







目录
七、Node.js 模块
模块(包)是 Node.js 中具有特定功能的对象。
之前我们学习 Web 端的 JS 时就已经学习过很多对象,比如 document 对象,window 对象,还有一些内置的,像String对象,Array对象,Math对象等等。在每一个对象里面,都有一些有用的函数可以用,比如document对象,有document.write可以在页面输出内容,document.getElementById,这些是在对象里封装的。

在Node端,不能操作浏览器,比如输出document对象是不可以的。Web端和Node端的交集部分在Node端是可以正常使用的。
Node端的 fs,path 这些,不叫对象,叫模块,这就是模块的概念。当然,在模块里面,也有各种有用的函数。
模块(包)是 Node.js 应用程序的基本组成部分。
大部分前端工程化的工具,是以模块的形式存在的。
模块的划分
根据模块的作者将模块划分为三类:
- 内置模块:官方提供的,无需单独安装,跟随 Node.js 一起安装,使用的时候直接用即可。可以到官网API文档 http://nodejs.cn/api/ 去看,官网有内置模块的列表和使用手册。
- 自定义模块:工程师自己写的,具有一定功能的代码块
文件模块:单独的一个 JS 文件组成的模块
目录模块:多个 JS 文件组合在一起,放在一个目录中形成的模块 - 第三方模块:社区维护的,需要单独下载才能使用。在Node中有一个集中管理的平台,npmjs.com,可以获取到相应信息。
第三方模块是区别前前面两个的,既不是官方提供的,也不是程序员自己写的,那就是第三方模块。Web端JS也有一些第三方的内容,例如jQuery,使用jQuery之前需要用Script引入jQuery,如果不引入的话,jQuery是不能用的。在Node端也一样,如果想要使用一些第三方模块,也需要先单独安装,然后才能使用。Node.js 的第三方模块对应 Web 端 JS 的第三方库。
在Node.js中,大量的第三方模块通过 npm 来管理。


内置模块
内置模块也叫核心模块,跟随 Node.js 一起安装。
之所以称为核心,是因为内置模块提供了最常用的API。
内置模块可以在官网查看英文版文档 https://nodejs.org/zh-cn/docs/ ,也可以查看中文镜像网站文档 http://nodejs.cn/api/(默认显示最新版本,想看指定版本只能去看英文版)。
1. 核心模块 - console
- 控制台中输出的内容,通过不同的颜色标识不同的变量类型。
- 控制台中可以一次输出多个变量, 多个变量之间,用逗号分隔。
- 官方文档:http://nodejs.cn/api/console.html
最简单的输出
//最简单
console.log("1");//输出字符1
console.log(1);//输出数字1
在控制台可以看到输出的字符 1 和数字 1 是不一样的颜色,所以,和 Web 端控制台类似,可以通过控制台输出结果的颜色判断数据类型。

输出对象
//输出对象
var obj = {
name:'Tom',
age:18
}
console.log(obj);
//如果想要表格样式
console.log('-----------------分割线------------------');
console.table(obj);
运行结果:

可以看到,console.log 输出的对象是直接输出,不像Web端输出对象那种有一个折叠菜单,有一个小三角,折开里面可以看到很多东西;但是在 Node 端输出对象就是直接输出。如果想要结构化地展示,可以用 console.table(obj),当然 table 这种方式在浏览器端也是支持的。
计时函数
计时函数是一对,console.time( ) ,time( ) 里面的参数就是计时的标识,或者叫文字提示。下面用for循环做演示。结束的函数是 console.timeEnd( )。
//计时函数
console.time('for'); //计时开始
for(let i = 1;i<1000000;i++){
} //let定义局部变量
console.timeEnd('for'); //计时结束
console.time('while');
var i = 0;
while (i<1000000){
i++;
}
console.timeEnd('while');
注意:开始和结束里面的标识字符串前后要一致,也就是 time( ) 里面的参数和timeEnd( )里面的参数要一致,如果不一致就会报错。
运行结果:

