






前景提要:打开idea,选择maven,搜索quick
maven内容:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.kgc.kb09</groupId>
<artifactId>pratice</artifactId>
<version>1.0-SNAPSHOT</version>
<name>pratice</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</project>
1.MapReduce实现WordCount
流程图:
过程如下:
1.现在d盘创建一个test1文件夹,里面在加入一个a.txt
2.代码如下:
导入的包:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapper extends Mapper<LongWritable, Text,Text, IntWritable> {
@Override
//重写map方法
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//将每行转成string类型
String line = value.toString();
//在将每行的内容按照空格进行分割,并将分割后的value放到数组中
String[] words = line.split(" ");
//遍历分割后的word,并进行写,每写一个计数1
for (String word : words) {
context.write(new Text(word),new IntWritable(1));
}
}
}
导入的包:
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
代码:
public class WCReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int total=0;
for (IntWritable value : values) {
total+=value.get();
}
context.write(key,new IntWritable(total));
}
}
导入的包:
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
代码:
public class WCDriver {
public static void main(String[] args)throws Exception {
//1.建立连接
Configuration cfg=new Configuration();
Job job=Job.getInstance(cfg,"job_wc");
job.setJarByClass(WCDriver.class);
//2.指定mapper输出
job.setMapperClass(WCMapper.class);
//3.指定reducer输出
job.setReducerClass(WCReducer.class);
//4.指定mapper输出类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5.指定reducer输出类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6.指定输入输出路径(默认是hdfs路径,但想要其读取本地路径,则file:///)
FileInputFormat.setInputPaths(job,new Path("file:///D:/test1/a.txt"));
//输出路径必须不存在
FileOutputFormat.setOutputPath(job,new Path("file:///D:/test1/wcResult/"));
//7.判断是否结果是否成功输出
boolean result = job.waitForCompletion(true);
System.out.println(result?"成功":"失败");
//运行结束退出
System.exit(result?0:1);
}
}
最后结果可在本地文件中查看到。
2.分片
新建一个类
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
//接收map的输出
public class WCPartitioner extends Partitioner<Text, IntWritable> {
//第三个参数表示分片数,reducer有几个,i就为几
@Override
public int getPartition(Text text, IntWritable intWritable,int i) {
return text.hashCode()%i;
}
}
并在WCDriver类中增加
//补充:指定partitioner
job.setPartitionerClass(WCPartitioner.class);
job.setNumReduceTasks(4);
结果生成四个分片:
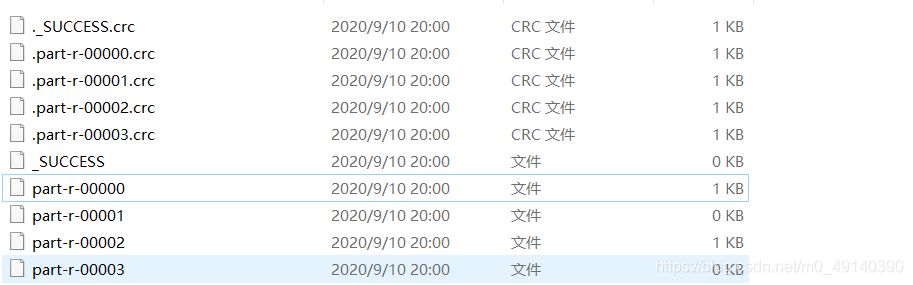
3.用hadoop运行jar包,并将文件上传到hdfs中
先打jar包:
点击ProjectStructure
选择Artifact,点击加号
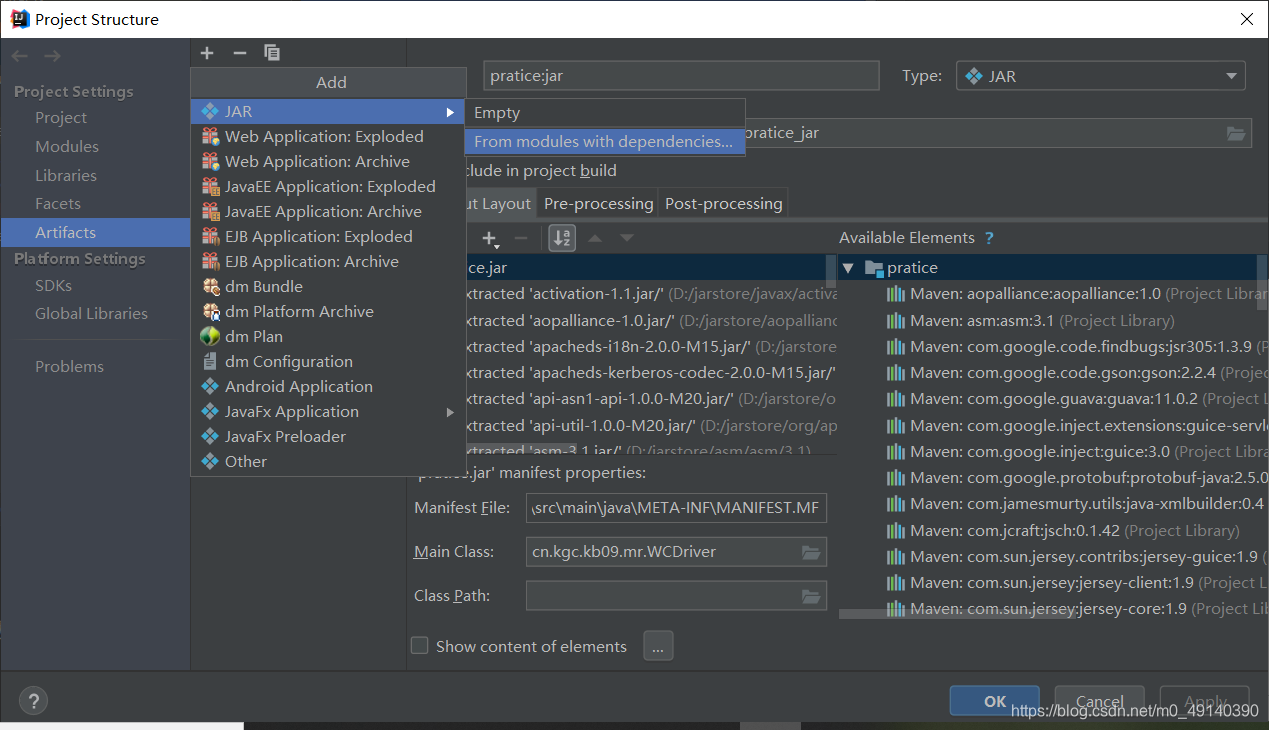
记得main class选择自己的main方法
点击apply,ok
点击build,然后再点击build artifacts,点击build
最后在out文件中,会出现jar包,右键点击show in explorer,将jar包拖到linux中
然后在linux中
