







property属性
property 属性就是负责把类中的一个方法当作属性使用,这样可以简化代码使用。
定义property属性有两种方式
1、装饰器方式
2、类属性方式
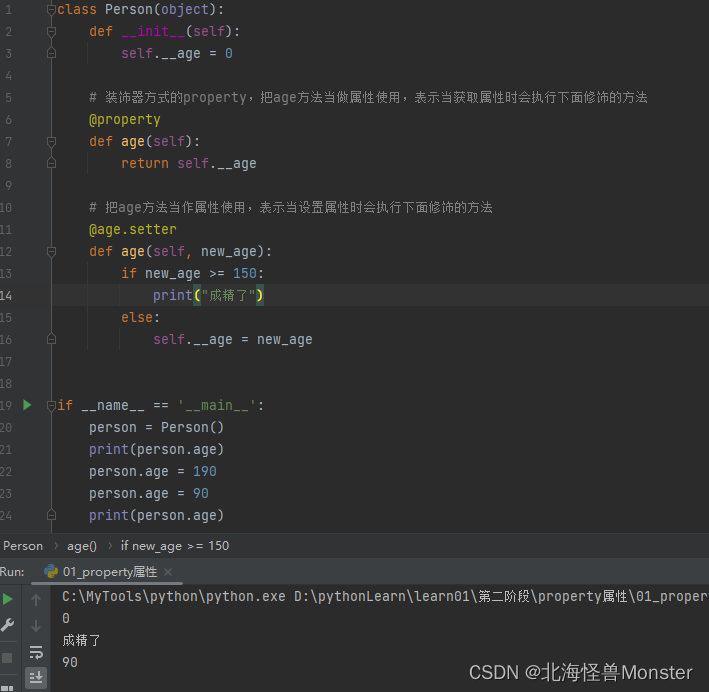
装饰器方式:
原本私有属性,我们不能直接访问,只能通过方法简介进行访问。
如果不加 @property,那么我们就只能通过方法的方式进行调用,加了 @property之后,我们就可以使用属性的方法,访问这个方法。
@age.setter , age必须和上面 @property修饰的方法名保持一致,表示把方法当作属性使用,表示当设置属性时会执行下面修饰的方法
而且两个 装饰器修饰的方法名必须一致。
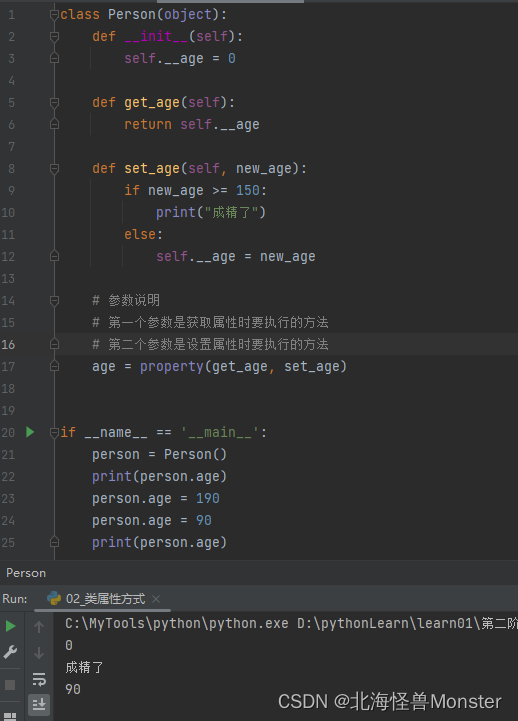
类属性方式:
本质上就是,之前访问私有属性是通过方法,现在将方法变为属性。其实我并不太理解这有什么意义,就是一对小括号的事情。
或者说,你直接把这个属性弄为公共属性。
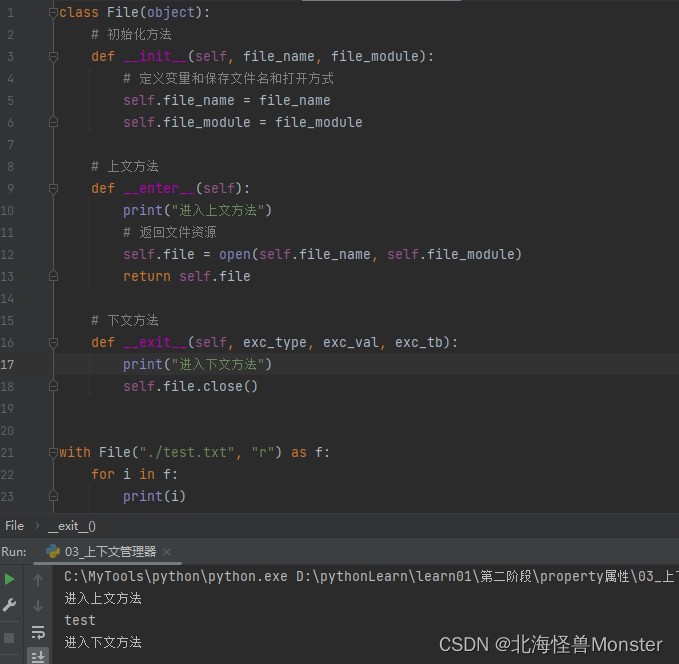
上下文管理器
之前有学习 with open 方法,这是打开文件的方法,并且会自动关闭文件。
with语句为什么可以,因为背后由 上下文管理器 做支撑
也就是说, f = open(…),open函数常见的 f 文件对象就是一个上下文管理器对象
什么是上下文管理器?
一个类只要实现了 __enter__() 和 __exit__() 这两个方法,通过该类创建的对象我们就称之为上下文管理器
__enter__ 表示上文方法,需要返回一个操作文件对象
__exit__ 表示下文方法,with语句执行完成会自动执行,即使出现异常也会执行该方法
但是你创建这个类之后,还是要通过 with 语句进行启动,你前面不加with语句,上下文方法是不会进去的。
但是我有一个疑问,为什么我点击进入 open 的源代码,open 这个类没有实现enter 和 exit 方法。
我找了一下,好像是由实现的,我不太会差python源代码,好像是用过其他子类或者接口实现的。
生成器
生成器作用:根据程序设计者指定的规则循环生成数据,当条件不成立时则生成数据结束,数据不是一次性全部生成出来的,而是使用一个,再生成一个,可以节约大量的内存。
和循环语句生成数据相比,循环语句是一次生成所有数据,而生成器是你使用才生成。
生成器创建
1、生成器推导式
2、yield关键字
1、生成器推导式
首先我们要是知道什么是推导式,python中由列表推导式。
