






mysql架构及原理
环境说明
- Mysql服务器环境
- Linux虚拟机:CentOS 7
- MySQL:MySQL8.0.27
- mysql文件结构
- mySQL是通过文件系统对数据和索引进行存储的。
- MySQL从物理结构上可以分为日志文件和数据索引文件。
Mysql在Linux中的数据索引文件和日志文件通常放在/var/lib/mysql目录下。
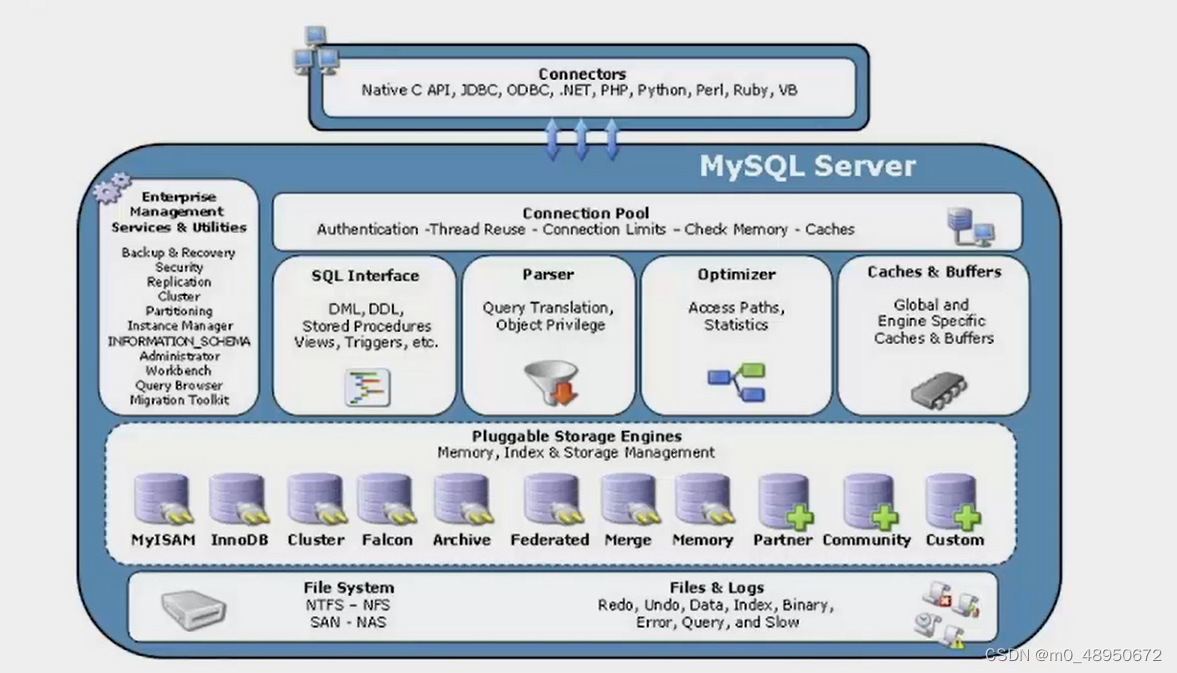
逻辑架构图
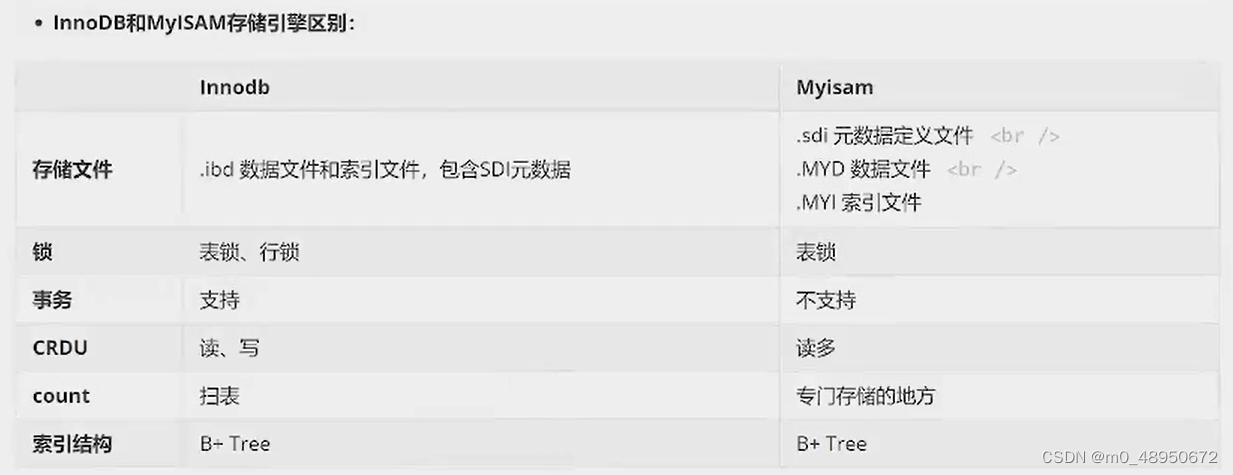
InnoDB和MyISAM存储引擎区别:
引擎的选择:
除非需要用到某些InnoDB不具备的特性,并且没有其他办法可以替代,否则都应该选择InnoDB引擎。
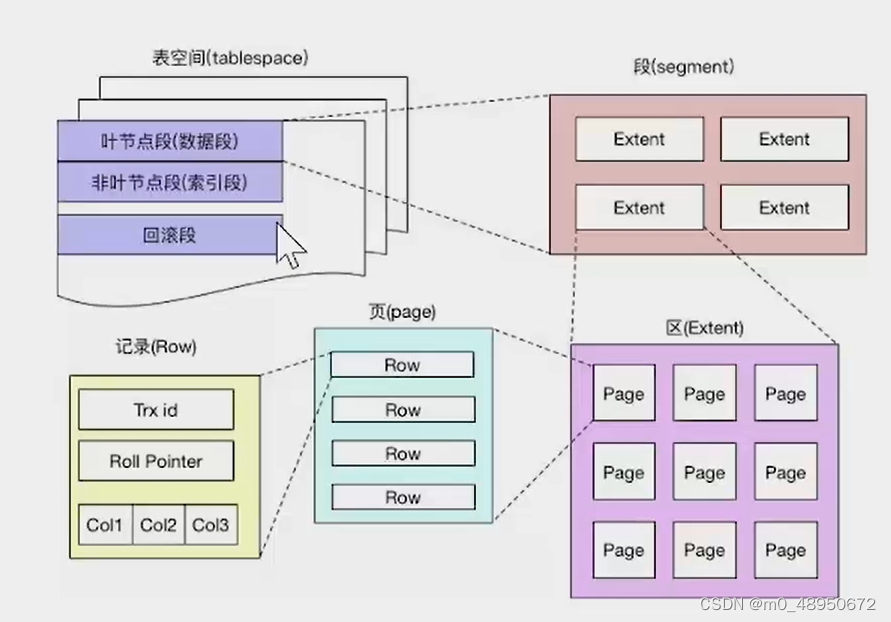
InnoDB逻辑存储结构
InnoDB存储引擎逻辑存储结构可分为五级:表空间,段,区,页,行。
索引
Mysql高效获取数据的数据结构。通俗来说,数据库索引好比是一本书前面的目录,能加快数据库的查询速度。
索引的优势和劣势:
优势:1 可以提高数据检索的效率,降低数据库的IO成本,类似于书的目录。 2 通过索引列对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势:1 索引会占据磁盘空间 2 索引虽然会提高查询效率,但是会降低更新表的效率。
常用的索引类型
主键索引
索引列中的值必须是唯一的,不允许有空值。
Alter Table table_name ADD PRIMARY KEY(column_name);
普通索引
MySQL中基本索引类型,没有什么限制,允许在定义索引的列中插入重复值和空值。