hdfs dfs -mkdir /test/
再创建一个文本文件
vi a.txt
将文件上传到hdfs中
hdfs dfs -put a.txt /test/a.txt
使用mapreduce方法
hadoop jar pratice.jar cn.kgc.kb09.mr.WCDriver /test/a.txt /test/result
查看hdfs中的文件
hdfs dfs -cat /test/result/part-r-00000
2.MapReduce原理概览:
map读取文件,reduce进行计算
注:行的起始偏移量指一行的字节数
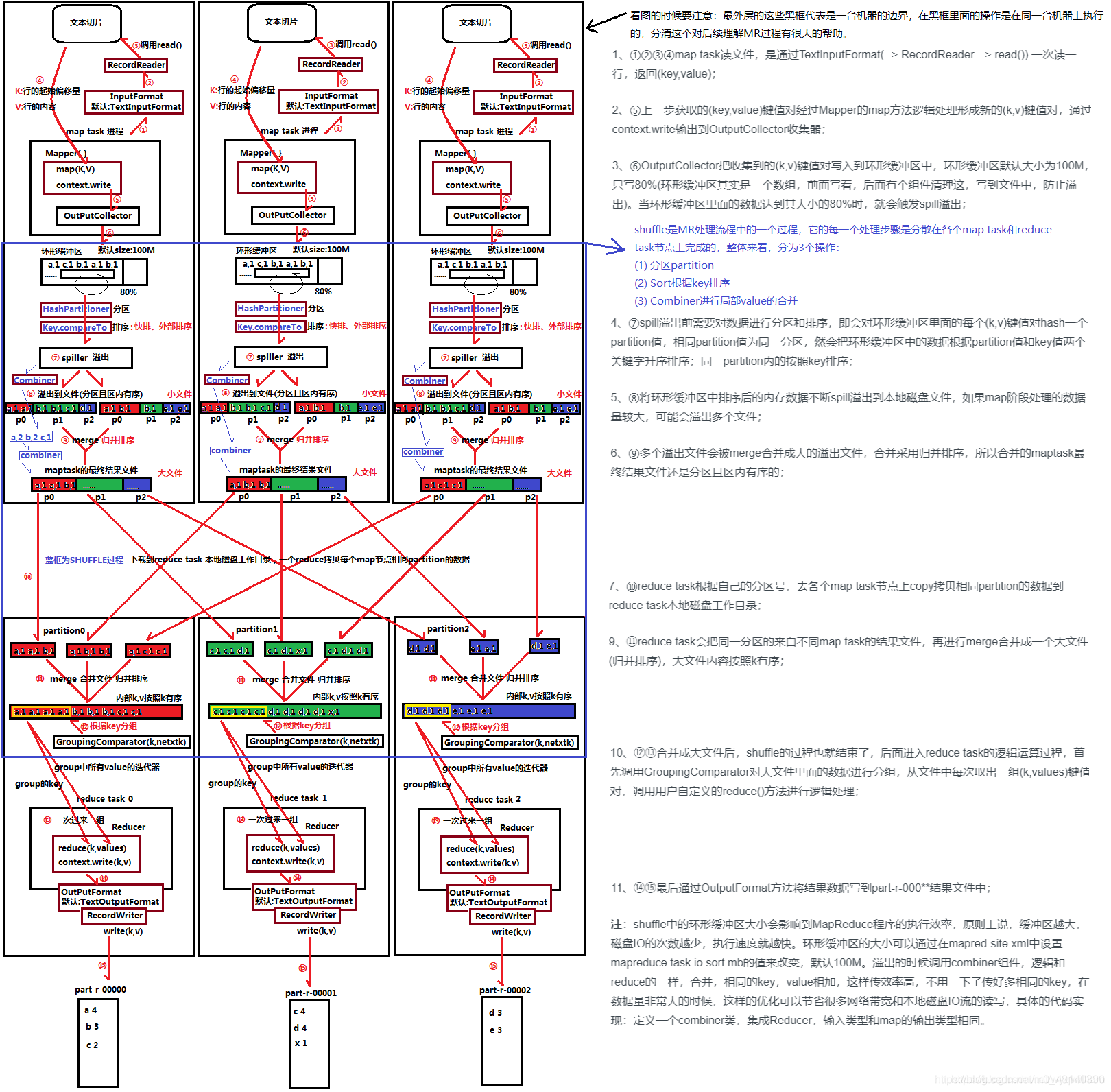
3.MAP端join
创建目录data,并放入两个文本
package pratice.join;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class CustomOrder implements Writable {
private String customId;
private String customName;
private String orderId;
private String orderStatus;
private String tableFlag;//为0时是custom表,为1是order表
@Override
public String toString() {
return
"customId='" + customId + '\'' +
", customName='" + customName + '\'' +
", orderId='" + orderId + '\'' +
", orderStatus='" + orderStatus + '\'' +
", tableFlag='" + tableFlag ;
}
public String getCustomId() {
return customId;
}
public void setCustomId(String customId) {
this.customId = customId;
}
public String getCustomName() {
return customName;
}
public void setCustomName(String customName) {
this.customName = customName;
}
public String getOrderId() {
return orderId;
}
public void setOrderId(String orderId) {
this.orderId = orderId;
}
public String getOrderStatus() {
return orderStatus;
}
public void setOrderStatus(String orderStatus) {
this.orderStatus = orderStatus;
}
public String getTableFlag() {
return tableFlag;
}
public void setTableFlag(String tableFlag) {
this.tableFlag = tableFlag;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(customId);
out.writeUTF(customName);
out.writeUTF(orderId);
out.writeUTF(orderStatus);
out.writeUTF(tableFlag);
}
@Override
public void readFields(DataInput in) throws IOException {
this.customId=in.readUTF();
this.customName=in.readUTF();
this.orderId=in.readUTF();
this.orderStatus=in.readUTF();
this.tableFlag=in.readUTF();
}
}
package pratice.join;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class WCMapperJoin extends Mapper <LongWritable, Text,Text, CustomOrder>{
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] columns = line.split(",");
CustomOrder co=new CustomOrder();
if(columns.length==4){//order表
co.setCustomId(columns[2]);
co.setCustomName("");
co.setOrderId(columns[0]);
co.setOrderStatus(columns[3]);
co.setTableFlag("1");
}else if (columns.length==9){
co.setCustomId(columns[0]);
co.setCustomName(columns[1]+"·"+columns[2]);
co.setOrderId("");
co.setOrderStatus("");
co.setTableFlag("0");
}
context.write(new Text(co.getCustomId()),co);
}
}
