







本文参照这位博主的文章https://blog.csdn.net/weixin_45754552/article/details/121019053,并亲自实操做的笔记。
一、前言
关于在IDEA中使用JavaAPI对Hadoop进行操作。
Hadoop中关于文件操作类基本上全部是在“org.apache.hadoop.fs”包中,这些API能够支持的操作包含:打开文件,读写文件,删除文件等。
1、文件在 Hadoop 中表示一个Path对象,通常封装一个URI,比如hdfs上的一个test文件,URI表示成hdfs://master:9870/test。Hadoop中的Configuration类的对象封装了客户端或者服务器的配置,每次开始一个对hdfs进行操作的Java程序都要进行的一步,可以使用该对象的一些方法来对文件进行操作。
比如:Configuration conf= new Configuration()
2、Hadoop中最终面向用户提供的接口类FileSystem,类的对象是文件系统对象,是个抽象类,只能通过类的 get 方法得到具体的类,可以用该对象的一些方法来对文件进行操作。
例:FileSystem fs = FileSystem.get(conf).
所以我们可以封装一个操作框架:
operator()
{
得到Configuration对象
得到FileSystem对象
对文件进行操作
}
- 上传文件
通过 “fs.copyFromLocalFile(Path src,Path dst)” 可将本地文件上传到HDFS指定的位置上,其中 src 和 dst 均为文件完整路径,但src是本地文件的路径,dst是在hdfs中存放文件的路径。
fs.copyFromLocalFile(new Path("D:\\java\\2.txt"),new Path("/test3"));
- 新建文件
通过 “fs.mkdirs(Path f)”可在 HDFS 上创建文件,其中 f为文件的完整路径。
fs.mkdirs(new Path("/test3"));
- 下载文件
通过“fs.copyToLocalFile(Path src, Path dst)”可在hdfs中下载文件。其中 src 为HDFS上的文件, dst为要下载到本地的文件名.
fs. copyToLocalFile(new Path("/hdfsfile"),new Path("D:\\java"));
- 删除文件
通过“ fs.delete(Path path, Boolean b)”可删除hdfs文件,其中 path 为要删除的文件。
fs.delete(new Path("/test"),true);
- 新建文件并写入数据
通过 “FileSystem.create(Path f, Boolean b)” 可在 HDFS 上创建文件,其中 f 为文件的完整路径, b 为判断是否覆盖。
Path dfs = new Path("/tmp/hdfsfile");
//创建新文件,如果有则覆盖(true)
FSDataOutputStream create = fs.create(dfs, true);
//向新创建的文件中写入数据
create.writeBytes("java2hdfs");
注意:
由于hdfs不支持并发写入,所以每次操作完都要关闭文件系统对象。
例: fs.close();
二、关于Windows环境下Hadoop环境变量配置
这一步我之前已经做好,此次不做过多记录,有兴趣的可以参照博主的文章。
三、创建Maven项目
关于Maven的安装和settings.xml的设置参照博主。我的已经弄好,此次不做记录。
pom.xml文件:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<artifactId>lzl</artifactId>
<groupId>com.lzl</groupId>
<version>1.0-SNAPSHOT</version>
</parent>
<modelVersion>4.0.0</modelVersion>
<artifactId>hadoop_client_3.2.3</artifactId>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.2.3</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-hdfs -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.2.3</version>
</dependency>
<!-- Junit是测试工具包,功能非常强大,无需把方法放入main函数中直接测试,就如示例代码中的@Test和@Before、@After等-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
<!--commons-logging:是apache最早提供的日志的门面接口。提供简单的日志实现以及日志解耦功能。
使用commons-logging能够灵活的选择使用那些日志方式,而且不需要修改源代码。-->
<dependency>
<groupId>commons-logging</groupId>
<artifactId>commons-logging</artifactId>
<version>1.2</version>
</dependency>
<!--log4j:Log4j是Java的一个日志工具,是Apache的一个开源项目,通过使用Log4j,
我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;
我们也可以控制每一条日志的输出格式;通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。-->
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
</dependencies>
</project>
log4j.properties:
hadoop.root.logger=DEBUG, console
log4j.rootLogger=INFO,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
四、代码测试:
package java.HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import java.io.IOException;
/**
* @author lzl
* @create 2022-10-08 18:46
* @name Demo01
*/
public class Demo01 {
public static void main(String[] args) throws IOException {
//1.创建配置文件
//封装了客户端或者服务器的配置
Configuration conf= new Configuration();
//在之前Linux系统中配置Hadoop时的core—site.xml文件中,有相关默认设置,用来指定我们要操作的文件系统hdfs
conf.set("fs.defaultFS","hdfs://cdh02:9870");
//指定用户名root
System.setProperty("HaDOOP_USER_NAME","root");
//2.获取文件系统对象
FileSystem fs = FileSystem.get(conf);
System.out.println(fs.toString());
}
}
运行结果:
链接master成功!