ALTER TABLE TABLE_NAME ADD INDEX INDEX_NAME(column_name);
唯一索引
索引列中的值必须是唯一的,但是允许为空值。
CREATE UNIQUE INDEX INDEX_NAME ON TABLE(COLUMN_NAME)
按照索引列的数量分类
单列索引:索引中只有一个列。
组合索引:使用两个以上的字段创建的索引。(组合索引的使用,需要遵循最左前缀原则 最左匹配原则)
一般情况下,建议使用组合索引代替单列索引(主键索引除外)
组合索引:
最左前缀匹配原则
使用组合索引查询时,mysql会一直向右匹配直至遇到范围查询
索引使用口诀:
全值匹配我最爱,最左前缀要遵守;
带头大哥不能死,中间兄弟不能断;
索引列上不计算,范围之后全失效;
like百分写最右,覆盖索引不写星;
不等空值还有OR,索引失效要少用;
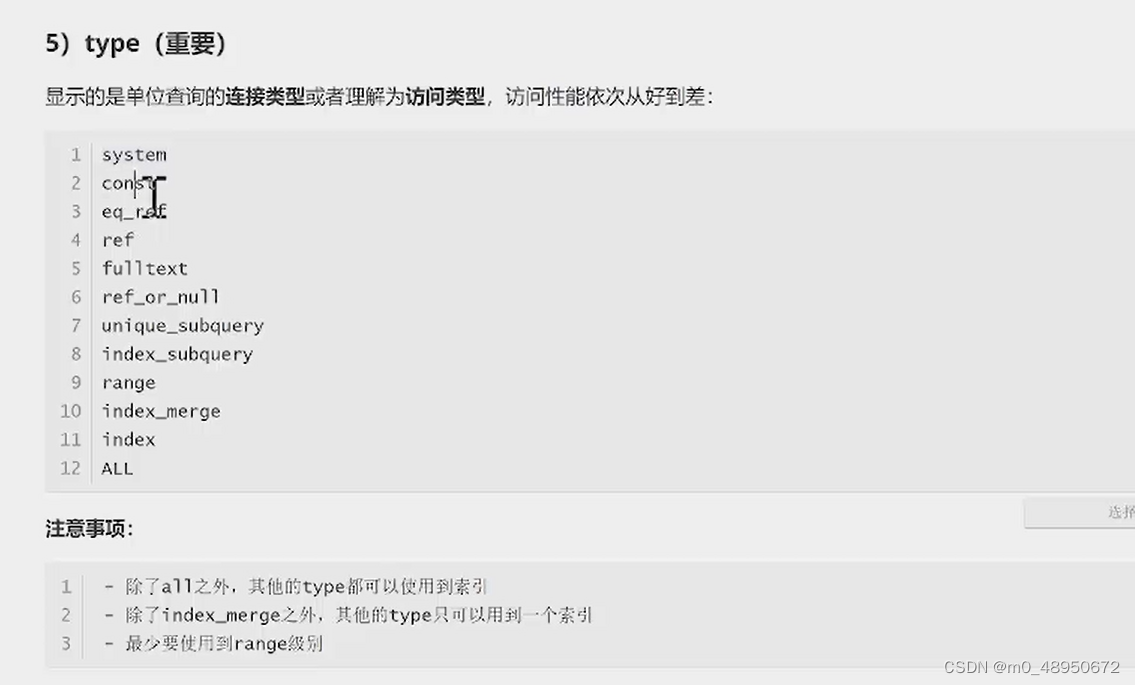
Explain分析
mysql提供一个Explain命令,他可以对Select语句的执行计划进行分析,并输出Select执行的详细信息,以供开发人员针对性优化。

索引的要求
索引的数据结构,至少需要支持两种最常用的查询需求:
1 等值查询:根据某个值查找数据
2 范围查询:根据某个范围区间查找数据
同时需要考虑时间和空间因素。在执行时间方面,我们希望通过索引,查询数据的时间尽可能小;在存储方面,我们希望索引不要消耗太多的内存空间和磁盘空间。
数据结构的选用
常用数据结构:Hash表,二叉树,平衡二叉查找树(红黑树是一个近似平衡二叉树),B树,B+树。
动画演示网站:
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
Hash表