package pratice.join;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class COReducejoin extends Reducer <Text,CustomOrder,CustomOrder, NullWritable>{
@Override
protected void reduce(Text key, Iterable<CustomOrder> values, Context context) throws IOException, InterruptedException {
StringBuffer orderId=new StringBuffer();
StringBuffer statues=new StringBuffer();
CustomOrder customOrder=null;
for (CustomOrder co : values) {
if(co.getCustomName().equals("")){
orderId.append(co.getOrderId()+"|");
statues.append(co.getOrderStatus()+"|");
}else{
customOrder=co;
}
}
customOrder.setOrderId(orderId.toString());
customOrder.setOrderStatus(statues.toString());
context.write(customOrder, NullWritable.get());
}
}
package pratice.join;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class CODriver {
public static void main(String[] args)throws Exception {
Configuration cfg=new Configuration();
Job job=Job.getInstance(cfg,"co_job");
job.setJarByClass(CODriver.class);
job.setMapperClass(WCMapperJoin.class);
job.setReducerClass(COReducejoin.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(CustomOrder.class);
job.setOutputKeyClass(CustomOrder.class);
job.setOutputValueClass(CustomOrder.class);
FileInputFormat.setInputPaths(job,new Path("file:///D:/pratice914/data"));
FileOutputFormat.setOutputPath(job,new Path("file:///D:/test/a1"));
boolean result=job.waitForCompletion(true);
System.out.println(result?"执行成功":"执行失败");
System.exit(result?0:1);
}
}
4.reduce端jion
package pratice.join;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class StudentJoin implements Writable {
private String course;
private String stuId;
private String name;
private String score;
public String getCourse() {
return course;
}
public void setCourse(String course) {
this.course = course;
}
public String getStuId() {
return stuId;
}
public void setStuId(String stuId) {
this.stuId = stuId;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getScore() {
return score;
}
public void setScore(String score) {
this.score = score;
}
@Override
public String toString() {
return
"course='" + course + '\'' +
", stuId='" + stuId + '\'' +
", name='" + name + '\'' +
", score='" + score + '\''
;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(stuId);
out.writeUTF(name);
out.writeUTF(course);
out.writeUTF(score);
}
@Override
public void readFields(DataInput in) throws IOException {
this.stuId=in.readUTF();
this.name=in.readUTF();
this.course=in.readUTF();
this.score=in.readUTF();
}
}
package pratice.reducejoin;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import pratice.join.StudentJoin;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.net.URI;