可以看到,同样是循环 1000000 次,for 循环所用时间比 while 循环所用时间长。所以,在后续编程中,能用while循环就不要用for循环。
2. 核心模块 - process
- process 提供了有关当前 Node.js 进程的信息并对其进行控制,就像任务管理器里面显示的进程,只不过微软公司做成了一个界面,在 Node中是通过命令操作的,这就是 process 的定位。
- process 是全局变量,始终可供 Node.js 应用程序使用,使用时无需使用 require 引入。
全局变量其实就是全局对象 global 中的变量,写起来就是 global.process 。
使用Node.js的核心模块,一般来说需要用require关键字先引入这个模块,然后才能使用这个模块,前面学到的 global、console,还有现在的 process 都是全局变量,所以不需要引入;但是后面要学习的,比如 fs 就需要引入。
process 用的时候可以写引入,也可以不写,因为它是全局变量 - 官方文档:http://nodejs.cn/api/process.html
//process是全局变量,使用时无需用require引入
const process = require('process');
process的属性
//输出 node 版本
console.log(process.version);
//输出操作系统架构(操作系统是 64 位的还是 32 位的)
console.log(process.arch);
//输出操作系统平台
console.log(process.platform);
运行结果:
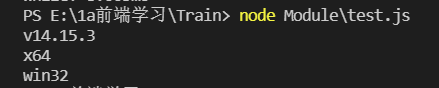
process的方法
上面三个输出的都是属性,因为后面都没有小括号,下面验证一个方法:
//获取当前工作目录,即当前文件所在的目录 cwd = current working directory
console.log(process.cwd());
运行结果:E:\1a前端学习\Train
环境变量
环境变量包含当前操作系统的一些信息。
//环境变量 env是environment的缩写
console.log(process.env);
环境变量除了有上面输出的默认信息外,还可以自定义环境变量:
//自定义环境变量
process.env.NODE_ENV = 'develop';
console.log(process.env);
这里的 NODE_ENV 的值是随便写的,在以后的学习中 NODE_ENV 会经常遇到,NODE_ENV 用来标识当前开发环境,当前是线上环境还是开发环境,可以用 NODE_ENV 做一个标识。
进程控制
获取进程编号
要想操作某个进程首先要获取到这个进程,进程的获取依靠属性 pid ,即进程编号,进程的编号具有唯一性,操作系统通过进程编号来区分进程。pid只能在进程运行期间拿到,进程未开始或已结束都无法拿到pid,每次开启一个进程时,编号都会重置,编号是随机的。其实每次执行一次js代码都相当于创建了一个新的进程,第二次执行时第一次的进程就结束了,所以每次运行获取到的pid都是不一样的。
//获取进程的编号()
console.log(process.pid);
pid 也可以在任务管理器的详细信息栏看到,这是微软提供的一个可视化页面。
杀死进程
//杀死进程
process.kill(进程编号);
process.kill(进程编号)杀死进程就相当于在任务管理器右键任务的“结束任务”。
3. 核心模块 - path
- path,路径,path 模块提供了有关路径操作的函数
当前目录 ./
上一级目录 …/ - 使用之前,需要通过 require 引入
- 官方文档:http://nodejs.cn/api/path.html
引入 path
//引入 path
const path = require('path');
const,声明常量,为什么声明常量?因为不希望有人再去更改,常量一旦声明就不能修改;const path 中的 path 一般与模块名称一致,这是一个约定俗成的规定,当然可以写成其他的比如 p ,然后用 p 去访问里面的方法,但是为了后续使用方便一般还是写成 path。后面的require是关键字,主要不要拼写错误即可,括号里面的是字符串,注意不要忘记单引号,单引号内部是模块名。
获取文件路径
path 提供了有关路径操作的函数,那么在写具体的函数之前,必须先拿到一个路径。前面在学习 process 时可以用console.log(process.cwd());得到文件路径,现在提供一个简单的写法:两个下划线加dirname,即console.log(__dirname);,这两种方式得到的结果相同。如果想要获取当前文件的完整路径,即包括文件名的路径,可以用 console.log(__filename);。
//引入 path
const path = require('path');
//获取当前文件所在的路径
console.log(process.cwd());
console.log(__dirname);//dir = directory 目录
//获取当前文件的完整路径
console.log(__filename);
运行结果:

获取文件扩展名
//引入 path
const path = require('path');
//获取当前文件的完整路径
console.log(__filename);
//获取文件扩展名 ext = extension
console.log(path.extname(__filename));
运行结果:

获取文件路径中的目录部分
//引入 path
const path = require('path');
//获取当前文件的完整路径
console.log(__filename);
//获取文件路径中的目录部分
console.log(path.dirname(__filename));
运行结果:

获取文件路径中的文件名
//引入 path
const path = require('path');
//获取当前文件的完整路径
console.log(__filename);
//获取文件路径中的目录部分
console.log(path.basename(__filename));
运行结果:

path.jion( )函数
join,合并,join()函数的作用就是合并路径。
//引入 path
const path = require('path');
//获取当前文件的完整路径
console.log(__filename);
//获取文件路径中的目录部分
console.log(path.dirname(__filename));
console.log(__dirname);//这两种方式结果相同
//join函数合并路径
const t = path.join(__dirname,'..');//输出dirname的上一级
console.log(t);
const a = path.join('D:/','a','b','c.jpg');//输出D:\a\b\c.jpg
console.log(a);
运行结果:

4. 核心模块 - fs
- fs,file system,文件系统,提供了大量文件操作的 API。
文件操作又分为两部分:
文件操作:指普通文件,比如 .js 文件,.txt 文件等,这样的文件我可以往里面写内容。
目录操作:目录其实就是文件夹,只不过我们平时使用时叫文件夹但是在程序的世界里称之为目录,目录操作比如可以创建一个目录,删除一个目录,可以重命名一个目录,还可以判断某一个目录是否存在,等等。 - 使用之前,需要通过 require 引入
- 官方文档:http://nodejs.cn/api/fs.html
- 为了方便接下来的演示,在VS Code编辑器中,在 Module 文件夹下建立 fs 文件夹,fs 文件夹下新建两个文件夹,一个是演示文件操作的 file 文件夹;另一个是演示目录操作的 dir 文件夹。
文件操作
在 fs 文件夹下的 file 文件夹中新建各个 js 文件来演示 fs 文件操作部分的内容。
文件的写操作
文件的写操作用 fs.writeFile( ) 函数,其中有三个参数:第一个参数是文件路径,即往哪一个文件里写东西,第二个参数是写入的内容,第三个参数是回调函数,即:
fs.writeFile(‘文件路径’,‘写入内容’,回调函数);
//引入fs
const fs = require('fs');
//文件的写操作
//fs.writeFile('文件路径','写入内容',回调函数);
fs.writeFile('./1.txt','有一首歌',(err)=>{
if (err) throw err
console.log('写入成功');
})
前面已经学过,./表示当前路径,那么 ./1.txt 即表示当前路径下的 1.txt 文件;回调函数部分采用箭头函数的形式,回调函数有一个参数 err,即 error 的缩写,就是报错。一般来说,写文件的过程中可能会遇到报错,所以 fs 中封装了一个 err ,里面包含可能出现的一些报错,可以在函数中用 if 语句判断一下有无报错,如果有报错,利用 throw 关键字抛出报错。报错有很多种,比如写文件时没有写权限,只能读不能写,那么就可能会有一个报错“没有权限”。如果没有写if 语句判断报错,有了报错也不会知道,写了的话有了报错就会提示,有利于编程。最后,如果没有报错,那么 console.log 输出一个提示消息即可。
注意写入文件的路径,代码中是 ./1.txt 表示当前目录下新建文件 1.txt,这里的当前目录是什么?是运行时的当前目录,下面图中运行时的目录是 E:\1a前端学习\Train> ,所以运行后 1.txt 文件会新建在 E:\1a前端学习\Train> 目录下。

下图中运行前先 cd .\Module\fs\file\ 进入了 file 文件夹的路径,所以 1.txt 文件会新建在 file 文件夹:

文件的读操作
文件的读操作用 fs.readFile(‘文件路径’,回调函数) 函数。要读取的文件的路径可以用前面学习的方法取到,可以用 __dirname + ‘/1.txt’ ,注意是左斜杠,也可以用 path.join(__dirname,‘1.txt’),两种方式结果相同 ,但是注意使用 path 时记得引入 path 模块;回调函数依然采用箭头函数的形式,但是参数与写操作函数的参数不太一样,读操作回调函数共两个参数,第一个是 err 与写操作相同,第二个参数是 data ,表示读到的数据。

