







端到端的图像压缩–《CONDITIONAL AND RESIDUAL METHODS IN SCALABLE CODING FOR HUMANS AND MACHINES》
CONDITIONAL AND RESIDUAL METHODS IN SCALABLE CODING FOR HUMANS AND MACHINES论文阅读
论文地址:https://arxiv.org/abs/2305.02562
摘要
我们在人类和机器的可扩展编码的背景下提出了条件编码和残差编码的方法。我们的重点是使用计算机视觉任务中可用的信息来优化重建任务的率失真性能。我们对两种方法进行了信息分析,以提供基线,并提出了一种适合条件编码的熵模型,该模型具有增强的建模能力和与以前的工作类似的易处理性。我们将这些方法应用于图像重建,在一种情况下,使用为 Cityscapes 数据集上的语义分割创建的表示,在另一种情况下,使用为 COCO 数据集上的对象检测创建的表示。在这两个实验中,我们在条件方法和残差方法之间获得了相似的性能,所得的率失真曲线包含在我们的基线内。
一、简介
1.1研究背景
- 随着人工智能技术的发展,数字内容不仅需要满足人类的需求,还需要满足机器的需求。
- 不同任务对内容的需求不同,且机器更偏好以适合其任务的方式表示内容。
- 在协作场景中,边缘设备捕获的信号需要传输到云服务进行处理,传输信息应仅限于完成任务所需的信息。
- 为每个子集任务创建表示会随着任务数量的增加而不易扩展。如果信息已经为某些任务传输,那么为更广泛的任务集传输新表示将存在冗余信息。因此,需要以可扩展的方式组合任务所需的信息。
1.2 研究问题与工作
如何利用可学习变换,有效地将信息从共享表示转移到目标域,以实现可扩展的表示编码。
提出了用于可扩展可学习压缩的条件和残差方法,其中转换表示以共享公共特征空间。还提出了一种熵模型,具有增强的建模潜力,适合条件编码。
1.3什么叫可拓展编码
可扩展编码(Scalable coding)是一种编码技术,旨在根据不同的需求或目标,灵活地组合和传输信息。它允许根据不同任务的需求,逐步增加信息量,从而实现可扩展性。
在可扩展编码中,通常存在一个基本表示(base representation)和一个或多个增强表示(enhancement representation)。基本表示包含满足所有任务所需的基本信息,而增强表示则包含特定任务所需的额外信息。这种设计允许根据实际需求逐步增加信息量,从基本表示开始,逐步添加增强表示,从而实现可扩展性。
例如,在视频编码中,基本层(base layer)包含满足所有基本播放需求的最低质量表示,而增强层(enhancement layers)则包含提高质量所需的额外信息。用户可以根据自己的带宽和显示设备,选择解码基本层、基本层+1个增强层,或者全部解码。这种灵活的组合方式使得视频编码可以根据实际需求实现可扩展性。
二、相关工作
- 可学习压缩:现阶段可学习编码输入和输出中间的潜在表达会产生信息瓶颈。通过采用变分编码框架、超先验和自回归模型可以突破信息瓶颈,取得更好的压缩比。
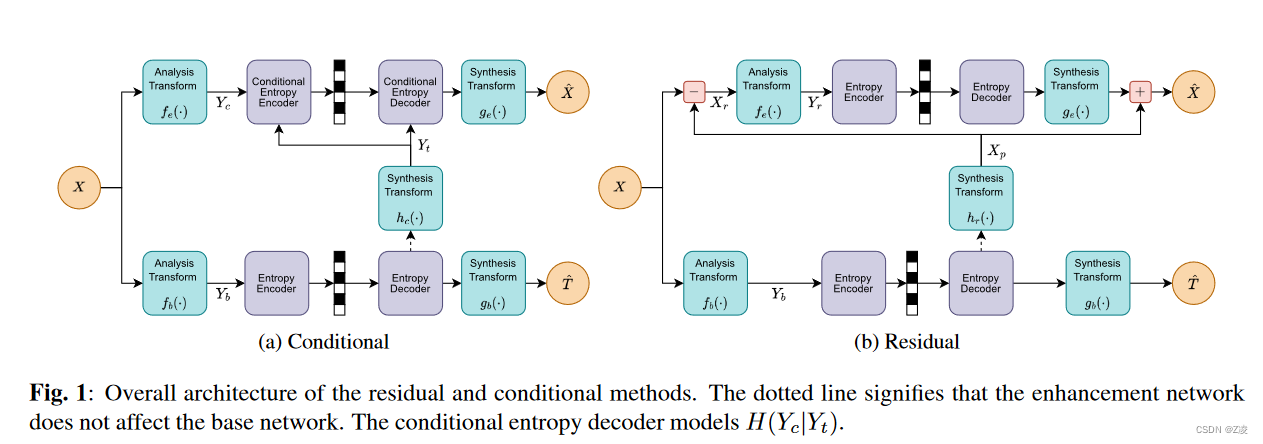
- 可扩展编码现状:现在的可拓展编码主要应用在图像重建和计算机视觉任务。重建任务使用专用表示和共享表示。这些表示解码后连接起来作为图像重建的输入。通过失真压缩比(rate-distortion)优化(有损压缩)生成图像重建的专用表示。在条件方法中,专用表示包含与重建相关的所有信息,但在编码期间利用共享表示解决的不确定性。在残差方法中,共享表示的信息在编码之前从目标表示中删除,然后在解码后沿着管道添加回来。
- 条件编码和残差编码:条件编码通常需要对辅助信息(先验、超先验)进行转换,这可能会导致一定程度的信息损失,使得残差方法可能优于条件方法。许多现有的可学习压缩的熵模型支持给定超先验表示的条件编码目标表示。在论文中,提出在两种方法中都转换辅助信息,并展示如何通过这种方式提高残差方法相对于条件方法的性能。此外,通过增强感受野和添加缩放残差连接的方式,增加了条件信息建模的能力。其中预测完全由原始信号解释,因此残差的信息量不能增加(why)。
三、模型框架
目标是训练一个有损压缩的基础表示:Y_b = f_b(X)。利用损失函数: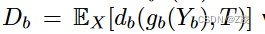
