






1、使用devEco自带模版启动native开发项目
1.1、使用自带Native C++模版创建
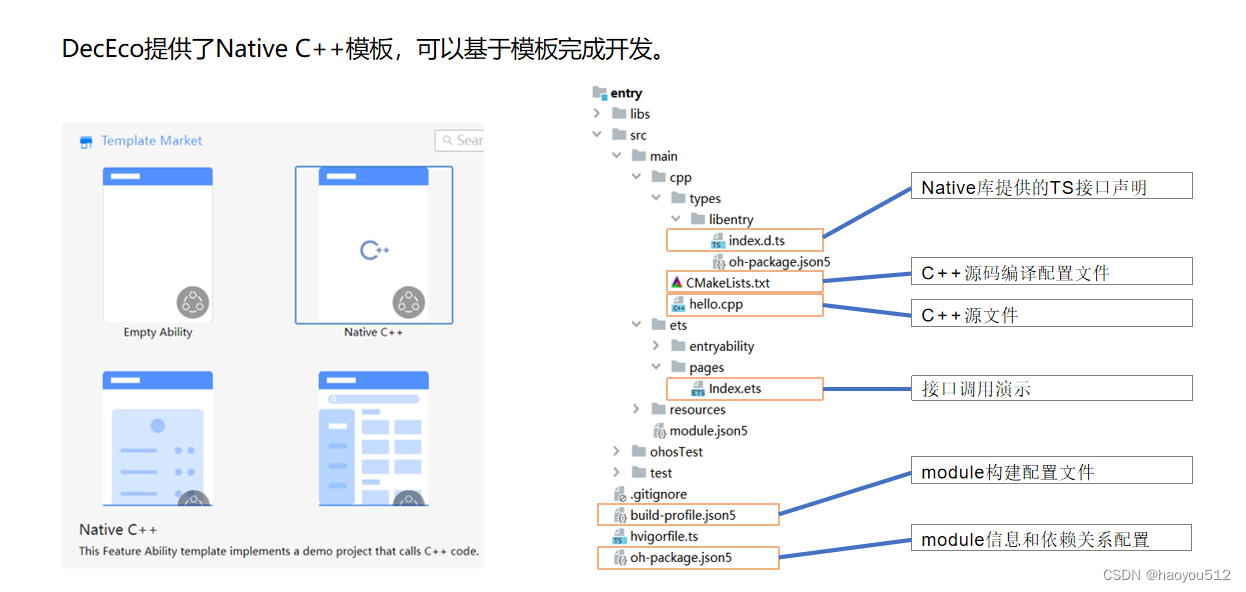
1.2、创建之后的文件目录
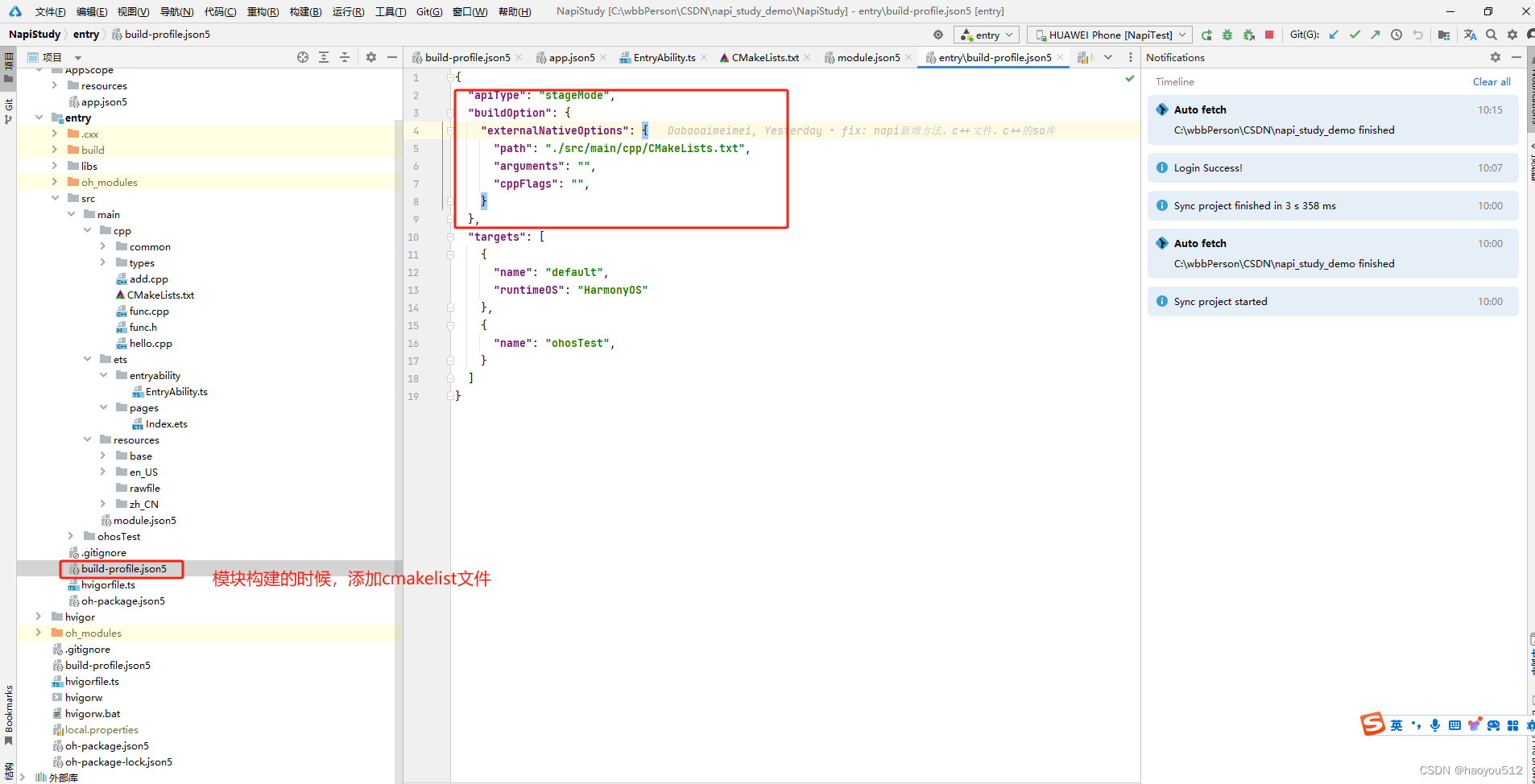
1.2.1 cmake引入按照napi处理后的模块生成一个可以让ninja编译的文件配置。
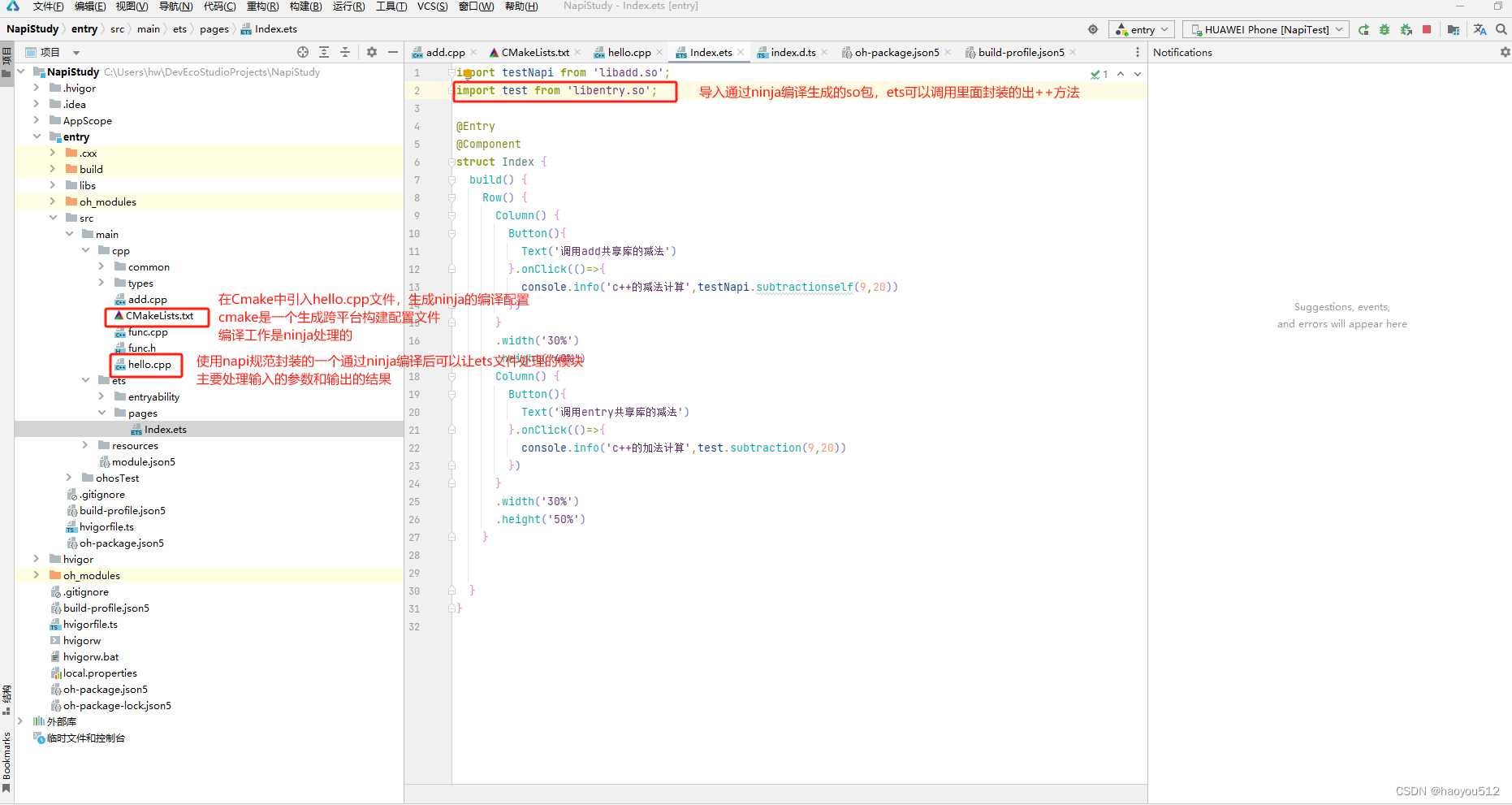
1.2.2 并且要把cmakelist文件引入到当前模块的打包构建文件中。
2、基于模版新增一个方法
2.1 新增一个静态方法
2.2 解释一下函数的定义,用typescript语法去类比理解
// 使用接口定义参数类型
interface napi_env {}
interface napi_callback_info {}
// 定义函数
function Add(env: napi_env, info: napi_callback_info): napi_value {
// 函数体
return null; // 用null代替napi_value
}
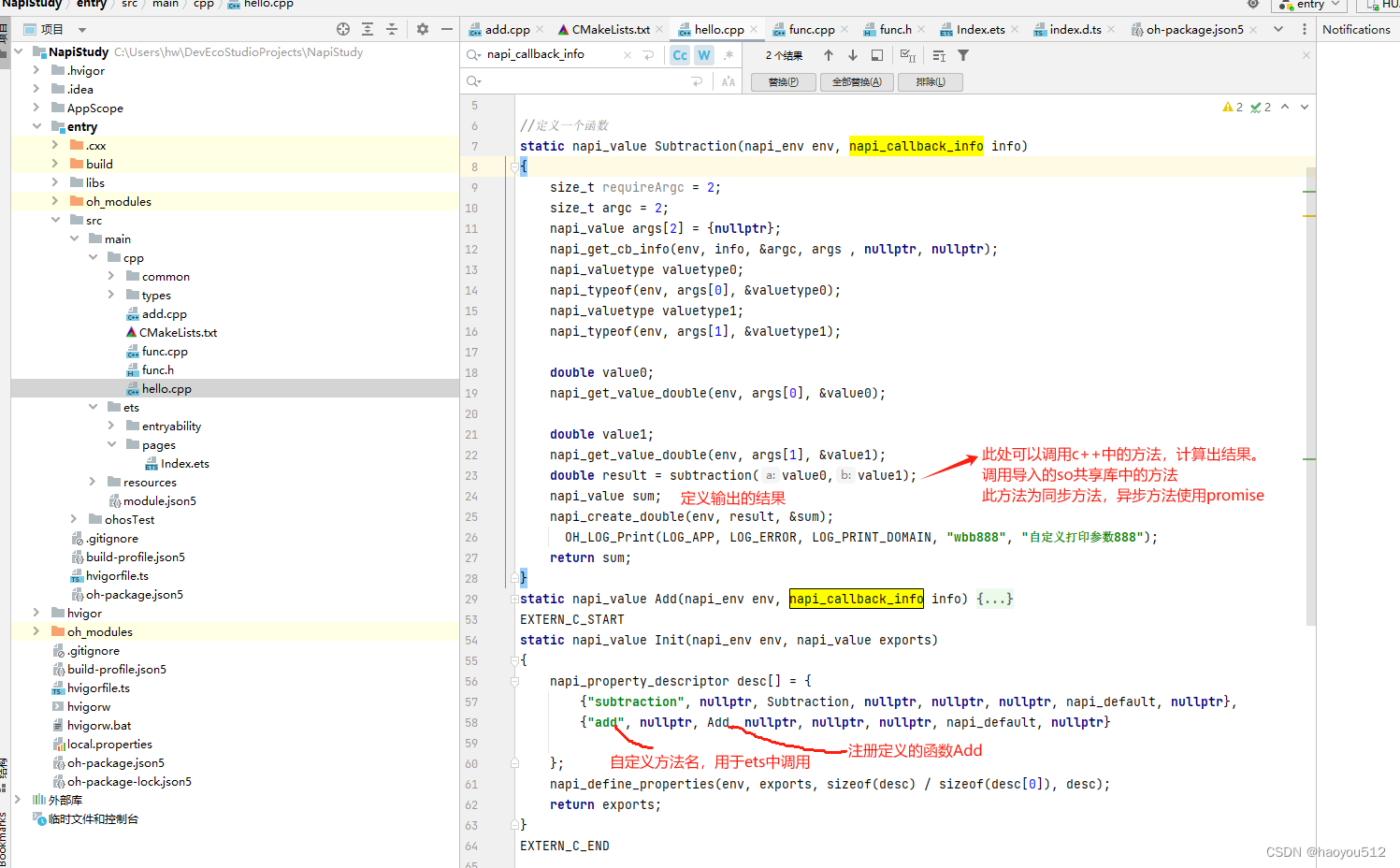
1 static napi_value Subtraction(napi_env env, napi_callback_info info): 这是一个名为 Subtraction 的静态函数,接受两个参数 env 和 info,返回一个 napi_value 类型的值。
