







使用requests爬取url带参数的网页源码,报“网络不给力,请稍后重试”错误的解决方法
原因:headers中添加了User-Agent
解决:登录百度账号刷新网页,再在headers中额外添加cookie信息
以爬取周杰伦百度搜索网页为例:
import requests
url = 'https://www.baidu.com/s?' #注意url参数通过data传递,也无需urlencode()编码
#headers中要添加登录账号之后的cookie,否则会反爬,报网络不给力的错
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36',
'Cookie' : '...' #此处的cookie我省略了,你们记得加上
}
data = {
'wd':'周杰伦'
}
response = requests.get(url = url ,params = data,headers = headers)
response.encoding='utf-8'
content = response.text
print(content)
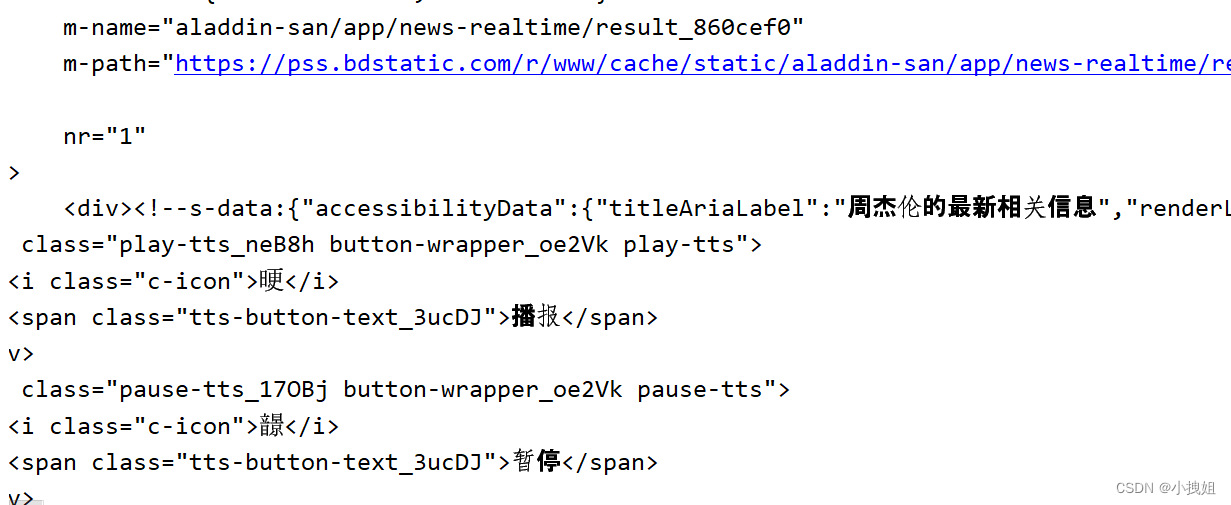
运行结果(打印输出网页源码):

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