可以看到,输出的 data 数据并不是我们想看到的,这是因为 data 是二进制数据。但是二进制数据,为什么不是只有 0 和 1 呢?这是因为:data 是二进制数据,默认输出时以十六进制的方式展示,以二进制方式存储。
如果想看到正常数据,可以采用前面学的 toString( ) 函数,toString( ) 函数是将变量转成字符串。
//引入 fs 模块
const fs = require('fs');
const path = require('path');
//文件的读操作
//指定目标文件所在的路径(复习一下前面学的)
//var filename = __dirname + '/1.txt';
var filename = path.join(__dirname,'1.txt');//两种方式结果相同
//语法:fs.readFile('文件路径',回调函数)
fs.readFile(filename,(err,data)=>{
if (err) throw err
console.log(data.toString());//没有错误则输出读到的内容
})
运行结果:

删除文件
删除文件,这里不用 delete ,这里用 unlink。删除文件的语法:fs.unlink(‘文件路径’,回调函数)。
//引入 fs 模块
const fs =require('fs');
//删除文件
//语法:fs.unlink('文件路径',回调函数)
fs.unlink(__dirname + '/1.txt',(err) => {
if (err) throw err
console.log('删除成功');
})
运行结果:

注意:相同的删除操作,只能执行一次,删除成功后再执行一次会报错,也就是会 throw 抛出 err 错误信息:no such file or directory,没有这样的文件或目录。
追加写入
如果已经将文件删除,那么再读取文件时会报错,所以此时就会想再创建一个文件。前面的 fs.write( )写文件的方式有些不足,因为它是清空写入,不管执行多少次 node Module\fs\file\write.js 在 1.txt文件中都只能看到一句话,而不是执行几次看到几句相同的话,这就是清空写入,这种方式会在写之前将文件中原来的内容去掉,但是一般来说,我们想写想的是在文件原有内容后面继续写,而不是每次写的时候都将原来的内容清空。所以,就有了一种新的写入方式——追加写入。
追加写入 append 方式与前面的清空写入 write 方式的语法类似,只是执行效果不同:
fs.appendFile(‘文件路径’,‘写入内容’,回调函数)
//引入 fs 模块
const fs = require('fs');
//追加写入
//语法类似于前面的清空写入:fs.appendFile('文件路径','写入内容',回调函数)
fs.appendFile(__dirname + '/2.txt','还有一首歌\n',(err) => {
if (err) throw err
console.log('追加写入成功');
})
两个注意的点:
- 第一个,第一个参数部分 __dirname + ‘/2.txt’ 如果 2.txt 前面的 / 没有的话,新建的文件名字就不是 2.txt,而是 file2.txt 。
- 第二个,如果写入内容部分后面的 \n 没有的话,多次执行写入内容不会换行。\n 的n就是 newline 即新的一行。

追加写入的用处很多,像这样需要在原有内容后面继续写的时候可以用追加写入;还有很多其他用法,比如有一个数组,想要将数组中的内容分别读出来,然后用追加写入的方式写到文件中且有换行效果,可以采用循环比如 for 循环,每次循环取出数组中一个数据,且将 append 放在循环里,拿出一个写入一个。
目录操作
目录即文件夹。
在 fs 文件夹下的 dir 文件夹中新建各个 js 文件来演示 fs 目录操作部分的内容。
创建目录
创建目录用 mkdir ,mk即make,即 fs.mkdir ( ),共有两个参数:第一个参数是目录路径,即将创建的目录放在哪里;第二个参数是回调函数,回调函数中只有一个参数 err 。
在当前目录下创建名字为 d1 的目录,当前目录即 ./,当前目录下的 d1 即./d1 :
//引入 fs 模块
const fs = require('fs');
//创建目录(文件夹)
//语法:fs.mkdir('目录路径',回调函数)
fs.mkdir('./d1',(err) => {
if (err) throw err
console.log('创建目录成功');
})
运行结果:

删除目录
删除目录用 rmdir ,rm 即 remove,即 fs.rmdir ( ),参数部分与 mkdir 相同。
删除当前路径下的 d1 目录:
//引入 fs 模块
const fs = require('fs');
//删除目录(文件夹)
//语法:fs.rmdir('目录路径',回调函数)
fs.rmdir('./d1',(err) => {
if (err) throw err
c
运行结果:

注意:rmdir 只能删除空目录,如果目录中有东西就不能删除成功,报错:directory not empty。
删除非空目录可以分两步:
第一步:先用 unlink 删除目录下的普通文件(清空目录)
第二步:用 rmdir 删除空目录
重命名目录
重命名目录用rename,语法:fs.rename(旧名称,新名称,回调函数)。
注意:指定旧名称时需要指定一个完整的路径,路径不完整的话找不到目录,fs.rename会自动的把整个目录的最后一个目录做重命名。
//引入 fs 模块
const fs = require('fs');
//重命名目录(文件夹)
//语法:fs.rename(旧名称,新名称,回调函数)
fs.rename(__dirname + '/d1',__dirname + '/d2',(err) => {
if (err) throw err
console.log('重命名目录成功');
})
运行结果:

rename 对目录做重命名时,对目录是否为空没有要求,不管目录是否为空都可以重命名。
读取目录
读取目录用 readdir,语法:fs.readdir(‘目录路径’,回调函数)。
//引入 fs 模块
const fs = require('fs');
//读目录(文件夹)
//语法:fs.readdir('目录路径',回调函数)
fs.readdir(__dirname,(err,data) => {
if (err) throw err
console.log(data);//以数组形式输出目录下各文件或文件夹的名称
//遍历输出
data.map((d) => {
console.log(d);
})
})
运行结果:

只是遍历输出还是有一个不足之处,读取到的目录无法区分文件夹和普通文件。左边可视化目录部分,dir 目录中,有文件夹 d2 ,其他都是普通文件,而文件夹与普通文件是可以区分开的,因为 d2 右边有个小三角表示是文件夹。
针对上述不足,fs 中有一个统计的 API ,可以判断当前内容是文件还是目录,**fs.stat( )**函数,第一个参数是一个完整路径,这个完整路径一定要写正确,否则找不到文件;第二个参数是回调函数。
//引入 fs 模块
const fs = require('fs');
//读目录(文件夹)
//语法:fs.readdir('目录路径',回调函数)
fs.readdir(__dirname,(err,data) => {
if (err) throw err
//遍历加判断输出
data.map((d) => {
fs.stat(__dirname + '/' + d, (err,stat) => {
if (stat.isDirectory()){
//判断当前内容是否是目录
console.log('目录:',d);
}else if (stat.isFile()){
//判断当前内容是否是普通文件
console.log('文件:',d);
}
})
})
})
运行结果:

fs – 同步函数 ( synchronization )
上面学习了 fs 中的文件操作和目录操作,也学习了相应的函数,比如文件操作中的 writeFile、readFile、appendFile等;目录操作中的 mkdir、rmdir、readdir 等,这些函数其实都是异步函数。在官方文档中还可以找到相应的同步函数,比如与 writeFile 对应的 writeFileSync,与 readFile 对应的 readFileSync,等。这里的 Sync 这是什么意思?这里的 Sync 其实就是同步的英文单词,上面那些以 Sync 为后缀的就是同步函数,之前学习的没有 Sync 后缀的那些就是异步函数。

说到同步函数和异步函数,就要说起JS代码的执行方式:主程序中的任务是阻塞式的,如果任务 1 没有执行完,后面的任务 2 3 4 都不能执行,这也就是 JS 的单线程,同步执行;异步执行就是在事件队列中执行一些操作。例如,任务 1 有两个子任务 1.1 和 1.2 ,1.1 是读文件,1.2 是写文件,现在操作的文件很大比如有10G,那么很明显 1.1 和 1.2 这两个子任务会花费很长时间,如果以同步的方式,那么后面的任务 2 3 4 就只能等待,然而如果用异步方式,也就是把 1.1 和 1.2 抛到事件队列当中执行,那么就不需要等待了,这样的话任务 1 就相当于瘦身了,任务 1 只需要很少时间执行就可以继续执行任务 2 3 4 了。上述就是同步函数和异步函数的执行原理。

