







学习NIO的笔记总结
NIO简介
Java NIO(New IO / Non Blocking IO<非阻塞式IO>)是从Java1.4版本开始引入的一个新的IO API,可用代替标准的Java IO API;NIO与原来的IO同样的作用和目的,但是使用的方式完全不同,NIO支持面向缓冲区的、基于通道的IO操作。NIO将以更加高效的方式进行文件的读写操作;
NIO和IO的主要区别
| NIO | IO |
|---|---|
| 面向流(Stream Oriented) | 面向缓冲区(Buffer Oriented) |
| 阻塞IO(Blocking IO) | 非阻塞IO(Non Blocking Oriented) |
| 无 | 选择器(Selectors) |
以上表的后两点是针对于网络编程而言
传统的IO

可见:传统的IO流是单向的,是面向流的
NIO

可见:NIO是以管道为连接(不进行数据的交互),缓冲区作为数据的存储来进行交互,因此NIO是面向缓冲区的
通道与缓冲区
Java NIO系统的核心在于:通道(Channel)和缓冲区(Buffer)。通道表示打开到IO设备(如:文件、套接字)的连接。若需要使用NIO系统,需要获取用于连接IO设备的通道以及用于容纳数据的缓冲区。然后操作缓冲区,对数据进行处理;总而言之,Channel负责传输,Buffer负责存储
缓冲区
- 缓冲区:一个用于特定基本数据类型的容器。由java.nio包定义的,所有缓冲区都是Buffer抽象类的子类;
- Java NIO的Buffer主要用于与NIO通道进行交互,数据是从通道读入缓冲区,从缓冲区写入通道中的;
缓冲区的图解:

代码演示
须知
- 缓冲区在Java NIO中负责数据的存取,用于存储不同数据类型的数据,根据数据类型不同(boolean除外),提供了相应类型的缓冲区,如:
ByteBuffer、CharBuffer、ShortBuffer、IntBuffer、LongBuffer、FloatBuffer、DoubleBuffer,上述缓冲区的管理方式几乎一致,都是通过allocate()获取缓冲区; - 缓冲区存取数据的两个核心方法:
put() // 存入数据到缓冲区中、get() // 获取缓冲区中的数据; - 缓冲区中的四个核心属性:
- capacity:容量,表示缓冲区中最大存储数据的容量。一旦声明就不能改变;
- limit:界限,表示缓冲区中可以操作数据的大小。(limit后的数据不能进行读写)
- position:位置,表示缓冲区中正在操作数据的位置()
- mark:标记,表示记录当前position的位置,可以通过reset()恢复到mark的位置
- 注意:0 <= mark <= position <= limit <= capacity
直接缓冲区与非直接缓冲区
- 非直接缓冲区:通过allocate()方法分配缓冲区,将缓冲区建立在JVM内存中;
- 直接缓冲区:通过allocateDirect()方法分配直接缓冲区,将缓冲区建立在物理内存中。因此在某种情况下可以提高效率;
package edu.hebeu.buffer;
import java.nio.ByteBuffer;
import org.junit.Test;
public class StuBuffer {
String dataStr = "abcde"; // 5各英文字符(对应着5个字节大小)
@Test
public void test1() {
// 1、分配一个指定大小的缓冲区
ByteBuffer bbuf = ByteBuffer.allocate(1024); // 容量为1024 byte
System.out.println("------------初始化的属性值-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
// 2、利用put()存入数据到缓冲区中
bbuf.put(dataStr.getBytes());
System.out.println("------------写入数据至缓冲区后各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
// 3、使用flip()方法将缓冲区切换到读数据的模式
bbuf.flip();
System.out.println("------------使用flip()方法切换到读数据模式后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
// 4、利用get()方法读取缓冲区的数据
byte[] target = new byte[bbuf.limit()];
bbuf.get(target); // 将bbuf字节数组内的数据全部读到target字节数组内
System.out.println("------------使用get()方法读取数据后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
// 5、利用rewind()方法将缓冲区内的数据变成执行完flip()方法后的形式,实现可重复读数据
bbuf.rewind();
System.out.println("------------使用rewind()方法切换到读数据模式后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
// 6、使用clear()方法清空缓冲区,但是缓冲区内的数据还在,没有清空,只是这些数据处于"被遗忘"状态(因为各属性值(指针)已经变到了最初的位置)
bbuf.clear();
System.out.println("------------使用clear()方法清空缓冲区后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
System.out.println("验证:" + (char) bbuf.get());
System.out.println("\n\n读到的数据:" + new String(target, 0, target.length));
}
@Test
public void test2() {
ByteBuffer bbuf = ByteBuffer.allocate(1024);
bbuf.put(dataStr.getBytes());
bbuf.flip();
byte[] target = new byte[bbuf.limit()];
// 表示将bbuf字节数组,从第0个索引开始,读2个字节,读入target字节数组内
bbuf.get(target, 0, 2);
System.out.println("------------使用get()方法读取数据后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
System.out.println("本次读到的数据:" + new String(target, 0, 2) + "\n\n");
// 使用mark()进行标记
bbuf.mark();
// 表示将bbuf字节数组,从第2个索引开始,读2个字节,读入target字节数组内
bbuf.get(target, 2, 2);
System.out.println("------------使用get()方法读取数据后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
System.out.println("本次读到的数据:" + new String(target, 2, 2) + "\n\n");
// 使用reset()方法恢复到mark的位置
bbuf.reset();
System.out.println("------------使用reset()方法恢复到mark位置后的各属性值的变化-------------");
System.out.println("capacity = " + bbuf.capacity());
System.out.println("limit = " + bbuf.limit());
System.out.println("position = " + bbuf.position());
// 使用hasRemaining()方法判断缓冲区还有没有剩余的数据
if (bbuf.hasRemaining()) {
// 通过remaining()获取缓冲区中可以操作的数据的数量
System.out.println("缓冲区中还可以操作的数据的数量:" + bbuf.remaining());
}
}
@Test
public void test3() {
// 分配直接缓冲区
ByteBuffer bbuf = ByteBuffer.allocateDirect(1024); // 创建直接缓冲区对象
System.out.println("是否为直接缓冲区?" + bbuf.isDirect()); // 判断该缓冲区是否为直接缓冲区
}
}
上述代码的test1()方法测试结果:

上述代码的test2()方法测试结果:

上述代码的test3()方法测试结果:

直接与非直接缓冲区*
- 字节缓冲区要么是直接的,要么是非直接的。如果为直接缓冲区,则Java虚拟机会尽最大努力直接在此缓冲区上执行I/O操作。也就是说,在每次调用基础操作系统的一个本机I/O操作之前(或之后),虚拟机都会尽量避免将缓冲区的内容复制到中间缓冲区中(或从中间缓冲区中复制内容);
- 直接字节缓冲区可以通过调用此类的allocateDirect()工厂方法来创建。此方法返回的缓冲区进行分配和取消分配所需成本通常高于非直接缓冲区。直接缓冲区的内容可以驻留在常规的垃圾回收堆之外,因此,它们对应用程序的内存需求量造成的影响可能并不明显。所以建议将直接缓冲区主要分配给那些易受基础系统的本机I/O操作影响的大型、持久的缓冲区。一般情况下,最好仅在直接缓冲区能在程序性能方面带来明显好处时分配它们;
- 直接字节缓冲区还可以通过FileChannel的map()方法将文件区域映射到内存中来创建。该方法返回MappedByteBuffer。Java平台的实现有助于通过JNI从本机代码创建直接字节缓冲区。如果以上这些缓冲区中的某个缓冲区实例指的是不可访问的内存区域,则试图访问该区域不会更改该缓冲区的内容,并且将会在访问期间或稍后的某个时间导致抛出不确定的异常;
- 字节缓冲区是直接缓冲区还是非直接缓冲区可通过调用其isDirect()方法来确定。提供此方法是为了能够在性能关键性代码中执行显示缓冲区管理;
非直接缓冲区

直接缓冲区

通道
- 通道(Channel):由java.nio.channels包定义的。Channel表示IO源头与目标打开的连接。Channel类似于传统的“流”。只不过Channel本身不能直接访问数据,Channel只能与Buffer进行交互;
通道