package test.HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
/**
* @author lzl
* @create 2022-10-08 19:26
* @name Demo03
*/
public class Demo03 {
//定义一个接口对象fs
private FileSystem fs;
@Before
public void before() throws IOException,InterruptedException{
System.setProperty("hadoop.home.dir", "D:\\hadoop\\hadoop-3.2.3");
//1.创建配置文件
Configuration conf = new Configuration();
fs = FileSystem.get(URI.create("hdfs://cdh02"),conf,"root"); //记住这里不能写端口号,否则会报错!
//测试
System.out.println("执行了before");
}
// //创建
// @Test
// public void mk() throws IOException {
// fs.mkdirs(new Path("/tmp/test/test2"));
// }
// //上传
// @Test
// public void put() throws IOException {
// fs.copyFromLocalFile(new Path("D:\\hadoop\\test\\test.txt"),new Path("/tmp/test"));
// }
//
// //重命名
// @Test
// public void rename() throws IOException {
// fs.rename(new Path("/tmp/test/test_1.txt"),new Path("/tmp/test/test_2.txt"));
// }
//
// //下载
// @Test
// public void get() throws IOException {
// fs. copyToLocalFile(new Path("/tmp/test/people.txt"),new Path("D:\\hadoop\\test"));
// }
//
// //删除
// @Test
// public void delete() throws IOException{
// fs.delete(new Path("/tmp/test/test_2.txt"),true);
// }
//
//新建文件并写入数据
//通过 "FileSystem.create(Path f, Boolean b)" 可在 HDFS 上创建文件,
// 其中 f 为文件的完整路径, b 为判断是否覆盖。
@Test
public void write() throws IOException{
//定义新文件
Path dfs = new Path("/tmp/test/new_test");
//创建新文件,如果有则覆盖(true)
FSDataOutputStream create = fs.create(dfs, true);
//向新创建的文件中写入数据
create.writeBytes("Hello,HDFS!");
}
@After
public void after() throws IOException{
System.out.println("执行了after");
fs.close();
}
}
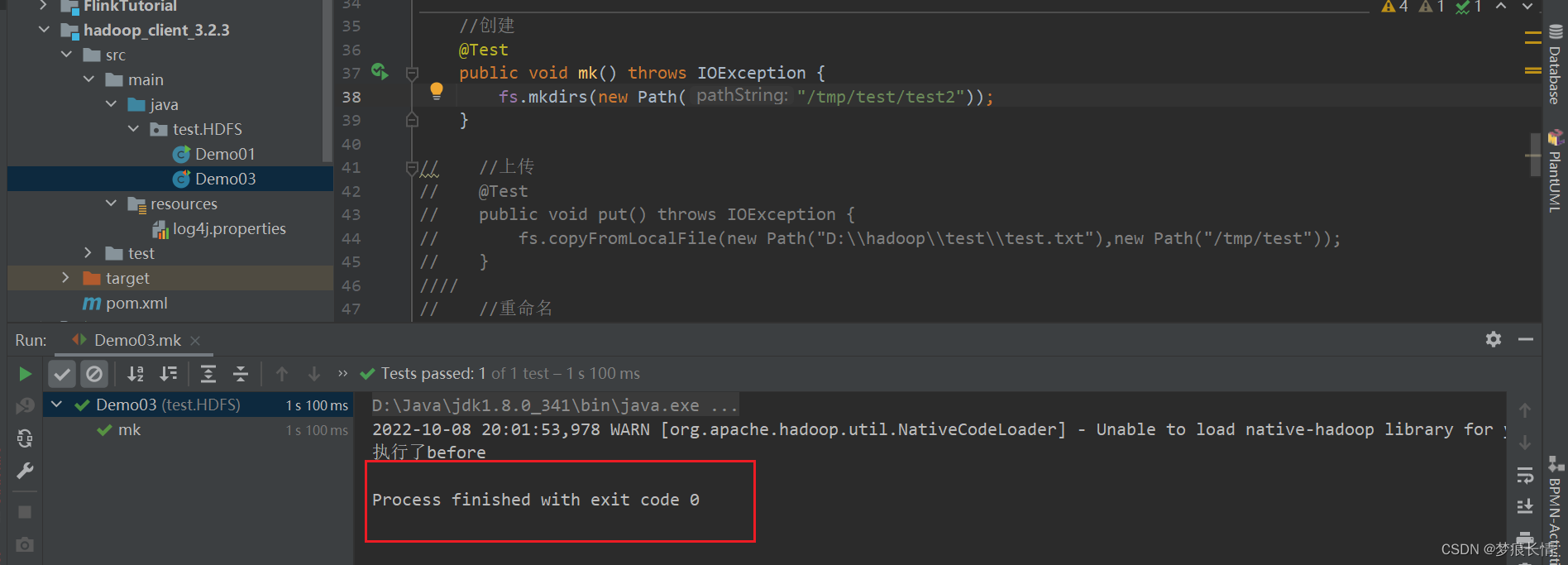
创建文件夹:
多了一个文件夹。
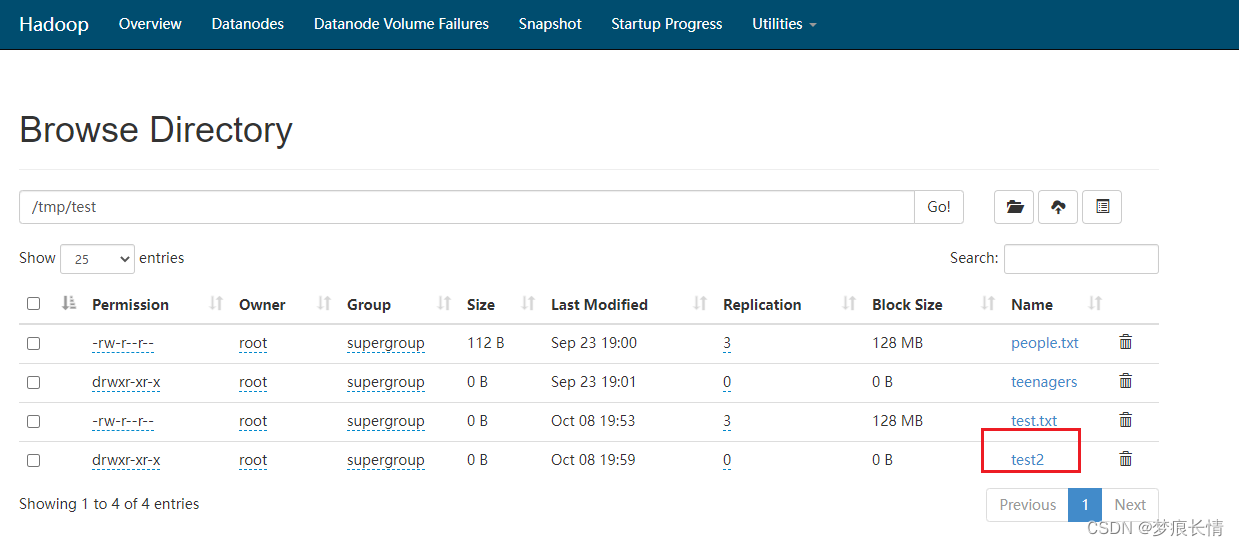
上传:
会有超时报错,但是文件已经上传成功!报错的解决方法在后面!
重命名:

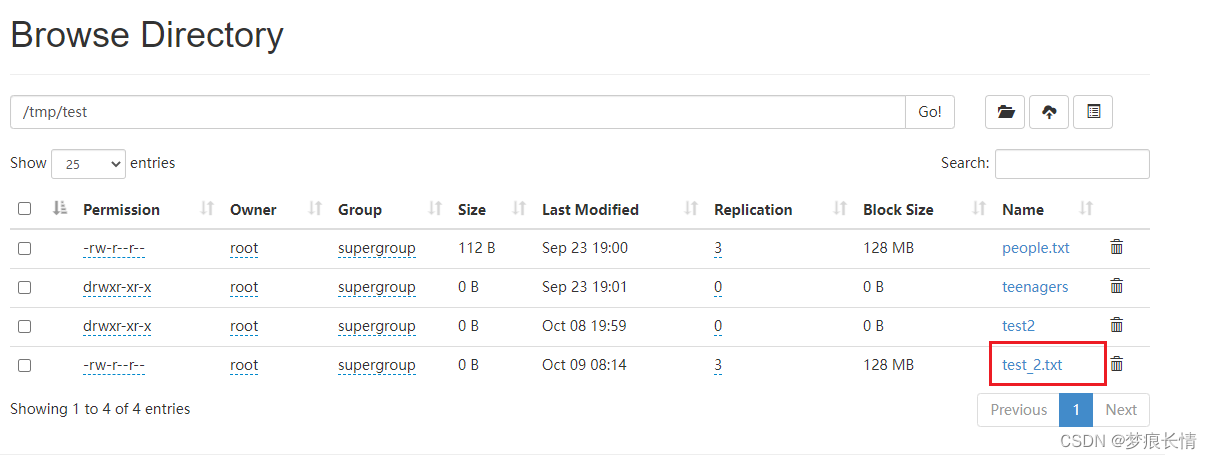
下载:
运行失败!虽然文件有下载下来了,但是里面的内容没下载来。报错的解决方法在后文!