2 size_t requireArgc = 2; 定义一个变量 requireArgc,值为 2,表示需要的参数个数。
3 size_t argc = 2; 定义一个变量 argc,值为 2,表示实际传入的参数个数。
4 napi_value args[2] = {nullptr}; 定义一个长度为 2 的 napi_value 类型的数组 args,初始化每个元素为 nullptr。
在C/C++语言中,使用大括号 {} 来初始化数组是一种更为简洁和方便的初始化方式。在这种情况下,大括号内部逐个指定数组元素的初始值,编译器会自动根据大括号内的元素数量来确定数组的长度,并为数组分配空间
5 napi_get_cb_info(env, info, &argc, args , nullptr, nullptr); 使用 napi_get_cb_info 函数获取回调信息,包括环境、回调信息、参数个数、参数数组等。
6 napi_valuetype valuetype0; 定义变量 valuetype0 用于存储第一个参数的数据类型。
7 napi_typeof(env, args[0], &valuetype0); 使用 napi_typeof 函数获取第一个参数的数据类型,并存储在 valuetype0 中。
8 napi_valuetype valuetype1;定义变量 valuetype1 用于存储第二个参数的数据类型。
9 napi_typeof(env, args[1], &valuetype1); 使用 napi_typeof 函数获取第二个参数的数据类型,并存储在 valuetype1 中。