列表推导式是一种 Python 构造,可减少生成新列表或过滤现有列表所需的代码行。列表推导式包含在方括号内,它由一个表达式、一个或多个 for 循环和一个用于过滤生成的列表的可选条件组成。
列表推导式的简单语法:
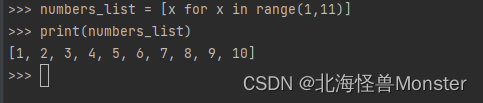
获取 1-10
numbers = [x for x in range(1,11)]
print(numbers)
>>> [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
乘以2 表达式 2*x , 一个for循环, 没有过滤
numbers = [2*x for x in range(1,11)]
print(numbers)
>>> [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
只要偶数 表达式:x , 一个for循环, 一个过滤: if x%2==0
numbers = [x for x in range(1,11) if x%2==0]
print(numbers)
>>> [2, 4, 6, 8, 10]
等差数列
numbers = [2*x-1 for x in range(1,11)]
print(numbers)
>>> [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
列表推导式,就是为了以精简代码的形式获得数据。但是列表推导式生成的是所有数据。
生成器推导式,也是为了生成数据,但是和列表推导式语法不一样的就是把 中括号换成小括号,然后,数据生成方面,列表推导式是一次把所有数据生成出来,生成器推导式是你取一个才生成一个。
生成器推导式:如果你要获取全部,你就使用for循环,或者直接定义列表推导式
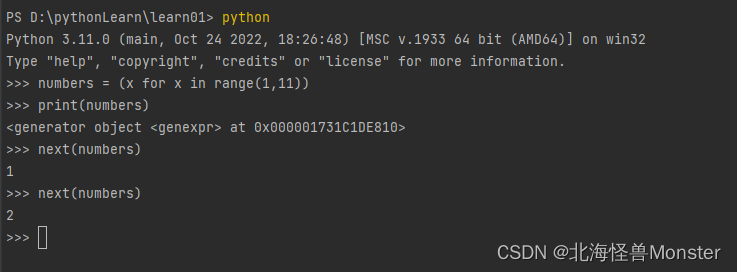
列表推导式:
yield关键字创建生成器
在def函数中具有yield关键字
这种方式是使用比较频繁的一种方式
注意点:
1、代码执行到yield会暂停,然后把结果返回出去,下次启动生成器会在暂停的位置继续往下执行
2、生成器如果把数据生成完成,再次获取生成器中的下一个数据会抛出 StopIteration异常,表示停止迭代异常
3、for循环内部自动处理了停止迭代异常,使用起来更加方便,推荐使用
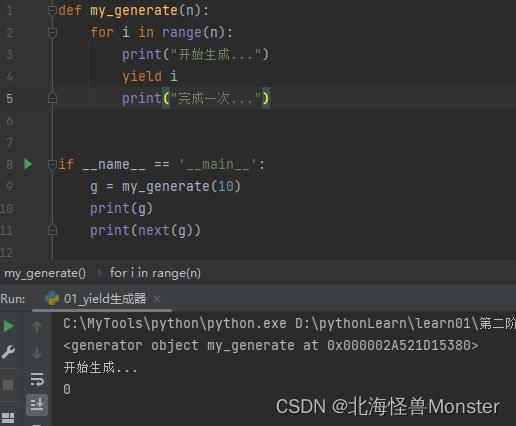