- 同步函数
在主程序中自上而下运行
例如:去火车站排队买票(期间只能等待买票,不能做其他事) - 异步函数
通过回调函数在事件队列中运行
例如:委托黄牛买票,票买好后通知我(无需等待,期间可以做其他事)
什么时候同步函数?什么时候执行异步函数?如果考虑性能,一般来讲是执行异步函数的,但是,如果任务有先后顺序的话,那么就可以用同步函数来实现。比如,要删除一个文件,必须要先确认这个文件存在,这就存在着先后顺序,就可以用同步函数实现。
//引入 fs 模块
const fs = require('fs');
//先判断文件是否存在
if (fs.existsSync(__dirname + '/1.txt')) {
//然后,如果文件存在的话,再执行删除
fs.unlinkSync(__dirname + '/1.txt');
}else {
console.log('文件不存在');
}
像上面例子一样,其实 fs 的大多数函数都分同步和异步,同步函数与异步函数使用方式类似,只是原理不同,一般异步函数才有回调函数,同步函数没有回调函数。
fs – 实现文件复制和压缩
所谓文件复制,其实就是将文件从一个位置复制放到另外一个位置,例如要将 src 目录下的 style.css 文件,复制到 dist 目录下,即 src/style.css ——> dist/style.css ,这时就可以思考可以用哪些学过的函数。文件复制本身是没有学过的,但是学过文件的读取和写入,那么就可以先将文件的内容读出来,然后写到新的位置。当然,读取文件之前,还要知道文件所在位置,就可以用之前学过的 path 模块获取文件的位置;另外,在执行复制时,要将文件复制到的 dist 目录是否存在,如果这个目录存在,那么直接写入即可,但是如果目录不存在,还需要去创建目录,那么之前学到的 mkdir 就可以派上用场。

下面在程序中演示:
文件复制
//引入 fs 模块和 path 模块
const fs = require('fs');
const path = require('path');
//目标:将 src/style.css 复制到 dist 目录下
const dist = path.join(__dirname,'dist');
//读取文件内容
fs.readFile('./src/style.css',(err,data) => {
if (err) {
throw err
}else{
console.log(data.toString());//测试读文件是否成功
//确保目标目录是否存在,如果不存在要创建目录
if( !fs.existsSync(dist)){//没有exists函数了,官方文档中已经废弃了,只能用existsSync
fs.mkdirSync(dist);//没有目录后面什么都做不了,所以用同步函数
}
//将读取到的内容,写入目标文件
fs.writeFile(dist+'/style.css',data.toString(),(err) => {
if (err) throw err
console.log('成功');
})
}
})
注意:在写文件之前,要确保目标是否存在,如果目标文件不存在,fs.writeFile 可以自动帮我们创建文件;但是如果目标目录不存在,fs.writeFile 不能自动帮我们创建目录。所以,在执行写文件之前,先判断目标目录是否存在,如果不存在的话,要先创建目录。
运行结果:

文件压缩
除此之外,还可以对文件进行压缩,所谓压缩,其实就是将文件中没有用的注释、空格等去掉,压缩后文件体积更小,上线之后页面加载就会更快。要执行压缩,就需要用到前面学过的 正则表达式 。