Hash表,Java中的HashMap,TreeMap就是Hash表结构,以键值对的方式存储数据。我们使用Hash表存储表数据Key可以存储索引列,Value可以存储行记录或者行磁盘地址。Hash表在等值查询时效率很高,时间复杂度为o(1);但是不支持范围快速查找,范围查找时还是只能通过扫描全表方式。
二叉查找树
平衡二叉查找树
采用二分法思维,平衡二叉树除了具备二叉树的特点,最主要的特征是树的左右两个子树的层级最多相差1.在插入删除数据时,通过左旋/右旋操作保持二叉树的平衡,不会出现左子树很高,右子树很矮的情况。使用平衡二叉查找树查询的性能接近于二分查找法,时间复杂度是O(logn).查询id=6,只需要两次IO。
平衡二叉树存在的问题:
1 时间复杂度和树高相关。树有多高就需要检索多少次,每个节点的读取,都对应一次磁盘IO操作。树的高度就等于每次查询数据时磁盘IO操作的次数。磁盘每次寻道时间为10ms,在表数据量大时,查询性能就会很差。(1百万的数据量,log2n约等于20次磁盘io,时间20*10=0.2)
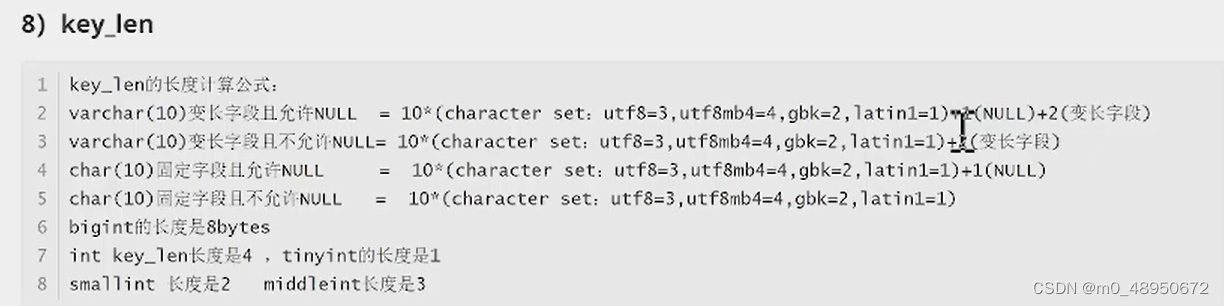
B树
B树是一种多叉平衡查找树
- B树的节点中存储着多个元素,每个内节点有多个分叉。
- 节点中的元素包含键值和数据,节点中的键值对从大到小排列。所有的节点都存储数据。
- 父节点当中的元素不会出现在子节点中。
- 所有的叶子结点都位于同一层,叶节点具有相同的深度,叶节点之间没有指针连接。
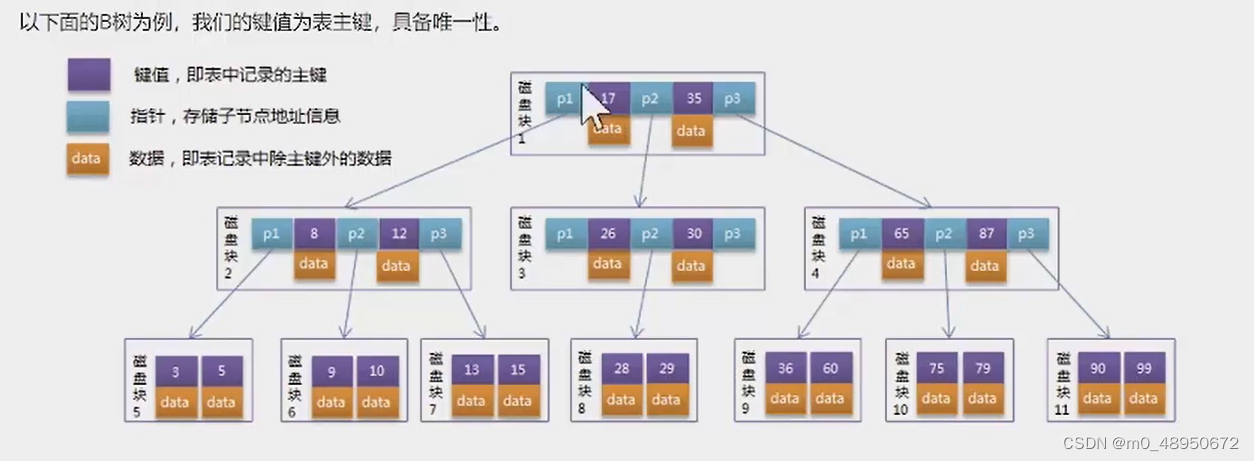
B+树
改造B树
在B树基础上,MySQL在B树的基础上继续改造,使用B+树构建索引。B+树和B树最主要的区别在于非叶子节点是否存储数据的问题。
B树:非叶子节点和叶子节点都会存储数据。
B+树:只有叶子节点才会存储数据,非叶子节点至存储键值。叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。
