







深入理解JS中的内存机制,浅析深浅拷贝
前言
讲个小故事吧:我在上学时,班上每个人都有自己的课桌(全班统一大小),课桌里空间有限,一般只能放一个书包就放不下了,班上公共区也有一个大一些的老师储物柜,每个老师都有一把钥匙打开,学生不能去动老师的储物柜,因为他们是“学生”。
老师检查作业时,点到名字的同学需要直接从抽屉里取出书包去拿自己的作业。
有一天数学老师去取自己的U盘时,发现U盘不见了,原来是昨天英语老师借走拷贝东西去了。
当有新的老师来上课的时候,班主任都会配一把新的钥匙给新老师,
当有新同学来的时候,他会得到自己的课桌。
阅读本文之后,我们可以在评论区探讨一下这个小故事!
说明:
Q 表示 question 问题
A 表示 answer 解答
我们认知的拷贝 == JS中的拷贝 ?
举个例子(示例-1):
function foo(){
var a = 1;
var b = a;
a = 2;
var c = { name:'abc'};
var d = c;
c.name = "123";
console.log(a);//2
console.log(b);//1
console.log(c);//123
console.log(d);//123
}
foo();
JS中的基本数据类型和引用数据类型
基本数据类型
Number、String 、Boolean、Null、Undefined、Symbol和BigInt
引用数据类型
Object、Array、Function、Data等
JS中的内存分配机制
很显然,JS中的拷贝相对于我们理解中的拷贝不完全相同!
Q1: 为什么会出现不同的拷贝结果?
A1:实际上这和JS的内存分配机制有关。在JS中,数据类型分为基本数据类型和引用数据类型。JS在保存不同类型值的方式不同。基本数据类型保存在内存的栈区,引用数据类型的数据保存在堆区,通过引用地址访问。
Q2:我们先来聊聊为什么内存要分为栈区和堆区?数据可不可以全部保存在栈区?
A2:js引擎需要用栈来维护程序执行期间的上下文状态,如果栈过大,所有数据都放在里面,会影响上下文的切换效率,进而影响整个程序的执行效率
Q3: 接着为什么基础数据类型要保存在内存的栈区,而引用数据类型要保存在内存的堆区?
A3:
基本数据类型占据的内存空间是固定的,所以可将他们存储在较小的内存区域 – 栈中。这样存储便于迅速查寻变量的值。
