







前言
我司的集群时刻处于崩溃的边缘,通过近三个月的掌握,发现我司的集群不稳定的原因有以下几点:
1、发版流程不稳定
2、缺少监控平台【最重要的原因】
3、缺少日志系统
4、极度缺少有关操作文档
5、请求路线不明朗
总的来看,问题的主要原因是缺少可预知的监控平台,总是等问题出现了才知道。次要的原因是服务器作用不明朗和发版流程的不稳定。
解决方案
发版流程不稳定
重构发版流程。业务全面k8s化,构建以kubernetes为核心的ci/cd流程。
发版流程
有关发版流程如下:
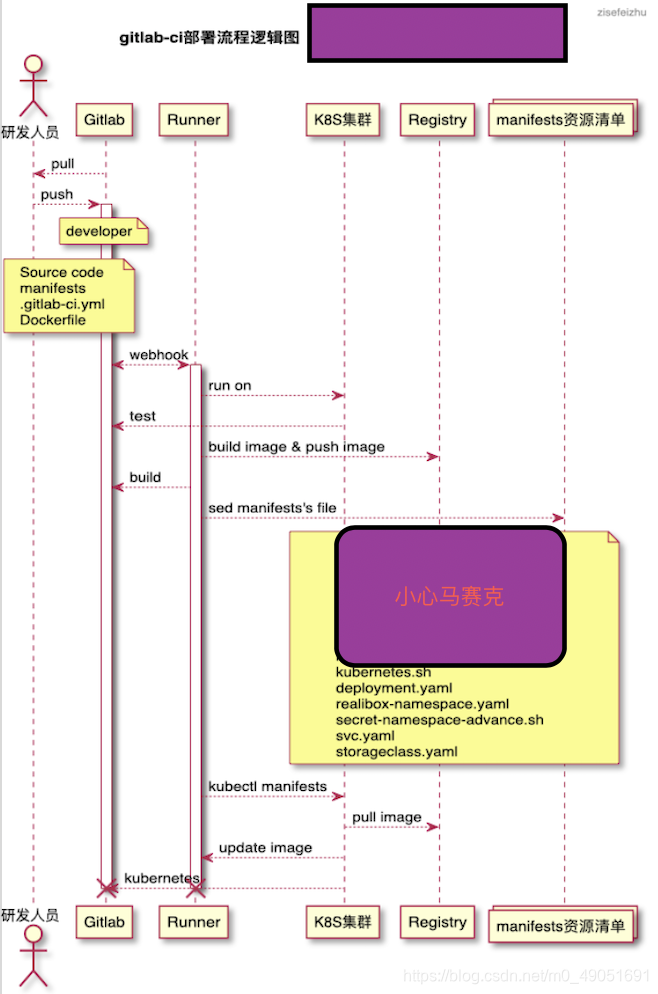
浅析:研发人员提交代码到developer分支(时刻确保developer分支处于最新的代码),developer分支合并到需要发版环境对应的分支,触发企业微信告警,触发部署在k8s集群的gitlab-runner pod,新启runner pod 执行ci/cd操作。在这个过程中需要有三个步骤:测试用例、打包镜像、更新pod。第一次部署服务在k8s集群环境的时候可能需要:创建namespace、创建imagepullsecret、创建pv(storageclass)、创建deploym
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