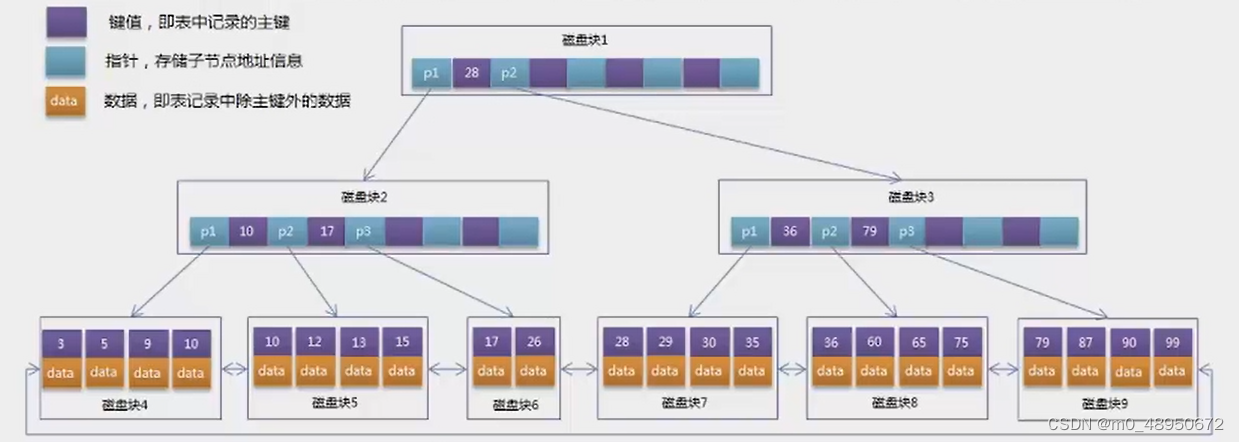
mysql索引的实现
1 MYISAM索引:数据和索引分开存储。
2 InnoDB索引:
每个innoDB表都有一个聚簇索引,聚簇索引使用B+树构建,叶子节点存储的数据是整行记录。一般情况下,聚簇索引等同于主键索引,当一个表没有创建主键索引时,InnoDB会自动创建一个ROWID字段来构建聚簇索引。InnoDB创建索引的具体规则如下:
1 在表上定义主键PRIMARY KEY,INNODB将主键索引用作聚簇索引。
2 如果表没有定义主键,InnoDB会选择第一个不为NULL的唯一索引列用作聚簇索引。
3 如果以上两个都没有,InnoDB会使用一个6字节长整型的隐式字段ROWID字段构建聚簇索引。该ROWID字段会在出入新行时自动递增。
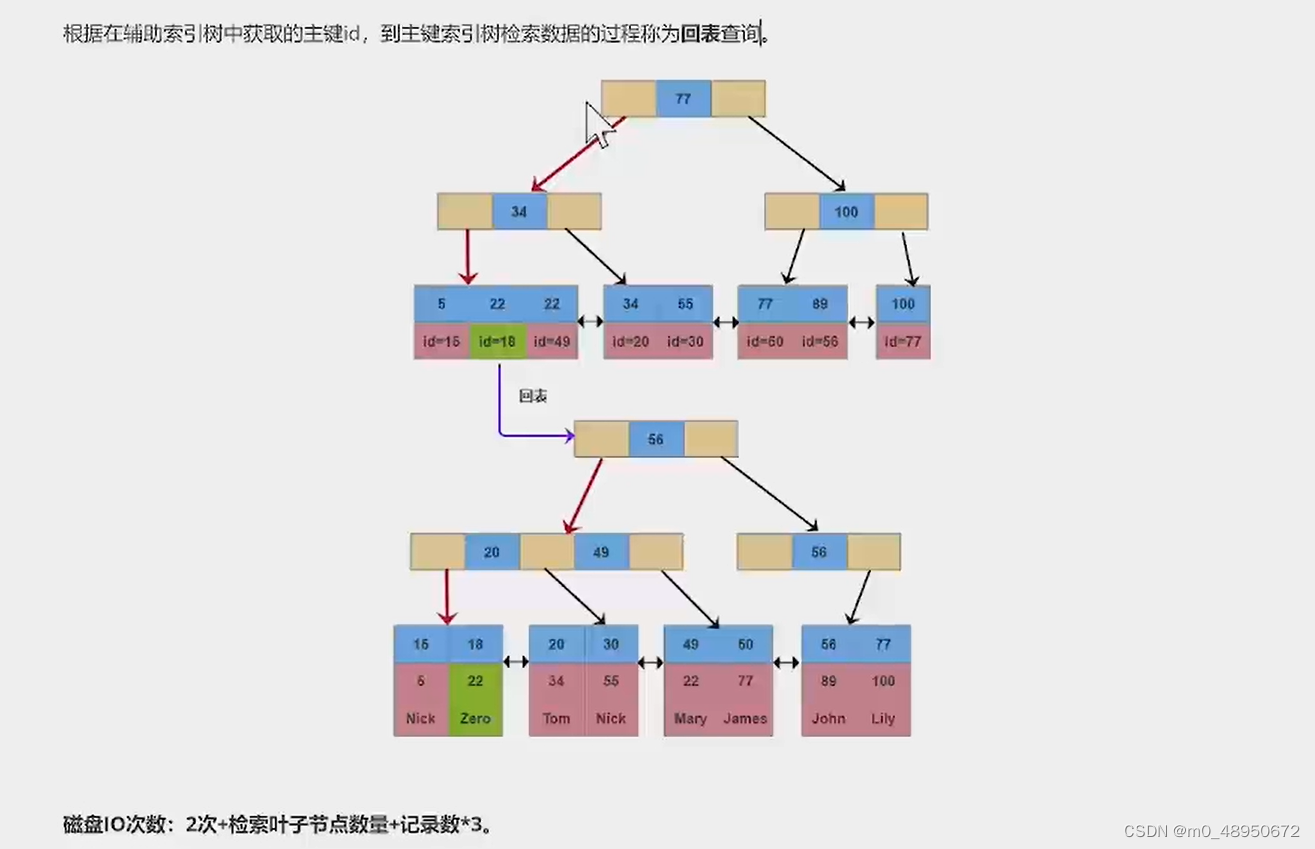
除聚簇索引之外的所有索引都称为辅助索引。在innoDB中,辅助索引中的叶子节点存储的数据是该行的主键值。在检索时,InnoDB使用此主键值在聚簇索引中搜索行记录。
INnoDB的数据和索引存储在一个文件t_user_innodb中。InnoDB的数据组织方式,是聚簇索引。
索引优化原则
1 那些情况需要创建索引
1 频繁的出现在where 条件字段,order排序,group by分组字段
2 select 频繁查询的列,考虑是否需要创建联合索引(覆盖索引,不回表)
3 多表join关联查询,on字段两边的字段都要创建索引
2 索引优化建议:
1 表记录很少不需要创建索引(索引是要有存储的开销)
2 一个表的索引个数不能过多
3 频繁更新的字段不建议作为索引
4 区分度低的字段,不建议建索引
5 在InnoDB存储引擎中,主键索引建议使用自增的长整型,避免使用很长的字段。