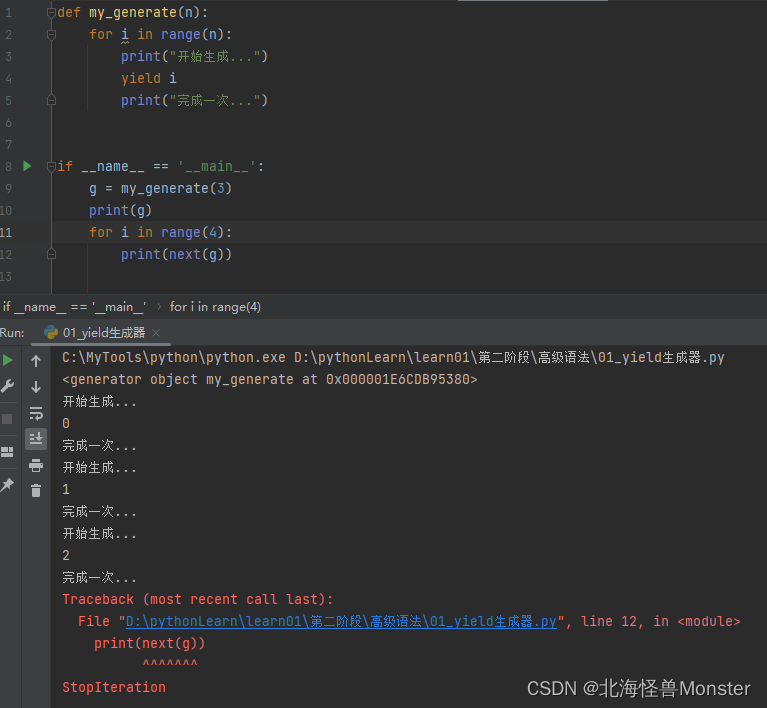
使用yield关键字后,这个函数放回的就是一个生成器,通过上图打印结果可以知道,执行到 yield i 之后就停止了,下次next取数据就会接着上一次的地方继续执行。
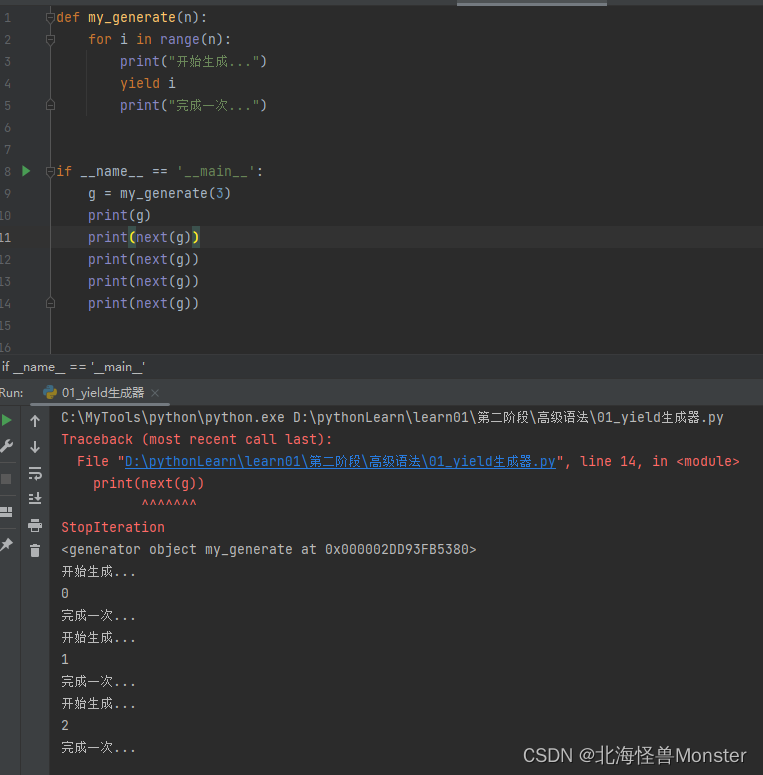
当你next超出返回之后会报错:
使用for循环读取 生成器的数据:
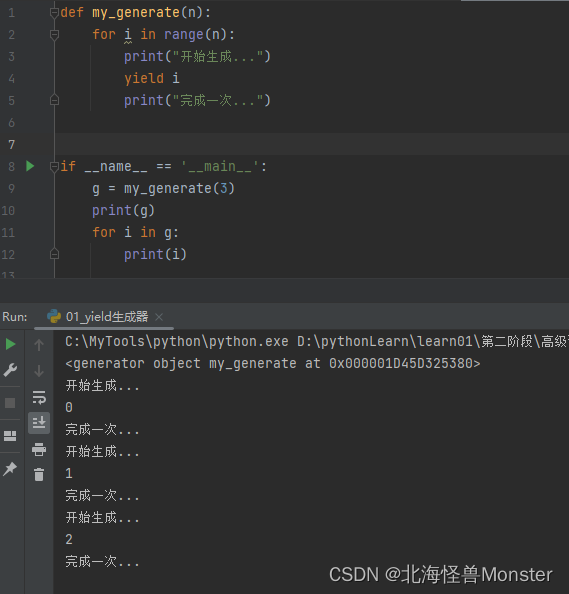
视频老师讲的是,for循环内部自动处理了停止迭代异常,我点不进去for 循环的源码,我觉得,通过下面代码,同样得异常为什么这次for循环没有捕获异常进行处理。我认为得是,for 循环内部不会捕获异常,这样我不是都可以当 try exception来用了嘛。for循环内部可以知道 被循环得数据得长度,所以for循环可以自动跳出循环,比例你循环列表,是不是自动跳出循环,你用while循环列表要自己手动设置跳出循环得条件。所以for循环就是 得跳出条件就是:当被循环数据全部都遍历了,我就跳出循环(个人认为)
生成器使用
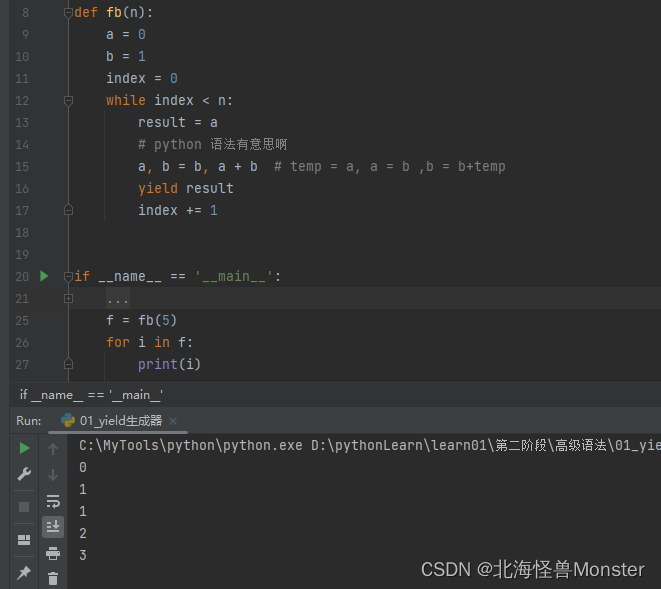
斐波那契数列,通过生成器创建,我使用一个创建一个。
简单说斐波那契数列,第一个值固定为 0 ,第二个值固定为1,
从第三个值开始,后面得值 = 前面两个值得和
0,1,1,2,3,5,8,13,21,34
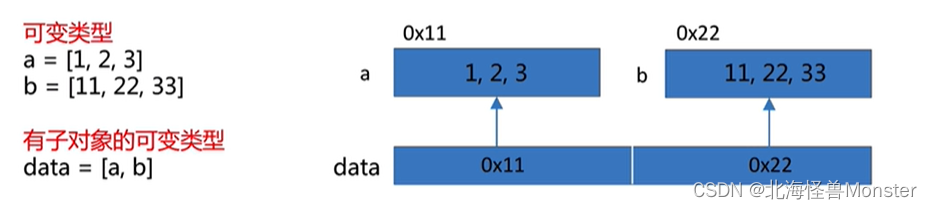
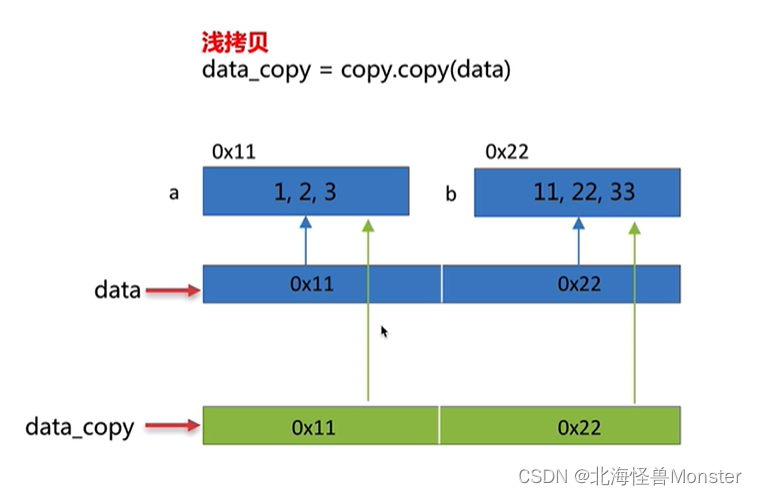
深拷贝和浅拷贝
copy函数是浅拷贝,只对可变类型得第一层对象进行拷贝,对拷贝的对象开辟新的内存空间进行存储,不会拷贝对象内部的子对象。
其实和java一样,对于基础类型,就是拷贝值。
对于引用类型才分深拷贝和浅拷贝。比如 p = Person() ,这个 p 对象,p存放的是指向这个对象的内存地址值,你浅拷贝就是把地址值拷贝了过来,两个变量指向的是同一个对象。如果是深拷贝,那么它是在内存空间申请一个新的地址,将原有对象复制过去,并把新的地址返回给拷贝变量,内存中是有两个对象的。两个对象互不干扰。
python的深浅拷贝:
import copy
深拷贝:
使用deepcopy函数:
只要发现拷贝对象由可变类型就会对该对象到最后一个可变类型的每一层对象进行拷贝,对每一层拷贝的对象都会开辟新的内存空间进行存储。
可变类型:

不可变类型:
依然是和普通赋值时一样的,没有开辟新空间。只是一个变量指向相同。
