(*api.QueueInfo)
if lv.Queue.CreationTimestamp.Equal(&rv.Queue.CreationTimestamp) {
return lv.UID < rv.UID
}
return lv.Queue.CreationTimestamp.Before(&rv.Queue.CreationTimestamp) //兜底,如果插件没实现相关钩子,则已时间戳判断queue顺序
}plugings函数有很多,代码目录volcano.orig/pkg/scheduler/plugins,下面用以列表来呈现plugins的功能:
| 插件 | 功能 | 参数说明 | 用法演示 |
|---|---|---|---|
| gang(大名鼎鼎) | 将一组pod看做一个整体去分配资源 | - | - |
| overcommit | 将集群的资源放到一定倍数后调度,提高负载入队效率。负载都是deployment的时候,建议去掉此插件或者设置扩大因子为2.0。 | overcommit-factor: 扩大因子,默认是1.2 | - plugins: - name: overcommit arguments: overcommit-factor: 2.0 |
| binpack | 将pod调度到资源使用较高的节点以减少资源碎片 | binpack.weight:binpack插件本身在所有插件打分中的权重 binpack.cpu:cpu资源在资源比重的比例,默认是1 binpack.memory:memory资源在所有资源中的比例,默认是1l binpack.resources: | - plugins: - name: binpack arguments: binpack.weight: 10 binpack.cpu: 1 binpack.memory: 1 binpack.resources: nvidia.com/gpu, example.com/foo binpack.resources.nvidia.com/gpu: 2 binpack.resources.example.com/foo: 3 |
| conformance | 跳过关键Pod,比如在kube-system命名空间的Pod,防止这些Pod被驱逐 | - | - |
| priority | 使用用户自定义负载的优先级进行调度 | - | - |
| drf (防止胖Job占用所有资源) | 根据作业使用的主导资源份额进行调度,用的越少的优先 | - | - |
| predicates(一些基础的预选功能) | 预选节点的常用算法,包括节点亲和,pod亲和,污点容忍,node ports重复,volume limits,volume zone匹配等一系列基础算法 | - | - |
| nodeorder | 优选节点的常用算法 | nodeaffinity.weight:节点亲和性优先调度,默认值是1 podaffinity.weight:pod亲和性优先调度,默认值是1 leastrequested.weight:资源分配最少的的节点优先,默认值是1 balancedresource.weight:node上面的不同资源分配平衡的优先,默认值是1 mostrequested.weight:资源分配最多的的节点优先,默认值是0 tainttoleration.weight:污点容忍高的优先调度,默认值是1 imagelocality.weight:node上面有pod需要镜像的优先调度,默认值是1 selectorspread.weight: 把pod均匀调度到不同的节点上,默认值是0 volumebinding.weight: local pv延迟绑定调度,默认值是1 podtopologyspread.weight: pod拓扑调度,默认值是2 | - plugins: - name: nodeorder arguments: leastrequested.weight: 1 mostrequested.weight: 0 nodeaffinity.weight: 1 podaffinity.weight: 1 balancedresource.weight: 1 tainttoleration.weight: 1 imagelocality.weight: 1 volumebinding.weight: 1 podtopologyspread.weight: 2 |
| numaaware | numa拓扑调度 | weight: 插件的权重 |
Volcano源码分析:
知乎上有比较好的源码分析文章,这里就做些导读和一些补充:
文章1:https://www.zhihu.com/question/366971238
文章2:https://zhuanlan.zhihu.com/p/349695188
1、如果想了解volcano的启动流程可以看文章1的4.2节,主要创建了cache和schedule
2、如果想对actions和plugings如何初始化并串起来,可以看文章1的4.3节,actions里如何调用plugings可以看本文上一节的例子QueueOrderFn中调用插件
3、如果想了解actions的enqueue的代码实现,可以看文章1的4.4节
4、如果想了解actions的allocate的代码实现,可以看文章1的4.5节
多个actions里在开始的整理queue,job,task的流程是很接近的,仔细看完4.4.1和4.4.2,在其他的actions里都有类似的整理流程
想了解更多的actions就要自己看代码。
补充cache的关键步骤和概念,在newSchedulerCache函数中,会创建很多k8s的informer,监听k8s的资源变化,比如:
sc.nodeInformer.Informer().AddEventHandlerWithResyncPeriod(
cache.FilteringResourceEventHandler{
FilterFunc: func(obj interface{}) bool {
node, ok := obj.(*v1.Node)
if !ok {
klog.Errorf("Cannot convert to *v1.Node: %v", obj)
return false
}
if !responsibleForNode(node.Name, mySchedulerPodName, c) {
return false
}
if len(sc.nodeSelectorLabels) == 0 {
return true
}
for labelName, labelValue := range node.Labels {
key := labelName + ":" + labelValue
if _, ok := sc.nodeSelectorLabels[key]; ok {
return true
}
}
klog.Infof("node %s ignore add/update/delete into schedulerCache", node.Name)
return false
},
Handler: cache.ResourceEventHandlerFuncs{
AddFunc: sc.AddNode, //注册Node资源监听函数,node上任何变化都会通知到Add,Update,Delete三个函数
UpdateFunc: sc.UpdateNode,
DeleteFunc: sc.DeleteNode,
},
},
0,
)Cache里监听了那些资源:node,pod,pvc,pv,storageClass,csi,quota,podgroup,queue,cpu
但是这些资源信息并不会原封不动的保存,而是抽取整理了必要信息,一下列出部分对应关系:
| 原资源 | volcano定义结构 | 说明 |
| node | NodeInfo | NodeInfo下收集JobInfo的信息 |
| pod | TaskInfo | 收在JobInfo下 |
| queue | QueueInfo | queue和job间通过map相互索引 |
| JobInfo | 相同PodGroup下的pod收集在同一个JobInfo,JobID也能看出端倪:namespace+podgroupnName |
从资源映射可以Job 就是 PodGroup 封装,可以当作PodGroup看,Task 就是 Pod 封装,额可以当中Pod看。
其他说明:
虽然为了方便Volcano使用,如果没有为Pod创建Podgroup和Queue,Volcano-admission会自动创建,但是自动创建资源控制肯定是不太准确的;所以为了更好的使用Volcano调度器,自动根据Pod声明的资源累加后创建PodGroup,Volcano提供了Volcano-controller,Volcano-controller还有其他替代项目如Training-operator。有时间再接着介绍Training-operator。
Training-operator对下要知道volcano的概念,对上要知道Pythorch,Tensorflow,mpi等智算框架的概念。
当然想要更好的了解volcano,不但要知道原来,更重要的是用起来,甚至是包括一些日志分析和debug的手段。
有兴趣的朋友可以留言自己关心的部分。


















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