10 double value0; 定义变量 value0 用于存储第一个参数的值。
11 napi_get_value_double(env, args[0], &value0); 使用 napi_get_value_double 函数从第一个参数中获取 double 类型的值,并存储在 value0 中。
12 double value1; 定义变量 value1 用于存储第二个参数的值。
13 napi_get_value_double(env, args[1], &value1); 使用 napi_get_value_double 函数从第二个参数中获取 double 类型的值,并存储在 value1 中。
14 double result = subtraction(value0,value1); 调用 subtraction 函数对 value0 和 value1 进行减法运算,并将结果存储在 result 中。
15 napi_value sum; 定义变量 sum 用于存储计算结果的 napi_value 类型。
16 napi_create_double(env, result, &sum); 使用 napi_create_double 函数将 result 转换为 napi_value 类型的值,并存储在 sum 中。
OH_LOG_Print(LOG_APP, LOG_ERROR, LOG_PRINT_DOMAIN, "wbb888", "自定义打印参数888"); 这行代码是一个自定义的打印输出,使用了 OH_LOG_Print 函数。
17 return sum;: 返回存储计算结果的 napi_value 类型的值 sum。1 EXTERN_C_START: 这个宏定义可能是在 C++ 中用来指示代码块开始处,告诉编译器这部分代码是 C 风格的代码。
2 static napi_value Init(napi_env env, napi_value exports): 这是一个静态函数 Init,接受两个参数 env 和 exports,返回一个 napi_value 类型的值。
3 napi_property_descriptor desc[] = { ... }: 定义一个 napi_property_descriptor 类型的数组 desc,用于存储属性描述符。
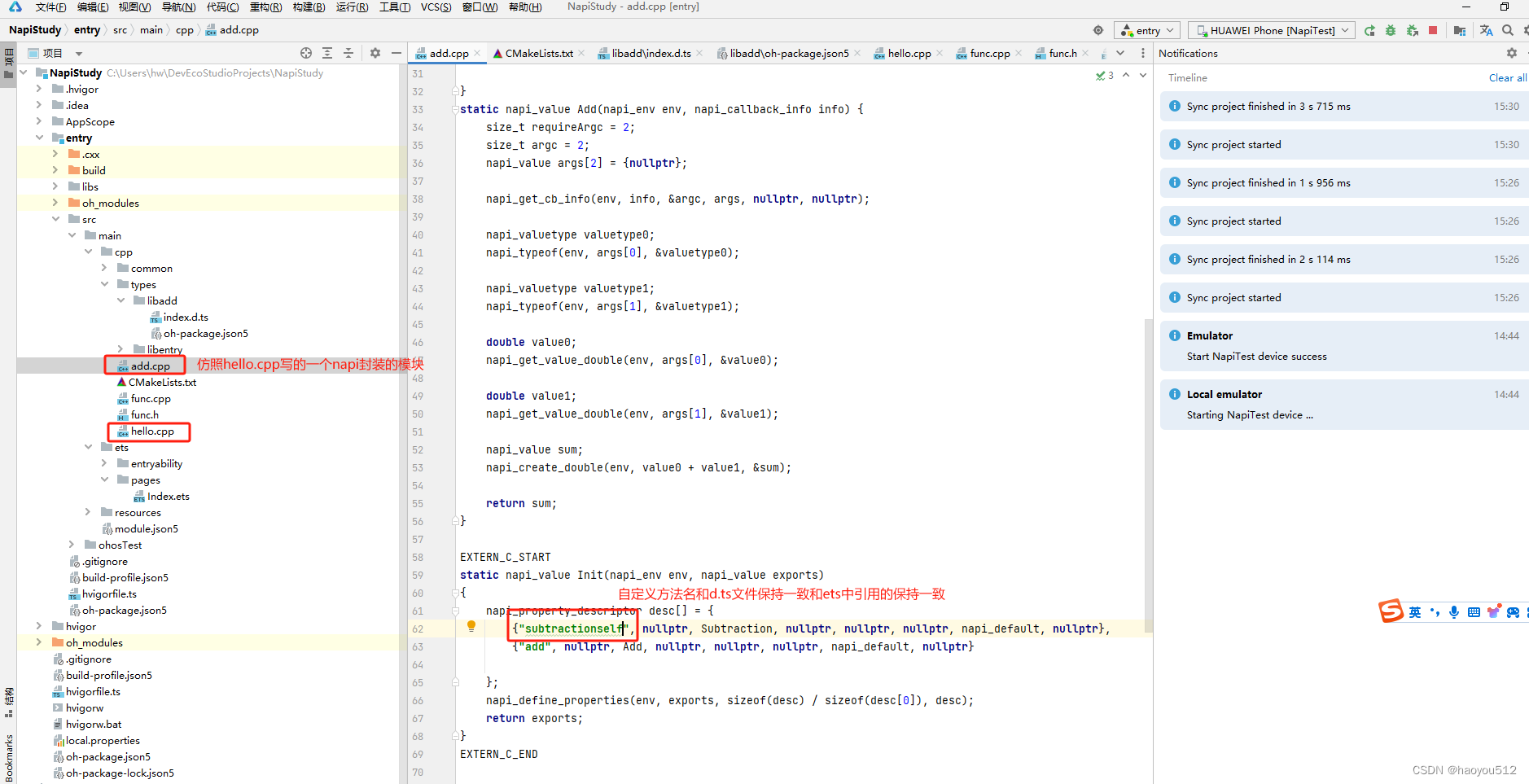
4 {"subtraction", nullptr, Subtraction, nullptr, nullptr, nullptr, napi_default, nullptr}: 定义一个属性描述符,属性名为 "subtraction",对应的处理函数是 Subtraction。
5 {"add", nullptr, Add, nullptr, nullptr, nullptr, napi_default, nullptr}: 定义另一个属性描述符,属性名为 "add",对应的处理函数是 Add。
6 napi_define_properties(env, exports, sizeof(desc) / sizeof(desc[0]), desc) 使用 napi_define_properties 函数将属性描述符数组 desc 定义到指定的 exports 对象中。