引用数据类型值的内存大小会更改变动,如果将其放在栈区,将会降低JS查询变量的速度。所以在栈区,引用数据类型存放的是对应堆内存中的访问地址,引用数据类型的值存放在堆区。
JS中的内存访问机制
1)按引用访问:javascript中是不允许直接访问保存在堆内存中的对象的,所以在访问一个对象时,首先得到的是这个对象在堆内存中的地址,然后再按照这个地址去堆区取得这个对象中的值
2)而原始类型的值则是可以直接访问到的。
从内存的角度对示例-1进行剖析
动态图示 :
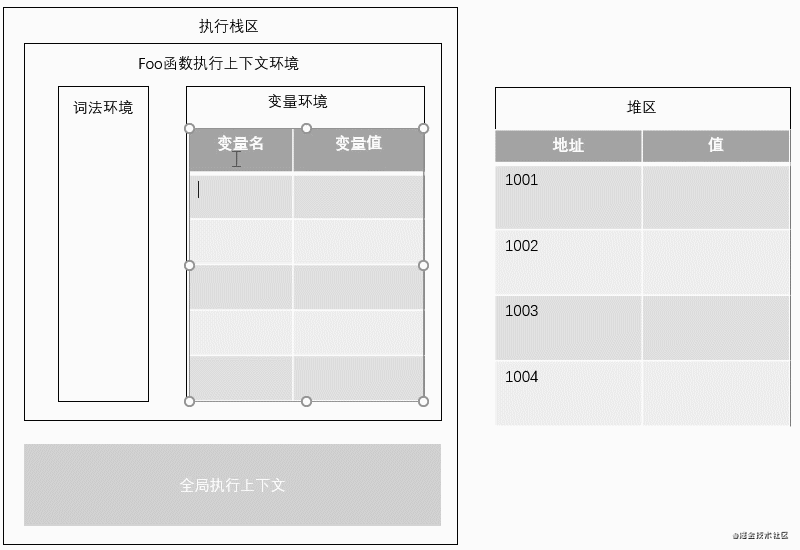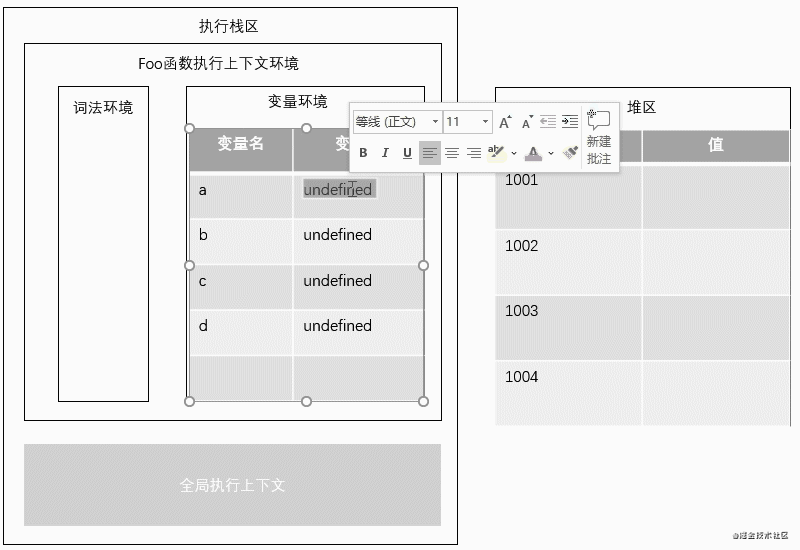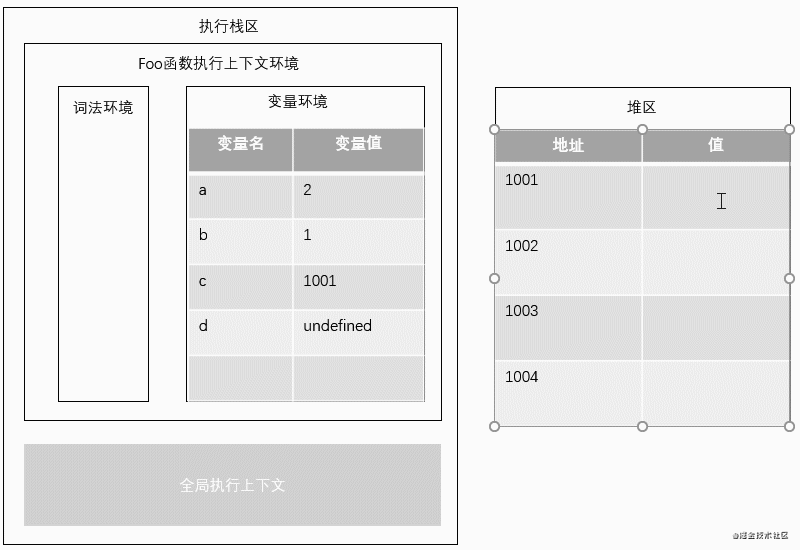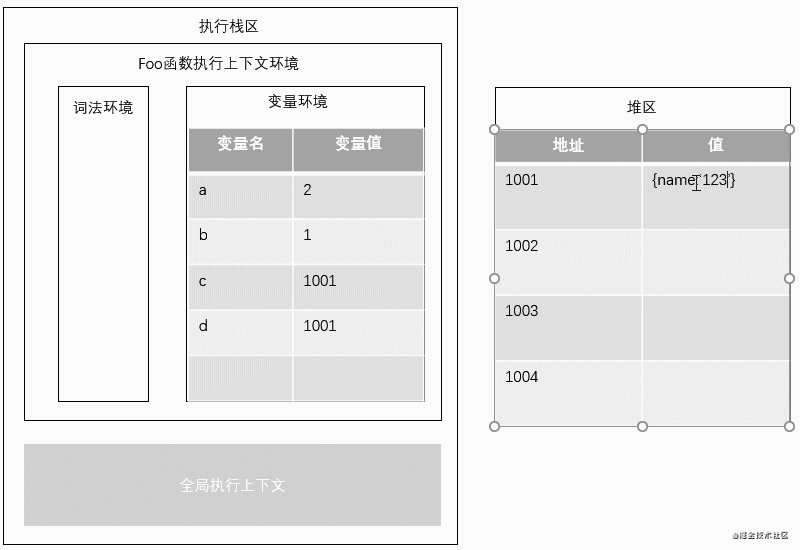
1.foo()函数执行时,在执行栈区会开辟一个属于foo()函数的执行上下文环境,可以理解为函数foo()的作用域。
2.根据JS编译原理,我们声明了四个变量,JS会先查找本作用域中是否有相同变量名的声明,有则忽略声明语句继续执行后续语句,没有则在内存栈区系统自动分配四个var变量的空间,值赋予undefined。
3.在给变量赋值和更改变量值时,基本数据类型直接修改栈区变量的值,而更改引用变量的值,改的是堆区的值,存储相同访问地址的变量,访问的也是同一个堆区的值
4.我们需要取值时,比如console.log(a,c);,我们在堆内存中找到对a,c的RHS引用(在栈区找到a,c变量),对a变量直接读取值,对c变量访问到引用地址时,再根据地址去堆区取值。
总结
本文仅是个人学习的笔记内容,仅仅简单介绍了JS中的深拷贝和浅拷贝。仍在学习之中,有不当的地方欢迎指出,共同学习。综上,我们可以大致总结一下:
浅拷贝:仅复制了对象的引用地址,两个对象指向同一个内存地址,所以修改其中任意的值,改的是地址所指向的堆中的值,另一个值都会随之变化。
深拷贝:在执行栈中系统分别自动分配内存区域,变量值保存在栈区而非地址,变量值是相同的,复制后的对象与原来的对象是独立的。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









