







1、HARDWARE-ORIENTED APPROXIMATION OF CONVOLUTIONAL NEURAL NETWORKS(卷积神经网络的面向硬件的逼近);2、Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference(神经网络的量化与训练)
- 定点数和浮点数
- 第一篇:HARDWARE-ORIENTED APPROXIMATION OF CONVOLUTIONAL NEURAL NETWORKS(卷积神经网络的面向硬件的逼近)
- 6、 CONCLUSION AND FUTURE WORK--6个结论和未来的工作
- 第二篇:Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference(高效整数算术推理的神经网络量化与训练)----2017
- Abstract
- 1. Introduction
- 2. Quantized Inference
- 3. Training with simulated quantization---采用模拟量化的方式进行训练
- 3.1. Learning quantization ranges---学习量化的范围
- 3.2. Batch normalization folding---匹标准化折叠
- 4. Experiments
- 5. Discussion
- A. Appendix: Layer-specific details----A.附录:特定于图层的详细信息
- B. Appendix: ARM NEON details--
- C. Appendix: Graph diagrams---图标
- D. Experimental protocols--实验方案
- D.3. COCO detection protocol--COCO检测协议
- D.4. Face detection and face attribute classification protocol---人脸检测和人脸属性分类协议
Integer-Arithmetic-Only Inference(神经网络的量化与训练)
定点数和浮点数

在计算机中,通常是用定点数来表示整数和纯小数,分别称为定点整数和定点小数。
对于既有整数部分、又有小数部分的数,- -般用浮点数表示。
(3)浮点数:
浮点数是属于有理数中某特定子集的数的数字表示,在计算机中用以近似表示任意某个实数。
具体的说,这个实数由一个整数或定点数(即尾数)乘以某个基数(计算机中通常是2)的整数次幂得到,这种表示方法类似于基数为10的科学记数法。
浮点数在计算机中用以近似表示任意某个实数。浮点计算是指浮点数参与的运算,这种运算通常伴随着因为无法精确表示而进行的近似或舍入。
一个浮点数a由两个数m和e来表示: a= m x be。在任意一个这样的系统中,我们选择一个基数b (记数系统的基)和精度p (即使用多少位来存储)。m (即尾数)是形如d.dd…ddd的p位数 (每一 位是一个介于0到b-1之间的整数,包括0和
b-1)。如果m的第- -位是非0整数, m称作规格化的。
有一些描述使用一个单独的符号位(S 代表+或者-)来表示正负,这样m必须是正的。e是指数。这种设计可以在某个固定长度的存储空间内表示定点数无法表示的更大范围的数。例如,-个指数范围为+4的4位十进制浮点数可以用来表示43210, 4.321或0.0004321, 但是没有足够的精度来表示432.123和43212.3 (必须近似为432.1和43210)。当然,实际使用的位数通常远大于4。此外,浮点数表示法通常还包括一些特别的数值: +∞和-∞(正负无穷大)以及NAN。
其他知识参考:https://wenku.baidu.com/view/b3c58d672d3f5727a5e9856a561252d381eb204f.html
定点数是啥?
从字面意思来理解,“定点数”就是“点”不动的数。那么究竟是什么“点”不动呢?没错,就是“小数点”。
在上一讲我们说道,不论是整数还是小数,都是有小数点的。整数的小数点表示在最后一位数字的后面,而小数的小数点标识在真值的符号位后面。
第一篇:HARDWARE-ORIENTED APPROXIMATION OF CONVOLUTIONAL NEURAL NETWORKS(卷积神经网络的面向硬件的逼近)
被接受为2016年ICLR大会上的研讨会贡献
code:量化和微调代码:1https://github.com/pmgysel/caffe
学校:加州大学戴维斯分校(University of California, Davis)
Abstract
较高的计算复杂度阻碍了卷积神经网络的广泛应用,特别是在移动设备上。 硬件加速器可以说是减少执行时间和功耗的最有前途的方法。加速器开发中最重要的步骤之一是面向硬件的模型逼近。在本文中,我们提出了Ristrecto,一个模型逼近框架,它分析了一个给定的CNN关于用于表示卷积和全连接层的权重和输出的数值分辨率。Ristrecto模型逼近框架可以通过使用定点运算来表示而不是浮点表示来压缩模型。此外,Ristrecto模型逼近框架还对所得到的不动点网络进行了细化。Given a maximum error tolerance of 1%, Ristretto can successfully condense CaffeNet and SqueezeNet to 8-bit.(在最大误差容忍度为1%的条件下,Ristrecto可以成功地将CaffeNet and SqueezeNet网压缩到8位。)The code for Ristretto is available。
1 、INTRODUCTION
在每年举行的ILSVRC竞赛中,深度网络实现了最先进的分类精度,如克里热夫斯基等人的AlexNet(2012)、西蒙扬和齐塞曼的VGG(2015)Simonyan & Zisserman (2015)、谷歌网(Szegedy等人,2015)和ResNet(He等人,2015)–GoogleNet (Szegedy et al., 2015) and ResNet (He et al., 2015)的分类精度。这些网络包含数百万个参数,并且需要数十亿次的算术运算。
已经提出了各种解决方案来减少cnn的资源需求。与浮点算法相比,固定点算法对资源的消耗更少。此外,它已经证明了不动点算法对于神经网络的计算是足够的(Hammerstrom, 1990—哈默斯特罗姆,1990)。这一观察结果最近被用来浓缩深层cnn。Gupta等人(2015)表明,在CIFAR-10(10个图像类)等数据集上的网络可以在16位内进行训练。对同一网络的进一步修剪使用了低至7位的乘数器(Courbariaux等人,2014)。Courbariaux等人(2016)的另一种方法是使用二元权值和激活,同样是在同一网络上。
深度cnn的复杂性可以分为两部分。首先,卷积层包含了超过90%的所需的算术运算。通过将这些浮点运算转化为小定点数的运算(通过将这些浮点运算转化为具有较小固定点数的运算),可以显著降低芯片面积和能耗。第二种资源密集型层类型是全连接的层,其中包含90%以上的网络参数。作为使用位宽减少固定点数的一个很好的副产品,全连接层的数据到芯片外存储器的数据传输减少了。在本文中,我们只关注于逼近卷积层和全连通层。利用定点算法是一种硬件友好的cnn近似方法。它允许使用更小的处理元素,并减少了内存需求,而不增加任何计算开销,如解压缩。
尽管已经证明cnn在较小的定点数下表现良好,但目前还没有对位宽减少和精度损失之间的微妙权衡进行彻底的研究。在本文中,我们提出了一个弹性图,它可以自动地在位宽减小和给定的能容忍的最大误差之间找到一个完美的平衡。ristrecto对任何给定的网络进行快速和全自动的修剪分析。这个训练后的工具可以用于神经网络的特定应用程序的修剪。
2、MIXED FIXED POINT PRECISION(混合不动点精度)
在接下来的两节中,我们将讨论浮点CNN到不动点的量子化。此外,我们还解释了动态不动点,并展示了如何利用它来进一步减小网络规模的同时保持分类精度。