7 return exports;返回 exports 对象,这个对象包含了定义的属性描述符,将被导出到外部使用。
8 EXTERN_C_END: 这个宏定义可能是在 C++ 中用来指示代码块结束处,告诉编译器这部分代码是 C 风格的代码。2.3 解释sizeof(desc) / sizeof(desc[0])
在这个代码片段中,sizeof(desc) / sizeof(desc[0]) 是用来计算 desc 数组中的元素个数。下面详细解释一下:
sizeof(desc)得到整个desc数组占用内存的大小(以字节为单位)。sizeof(desc[0])得到数组中每个元素占用内存的大小。由于desc是一个napi_property_descriptor类型的数组,这里就是napi_property_descriptor结构的大小。- 当你将
sizeof(desc)除以sizeof(desc[0]),结果就是desc数组中napi_property_descriptor元素的数量。
3、Napi模块中调用自定义的fun.cpp方法
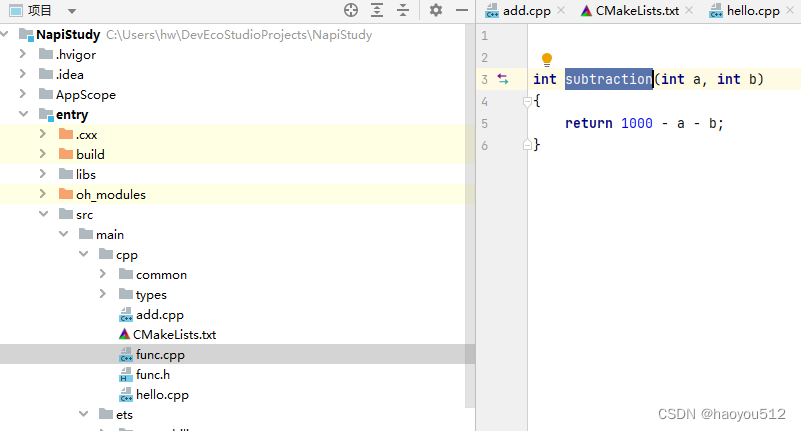
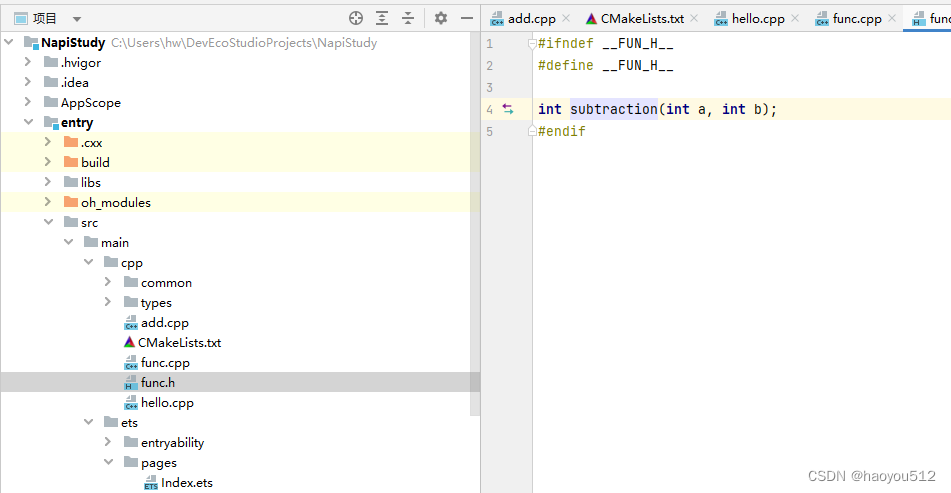
3.1、写一个c++的方法和头文件
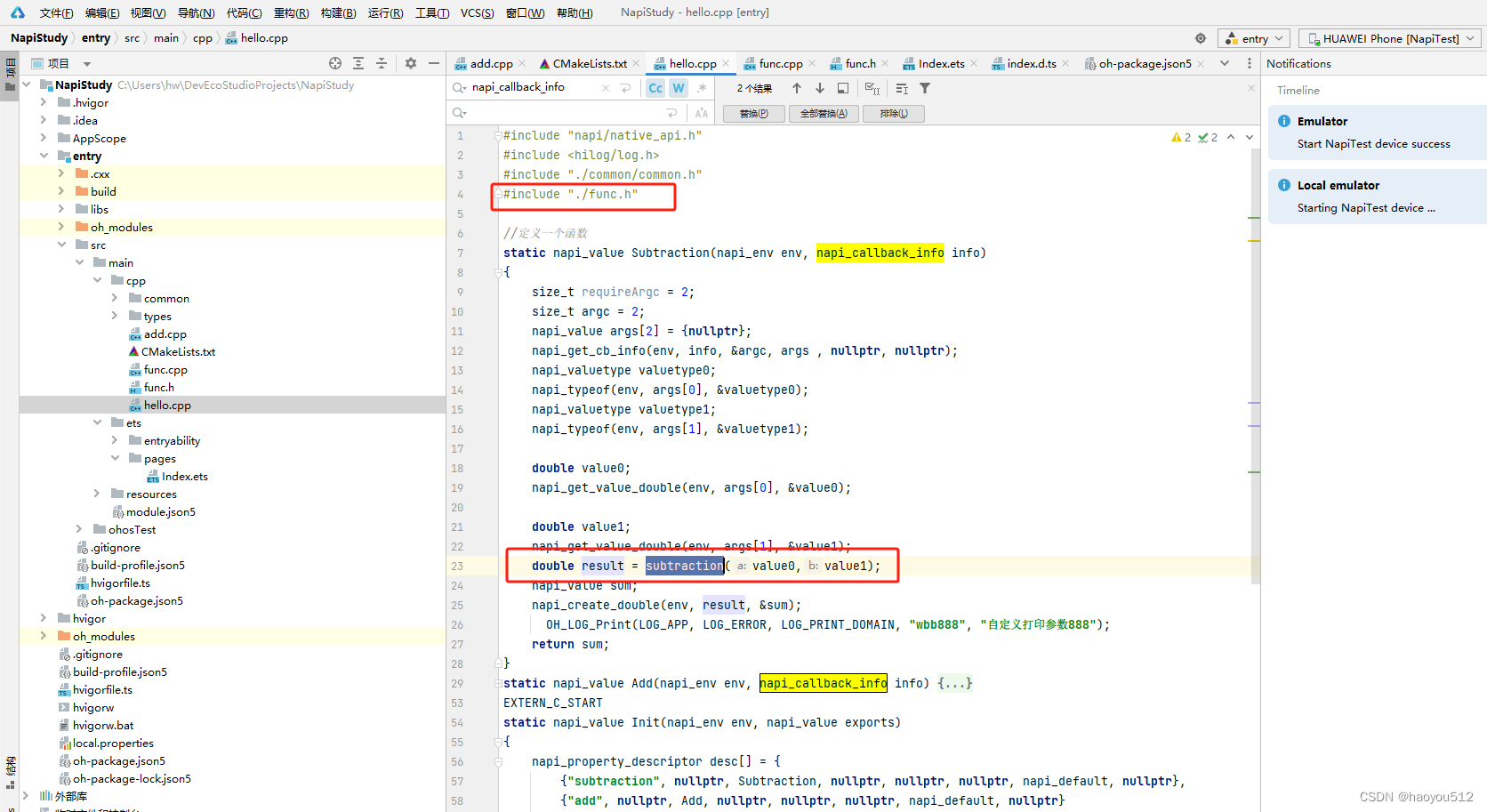
3.2 、引入头文件,然后调用头文件中定义的方法
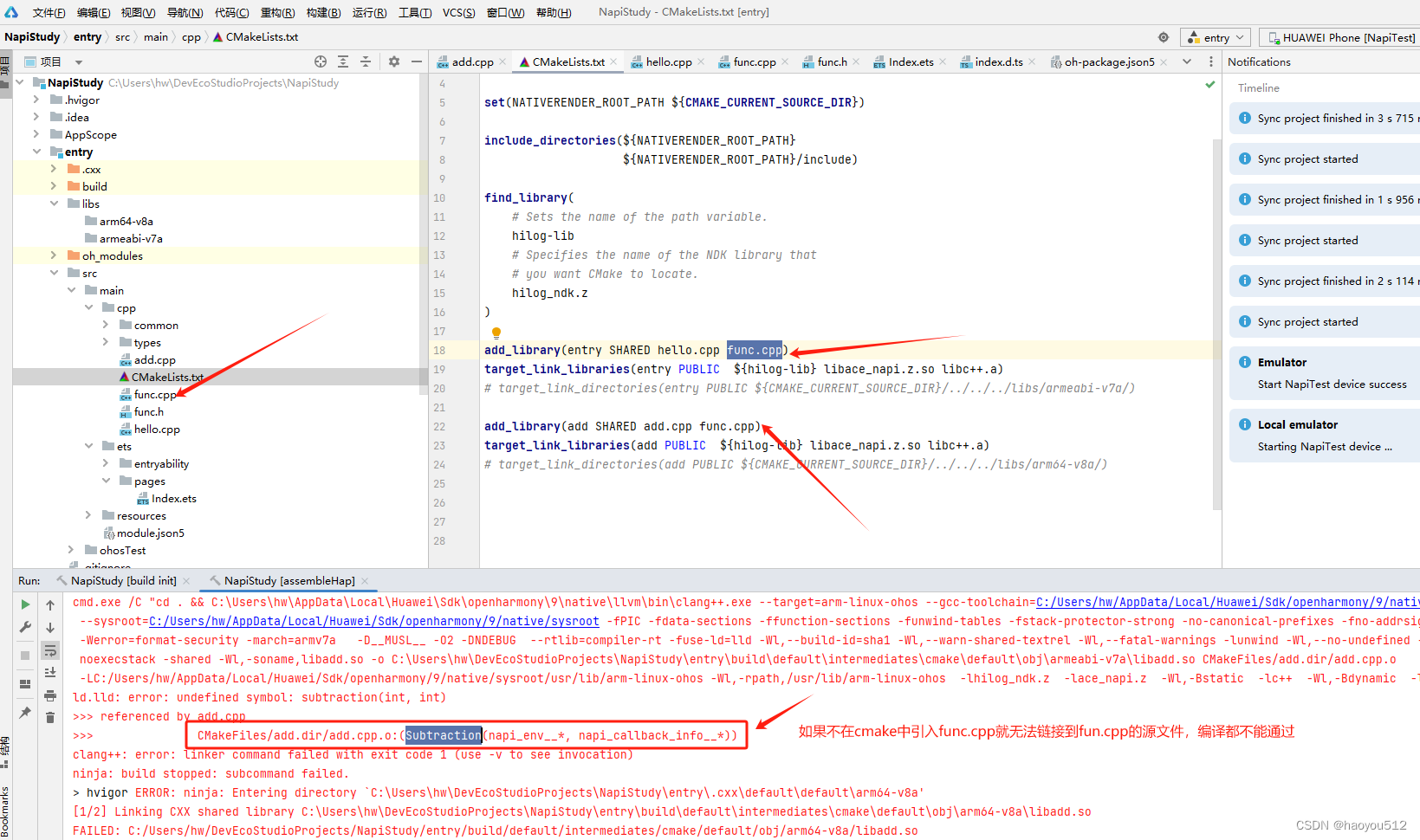