浅拷贝:
开辟一个新空间,把原有里面的东西拷贝一份过来。
针对不可变类型:不可变类型进行浅拷贝不会给拷贝的对象开辟新的内存空间,而只是拷贝了这个对象的引用。
例如:元组是不可变类型,不可变类型浅拷贝就和普通赋值是一样的
a = (1,2,3)
b = (11,22,33)
data = (a,b)
# data_copy = data
data_copy = copy.copy(data)
下面是可变类型的拷贝,例如 list
普通赋值:
不会开辟新空间,变量直接是指向原有的内存地址

正则表达式
在python中使用正则表达式需要导入 re 模块
import re
# 使用match方法进行匹配操作,不仅限于match方法
result = re.match(正则表达式,要匹配的字符串)
# 如果上一步匹配到数据,可以使用group方法来提取数据
result.group()
正则表达式书写
1、匹配单个字符
| 代码 | 功能 |
|---|---|
| . | 匹配任意一个字符,除了\n |
| [] | 匹配 []中列举的字符 |
| \d | 匹配数字,即0-9 |
| \D | 匹配非数字,即不是数字的任意字符 |
| \s | 匹配空白,即空格和tab |
| \S | 匹配非空白 |
| \w | 匹配非特殊字符,即a-z,A-Z,0-9,_,汉字 |
| \W | 匹配特殊字符,即非字母,非数字,非汉字 |
大写的就是取小写的反
import re
# result = re.match("test.", "test\n")
# result = re.match("test.", "test123") 只会匹配到test1
# result = re.match("test[123a.v]", "test.") # 匹配一个指定元素, . 会在中括号里面转义(只是一个普通字符)
# result = re.match("test[0-9]", "test5") # 等价于 result = re.match("test[\d]", "test5")
# result = re.match("test\D", "testq")
result = re.match("test\s", "test 123123")
print(result) # 如果没有匹配到数据,返回值为None
if result:
info = result.group()
print(info)
else:
print("没有匹配到")
2、匹配多个字符