全连接层和卷积层的数据路径由一系列的MAC操作(乘法和积累)组成,如图1所示。层激活与网络权值相乘,结果累积形成输出。如Qiu等人(2016)所示,使用混合精度是一种很好的方法,即CNN的不同部分使用不同的位宽。
在图1中,m和n分别表示层输出和层权值的位数。乘法结果是使用最后越来越厚的加法器树累积的。第一级的加法器输出为m+n+2位宽,每一级的位宽增加1位。在最后一级中,位宽为m+n+lg2x,其中x是每个输出值的乘法运算次数。在最后一个阶段,添加偏置以形成层的输出。对于每个网络层,我们需要在减少比特宽(m和n)和保持良好的分类精度之间找到正确的平衡。
3、 DYNAMIC FIXED POINT(浮点数)
CNN的不同部分有一个显著的动态范围。在更大的层中,输出是数千次累积的结果,因此网络参数比层的输出要小得多。定点数只有有限的能力来覆盖一个广泛的动态范围。动态定点数(威廉姆森,1991;courbariaux等人,2014)是这个问题的解决方案。
在动态定点数中中,每个数字表示如下: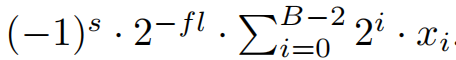 这里B表示位宽,s符号位,fl是分数长度,x表示尾数位。网络中的中间值有不同的范围。因此,希望将固定点数分配给几个fl(分数长度)恒定的组,这样分配给分数部分的位数在该组内是恒定的。每个网络层被分成两组:一个用于层的输出,一个用于层的权重。这允许更好地覆盖两层输出和权重的动态范围,因为权重通常要小得多。在硬件方面,可以利用移位器实现动态不动点算法。
这里B表示位宽,s符号位,fl是分数长度,x表示尾数位。网络中的中间值有不同的范围。因此,希望将固定点数分配给几个fl(分数长度)恒定的组,这样分配给分数部分的位数在该组内是恒定的。每个网络层被分成两组:一个用于层的输出,一个用于层的权重。这允许更好地覆盖两层输出和权重的动态范围,因为权重通常要小得多。在硬件方面,可以利用移位器实现动态不动点算法。
人们已经提出了不同的神经网络部署硬件加速器(Motamedi等人,2016;邱等人,2016;Han等人,2016a)。加速器设计的第一个重要步骤是对相关网络的压缩。在下一节中,我们将介绍Ristrecto这个工具,它可以以快速和自动化的方式浓缩任何神经网络。
4、 RISTRETTO: APPROXIMATION FRAMEWORK IN CAFFE
From Caffe to Ristretto
根据维基百科的说法,Ristretto是“一小杯浓缩咖啡,用正常量的磨碎咖啡制成,但用大约一半的水提取”。同样,我们的压缩器删除了CNN中不必要的部分,同时确保保留其本质——预测图像类别的能力。Caffe(Jia等人,2014年)拥有强大的社区和针对深度CNN的快速训练,是一个很好的架构。
Ristrecto将一个训练过的模型作为输入,并自动生成一个压缩的网络版本。Ristrecto的输入和输出是一个网络描述文件(原生协议)和网络参数。可选地,量化网络可以用弹性拉伸进行微调。所得到的caffe格式的不动点模型可以用于硬件加速器