3.3、在cmake构建配置文件的过程中,添加func.cpp源文件,否则会编译报错
4、添加d.ts文件,让ets可以引用
4.1 新添加了一个add.cpp模块

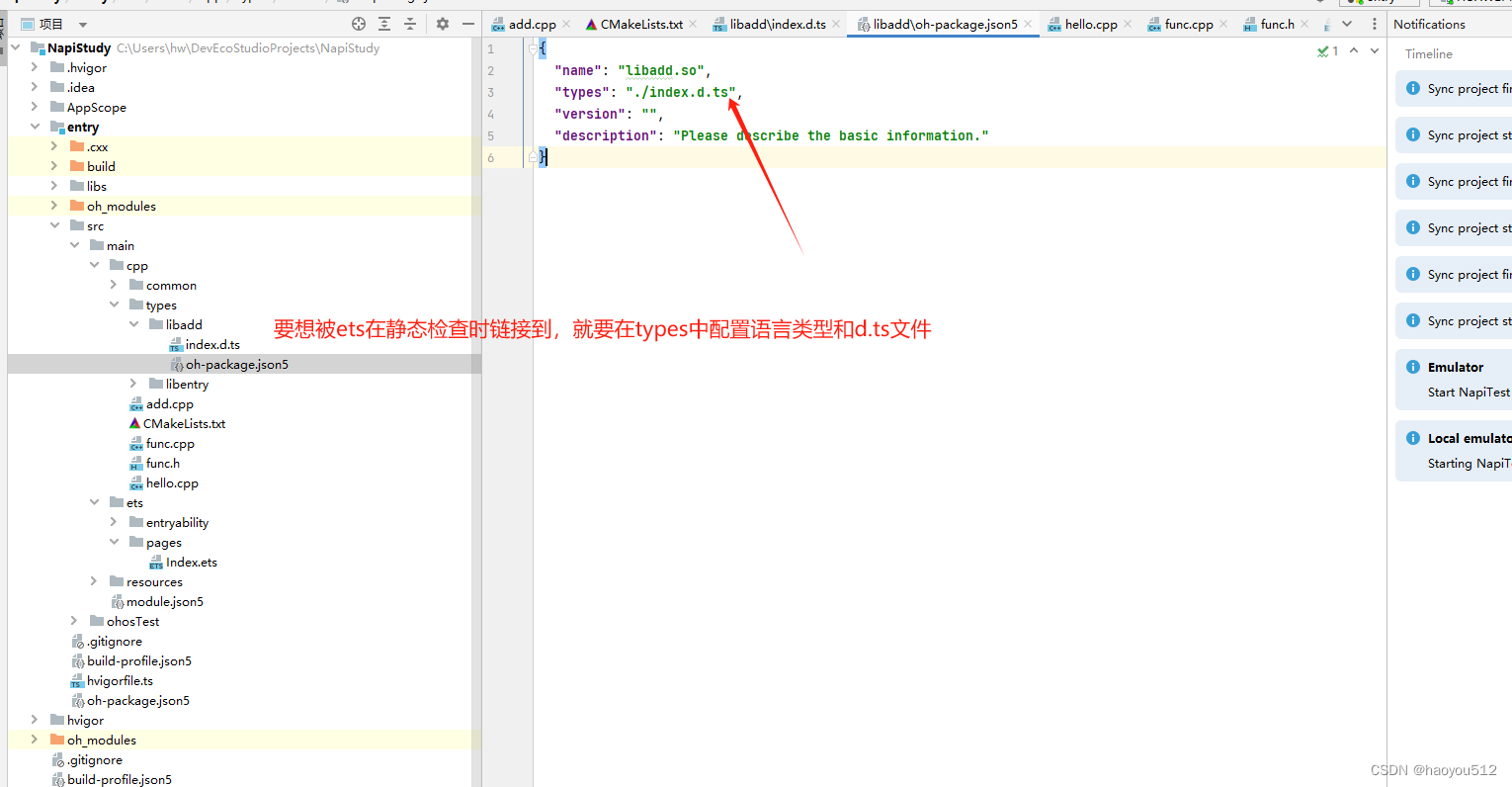
4.2 添加d.ts模块
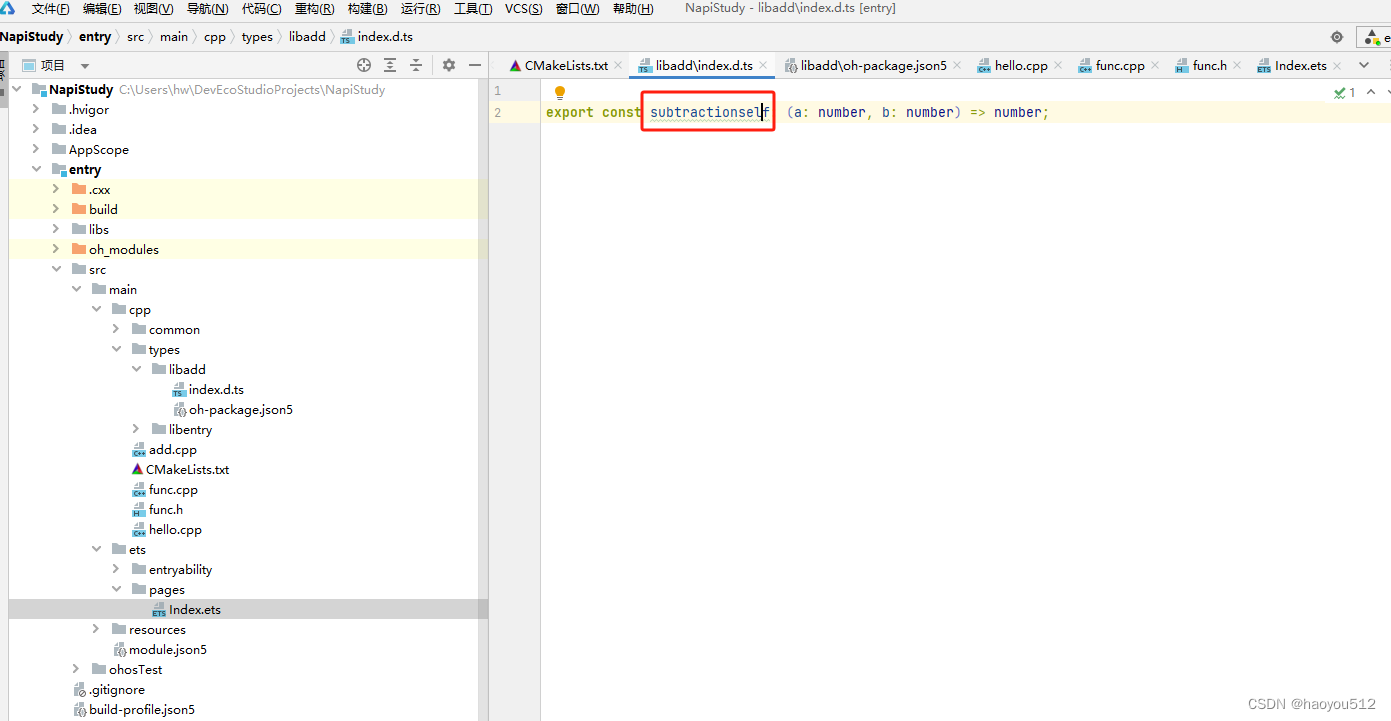
4.3 添加了d.ts模块,要想被ets在静态时检查到,需要配置entry/oh-package.json5下配置dependencies
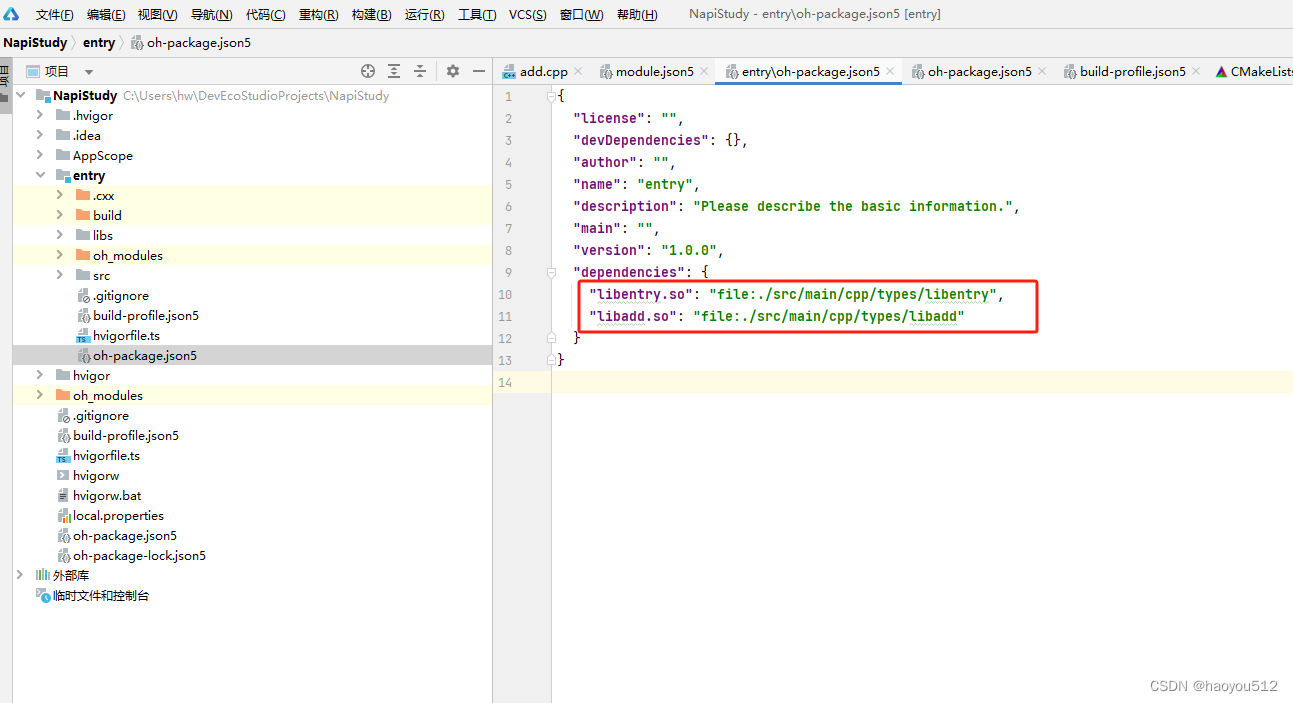
在这个上下文中,file: 表示依赖的库引用的是一个本地文件路径,而不是网络资源或者其他类型的引用。路径是通过相对路径给出的,. 表示当前目录。例如,对于 libentry.so,它的路径是 ./src/main/cpp/types/libentry:
./表示当前目录(通常是这个配置文件位于的目录)src/main/cpp/types/libentry是从当前目录开始到库文件libentry位置的相对路径。
因此,这行代码告诉系统或工具,它们可以在指定的相对路径下找到所需的库文件 libentry.so 和 libadd.so。示意图形如:
项目根目录
│
├── src
│ ├── main
│ │ ├── cpp
│ │ │ ├── types
│ │ │ │ ├── libentry (这里应该是 libentry.so 文件的路径)
│ │ │ │ ├── libadd (这里应该是 libadd.so 文件的路径)
│ ...
│
...