分散与聚集
- 分散读取(Scattering Reads):将通道中的数据分散到多个缓冲区中
- 聚集写入(Gathering Writes):将多个缓冲区中的数据聚集到通道中
- 需要注意:无论是分散读取还是聚集写入,都是按照顺序的,如分散读取就是将Channel管道内的数据按照顺序依次填满Buffer缓冲区;聚集写入就是将每个Buffer按照填满的顺序写入Channel管道中;
分散与聚集

代码演示
须知:
- 通道(Channel)用于源节点与目标节点的连接,在Java NIO中负责缓冲区中数据的传输;
- Channel本身不存储数据,因此需要配合缓冲区进行传输;
- 通道的主要实现类:
- java.nio.channels.Channel接口
- FileChannel // 用于操作本地文件
- SocketChannel // 用于网络TCP
- ServerSocketChannel // (套接字)用于网络TCP
- DatagramChannel // 用于网络UDP
- java.nio.channels.Channel接口
- 如何获取通道?
- 方式一、Java针对支持通道的类提供了getChannel()方法,支持通道的部分类如下所示:
- 本地IO:
FileInputStream/FileOutputStream、RandomAccess - 网络IO:
Socket、ServerSocket、DatagramSocket
- 本地IO:
- 方式二、在JDK1.7中的NIO.2针对各个通道提供了静态方法open()方法;
- 方式三、在JDK1.7中的NIO.2的Files工具类的newByteChannel()方法;
- 方式一、Java针对支持通道的类提供了getChannel()方法,支持通道的部分类如下所示:
- 通道之间的数据传输使用的方法:
- transferFrom()方法、transferTo()方法
- 分散(Scatter)与聚集(Gather)的须知:
- 分散读取(Scattering Reads):将通道中的数据分散到多个缓冲区中
- 聚集写入(Gathering Writes):将多个缓冲区中的数据聚集到通道中
- 补充知识:字符集的概念:
- 编码:字符串 -> 字节数组
- 字节数组 -> 字符串(此部分处理不当<如字符集使用错误等>可能会乱码)
以下代码将上面介绍的内容都进行演示
package edu.hebeu.channel;
import java.io.FileInputStream;
import java.io.FileNotFoundException;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.RandomAccessFile;
import java.nio.ByteBuffer;
import java.nio.CharBuffer;
import java.nio.MappedByteBuffer;
import java.nio.channels.FileChannel;
import java.nio.channels.FileChannel.MapMode;
import java.nio.charset.CharacterCodingException;
import java.nio.charset.Charset;
import java.nio.charset.CharsetDecoder;
import java.nio.charset.CharsetEncoder;
import java.nio.file.Paths;
import java.nio.file.StandardOpenOption;
import java.util.Map;
import java.util.Map.Entry;
import java.util.Set;
import org.junit.Test;
public class StuChannel {
/**
* 利用通道完成文件的复制(非直接缓冲区)
*/
@Test
public void test1() {
long start = System.currentTimeMillis(); // 开始时间
FileInputStream fis = null;
FileOutputStream fos = null;
FileChannel inChannel = null;
FileChannel outChannel = null;
try {
fis = new FileInputStream("D:\\programme\\code\\img\\bianmu.jpg");
fos = new FileOutputStream("copy\\bianmu.jpg");
// 1、获取通道
inChannel = fis.getChannel();
outChannel = fos.getChannel();
// 2、分配指定大小的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 3、将通道中的数据存入缓冲区中
while(inChannel.read(buffer) != -1) { // 如果通过read()方法读取的返回值不是-1,即表示读到了数据
buffer.flip(); // 将缓冲区切换成读取数据的模式
// 4、将缓冲区中的数据写入通道
outChannel.write(buffer);
buffer.clear(); // 情况缓冲区,此时缓冲区内的数据还在,没有清空,只是这些数据处于"被遗忘"状态(因为各属性值(指针)已经变到了最初的位置)
}
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
// 5、关闭资源
if (outChannel != null) {
try {
outChannel.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (inChannel != null) {
try {
inChannel.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (fos != null) {
try {
fos.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (fis != null) {
try {
