







摘要
微调是利用预训练大型语言模型执行下游任务的标准方法。然而, 它修改了所有语言模型参数, 因此需要为每个任务存储完整的副本。在这篇论文中, 我们提出了前缀微调 (prefix-tuning), 这是一种针对自然语言生成任务的轻量级替代方法, 它保持语言模型参数冻结, 但优化一个小型的(连续的)任务特定向量 (称为前缀)。前缀微调借鉴了提示的方法, 使得后续的令牌可以像 “虚拟令牌” 一样关注这个前缀。我们将在GPT-2上应用前缀微调进行表格到文本生成, 并在BART上用于摘要。我们发现,仅学习参数的 0.1 % 0.1\% 0.1% ,前缀微调在全数据设置下表现出相当的性能, 低数据设置下优于微调, 并且在训练期间未见过的主题的示例上表现得更好。
1 Introduction
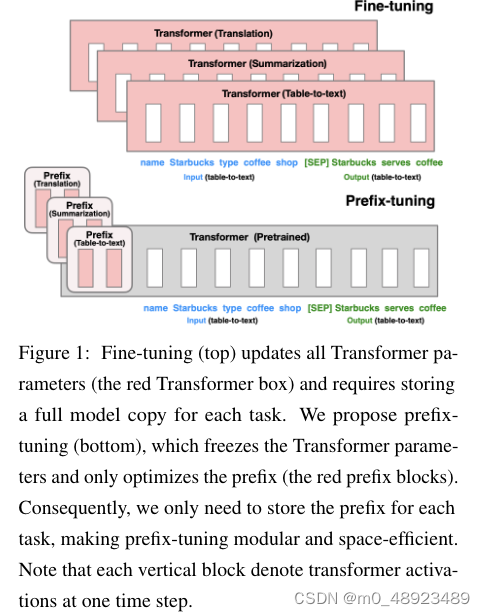
微调是使用大型预训练语言模型 (LMs) 进行下游任务 (如摘要) 的常用方法 ((Radford et al., 2019; Devlin et al., 2019)), 但它需要更新和存储LM的所有参数。因此, 为了构建和部署依赖大型预训练LM的NLP系统, 目前需要为每个任务存储修改后的LM参数副本。考虑到当前LM的庞大规模, 这可能代价高昂; 例如, GPT-2有774M个参数 ((Radford et al., 2019)), 而GPT-3的参数量更是达到了 175 B 175\mathrm{\ B} 175 B ((Brown et al.,2020))。
针对这个问题的一个自然方法是轻量级微调 (lightweight fine-tuning), 它冻结了预训练模型的大部分参数, 并通过添加少量可训练模块来增强模型。例如, adapter-tuning ((Rebuffi et al., 2017; Houlsby et al., 2019)) 会在预训练语言模型的层之间插入专门针对任务的额外层。 adapter-tuning在自然语言理解和生成基准上表现出色,虽然只增加了约 2 − 4 % 2 {-} 4\% 2−4% 的任务特定参数, 但性能却与微调相当(Houlsby et al., 2019;
Lin et al., 2020)。
在极端情况下, GPT-3(Brown et al., 2020)可以在无需任何任务特定微调的情况下部署。用户只需在任务输入前添加自然语言任务指令 (例如, 对于摘要任务, 可以是“TL;DR”) 和一些示例, 然后让语言模型生成输出。这种方法被称为上下文学习或提示 (prompting)。
本文提出prefix-tuning, 一种针对自然语言生成 (NLG) 任务的轻量级替代微调方法, 灵感来源于提示。以生成数据表格的文本描述为例 (如图??所示), 任务输入是线化的表格 (如 “name: Starbucks | type: coffee shop”), 输出是文本描述 (如 “Starbucks serves cof-fee。”)。prefix-tuning在输入前添加一系列连续的任务特定向量, 我们称之为前缀, 如图?? (底部) 中的红色块所示。对于后续的令牌, Transformer可以像处理虚拟令牌序列一样关注前缀, 但与提示不同的是, 前缀完全由自由参数组成, 不对应于实际的令牌。
与图 (顶部) 中的微调相比, 微调会更新所有Transformer参数, 因此需要为每个任务存储一个微调后的模型副本, 而prefix-tuning仅优化前缀。因此, 我们只需要存储一个大型Transformer的单个副本和一个学习到的任务特定前缀, 为每个额外任务带来的额外开销非常小 (例如, 对于表格到文本任务, 大约 250 K 250\mathrm{\ K} 250 K 参数)。
与微调不同, prefix-tuning是模块化的: 我们训练一个上游前缀来引导下游的LM, 而下游LM保持不变。因此, 一个单一的LM可以同时支持多个任务。在个性化场景中, 如果任务对应不同的用户(Shokri and Shmatikov, 2015; McMahan et al., 2016), 我们可以为每个用户训练一个单独的前缀, 仅使用该用户的数据, 从而避免数据交叉污染。此外, 基于前缀的架构甚至允许我们在单个批次中处理来自多个用户/任务的示例, 这是其他轻量级微调方法无法做到的。
我们在表格到文本生成 (使用GPT-2) 和抽象性摘要 (使用BART) 任务上评估prefix-tuning。在存储方面, prefix-tuning存储的参数数量是微调的 1000 倍。在使用完整数据集训练时, 对于表格到文本任务 (§6.1), prefix-tuning和微调的性能相当, 而对于摘要任务 $($6.2),$ prefix-tuning性能稍有下降。在低数据设置下, prefix-tuning在两个任务上平均优于微调 (§6.3)。prefix-tuning在处理未见过主题的表格 (对于表格到文本) 和文章 (对于摘要) 时,也表现出更好的外推能力 $($6.4)$ 。
2 Related Work
针对自然语言生成的微调。 当前最先进的自然语言生成系统基于预训练语言模型的微调。对于表格到文本生成, Kale (2020) 微调序列到序列模型 (T5; Raffel et al., 2020)。对于抽取式和抽象式摘要, 研究人员分别微调掩码语言模型 (如BERT; Devlin et al., 2019) 和编码-解码模型 (如BART; Lewis et al., 2020) (Zhong et al., 2020; Liu and Lapata, 2019; Raffel et al., 2020)。对于机器翻译和对话生成等其他条件性自然语言生成任务, 微调也是主流方法(Zhang et al., 2020c; Stickland et al., 2020; Zhu et al., 2020; Liu et al., 2020)。本论文专注于使用GPT-2的表格到文本和使用BART的摘要, 但前缀微调可以应用于其他生成任务和预训练模型。