6 不建议用无序的值作为索引。例如身份证,uuid(跟新数据时回发生频繁的页分裂,页内数据不紧凑,浪费磁盘空间)
7 尽量创建组合索引,而不是单列索引。
优点:
1 一个组合索引等同于多个索引效果,节省空间
2 可以使用覆盖索引
创建原则:组合索引应该把频繁的列,区分度高的值放在前面。频繁使用代表索引的利用率高,区分度高代表筛选粒度大,可以尽量缩小筛选范围。
数据库事务介绍
数据库事务具有ACID四大特性
原子性(atomicity):事务最小工作单元,要么全成功,要么全失败。
一致性(consistency):事务开始和结束后,数据库的完整性不会被破坏。
隔离性(isolation):不同事务之间互不影响,四种隔离级别为RU(读未提交),RC(读已提交),RR(可重复读),SERIALIZABLE(串行化)
持久性(durability):事务提交之后,对数据的修改是永久性的,即使系统故障也不会丢失。
隔离级别
1 未提交读(READ UNCOMMITTED)
脏读:一个事务读取到另一个事务未提交的数据。
脏读违背了现实世界的业务含义,所以这种READ UNOMMITTED算是十分不安全的一种隔离级别。
2 已提交读(READ COMMITTED)
不可重复读:一个事务因读取到另一个事务已提交的数据。导致相同的查询两次以上的查询结果不同。
3 可重复读(REPEATABLE READ/RR)mysql默认的隔离级别
幻读:一个事务因读取到另一个事务已提交的insert数据。导致对同一张表读取两次以上的结果不一致。
4 串行化(SERIALIZABLE)
以上三种隔离级别都允许对同一记录进行 读-读、读-写,写-读的并发操作,如果我们不允许读-写,写-读的并发操作,可以使用SERIALIZABLE隔离级别。
并发问题的思考
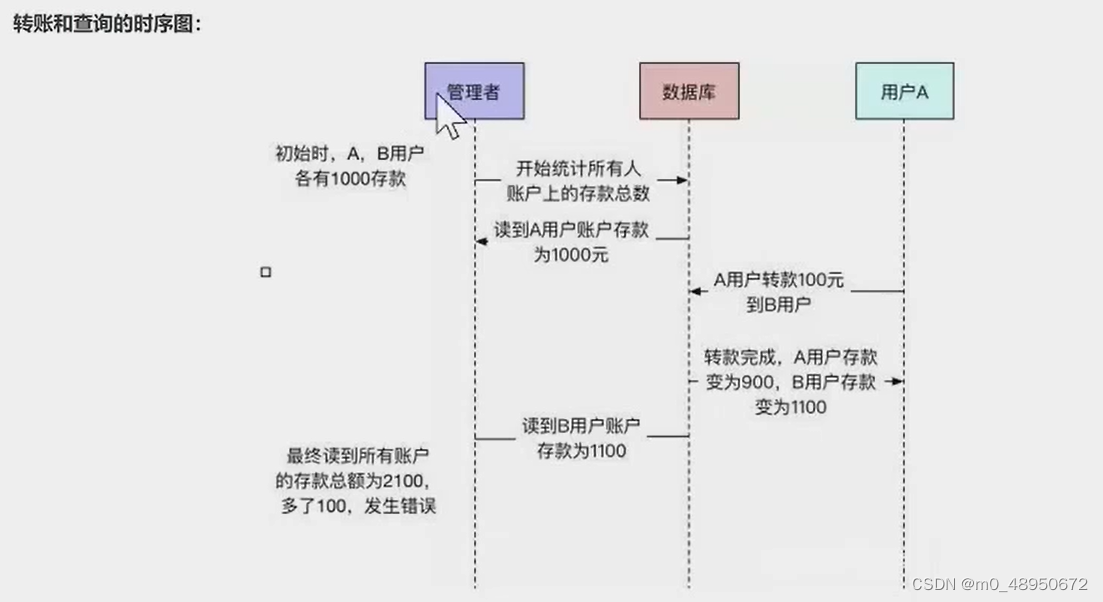