fis.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
long end = System.currentTimeMillis(); //结束时间
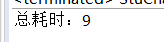
System.out.println("总耗时:" + (end - start));
}
/**
* 使用直接缓冲区实现文件的复制(内存映射文件),在操作大文件时,该方式的速度相较于上面的方式会快
*/
@Test
public void test2() {
long start = System.currentTimeMillis(); // 开始时间
FileChannel inChannel = null;
FileChannel outChannel = null;
try {
// 通过读(READ)的方式去相应的路径下创建一个管道对象
inChannel = FileChannel.open(Paths.get("D:/programme/code/img/奥利奥.jpg"), StandardOpenOption.READ);
// 通过读(READ)写(WRITE)的方式去相应的路径下创建一个管道对象,CREATE:表示文件不存在就创建,存在就进行覆盖;CREATE_NEW:表示文件不存在就创建,存在就报错
outChannel = FileChannel.open(Paths.get("copy/边牧.jpg"),
StandardOpenOption.WRITE, StandardOpenOption.READ,
StandardOpenOption.CREATE_NEW);
// 通过只读方式(READ_ONLY),从0开始inChannel.size()大小的数据(通道内的全部数据),创建内存映射文件
MappedByteBuffer inMappedBuffer = inChannel.map(MapMode.READ_ONLY, 0, inChannel.size());
// 通过读写方式(READ_WRITE),从0开始inChannel.size()大小的数据(通道内的全部数据),创建内存映射文件
MappedByteBuffer outMappedBuffer = outChannel.map(MapMode.READ_WRITE, 0, inChannel.size());
// 直接对直接缓冲区进行读写操作
byte[] target = new byte[inMappedBuffer.limit()];
inMappedBuffer.get(target); // 通过inMappedBuffer将文件读入target字节数组中
outMappedBuffer.put(target); // 通过outMappedBuffer将target字节数组中的数据写出
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
// 关闭资源
if (inChannel != null) {
try {
inChannel.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (outChannel != null) {
try {
outChannel.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
long end = System.currentTimeMillis(); //结束时间
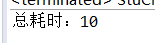
System.out.println("总耗时:" + (end - start));
}
/**
* 通道之间的数据传输(直接缓冲区)
* 因为transferTo()、transferFrom()方法都是直接缓冲区
*/
@Test
public void test3() {
FileChannel inChannel = null;
FileChannel outChannel = null;
// 通过读(READ)的方式去相应的路径下创建一个通道对象
try {
inChannel = FileChannel.open(Paths.get("D:/programme/code/img/奥利奥.jpg"), StandardOpenOption.READ);
// 通过写(WRITE)的方式去相应的路径下创建一个管道对象,CREATE:表示文件不存在就创建,存在就进行覆盖;CREATE_NEW:表示文件不存在就创建,存在就报错
outChannel = FileChannel.open(Paths.get("copy/奥利奥.jpg"),
StandardOpenOption.WRITE, StandardOpenOption.READ,
StandardOpenOption.CREATE_NEW);
// inChannel通道从0到inChannel.size()长度,到outChannel通道内
// inChannel.transferTo(0, inChannel.size(), outChannel);
// 或者outChannel通道从inChannel通道的0到inChannel.size()长度获取其数据
outChannel.transferFrom(inChannel, 0, inChannel.size());
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} finally {
// 关闭资源
if (inChannel != null) {
try {
inChannel.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
if (outChannel != null) {
try {
outChannel.close();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
}
/**
* 分散与聚集
*/
@Test
public void test4() {
RandomAccessFile raf = null;
try {
raf = new RandomAccessFile("data/JavaSE学习笔记.txt", "rw");
// 1、获取通道
FileChannel channel = raf.getChannel();