| 代码 | 功能 |
|---|---|
| * | 匹配前一个字符出现0次或者无数次,即可有可无 |
| + | 匹配前一个字符出现1次或者无数次,即至少出现一次 |
| ? | 匹配前一个字符出现1次或者0次,即要么有一次,要么没有 |
| {m} | 匹配前一个字符出现m次 |
| {m,} | 匹配前一个字符至少出现m次 ,即出现次数大于等于m |
| {m,n} | 匹配前一个字符出现 m次到n次 |
import re
# result = re.match("test1*", "test1111333") test1111
# result = re.match("test1+", "test333") None
# result = re.match("test1?", "test333") test
# result = re.match("test1{2,4}", "test111333") test111
# result = re.match("test1{2,}", "test11111333") test11111 至少出现2次
result = re.match("test1{2}", "test111333") # test11
print(result) # 如果没有匹配到数据,返回值为None
if result:
info = result.group()
print(info)
else:
print("没有匹配到")
3、匹配开头和结尾
| 代码 | 功能 |
|---|---|
| ^ | 匹配字符串开头 |
| $ | 匹配字符串结尾 |
| [^指定字符] | 匹配除了指定字符以外的所有字符 |
import re
# result = re.match("^\d.*test", "123test111333") # 匹配任意以数字开头
# result = re.match(".*\d$", "123test8333") # 匹配任意以数字结尾
result = re.match("[^4]*", "123test84333") # 123test8
print(result) # 如果没有匹配到数据,返回值为None
if result:
info = result.group()
print(info)
else:
print("没有匹配到")
4、匹配分组
| 代码 | 功能 |
|---|---|
| | | 匹配左右任意一个表达式 |
| (ab) | 将括号中字符作为一个分组 |
| \num | 引用分组num匹配到的字符串 |