解决方法:
1 LBCC(基于锁的并发控制)
按照锁的粒度来说,mysql主要包含三种类型(级别)的锁定机制:
全局锁:锁的是整个database。由Mysql的SQL layer层实现的。
加全局锁的命令为:flush tables with read lock;
释放全局锁的命令为:unlock tables; 或者断开加锁session的连接,自动释放全局锁。
表级锁:锁的是某个table.由Mysql的SQL layer层实现的
表级锁有四种:
1 表读,写锁。
2 元数据锁(meta data lock,MDL)
不需要显式使用,在访问一个表的时候会被自动加上。锁定表结构。
3 自增锁(AUTO-INC LOCKS)
手动增加读写锁;lock table 表名称 read(write),表名称2 read(write),其他;
行级锁:锁的是某行数据,也可能锁定行之间的间隙。由某些存储引擎实现,比如InnoDB
记录锁(Record Locks):锁定索引中一条记录
执行delete,update操作时默认加记录锁。(X锁)
select * from t where id =1 for update;(X锁)
select * from t where id =2 for share(s锁)
select * from t where id =1 lock in share mode;(s锁)
如果给某一条记录加锁时,查询条件中必须包含唯一索引条件。
间隙锁(Gap Locks)要么锁住索引记录中间的值,要么锁住第一个索引记录前面的值或者最后一个索引记录后面的值。
根据唯一索引进行查询没有命中数据时,加间隙锁(防止幻读)。
间隙锁的后果是无法向间隙中插入数据。
临键锁(Next-key Locks):是索引记录上的记录锁和在索引记录之前的间隙锁的组合(间隙锁+记录锁)。