// 2、分配若干个指定大小的缓冲区,如果分配的缓冲区不合理(这几个ByteBuffer对象的总字节数相比于要操作的文件字节数小、字符集不匹配等),可能会造成乱码的现象,并且操作中文时也有可能会出现乱码(Java下编码大多数使用UTF-8,汉字在该编码下是3个字节<奇数个字节,导致某个汉字会出现读取不全导致乱码>,因此测试文件最好使用没有中文的内容)
ByteBuffer bbuf1 = ByteBuffer.allocate(5000);
ByteBuffer bbuf2 = ByteBuffer.allocate(8000);
ByteBuffer bbuf3 = ByteBuffer.allocate(10000);
// 3、分散读取
ByteBuffer[] bbufs = {bbuf1, bbuf2, bbuf3};
channel.read(bbufs); // 分散读取至ByteBuffer缓冲区数组中
// 将所有的ByteBuffer缓冲区切换为读模式
for (ByteBuffer bbuf : bbufs) {
bbuf.flip(); // 切换成读模式
}
System.out.println("-----------------------------");
// bbufs[0].array()表示将ByteBuffer数组的第一个ByteBuffer对象元素转换为字节数组
System.out.println(new String("bbuf1 = {" + new String(bbufs[0].array(), 0, bbufs[0].limit()) + "}"));
System.out.println("-----------------------------");
System.out.println(new String("bbuf2 = {" + new String(bbufs[1].array(), 0, bbufs[1].limit()) + "}"));
System.out.println("-----------------------------");
System.out.println(new String("bbuf3 = {" + new String(bbufs[2].array(), 0, bbufs[2].limit()) + "}"));
// 4、聚集写入
RandomAccessFile rafWrite = new RandomAccessFile("copy/data.txt", "rw");
FileChannel writeChannel = rafWrite.getChannel(); // 获取通道
// 将ByteBuffer数组(缓冲区数组)聚集写入通道内
writeChannel.write(bbufs);
} catch (FileNotFoundException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
/**
* 字符集
*/
@Test
public void test5() {
// 获取所有的字符集
Map<String, Charset> charsetMap = Charset.availableCharsets();
// 将ap集合转换成Set集合
Set<Entry<String, Charset>> charsetSet = charsetMap.entrySet();
// 遍历转换后的Set集合
for (Entry<String, Charset> charset : charsetSet) {
System.out.println(charset.getKey() + " = " + charset.getValue());
}
System.out.println("----------------------------------------\n\n");
// 创建GBK的字符集
Charset csGBK = Charset.forName("GBK");
// 通过字符集获取对应的编码器
CharsetEncoder ceGBK = csGBK.newEncoder();
// 通过字符集获取对应的解码器
CharsetDecoder cdGBK = csGBK.newDecoder();
// 创建1024容量的字符缓冲区
CharBuffer cbff = CharBuffer.allocate(1024);
// 向字符缓冲区添加数据
cbff.put("添加一点数据");
// 通过编码器进行编码
cbff.flip(); // 将缓冲区变成读模式
ByteBuffer bbff = null;
try {
bbff = ceGBK.encode(cbff); // 进行编码
} catch (CharacterCodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.print("编码后:");
for (int i = 0; i < bbff.limit(); i++) {
System.out.print(bbff.get() + ", ");
}System.out.println("\n----------------------");
// 通过解码器解码
bbff.flip(); // 将缓冲区变成读模式
CharBuffer cb = null;
try {
cb = cdGBK.decode(bbff); // 进行解码
} catch (CharacterCodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
System.out.println("解码后:" + cb);
System.out.println("-----------------------------");
// 如果创建编码器和解码器的字符集不是一致的
Charset csUTF8 = Charset.forName("UTF-8"); // 创建UTF-8字符集
bbff.flip(); // 将缓冲区变成读模式
CharBuffer cb2 = csUTF8.decode(bbff); // 对GBK字符集创建的编码器生成的缓冲区进行解码
System.out.println(cb2); // 输出会发现已经乱码了
}
}
注意上述的测试某些部分需要文件操作,因此注意要创建与代码对应的文件路径,如下:

上述代码的test1()方法的测试:
上述代码的test2()方法的测试:

上述代码的test3()方法的测试:

上述代码的test4()方法的测试:


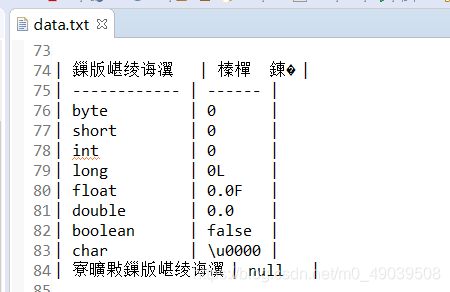
可以发现,中文全部乱码了,但是英文和数字(一个对应一个字节)没有乱码
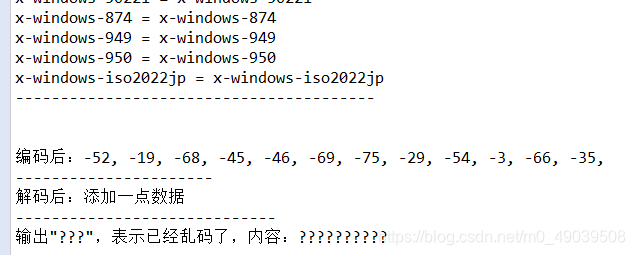
上述代码的test5()方法的测试
阻塞式和非阻塞式
阻塞与非阻塞
- 传统的IO流都是阻塞式的,也就是说,当一个线程调用read()或write()时,该线程被阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务。因此,在完成网络通信进行IO操作时,由于线程会阻塞,所以其他服务端必须为每个客户端都提供一个独立的线程进行处理,当服务端需要处理大量客户端时,性能急剧下降;
- Java NIO是非阻塞式的,当线程从某通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞IO的空闲时间用于在其他通道上执行IO操作,所以单独的线程可以管理多个输入和输出通道。因此,NIO可以让服务器使用一个或有限几个线程来同时处理连接到服务端的所有客户端;
传统IO在网络中的形式(阻塞式)

NIO在网络中的形式(非阻塞式)

代码演示
须知,使用NIO完成网络通信的三个核心:
- 1、通道(Channel):负责连接,对应java.nio.channels.Channel接口
- SelectableChannel // TCP使用
- ServerSocketChannel //TCP使用
- DatagramChannel // UDP使用
- Pipe.SinkChannel
- Pipe.SourceChannel
- 2、缓冲区(Buffer):负责数据的存取
- 3、选择器(Selector):是SelectableChannel的多路复用器。用于监控SelectableChannel的IO状况,其重要的方法:
- register(Selector selector, int ops); // 用于将通道注册选择器时,选择器对通道的监听事件,需要通过第二个参数ops指定;
- 第二个参数ops表示可以监听的事件类型(可使用SelectionKey的四个常量表示):读:SelectionKey.OP_READ (1)、写:SelectionKey.OP_WRITE (4)、连接:SelectionKey.OP_CONNECT (8)、接收:SelectionKey.OP_ACCEPT (16 );
- 若注册时不止一个事件,则可以使用"位或"操作符连接,如:int intertSet = SelectionKey.OP_READ | SelectionKey.OP_WRITE;
- register(Selector selector, int ops); // 用于将通道注册选择器时,选择器对通道的监听事件,需要通过第二个参数ops指定;
传统TCP网络编程操作文件的方式就是是阻塞模式(我的另一篇博文《Java网络编程的笔记小结》有详解),这里我就不做赘述,非阻塞模式的代码如下:
package edu.hebeu.noblocking;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.time.LocalDateTime;
import java.util.Iterator;
import java.util.Scanner;
import org.junit.Test;
public class TCPNoBlockingTest {
@Test
public void client() throws IOException {
// 1、获取通道
SocketChannel sChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 9898));
// 2、切换成非阻塞模式
sChannel.configureBlocking(false);
// 3、分配指定大小的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 4、发送数据给服务端
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()) {
String str = scanner.next();