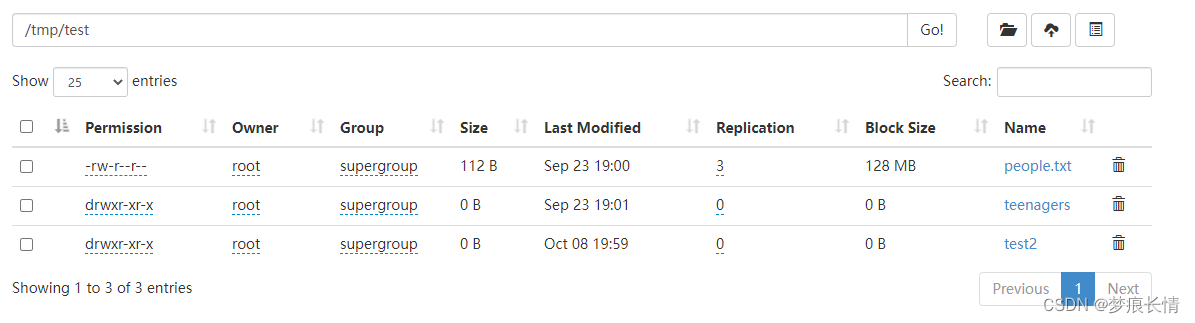
删除:
执行ok!删除成功!

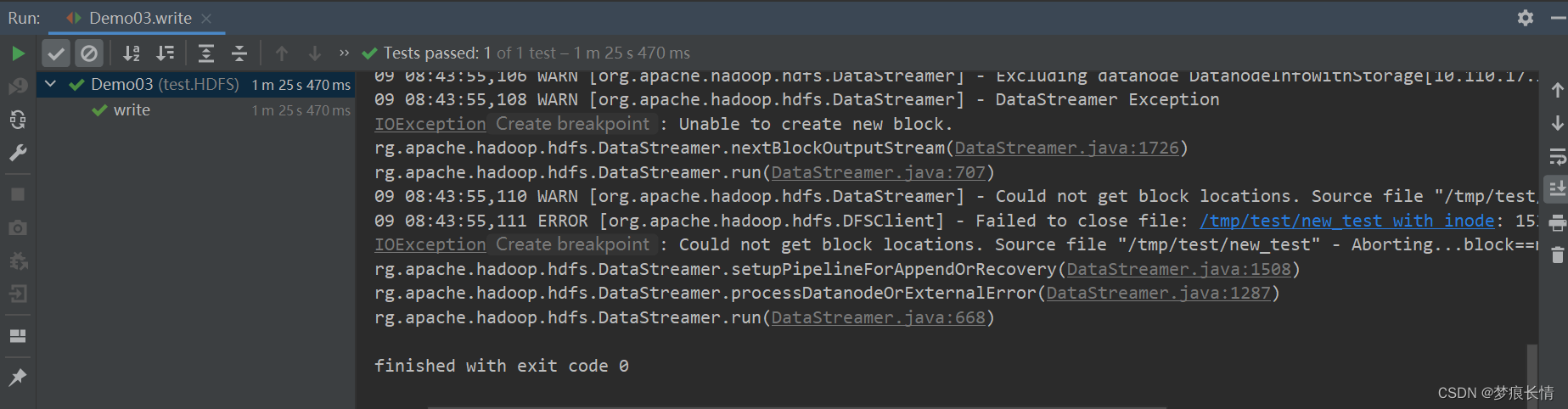
新建文件并写入数据:
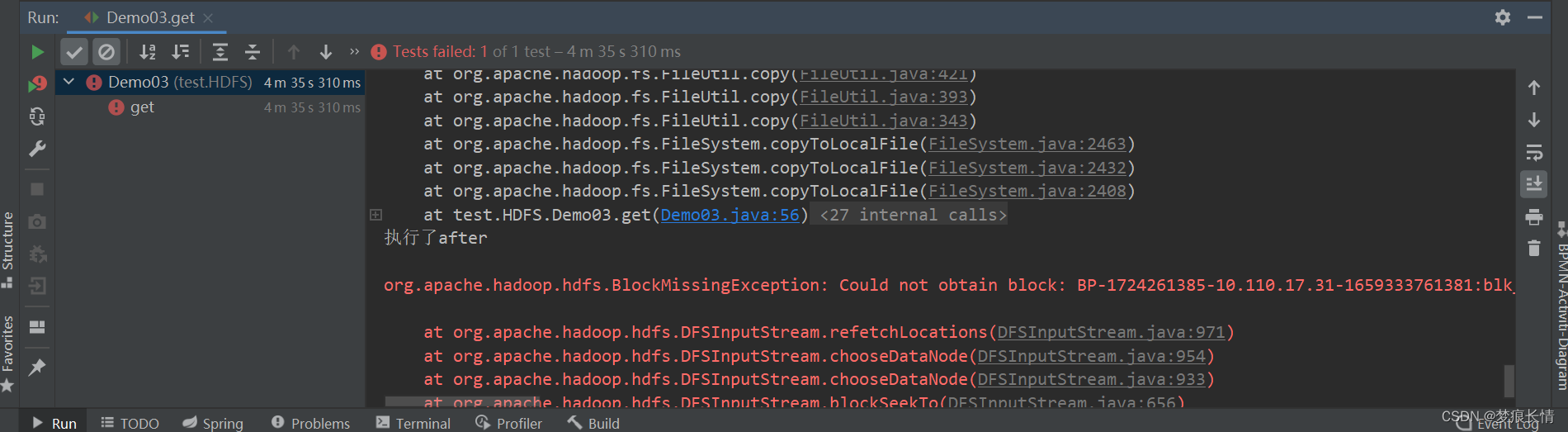
经过艰难的运行之后,虽然成功了。但是文件存储的块上有些问题。原因在下面。

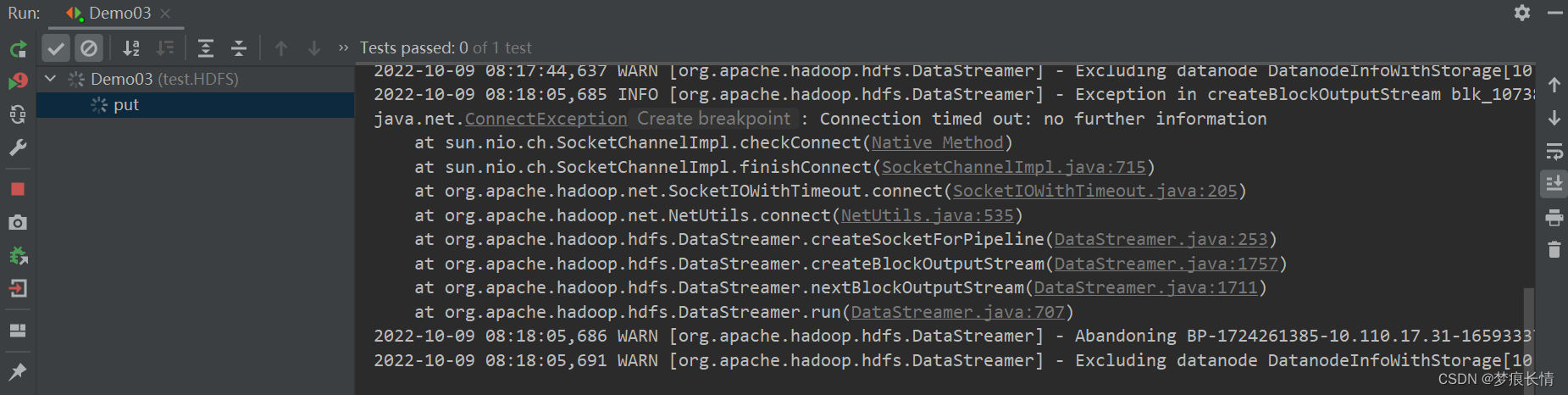
报错的现象一般是一些告警:
告警:Could not get block locations. Source file "/user/hive/warehouse/xxx…
HDFS-java.io.IOException: Unable to create new block.
Could not get block locations. Source file “/tmp/test/sgd_test.txt” - Aborting…blocknull

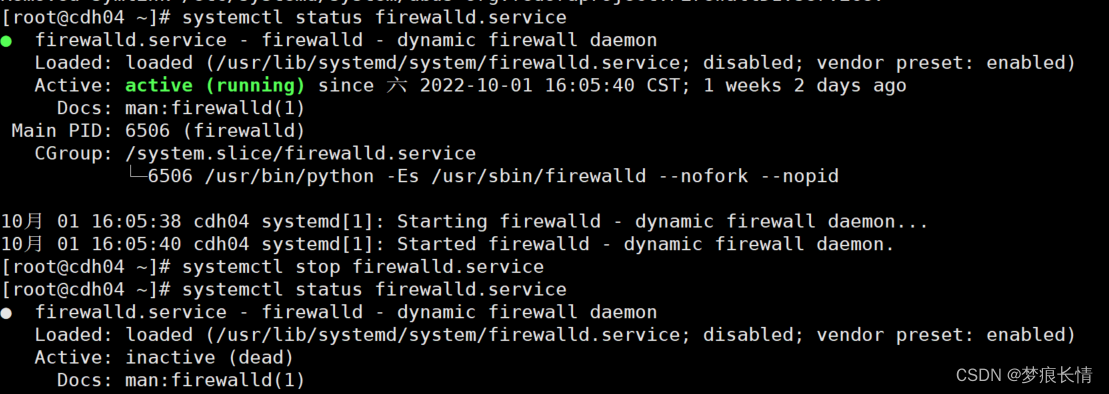
原因是:因为服务器的防火墙没关闭!泪呀!