临键锁就是记录锁+间隙锁。【左开右闭的区间】例如(5,10】
插入意向锁(Insert Intention Loks):做insert操作时添加的对记录id的锁。
需要根据意向锁去判断表中有没有数据行被锁定(行锁)
意向共享锁(IS锁):事务在请求S锁前,需先获取IS锁
意向排他锁(IX锁):事务在请求X锁前,需要获得IX锁
按照锁的功能来说分为:共享锁和排他锁。
共享锁(Shared Locks s锁):
1 兼容性:加了S锁的记录,允许其他事务再加S锁,不允许事务再加X锁
2 加锁方式:select * lock in share mode
排他锁(Exclusive Locks x锁):
1 兼容性:加了X锁的记录,不允许其他事务再加S锁或者X锁
2 加锁方式:select … for update
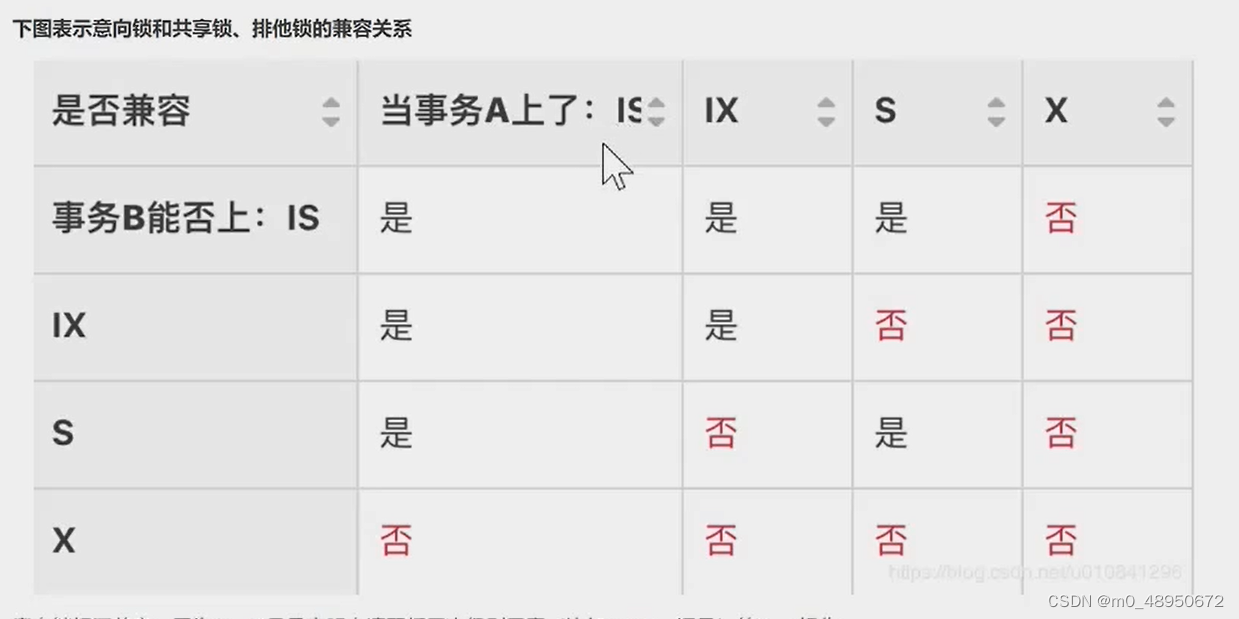
行锁加锁规则:
主键索引
1 等值查询
1 命中记录,加记录锁
2 未命中记录,加间隙锁
2 范围查询
1 没有命中任何一条记录时,加间隙锁
2 命中一条或者多条,包含where条件的临键区间,加临键锁
辅助索引
1 等值查询
1 命中记录,命中记录的辅助索引项+主键索引项加记录锁,辅助索引项两侧加间隙锁。
2 未命中记录,加间隙锁。
2 范围查询
1 没有命中任何一条记录时,加间隙锁。
2 命中一条或者多条,包含where条件的临键区间加临建锁。命中记录的id索引项加记录锁。
MVCC(多版本的并发控制,主要解决读写的并发)
mvcc在mysql中的实现依赖是 undo log 与 read view.
undo log:
1 事务id:mysql数据库全局自增长,保证唯一的编号。版本中记录产生此版本的事务id.
2 回滚指针:版本链中指向上一个版本的指针
3 rowid:主键。如果表中没有主键,自动生成主键rowid,作为记录的唯一编号。