轻量级微调。 轻量级微调冻结大部分预训练参数, 并通过小的可训练模块对其进行修改。关键挑战在于确定高性能的模块架构和要调整的预训练参数子集。一种研究路线是移除参数: 通过在模型参数上训练二进制掩码来消除一些模型权重(Zhao et al., 2020; Radiya-Dixit and Wang, 2020)。另一种路线是插入参数。例如, Zhang et al. (2020a) 训练一个 “侧面” 网络, 通过求和与预训练模型融合: adapter-tuning在预训练LM的每层之间插入任务特定的层(适配器) (Houlsby et al., 2019; Lin et al., 2020; Rebuffi et al., 2017; Pfeiffer et al., 2020)。与这些工作相
比,它们调整大约 3.6 % 3.6\% 3.6% 的 L M \mathrm{LM} LM 参数,而我们的方法进一步减少了 30 倍的任务特定参数, 仅调整 0.1 % 0.1\% 0.1% ,同时保持了相当的性能。
提示。 提示意味着在任务输入前添加指令和一些示例, 然后让LM生成输出。GPT-3(Brown et al., 2020) 使用手动设计的提示来调整其生成以适应不同的任务, 这种框架称为上下文学习。然而, 由于Transformer只能处理有限长度的上下文 (如GPT-3的2048个令牌), 上下文学习无法充分利用超过上下文窗口的训练集。Sun and Lai (2020) 也通过关键词提示来控制生成句子的情感或主题。在自然语言理解任务中, 对于BERT和RoBERTa等模型, 提示工程已在先前的工作中进行过探索(Liu et al., 2019; Jiang et al., 2020; Schick and Schütze, 2020)。例如, AutoPrompt(Shin et al., 2020) 通过搜索离散触发词序列并将其与每个输入连接起来, 从掩码LM中激发情感或事实知识。与AutoPrompt不同, 我们的方法优化连续前缀, 它们更具表达力 (§7.2), 而且我们专注于语言生成任务。
连续向量已被用于引导语言模型; 例如, Subramani et al. (2020) 证明了预训练的LSTM语言模型可以通过优化每个句子的连续向量来重建任意句子, 使向量成为输入特定的。相比之下, 前缀微调优化一个任务特定的前缀, 该前缀适用于该任务的所有实例。因此, 与先前的工作相比, 其应用仅限于句子重建, 前缀微调可以应用于自然语言生成任务。
可控生成。 可控生成的目标是引导预训练语言模型以匹配句子级别的属性 (如积极情感或体育主题)。这种控制可以在训练时实现: Keskar et al. (2019) 预训练了语言模型 (CTRL), 使其能够根据元数据 (如关键词或URL) 进行条件生成。此外, 控制也可以在解码时通过加权解码 (GeDi, Krause et al., 2020) 或迭代地更新过去激活 (PPLM, Dathathri et al., 2020) 来实现。然而, 对于像表格到文本和摘要这样的任务, 要实现对生成内容的精细控制, 目前还没有直接的方法。
3 Problem Statement
我们关注一个条件生成任务, 其中输入是一个上下文 x x x ,输出是一个 token 序列。我们关注两个任务, 如图 ?? (右) 所示: 在表格转文本任务中, x x x 对应于线性化的数据表格, y y y 是一个文本描述: 在摘要任务中, x x x 是一篇文章, y y y 是一个简短的摘要。
3.1 Autoregressive LM
假设我们有一个基于Transformer架构 ( (Vaswani et al., 2017), 如GPT-2(Radford et al., 2019)) 的自回归语言模型 p ϕ ( y ∣ x ) p_{\phi}(y {\mid} x) pϕ(y∣x) ,参数化为 ϕ \phi ϕ 。如图?? (顶部) 所示,令 z = [ x ; y ] z = \lbrack x;y\rbrack z=[x;y] 表示 x x x 和 y y y 的拼接; X i d x {\mathrm{X}}_{\mathrm{idx}} Xidx 表示 x x x 的索引序列, Y i d x {\mathrm{Y}}_{\mathrm{idx}} Yidx 表示 y y y 的相同内容。
在时间步 i i i 的激活为 h i ∈ R d h_{i} {\in} {\mathbb{R}}^{d} hi∈Rd ,其 中 h i = [ h i ( 1 ) ; ⋯ ; h i ( n ) ] h_{i} = \left\lbrack h_{i}^{(1)};{\cdots};h_{i}^{(n)} \right\rbrack hi=[hi(1);⋯;hi(n)] 是该时间步所有激活层的拼接,而 h i ( j ) h_{i}^{(j)} hi(j) 是第 j j j 个Transformer层在时间步 i i i 的激活。 1
自回归Transformer模型根据 z i z_{i} zi 以及其左侧
上下文中的过去激活来计算 h i h_{i} hi 。
h i = L M ϕ ( z i , h < i ) , h_{i} = {\mathrm{LM}}_{\phi}\left( z_{i},h_{< i} \right),
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