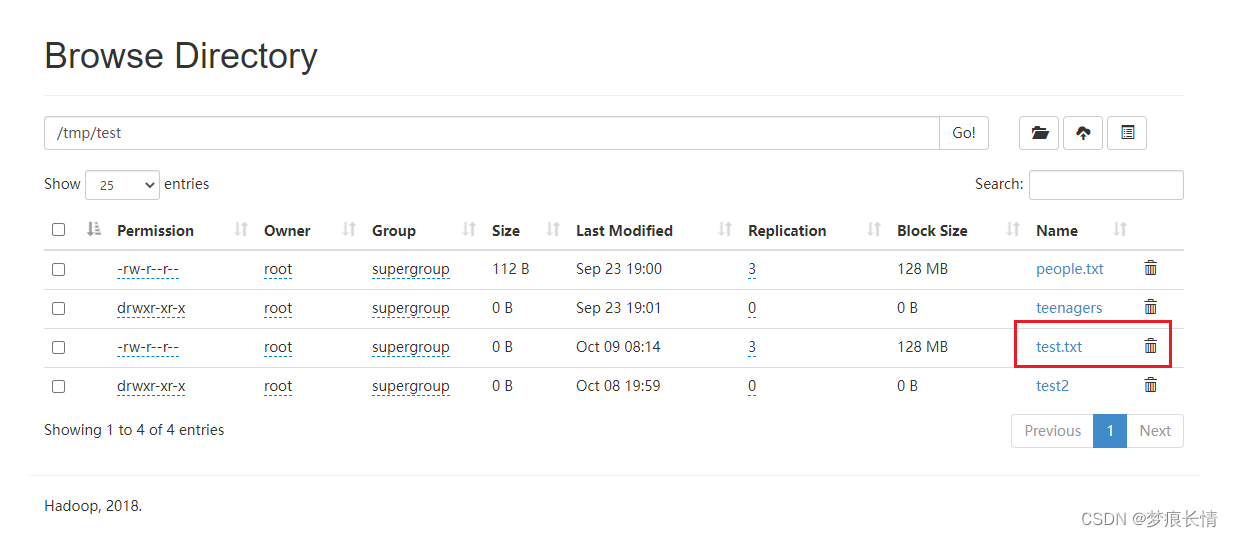
关闭防火墙后,再执行代码。发现已经ok!
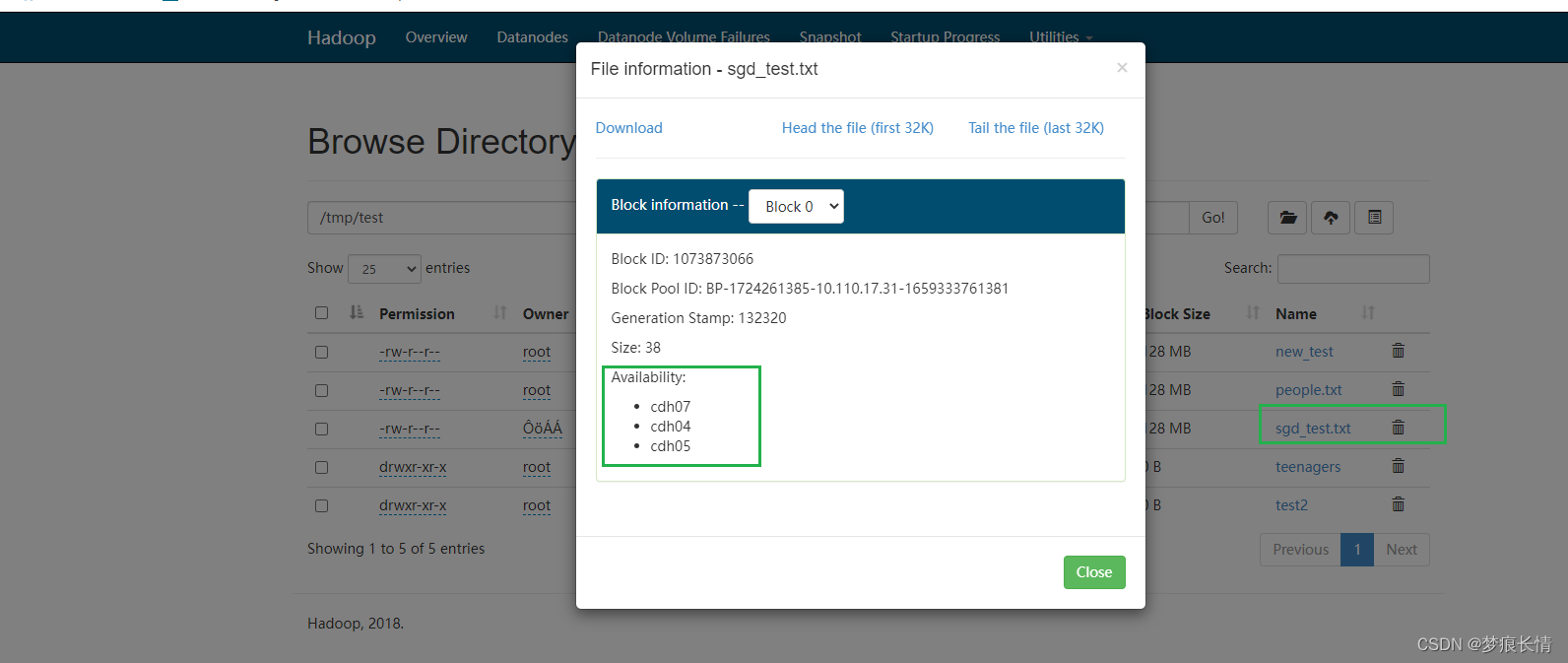
存储块也没问题了!