| (?P<name>) | 分组器别名 |
| (?P=name) | 引用别名为name分组匹配到的字符串 |
| 代码演示: |
import re
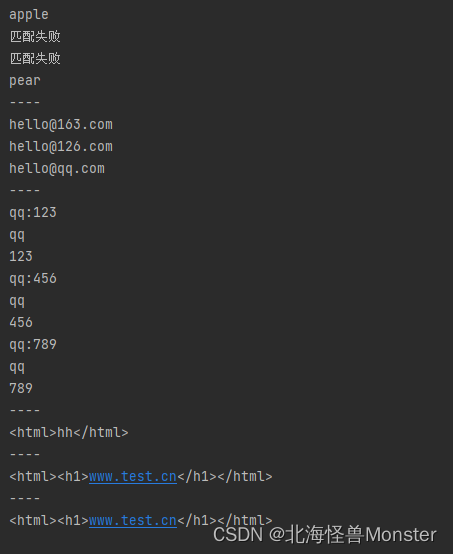
# 1需求:在列表中["apple","banana","orange","pear"] 匹配 apple和pear
fruit = ["apple", "banana", "orange", "pear"]
for value in fruit:
# | 匹配左右任意一个表达式
result = re.match("apple|pear", value)
if result:
print(result.group())
else:
print("匹配失败")
print("----")
# 2需求:匹配出163,126,qq等邮箱
# (ab) 将括号中字符作为一个分组
email = ["hello@163.com", "hello@126.com", "hello@qq.com"]
for value in email:
# 当你匹配表达式中由和正则表达式的特殊字符冲突,可以使用\进行转义
result = re.match("[a-zA-Z0-9]{4,9}@(163|126|qq)\.com", value)
if result:
print(result.group())
else:
print("匹配失败")
print("----")
# 3需求:匹配qq:123456这样的数据,提取出来qq文件和qq号码
# group()方法没有默认参数为0,即不采用分组
# group(1)表示第一个分组的数据,group(2)表示第二个分组的数据,从左到右依次排序
qq = ["qq:123", "qq:456", "qq:789"]
for value in qq:
result = re.match("(qq):([1-9]\d{2,10})", value)
if result:
print(result.group())
print(result.group(1))
print(result.group(2))
else:
print("匹配失败")
print("----")
# 4需求:匹配<html>hh<html>
# \num 引用分组num匹配到的字符串,在一个正则表达式中,前提是前面有分组,在后面 通过 \num使用前面的分组
# \1 是转义字符,所以我们需要多加一个\,将前面的\ 进行转义
result = re.match("<([a-zA-Z0-9]{4})>.*</\\1>", "<html>hh</html>")
