






目录
Zookeeper
1.Zookeeper介绍
ZooKeeper是一个分布式的,开放源码的分布式应用程序协调服务,是Google的Chubby一个开源的实现,是Hadoop和Hbase的重要组件。它是一个为分布式应用提供一致性服务的软件,提供的功能包括:配置维护、域名服务、分布式同步、组服务等。
ZooKeeper的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效、功能稳定的系统提供给用户。
ZooKeeper包含一个简单的原语集,提供Java和C的接口。
ZooKeeper代码版本中,提供了分布式独享锁、选举、队列的接口,代码在zookeeper-3.4.3\src\recipes。其中分布锁和队列有Java和C两个版本,选举只有Java版本。
总结:Zookeeper负责服务的协调调度.当客户端发起请求时,返回正确的服务器地址
2.zookeeper下载
网址:http://zookeeper.apache.org/releases.html

下载路径,点击download

下载Zookeeper地址:http://mirrors.hust.edu.cn/apache/zookeeper/

3.安装(zookeeper要用到jdk要提前安装jdk)
1):上传zookeeper安装文件.之后解压
tar -xvf apache-zookeeper-3.6.0-bin.tar.gz
2):修改文件名称为zookeeper
3):启动测试
1.进入zookeeper文件创建zkCluster文件
2.在zkCluster下创建 data和log文件
3.在zk1,data文件中创建myid文件写数字 1

4.进入zookeeper的conf目录 复制配置文件并重命名

单台zookeeper服务配置
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
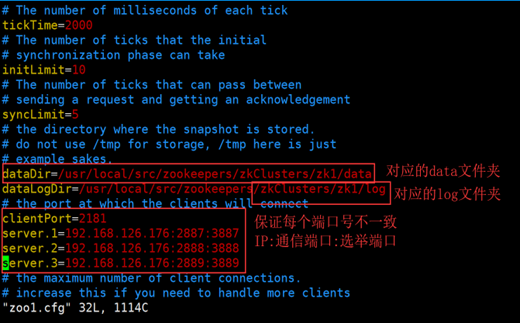
dataDir=/usr/local/src/zookeeper/zkCluster/zk1/data
dataLogDir=/usr/local/src/zookeeper/zkCluster/zk1/log
# the port at which the clients will connect
clientPort=2181
server.1=192.168.50.76:2887:3887
# the maximum number of client connections.
# increase this if you need to handle more clients
#maxClientCnxns=60
#
# Be sure to read the maintenance section of the
# administrator guide before turning on autopurge.
#
# http://zookeeper.apache.org/doc/current/zookeeperAdmin.html#sc_maintenance
#
# The number of snapshots to retain in dataDir
#autopurge.snapRetainCount=3
# Purge task interval in hours
# Set to "0" to disable auto purge feature
#autopurge.purgeInterval=1
## Metrics Providers
#
# https://prometheus.io Metrics Exporter
#metricsProvider.className=org.apache.zookeeper.metrics.prometheus.PrometheusMetricsProvider
#metricsProvider.httpPort=7000
#metricsProvider.exportJvmInfo=true
服务常用指令:
sh zkServer.sh start zoo1.cfg 启动
sh zkServer.sh stop zoo1.cfg 停止
sh zkServer.sh status zoo1.cfg 查看状态

4.配置zookeeper集群
4.1): 进入zkCluster,创建zk1 zk2 zk3


4.2):在zk1 zk2 zk3创建data和log文件
mkdir {zk1,zk2,zk3}/{data,log} (查看文件可以简写 ls zk1不用进入zk1)

4.3):在zk1 zk2 zk3,data文件中创建myid文件
zk1文件写1, zk2写2, zk3写3,主机服务宕机后,会根据id选主机,myid的最大值优先.

4.4):进入zookeeper的conf目录 复制配置文件并重命名
编写配置文件zoo1.cfg,zoo2.cfg,zoo3.cfg
clientPort在多个配置中不能相同
server属性 所有文件都要写成一样的
4.5):进入zookeeper的bin目录
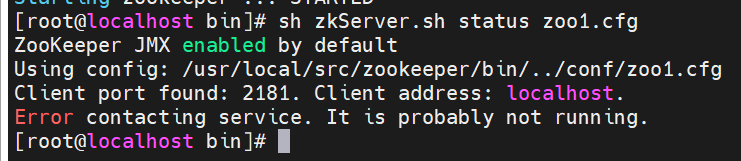
启动zookeeper服务并检测当前状态
启动第一个服务报错是正常的,因为一个不算集群
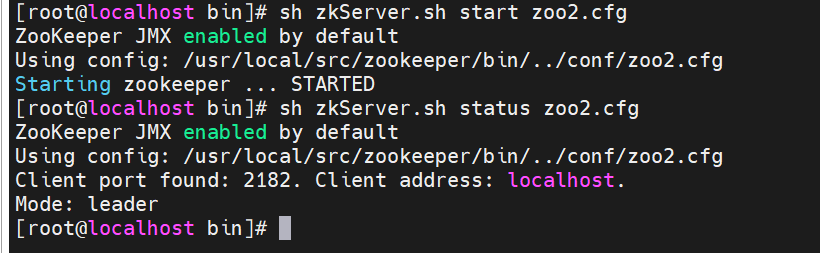
第二个就不会报错,但是第二台启动是 leader(领导),第一台是 follower(从)
启动第三台也是从

5.配置中出现错误,把对应的zk1/2/3文件下新生成的文件删除,再重新启动
5.1 执行 “jps” 显示当前运行的 zookeeper
6. 关于集群知识点说明
6.1 为什么集群最小单位3台
集群正常工作的公式: 存活的节点数量 > N/2 (2的分针)
讨论: 1个节点 1-1 > 1/2 不满足 1个节点不能搭建集群
2个节点 2-1 > 2/2 不满足 2个节点不能搭建集群
3个节点 3-1 > 3/2 满足 3个节点是搭建集群最小单位
集群宕机过半就不会继续工作
6.2 为什么集群一般都是奇数台
从容灾性的角度考虑问题:
3台服务器 3-1 > 3/2 宕机1台集群可以工作
4台服务器 4-1 > 4/2 宕机1台集群可以工作
说明: 由于奇数和偶数容灾性一样的,所以搭建奇数台更加合理.
6.3 ZK选举规则
说明: 1.myid的最大值优先.
2.超半数同意 当选主机.
案例1: 依次启动zk1,zk2,zk3 3台服务器.
案例2: 依次启动zk1-zk7
1).谁当主机? 4
2).谁永远当选不了主机 1 2 3














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