其他的读写方法一:
package test.HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
/**
* @author lzl
* @create 2022-10-09 14:30
* @name HDFS_CRUD
*/
public class HDFS_CRUD {
FileSystem fs = null;
@Before
public void init() throws IOException {
//构建配置参数对象:Configuration
Configuration conf = new Configuration();
//设置参数,指定我们要访问的文件系统的类型:HDFS文件系统
conf.set("fs.defaultFS","hdfs://cdh02:8020");
//设置客户端的访问身份,以root身份访问HDFS
System.setProperty("HaDOOP_USER_NAME","root");
//通过FileSystem类静态方法,获取客户端访问对象
fs = FileSystem.get(conf);
}
/*
* 将本地文件上传HDFS
* @throws IOException
*/
@Test
public void testAddFileToHdfs() throws IOException{
//创建本地路径的Path对象
Path src = new Path("D:\\hadoop\\test\\sgd_test.txt");
//创建HDFS路径的Path对象
Path dst = new Path("/tmp/test");
//实现数据的上传
fs.copyFromLocalFile(src,dst);
//关闭资源
fs.close();
}
/*
* 从HDFS下载文件到本地
* @throes IllegalArgumentException
* @IOException
*/
@Test
public void testDownloadFileToLocal() throws IOException ,IllegalArgumentException{
//实现文件的下载
fs.copyToLocalFile(new Path("/tmp/test/people.txt"), new Path("D:\\hadoop\\test"));
//关闭资源
fs.close();
}
}
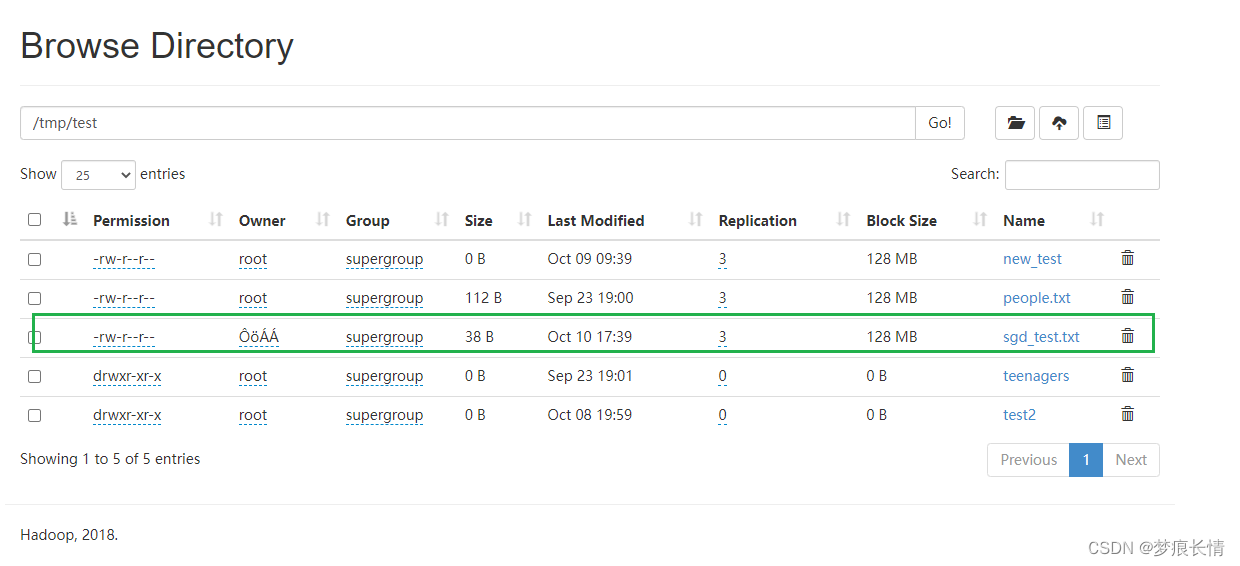
文件的上传:
文件的下载:

其他的写法二:
将HDFS上的/tmp/test/people.txt 下载到本地/hadoop/test/test01.txt。是将内容下载下来,文件命名为test01。
package test.HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
/**
* @author lzl
* @create 2022-10-09 8:54
* @name HdfsTest
*/
public class HdfsTest {
public static void main(String[] args) throws IOException {
// readFileToConsole("/tmp/test/people.txt");
readFileToLocal("/tmp/test/people.txt");
}
//读取hdfs文件系统中的文件
public static void readFileToConsole(String path) throws IOException {
//获取配置
Configuration conf = new Configuration();
//配置
conf.set("fs.defalutFS","hdfs://cdh02:8020");
//获取hdfs文件系统的操作对象
FileSystem fs = FileSystem.get(conf);
//具体对文件操作
FSDataInputStream fis = fs.open(new Path(path));
IOUtils.copyBytes(fis, System.out, 4096, true);
}
//读取hdfs文件系统中的文件
public static void readFileToLocal(String path) throws IOException{
OutputStream out =null;
FSDataInputStream fis =null;
try{
//获取配置
Configuration conf = new Configuration();
//获取hdfs文件系统的操作对象
FileSystem fs = FileSystem.get(new URI("hdfs://cdh02:8020"),conf,"root");
//具体对文件的操作
fis= fs.open(new Path(path));
out = new FileOutputStream(new File("D:\\hadoop\\test\\test01.txt"));