readView :在读,写并发的场合解决并发问题,让读写不冲突,实现快照读
1 创建ReadView的时机。执行Select操作时会生成ReadView
2 取当前数据库中活跃的事务id(没有提交的事务id)放到一个数组中m_ids,按照id的大小降序排列。
mvcc,基于ReadView判断版本可见性
1 取当前事务id,如果版本链中的版本小于ReadView的最小值,那么此版本可见。
2 如果大于等于ReadView最大值那么此版本不可见。
3 如果版本号大于等于ReadView最小值,小于最大值。判断版本号是否存在m_ids中存在,如果不存在那么版本可见的,如果存在,版本不可见的。
ReadView当select所在的事务执行完毕后就会消失,和事务隔离级别有关系。
RC事务隔离级别的实现:
在事务中,每次执行select时都会产生一个新的ReadView
RR事务隔离级别的实现:
在事务中,第一次执行select时都产生一个ReadView.以后再次执行此Select语句会使用同一个readview,保证每次查询到的结果是相同的。
死锁
两个或者多个事务互相持有对方需要获得的资源,此时就会产生死锁。
A
1-ok
2-期望获得
B
2-OK
1-期望获得
如何避免死锁:
Mysql默认会主动探知死锁,并回滚某一个影响最小的事务。等另一个事务执行完成之后,再重新执行该事务。
如何避免死锁:
1.注意程序的逻辑

2 保持事务的轻量
越是轻量的事务,占有越少的锁资源,这样发生死锁的几率就越小。
3 提高运行的速度
避免使用子查询,尽量使用主键等等
4 尽量快提交事务,减少持有锁的时间。















 346
346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