Quantization flow(没看懂)
Ristrecto的量化流有五个阶段(图2),将浮点网络压缩为固定点。在第一步中,分析了权值的动态范围,以找到一个良好的定点表示。对于从浮点到不动点的量化,我们使用圆最近法。第二步以前进的路径运行数千张图像。分析生成的层激活情况,以生成统计参数。Ristrecto在固定点数的整数部分使用足够的位,以避免层激活的饱和。接下来,Ristrecto执行二进制搜索,以找到卷积权值、全连接权值和层输出的最佳位数。在这个步骤中,某个网络部分被量化,而其余部分保持在浮点状态。由于有三个网络部分应该使用独立的位宽(卷积层和全连接层的权值以及层输出),迭代量化一个网络部分允许我们找到每个部分的最佳位宽。一旦在小数表示和分类精度之间找到良好的权衡,就得到定点网络
Fine-tuning
为了弥补量化导致的精度下降,在 Ristretto(/实时化中)对定点网络进行了精调。在这个再训练过程中,网络学习如何对具有定点参数的图像进行分类。由于网络权值只能有离散值,主要的挑战在于权值更新。我们采用了之前的工作(Courbariauxetal.,2015)的想法,它使用了全精度的阴影权重。小权值更新∆w应用于全精度权值w,而离散权值w0则从全精度权值中采样。微调过程中的采样是通过随机舍入来完成的。Gupta等人(2015)成功地将该舍入方案用于16位定点网络的权重更新。
Ristrecto使用了图3所示的微调过程。对于每一批,全精度权重被量化到固定点。在前向传播过程中,这些离散的权值被用来计算层的输出yl。每一层l根据其函数fl:(xl,w0)→yl,将其输入批xl转换为输出yl。假设最后一层计算损失,我们将f表示为整体的CNN函数。

The goal of back propagation is to compute the error gradient δf /δw with respect to each fixed point parameter. For parameter updates we use the Adam rule by Kingma & Ba (2015). As an important observation, we do not quantize layer outputs to fixed point during fine-tuning. We use floating point layer outputs instead, which enables Ristretto to analytically compute the error gradient with respect to each parameter. In contrast, the validation of the network is done with fixed point layer outputs.
反向传播的目标是计算关于每个定点参数的误差梯度δf/δw。对于参数更新,我们使用Kingma&Ba(2015)的Adam rule。作为一个重要的观察结果,我们在微调过程中不量化层输出到定点点。我们而是使用浮点层输出,这使Ristretto能够分析计算对每个参数的误差梯度。相比之下,该网络的验证是用定点层输出来完成的。
To achieve the best fine-tuning results, we used a learning rate that is an order of magnitude lower than the last full precision training iteration. Since the choice of hyper parameters for retraining is crucial (Bergstra & Bengio, 2012), Ristretto relies on minimal human intervention in this step.
为了获得最佳的微调结果,我们使用了一个比最后一次全精度训练迭代低一个数量级的学习率。由于再训练的超参数的选择是至关重要的(Bergstra&Bengio,2012)ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











