







1.kafka为什么快
1.数据压缩,减少网络IO,压缩格式包括Gzip、Snappy
2.批量传输,先将消息缓存在内存中,然后达到某个条件(比如到多少条数据,或者到几秒钟)就flush一次,flush到磁盘上
3.顺序读写,避免随机寻址,写入时是单个partition末尾添加
4.利用操作系统的page cache优化读写
5.零拷贝技术。在producer和consumer两个方面都使用了零拷贝技术。
网络数据持久化到磁盘 (Producer 到 Broker)。(使用了mmap)
磁盘文件通过网络发送(Broker 到 Consumer)。(使用了DMA)
零拷贝(Zero-copy)技术指在计算机执行操作时,CPU 不需要先将数据从一个内存区域复制到另一个内存区域,从而可以减少上下文切换以及 CPU 的拷贝时间。
2.kafka删除一个topic
Kafka删除一个topic会经历几个步骤:
- 首先判断要删除的topic是否存在
- 然后判断是否开启了删除功能,也就是说删除的那个配置是否为true,如果不是true,设置为false,则不会删除,只会将其进行标记
- 再判断是否有正在进行重分配的topic,topic重分配会导致partition中的数据在broker中转移
- 如果上述三个都可以,执行删除命令
- 删除某个topic,其实删除的就是topic下面的partition的数据,此外每个Partition还有主从备份的机制,主备都要删,然后再删除zookeeper里面的数据,因为zookeeper里面管理着kafka的元数据
3..如果一个leader挂掉后,所有的follower都有机会成为leader吗
不是,kafka有一个ISR OSR副本同步队列机制。ISR表示只有跟的上leader的follower才可以进入ISR队列,否则只能呆在OSR队列。因为ISR的机制就保证了,处于ISR内部的follower都是可以和leader进行同步的,一旦出现故障或延迟,就会被踢出ISR。如果Leader挂掉之后,只有ISR中的follower才有机会成为新的leader。
4.follower的作用
读写都是由leader处理,follower只是作备份功能,不对外提供服务。
5.kafka如果保证数据一致性
通过ISR + High WaterMark
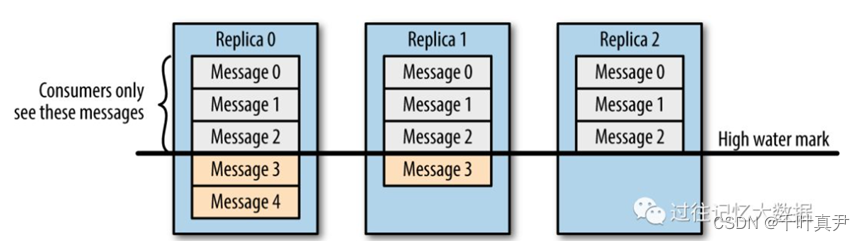
假设有一主(replica 0)两备(replica 1 replica 2),两备都是在ISR队列中
其中leader数据已经写到了Message4,replica1写到了Message3,replica2写到了Message2。但是consumer只能读取到Message2的数据。
这个比较类似木桶原理,就是consumer读取到的数据永远是ISR队列中所有数据的最小值。在上述情况中,最小值为Message2,因此High WaterMark就是Message2。
原因是因为如果leader挂掉了,但是consumer读取到了原来leader中的Message4的数据,当选出新的leader之后,consumer再次读取,发现读不到Message4了,这就是数据不一致的表现,因此consumer读取到的数据永远都是在High WaterMark之上的数据,也就是ISR中的最小偏移量。
6.kafka如何保证数据全局有序
将同一个特征的数据写到同一个分区。
7.kakfa有几个分区,分区的消费策略有哪些
kafka分区数:
3个
consumer partition分配策略:
roundrobin策略
range策略
8.Kafka为什么同一个消费者组的消费者不能消费相同的分区
kafka设计的是同一个消费者组里面的消费者不能消费相同的分区,这样设计是有原因的。因为消费者端是pull模式,也就是消费者主动向kafka拉取数据,同时通过offset记录自己消费到哪里了,这个offset是由消费者掌管的。如果同一个消费者组里面不同的消费者可以消费同一个分区,会导致重复消费的问题,比如在同一个消费者组里面,消费者1的offset记录到了10,也就是消费了10条数据,消费者2的offset记录到了5,也就是消费者5条数据,那么其实消费者2的这5条数据是重复消费了的,并且也不能保证读取的顺序。
9.Kafka分区数可以增加或减少吗
我们可以使用bin/kafka-topics.sh命令对kafka增加分区数据,但是kafka不支持减少分区数
kafka不支持减少分区数是有很多原因的?
1)删除的话,没消费的消息就丢了
按照Kafka现有的代码逻辑而言,此功能完全可以实现,不过也会使得代码的复杂度急剧增大。实现此功能需要考虑的因素很多,比如删除掉的分区中的消息该作何处理?如果随着分区一起消失则消息的可靠性得不到保障;如果需要保留则又需要考虑如何保留。直接存储到现有分区的尾部,消息的时间戳就不会递增,如此对于Spark、Flink这类需要消息时间戳(事件时间)的组件将会受到影响;如果分散插入到现有的分区中,那么在消息量很大的时候,内部的数据复制会占用很大的资源,而且在复制期间,此主题的可用性又如何得到保障?















 393
393











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