buffer.put((str + "\t\t" + LocalDateTime.now().toString()).getBytes()); // 给缓冲区buffer中添加数据
buffer.flip(); // 将缓冲区变成读模式
sChannel.write(buffer); // 将buffer内的数据写入通道
buffer.clear(); // 将缓冲区内的数据"遗忘"
}
// 5、关闭资源
scanner.close();
sChannel.close();
}
@Test
public void server() throws IOException {
// 1、获取通道
ServerSocketChannel ssChannel = ServerSocketChannel.open();
// 2、切换成非阻塞模式
ssChannel.configureBlocking(false);
// 3、绑定链接
ssChannel.bind(new InetSocketAddress(9898));
// 4、获取选择器
Selector selector = Selector.open();
// 5、将通道注册到选择器上,并指定监听事件为ACCEPT接收事件,以使选择器能够监控该通道
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
// 6、通过选择器轮询式的获取选择器上已经"准备就绪"的事件
while(selector.select() > 0) { // 因为监听事件的常量值对应的int都是大于0的,所以当select()方法检测到选择器selector大于0,表示至少有一个事件已经准备就绪
/*
* 方法分析:获取选择器中所有注册的选择键的Set集合对应的迭代器
* selectedKeys(); // 获取选择器对象上所有注册的事件,以Set<SelectionKey>的集合形式返回
* iterator(); // 获取选择器上所有注册的事件的集合的迭代器
*/
Iterator<SelectionKey> selectionKeyIterator = selector.selectedKeys().iterator();
// 8、迭代所有的选择键
while(selectionKeyIterator.hasNext()) {
// 9、获取"准备就绪"的事件
SelectionKey sk = selectionKeyIterator.next(); // 获取选择键
// 10、判断具体是什么事件准备就绪
if(sk.isAcceptable()) { // 如果"接收就绪"
SocketChannel sChannel = ssChannel.accept(); // 获取客户端连接
// 11、将客户端的通道切换成非阻塞模式
sChannel.configureBlocking(false);
// 12、将该通道注册到选择器上,并指定监听事件为READ接收事件,以使选择器能够监控该通道
sChannel.register(selector, SelectionKey.OP_READ);
} else if(sk.isReadable()) { // 13、如果"读就绪"
// 14、获取当前选择器上"读就绪"状态的通道
SocketChannel sChannel = (SocketChannel) sk.channel();
// 15、读取数据
ByteBuffer buffer = ByteBuffer.allocate(1024); // 设置指定大小的缓冲区
int count = 0;
while((count = sChannel.read(buffer)) > 0) {
buffer.flip(); // 将缓冲区切换成读模式
System.out.println(new String(buffer.array(), 0, count));
buffer.clear(); // 将缓冲区内的数据"遗忘"
}
} else if(sk.isWritable()) { // 如果"写就绪"
// ...
} else if(sk.isConnectable()) { // 如果"连接就绪"
// ...
} else if(sk.isValid()) { // 如果"是有效的"
}
// 16、取消选择键SelectionKey
selectionKeyIterator.remove();
}
}
ssChannel.close(); // 关闭通道
}
}
测试:
先启动server()方法,在启动client()方法(并且该方法可以启动多个!这里我们启动两个client()方法),如下:

去启动的client()方法的控制台,随便输入点信息,如下:

server()方法的控制台的打印信息如下:

也可以去另一个client()方法的控制台输入信息,如下:

server()方法的控制台的打印信息如下所示:

使用UDP的方式实现非阻塞的代码,换汤不换药,如下所示:
package edu.hebeu.noblocking;
import java.io.IOException;
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.time.LocalDateTime;
import java.util.Iterator;
import java.util.Scanner;
import org.junit.Test;
public class TCPNoBlockingTest {
@Test
public void client() throws IOException {
// 1、获取通道
SocketChannel sChannel = SocketChannel.open(new InetSocketAddress("127.0.0.1", 9898));
// 2、切换成非阻塞模式
sChannel.configureBlocking(false);
// 3、分配指定大小的缓冲区
ByteBuffer buffer = ByteBuffer.allocate(1024);
// 4、发送数据给服务端
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()) {
String str = scanner.next();
buffer.put((str + "\t\t" + LocalDateTime.now().toString()).getBytes()); // 给缓冲区buffer中添加数据
buffer.flip(); // 将缓冲区变成读模式
sChannel.write(buffer); // 将buffer内的数据写入通道
buffer.clear(); // 将缓冲区内的数据"遗忘"
}
// 5、关闭资源
sChannel.close();
scanner.close();
}
@Test
public void server() throws IOException {
// 1、获取通道
ServerSocketChannel ssChannel = ServerSocketChannel.open();
// 2、切换成非阻塞模式
ssChannel.configureBlocking(false);
// 3、绑定链接
ssChannel.bind(new InetSocketAddress(9898));
// 4、获取选择器
Selector selector = Selector.open();
// 5、将通道注册到选择器上,并指定监听事件为ACCEPT接收事件,以使选择器能够监控该通道
ssChannel.register(selector, SelectionKey.OP_ACCEPT);
// 6、通过选择器轮询式的获取选择器上已经"准备就绪"的事件
while(selector.select() > 0) { // 因为监听事件的常量值对应的int都是大于0的,所以当select()方法检测到选择器selector大于0,表示至少有一个事件已经准备就绪
/*
* 方法分析:获取选择器中所有注册的选择键的Set集合对应的迭代器
* selectedKeys(); // 获取选择器对象上所有注册的事件,以Set<SelectionKey>的集合形式返回
* iterator(); // 获取选择器上所有注册的事件的集合的迭代器
*/
Iterator<SelectionKey> selectionKeyIterator = selector.selectedKeys().iterator();
// 8、迭代所有的选择键
while(selectionKeyIterator.hasNext()) {
// 9、获取"准备就绪"的事件
SelectionKey sk = selectionKeyIterator.next(); // 获取选择键
// 10、判断具体是什么事件准备就绪
if(sk.isAcceptable()) { // 如果"接收就绪"
SocketChannel sChannel = ssChannel.accept(); // 获取客户端连接
// 11、将客户端的通道切换成非阻塞模式
sChannel.configureBlocking(false);
// 12、将该通道注册到选择器上,并指定监听事件为READ接收事件,以使选择器能够监控该通道
sChannel.register(selector, SelectionKey.OP_READ);
} else if(sk.isReadable()) { // 13、如果"读就绪"
// 14、获取当前选择器上"读就绪"状态的通道
SocketChannel sChannel = (SocketChannel) sk.channel();
// 15、读取数据
ByteBuffer buffer = ByteBuffer.allocate(1024); // 设置指定大小的缓冲区
int count = 0;
while((count = sChannel.read(buffer)) > 0) {
buffer.flip(); // 将缓冲区切换成读模式
System.out.println(new String(buffer.array(), 0, count));
buffer.clear(); // 将缓冲区内的数据"遗忘"
}
sChannel.close(); // 关闭通道
} else if(sk.isWritable()) { // 如果"写就绪"
// ...
} else if(sk.isConnectable()) { // 如果"连接就绪"
// ...
} else if(sk.isValid()) { // 如果"是有效的"
}
// 16、取消选择键SelectionKey
selectionKeyIterator.remove();
}
}
ssChannel.close(); // 关闭通道
}
}
结果演示:

发送方的消息信息:


管道(Pipe)
Java NIO管道是2个线程之间的单向数据连接,管道(Pipe)有一个source通道和一个sink通道。数据会被写道sink通道,从source通道读取;
管道

代码演示
管道是的原理如上图,是非常简单的,下面直接通过代码来阐述上图:
package edu.hebeu.pipe;
import java.io.IOException;
import java.nio.ByteBuffer;
import java.nio.channels.Pipe;
import org.junit.Test;
public class StuPipe {
@Test
public void test1() throws IOException {
// 1、获取管道
Pipe pipe = Pipe.open();
// 2、将缓冲区中的数据写入管道
Pipe.SinkChannel sinkChannel = pipe.sink(); // 获取sink管道
ByteBuffer buffer = ByteBuffer.allocate(1024); // 创建指定大小的缓冲区
buffer.put("管道内的数据...".getBytes()); // 向管道内添加数据
buffer.flip(); // 将管道变成读模式
sinkChannel.write(buffer); // 将缓冲区内的数据通过写入SinkChannel通道至pipe管道
// 3、读取缓冲区中的数据
Pipe.SourceChannel sourceChannel = pipe.source(); // 获取source管道
buffer.flip(); // 将缓冲区变成读模式
int count = sourceChannel.read(buffer); // 将pipe管道内的数据通过SourceChannel通道读取值缓冲区,并获取缓冲区内的数据个数
System.out.println(new String(buffer.array(), 0, count));
// 4、关闭资源
sourceChannel.close();
sinkChannel.close();
}
}
测试结果:
















 279
279











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