IOUtils.copyBytes(fis,out,4096,true);
} catch (Exception e) {
//
} finally {
//释放资源
fis.close();
out.close();
}
}
}
运行结果:
打开确认:
内容一样。
这样的结果就不会有之前的crc文件了。


从本地上传文件到HDFS:
package test.HDFS;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.yarn.webapp.hamlet2.Hamlet;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.OutputStream;
import java.net.URI;
import java.net.URISyntaxException;
/**
* @author lzl
* @create 2022-10-09 8:54
* @name HdfsTest
*/
public class HdfsTest {
static FileSystem fs = null;
static {
//获取配置
Configuration conf = new Configuration();
//获取hdfs文件系统的操作对象
try {
fs = FileSystem.get(new URI("hdfs://cdh02:8020"),conf,"root");
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
// readFileToConsole("/tmp/test/people.txt");
// readFileToLocal("/tmp/test/people.txt");
copyFromLocal();
}
//读取hdfs文件系统中的文件
public static void readFileToConsole(String path) throws IOException {
//获取配置
Configuration conf = new Configuration();
//配置
conf.set("fs.defalutFS","hdfs://cdh02:8020");
//获取hdfs文件系统的操作对象
FileSystem fs = FileSystem.get(conf);
//具体对文件操作
FSDataInputStream fis = fs.open(new Path(path));
IOUtils.copyBytes(fis, System.out, 4096, true);
}
//读取hdfs文件系统中的文件
public static void readFileToLocal(String path) throws IOException{
OutputStream out =null;
FSDataInputStream fis =null;
try{
//获取配置
Configuration conf = new Configuration();
//获取hdfs文件系统的操作对象
FileSystem fs = FileSystem.get(new URI("hdfs://cdh02:8020"),conf,"root");
//具体对文件的操作
fis= fs.open(new Path(path));
out = new FileOutputStream(new File("D:\\hadoop\\test\\test01.txt"));
IOUtils.copyBytes(fis,out,4096,true);
} catch (Exception e) {
//
} finally {
//释放资源
fis.close();
out.close();
}
}
//从本地上传文件到HDFS
public static void copyFromLocal() throws IOException{
//创建本地路径的Path对象
Path src = new Path("D:\\hadoop\\test\\test02.txt");
//创建HDFS路径的Path对象
Path dst = new Path("/tmp/test");
//调用它的接口函数方法
fs.copyFromLocalFile(src,dst);
System.out.println("finished.....!");
//关闭资源
fs.close();
}
}
执行结果:

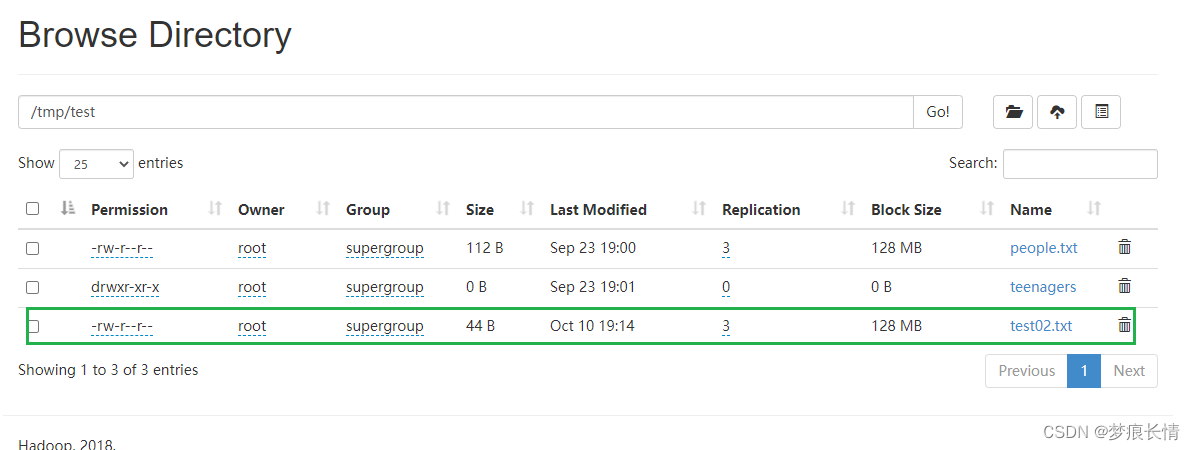
查看里面的内容:
[root@cdh01 ~]# hdfs dfs -cat /tmp/test/test02.txt
hello world!
hello HDFS!
hello java!
















 1231
1231











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