if result:
print(result.group())
else:
print("匹配失败")
print("----")
# 5需求:匹配<html><h1>www.test.cn</h1></html>
result = re.match("<([a-zA-Z0-9]{4})><([a-zA-Z0-9]{2})>.*</\\2></\\1>", "<html><h1>www.test.cn</h1></html>")
if result:
print(result.group())
else:
print("匹配失败")
print("----")
# (?P\<name\>) 分组器别名
# (?P=name) 引用别名为name分组匹配到的字符串
# 6需求:匹配<html><h1>www.test.cn</h1></html>
result = re.match("<(?P<name1>[a-zA-Z0-9]{4})><(?P<name2>[a-zA-Z0-9]{2})>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.test.cn</h1></html>")
if result:
print(result.group())
else:
print("匹配失败")
效果显示:
loggin日志
日志分五个等级
DEBUG < INFO < WARNING < ERROR < CRITICAL
默认是WARNING等级,当在WARNING或者WARNING之上等及才会记录。
1、导入logging模块
2、logging初始化,选择输出到控制台还是文件。以及输出格式
logging.basicConfig(level = logging.DEBUG,
fromat = '%(asctime)s - %(filename)s[line:%(lineno)d]) - %(levelname)s: %(message)s',
filename= "log.txt",
filemode="w")

format 就是日志前缀格式
3、在程序中使用
logging.info(…)
logging.error(…)















 284
284











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