import java.util.HashMap;
import java.util.Map;
public class COJoinMapper extends Mapper<LongWritable, Text,Text, StudentJoin> {
Map <String,String>map=new HashMap();
@Override
protected void setup(Context context) throws IOException, InterruptedException {
URI[] cacheFiles = context.getCacheFiles();
if(cacheFiles!=null&&cacheFiles.length>0){
String filePath = cacheFiles[0].getPath();
FileReader fr=new FileReader(filePath);
BufferedReader br=new BufferedReader(fr);
String line;
while((line=br.readLine())!=null&&!"".equals(line)){
String [] columns=line.split(",");
map.put(columns[0],columns[1]);
}
}
}
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line=value.toString();
String[] columns = line.split(",");
StudentJoin stu=new StudentJoin();
String stuid=columns[0];
String name=map.get(stuid);
String course=columns[1];
String score=columns[2];
stu.setStuId(stuid);
stu.setName(name);
stu.setCourse(course);
stu.setScore(score);
context.write(new Text(stuid),stu);
}
}
package pratice.reducejoin;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import pratice.join.StudentJoin;
import java.net.URI;
public class COJoinDriver {
public static void main(String[] args)throws Exception {
Job job=Job.getInstance(new Configuration(),"job_a");
job.setJarByClass(COJoinDriver.class);
job.setMapperClass(COJoinMapper.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(StudentJoin.class);
String inPath="file:///D:/pratice914/data/student_score.txt";
String outPath="file:///D:/test/a7";
String cachePath="file:///D:/pratice914/data/student.txt";
job.addCacheFile(new URI(cachePath));
FileInputFormat.setInputPaths(job,new Path(inPath));
FileOutputFormat.setOutputPath(job,new Path(outPath));
boolean result=job.waitForCompletion(true);
System.out.println(result?"执行成功":"执行失败");
System.exit(result?0:1);
}
}
5.补充:
1.mapreduce流 程
job-->TaskTracker-->Map/Reduce Task
resourcemanager-->app master-->container-->
scheduler
split-->map-->combiner-->partitioner-->reducer-->resoucemanager
2.hadoop1.0和2.0的区别
1.0管理和计算都是由mapreduce来完成
2.0管理由yarn负责,计算框架扩展
3.driver类的核心逻辑
Job对象-->指定driver类为驱动类-->设置map和reduce/partitioner -->设置mapper和reducer的输出类型-->设置输入输出文件路径-->运行
4.文件关联的逻辑
mapper端负责把文件合并,并且根据业务逻辑,把相同的key归类
reducer端负责根据相同的key进行关联
补充2:
1.mapjoin和reducejoin的区别
mapjoin是会利用cachefile接入数据,与map端接入的数据进行逻辑关联
不需要写reducer
reducejoin是map端只完成文件合并,利用相同的关联条件(例如id)作为key,输出到reduce端,reduce端根据key聚合达到关联的效果
2.shuffle















 3283
3283

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