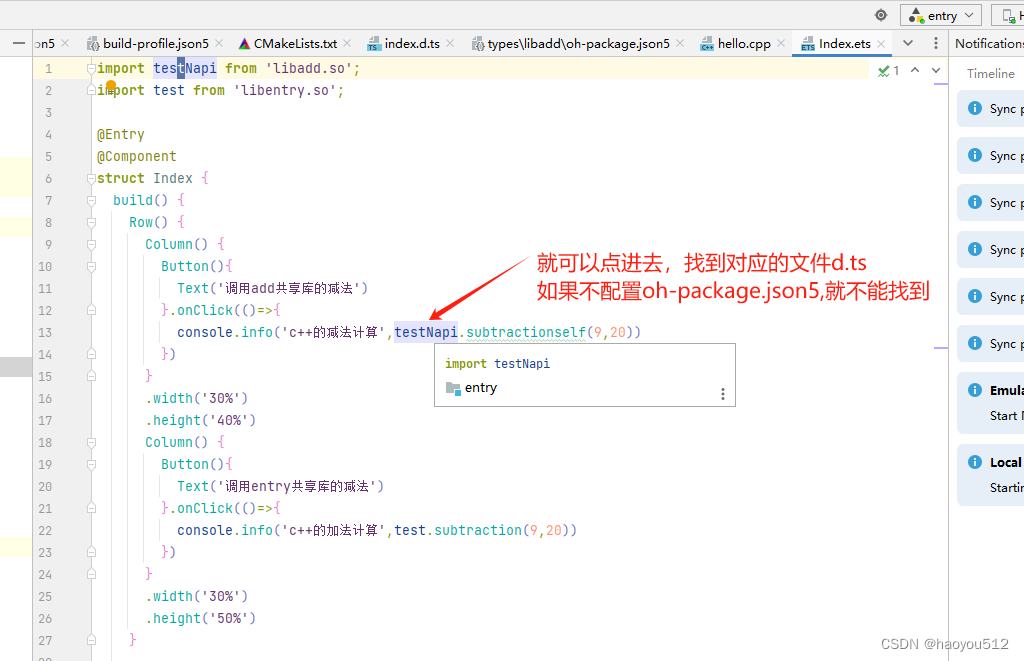
5、导入c++ 的so(共享资源库)和头文件
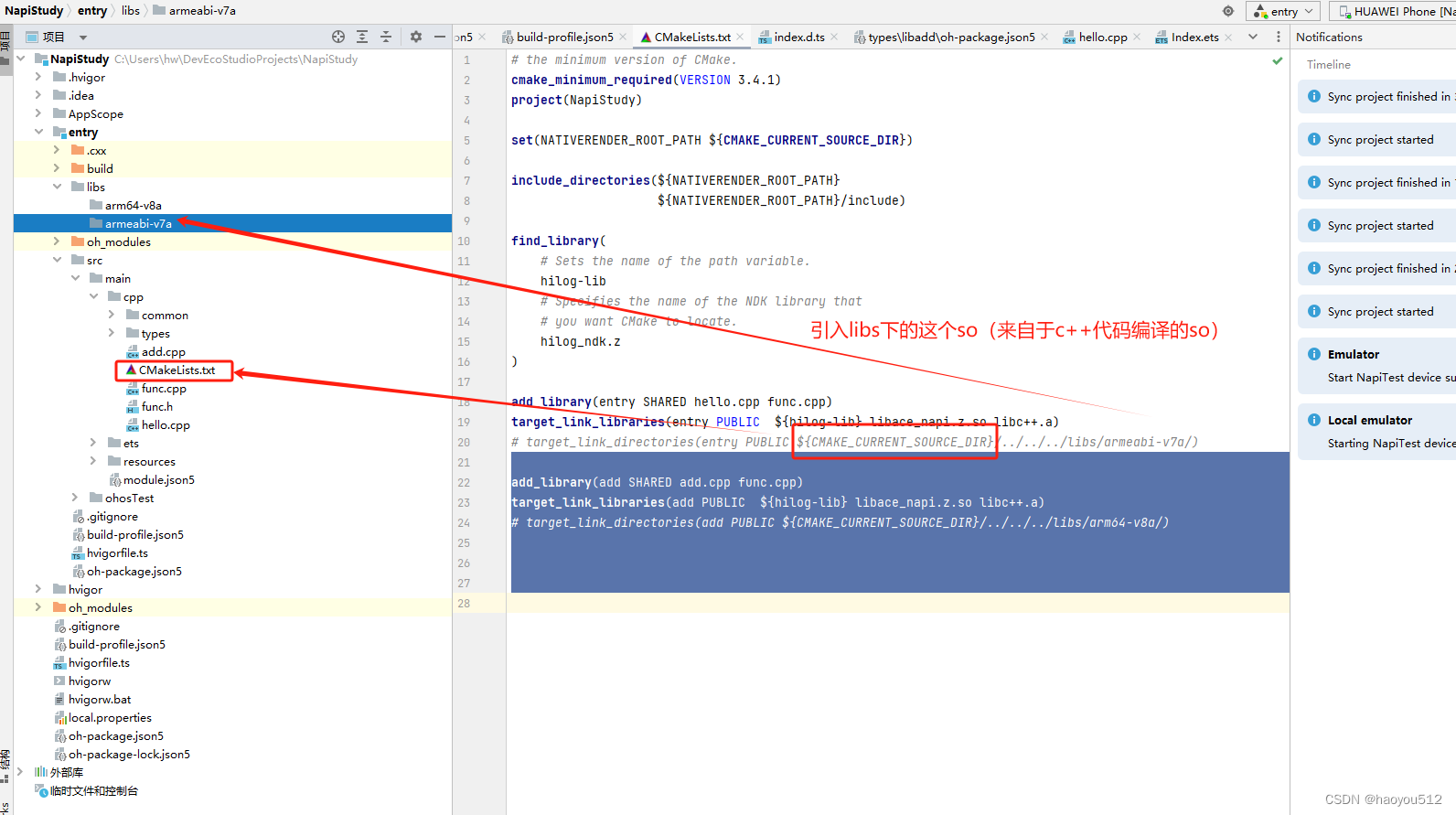
5.1 cmake中配置,需要target_link_directories 引入
5.2 在napi封装的模块中使用,需要引入头文件 .h的文件,参考新增一个c++方法
和添加c++代码一样,so(共享库)是一个编译好的可执行的资源文件,c++代码是未进行编译的资源。
5.3 同样需要添加.d.ts文件和在oh-package.json5中配置
只有进行配置,ets文件在静态时才能找到
6、本地编译之后的so路径
这个路径是我本地的,大家根据自己的配置查看。我的本地参考路径:C:\Users\hw\DevEcoStudioProjects\NapiStudy\entry\build\default\intermediates\cmake\default\obj\x86_64
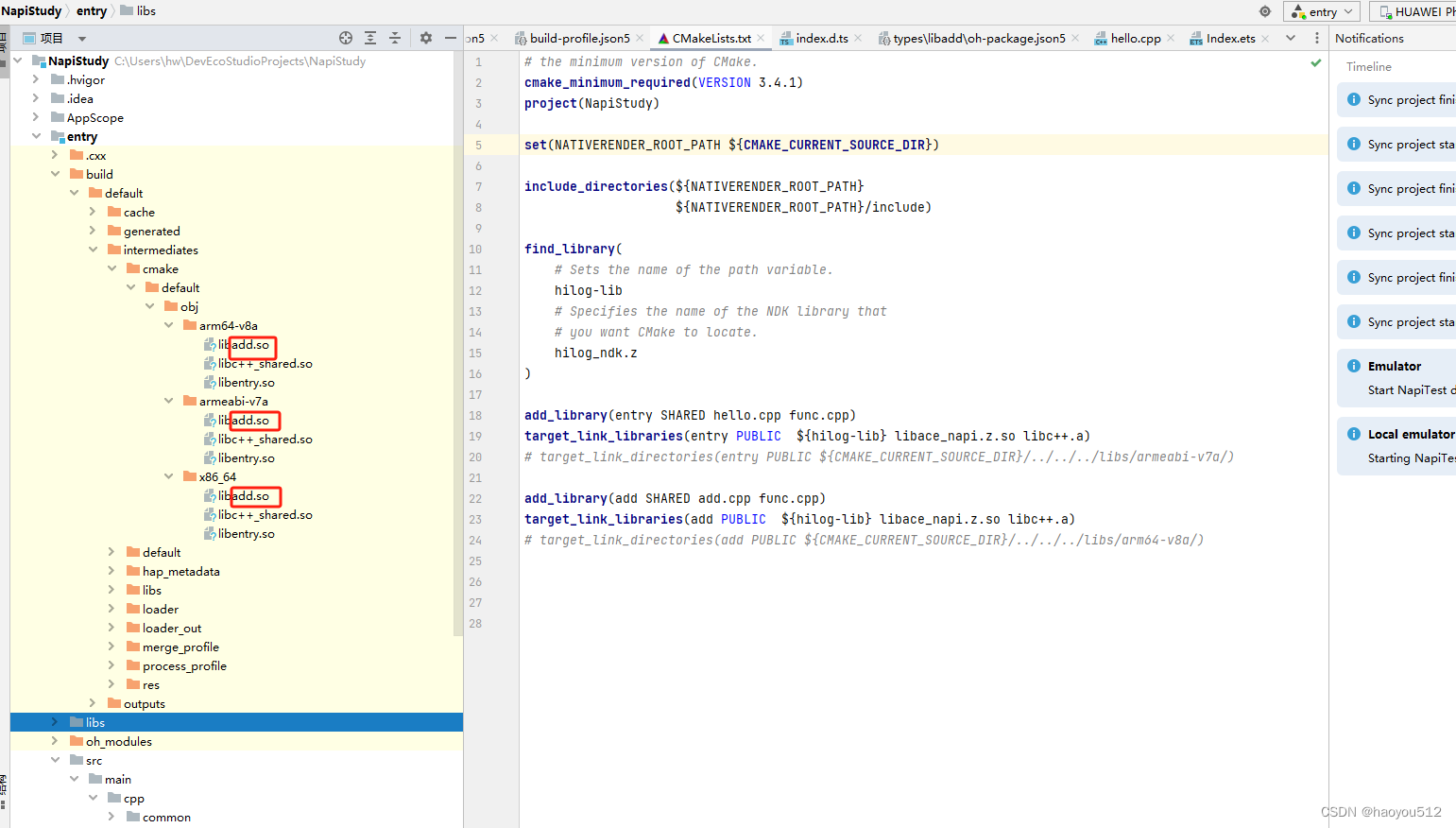
arm64-v8a, armeabi-v7a, 和 x86_64 这三个文件夹名字对应于不同的安卓平台架构,每个架构有其相应的指令集和特性。在为安卓应用打包共享库(.so 文件)时,你需要针对不同的硬件架构编译不同的版本,以确保最终的应用能在各种设备上正常运行。
下面是每个文件夹名字所对应的系统架构:
arm64-v8a:
这个架构是为支持64位 ARM 处理器(称为 ARMv8-A 架构)的设备编译的。