replace 替换函数,两个参数:第一个参数是要查找的内容,第二个参数是要替换的内容。
处理空格时,最好用 \s 表示,如果用 ’ ’ 来表示,只能表示一个空格,如果有多个空格就无法表示,所以要用正则。首先是正则的声明,两个反斜线,在正则里面叫定界符,中间 \s 表示匹配空格,s 即 space ,匹配多少个空格呢,然后在写一个 + ,这个 + 是正则当中的量词,表示匹配一个到多个,+ 修饰的是其左侧的内容,所以 replace(/\s+/) 就表示查找一个或多个空格。还有一个点不要忘记,在 JS 中正则默认的是懒惰模式,如果想让他做全局匹配的话,还有一个修饰符,g ,g就是 global ,表示可以做全局匹配。replace 第二个参数是要替换的内容,将空格替换成空字符,所以第二个参数是 ‘’。所以,目前代码为 data.toString().replace(/\s+/g,’’)。
接下来处理注释。注释是在 /* */ 中的,里面是注释的内容。所以,先匹配出注释的边界,也就是 /* 和*/ 。同样,replace函数中,首先写正则的定界符 / /,在正则的里面如果要匹配斜线的话是需要转义的,就是 \/ ,这样就实现了将 / 转义。同样的,* 也需要转义,因为 * 在正则中是一个量词,默认匹配零到多,所以用 \* 来转义 * 。所以最终,转义注释的边界的代码是 replace(//**//) 。边界匹配完成,然后看注释的内容,注释开始时,可能写的 /*,也可能写的 /**,可能一个 * 也可能两个 * ,所以 * 后面加量词,{1,2} ,即匹配 * 一次或匹配 * 两次。注释内容再往后可能是空格也可能是其他内容,所以写一个 [ ],如果是空格那就是 \s ,如果是其他内容也就是非空格那就用 \S 来匹配,这些内容有可能有也有可能没有,所以在[\s\S ] 后面写一个 * ,这个 * 是用来修饰 [ ] 的,* 匹配零到多次。同样的,正则有可能有一个也有可能有多个,所以要全局匹配,要加修饰符 g 。再加上 replace 的第二个参数 ‘’ 。所以,处理注释的代码: replace(//*{1,2}[\s\S]**//g,’’) 。
文件压缩完成后,习惯上,将压缩后的 style.css 改名为 style.min.css ,所以就可以将 fs.writeFile函数的第一个参数修改为 dist+’/style.min.css’ ,或者用 rename 函数改名字。
//引入 fs 模块和 path 模块
const fs = require('fs');
const path = require('path');
//目标:将 src/style.css 复制到 dist 目录下
const dist = path.join(__dirname,'dist');
//读取文件内容
fs.readFile('./src/style.css',(err,data) => {
if (err) {
throw err
}else{
console.log(data.toString());//测试读文件是否成功
//确保目标目录是否存在,如果不存在要创建目录
if( !fs.existsSync(dist)){//没有exists函数了,官方文档中已经废弃了,只能用existsSync
fs.mkdirSync(dist);//没有目录后面什么都做不了,所以用同步函数
}
//对文件进行压缩,将无用的注释或空格去掉\
var mydata = data.toString().replace(/\s+/g,'').replace(/\/\*{1,2}[\s\S]*\*\//g,'');
//将读取到的内容,写入目标文件
fs.writeFile(dist+'/style.min.css',mydata,(err) => {
if (err) throw err
console.log('成功');
})
}
})
压缩完成:

其实,在以后工作中,文件的复制和压缩,都是有插件去实现的,不用自己手动敲代码实现,上述只是讲述一下原理,后面学到前端工程化时会学这样的一款专门的压缩工具。
文件操作的方式(原理)
上面学习了文件操作的相关函数,现在来学习文件操作的方式。所谓文件操作的方式,可以理解为文件操作的原理,主要指两个,一个是缓冲,一个是流。
文件操作 – 缓冲方式
缓冲方式原理:在做文件操作时,操作系统会先把原文件的内容加载到内存缓冲当中,然后再把数据从内存缓冲中调入目标文件,也就是说,文件操作需要借助内存缓冲。这种方式有一个明显的缺陷,就是必须要保证内存缓冲足够大,否则后续操作可能无法执行。执行方式:在原文件中拿到数据,先写到内存缓冲中,此时注意,如果只写了很少的一部分,操作系统是不会做下一步操作的,一直往里写,等到把内存缓冲填满之后,操作系统才会把内存缓冲中的数据调入到目标文件,这就是缓冲方式的执行逻辑。
文件操作 - 流方式
看下图,有 A B两个杯子,A 里面有数据,B 里面是空的,此时可以通过一个管道把 A 和 B 连接起来,那么 A 中的数据就可以流到 B 当中。在这个模型中, A 称之为读取流, B 称之为写入流,中间的就称之为管道。
流操作方式与缓冲操作方式比较的优势 / 为什么要选择流方式?
- 内存效率提高
无需加载大量数据
流把大数据切成小块,占用内存更少 - 时间效率提高
接获数据后立即开始处理
无需等到内存缓冲填满
比如取水,缓冲方式就相当于用水桶挑水,要考虑水桶够不够大,一桶不够还有挑两桶三桶四桶等;而流方式就相当于水龙头,只要打开谁就可以流出来。
流的操作函数
流的概念不是 Node.js 中独有的,其他的编程语言中也有流相关的概念。实际上流是操作系统里面的概念,但是 Node.js 中也有流相关的操作函数。
实现将 file2.txt 文件中的内容复制到 file_stream.txt 文件中,如果目标文件不存在 fs 也会自动创建:
第一步:创建读取流,创建读取流的函数是 fs 下面的 createReadStream( ) 函数,里面的参数就是要读的文件的路径。
第二步:创建写入流,创建写入流的函数是 fs 下面的 createWriteStream( ) 函数,里面的参数就是要写入的文件的路径,也就是目标路径。
第三步:把读取流通过管道传给写入流 ,利用 readStream 的 pipe( )函数,pipe 就是管道的意思。
//引入 fs 模块
const fs = require('fs');
//第一步:创建读取流
var readStream = fs.createReadStream('./file2.txt');//当前路径下的 file2.txt 文件
//第二步:创建写入流
var writeStream = fs.createWriteStream('./file_stream.txt');
//放在当前路径下的 file_stream.txt 文件中
//第三步:把读取流通过管道传给写入流
readStream.pipe(writeStream);
运行结果:

这样就比前面的方式要简洁很多,前面还要写 readFile,还要写 writeFile,还要写回调函数等,而这样使用流的方式就比较简洁。
5. 核心模块 - http
- http 模块可以发布 web 服务
所谓发布 Web 服务,就是写了一段代码,想要在浏览器上看效果,那么一般可以在浏览器输入一段域名,就可以呈现页面,这就是 Web 服务的效果。
之前如果我们想实现这样一个效果的话,可能需要借助 Apache 、 Nginx 这种专业的服务软件才能做到。但是,在 Node.js 中,http 模块就可以实现。 - 使用之前,通过 require 引入
- 官方文档:http://nodejs.cn/api/http.html
示例:
第一步:创建服务器
使用 http 模块的 createServer( ) 函数创建服务器,这个函数中有一个回调函数,回调函数有两个参数,一个是 req ,第二个是 res,req 和 res 其实是两个对象,req 就是 request ,请求,res 就是 response ,响应,这是 http 请求中的两个关键步骤,比如想去访问一个网站,首先需要指定一个网址,这其实就是一个请求,访问网址输入完之后会找到响应的服务器,服务器准备好数据就返回回来,这个过程就是响应。所以,一个完整的服务器就包含这两个内容,在 Node.js 中,具体来说就是在 http 中,将这两个内容都封装成了对象,一个是请求对象,一个是响应对象,这就是 req 和 res。
在回调函数内部,先随便写点东西,比如,res.statusCode 设置响应编码,如果成功则响应 200 ;另外,还可以设置头 res.setHeader ,头其实就是一些元数据,就是一些基本数据,可以约定响应数据的类型,浏览器可以呈现很多信息比如文本信息、图片、视频等,对于不同类型的数据处理方式不一样,所以需要在 res.setHeader( )里面指定,比如写 res.setHeader(‘Content-Type’,‘text/plain’) ,plain就是普通的,表示最终返回一些普通的文本信息,charset = utf-8 指定字符集,否则会出现乱码。然后就可以结束了,res.end( ),结束时可以发送“你好:Node.js”,即 res.end(‘你好:Node.js’) 。
第二步:发布 Web 服务
发布 Web 服务时用 server.listen( ) 方法,listen 监听,监听什么呢?监听端口号 port ,主机名(域名) host ,然后是回调函数。
//引入 http 模块
const http = require('http');
//第一步:创建服务器
const server = http.createServer((req,res) => {
res.statusCode = 200;
res.setHeader('Content-Type','text/plain; charset=utf-8');
res.end('你好:Node.js');
})
//第二步:发布 Web 服务
const port = 3000;
const host = 'localhost'//本机域名
//在浏览器中访问 http://localhost:3000即可看到效果
server.listen(port,host,() => {
console.log(`服务器运行在 http://${host}:${port}`);
//ES6的新语法,模板字符串,两边用反引号将字符串括起来(英文输入法下键盘顶部1左边的按键)
})
编辑器中和浏览器中运行结果:

















 292
292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