它提供 64 位计算的优势,并且常用于新型号的手机和平板电脑中。
armeabi-v7a:
这是适用于较老的设备的架构,支持 ARM v7 架构的 32位指令集。
虽然它是较旧的架构,但因为很多安卓设备还在使用这种处理器,支持它可以最大程度地兼容性老设备。
x86_64:
这个架构是针对使用 64 位 x86架构处理器的设备而设计的,这种处理器通常在安卓模拟器中使用,如 Android Studio 自带的模拟器,或者某些特殊的安卓设备和平板电脑。
对这个架构的支持使应用能在运行于 x86_64 架构的设备上提供更好的性能和更少的电源消耗。
在进行跨平台编译共享库文件时,通常需要使用对应的 NDK(Native Development Kit),并为每种目标架构设置合适的编译器和工具链。生成的每个架构的 .so 文件会被放置在相应命名的目录下,然后在应用打包时被包含进 APK 包内。安卓系统会根据设备架构自动选择并加载相应的库文件。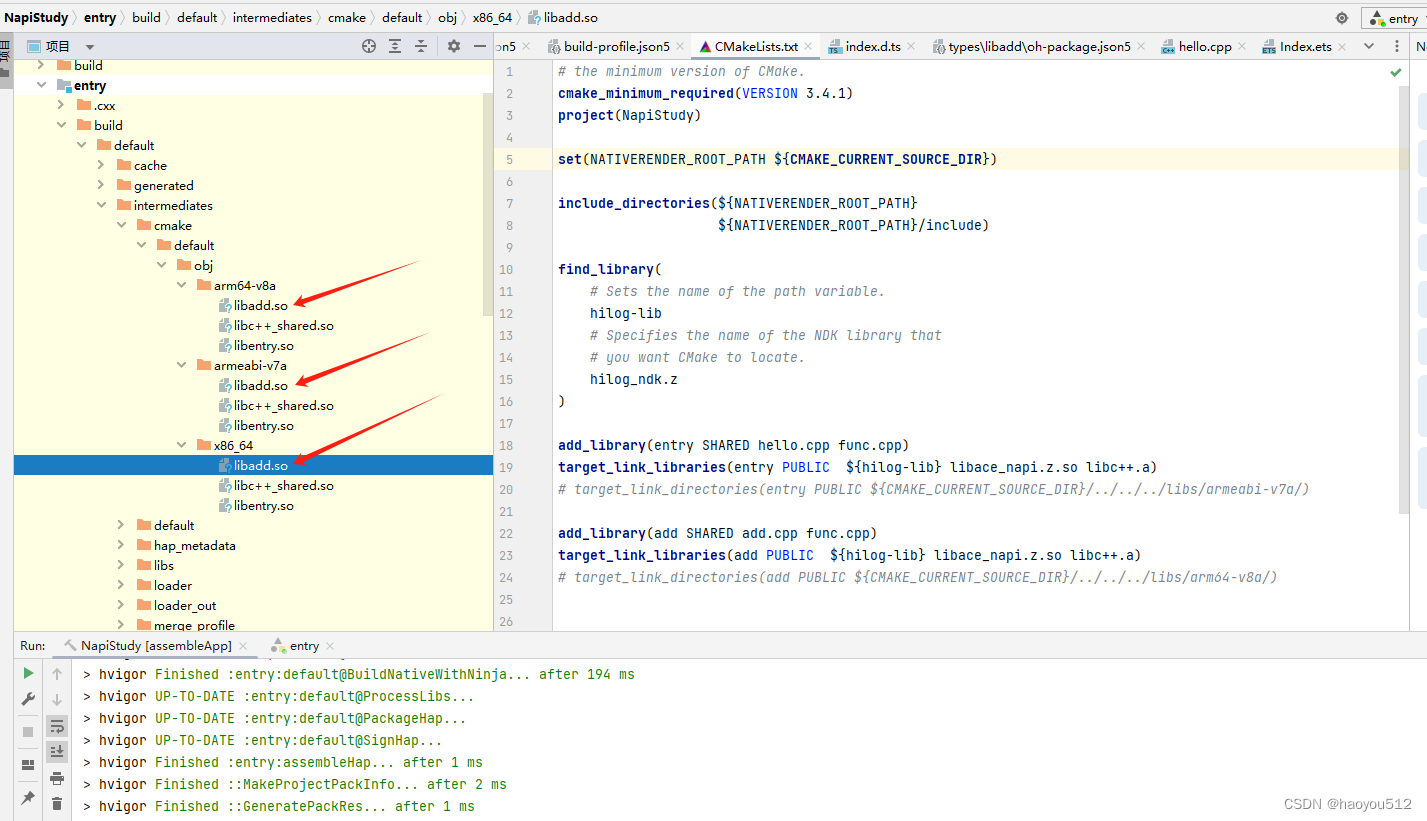
7、链接so库
想要链接so库,除了需要再cmake中配置,还需要在napi的封装过程中使用dlopen动态的打开查找可执行方法。鸿蒙基于安全考虑,在调用so中的方法时候,需要需从Arkts测传递so的沙箱路径。

















 1406
1406

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