其中d_b(·,·)是任务损失函数,g_b(·)是可学习的解码函数。
在条件编码中,学习一个有损压缩的增强表示Y_c = f_e(X),以最小化失真![Dc = E[de( b X, X)]; b X = ge(Yc)](https://i-blog.csdnimg.cn/blog_migrate/30c0d7de74fe9ee71b88352399722e97.png) ,使用图像重建失真函数d_e(·,·)和可学习解码器g_e(·)。所有用于重建任务的信息都包含在Y_c中,而Yb中的信息用于有效编码Y_c。条件编码有效地建模了H(Y_c|Y_t),其中Y_t = h_c(Y_b)是Y_b的一个可学习变换,其直观特征空间与增强表示Y_c相似,以便利用它们的相似性。任何减少条件熵的信息都应该保留在Y_t中。(到这都和超先验模型类似,但是“超先验”是直接从原图得到的)。
,使用图像重建失真函数d_e(·,·)和可学习解码器g_e(·)。所有用于重建任务的信息都包含在Y_c中,而Yb中的信息用于有效编码Y_c。条件编码有效地建模了H(Y_c|Y_t),其中Y_t = h_c(Y_b)是Y_b的一个可学习变换,其直观特征空间与增强表示Y_c相似,以便利用它们的相似性。任何减少条件熵的信息都应该保留在Y_t中。(到这都和超先验模型类似,但是“超先验”是直接从原图得到的)。
在残差编码中,创建了一个类似的表示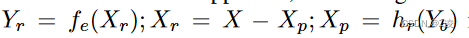 ,以最小化
,以最小化![Dr = E[de(ge(Yr) + Xp, X)]](https://i-blog.csdnimg.cn/blog_migrate/84fcb351339cce158345cb56c34c4698.png) 。这里,h_r(·)是Y_b的一个可学习变换,它隐式地重建了图像。在重建过程的最后添加预测X_p。
。这里,h_r(·)是Y_b的一个可学习变换,它隐式地重建了图像。在重建过程的最后添加预测X_p。
3.1条件边界:
理论分析是在无损情况下进行的,对 H(Y_b) + H(Y_c|Y_t) 进行建模,以 H(Y_c) 作为下界:
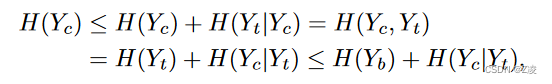
其中使用了H(Y_t) ≤ H(Y_b),这表示经过h_c变换熵不会增加。当H(Y_t|Y_c) = 0和H(Y_b|Y_t) = 0时,或者H(Y_b) = I(Y_c; Y_t)时等号成立。这对应于H(Y_c|Y_t)中信息的减少H(Yb)。
ps:
H(Y_t|Y_c):是Y_t和Y_c的条件熵。表示在给定Y_c的条件下,Y_t的剩余不确定性。H(Y_t|Y_c) = H(Y_t) - I(Y_t,Y_c)。条件熵反映了在已知Y_c的情况下,Y_t中还剩余多少不确定性,或者Y_t中还有多少信息是Y_c无法解释的。
H(Y_t,Y_c):是Y_t和Y_c的联合熵。它表示Yc和Yt这两个随机变量共同具有的不确定性。 H(Y_t,Y_c)=H(Y_t)+H(Y_c)-I(Y_t,Y_c).
I(Y_t,Y_c):是Y_t和Y_c的互信息。是衡量两个随机变量之间相互依赖性的一种统计量。
上界为:
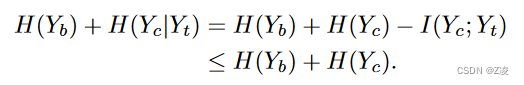
在I(Y_c; Y_t) = 0时等号成立,这对应于Y_c和Y_t是独立的。
3.2残差编码边界:
从下面两篇论文可知:条件编码是残差编码的上界

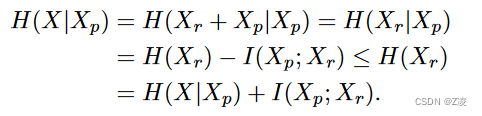
I(X_p;X_r)对残差公式起到了惩罚作用。为了最小化它,残余X_r和预测X_p必须尽可能独立。当X_p使X中的值塌陷,使H(X_r)减少时,或者当X_p对不同值产生恒定值,减少H(X_p)时,这可以实现。但减少H(X_p)会增加H(X|X_p)[因为H(X|X_p)=H(x)-I(X;X_p)=H(x)-],这反过来可能会对增加 H(Xr) 产生不利影响。强制X_p与原始输入X相似可能不是最佳过程,因为尽管这种优化将减小H(X|Xp),但它可能导致I(X_p;X_r)的增加。使用论文鼓励可学习函数hr(·)创建一个尽可能准确恢复输入X的表示X_p,同时尽可能独立于产生的残余X_r。
3.3熵模型:
论文提出了一个用于条件编码的CNN熵模型,该模型在建模复杂性和准确性之间取得了平衡。
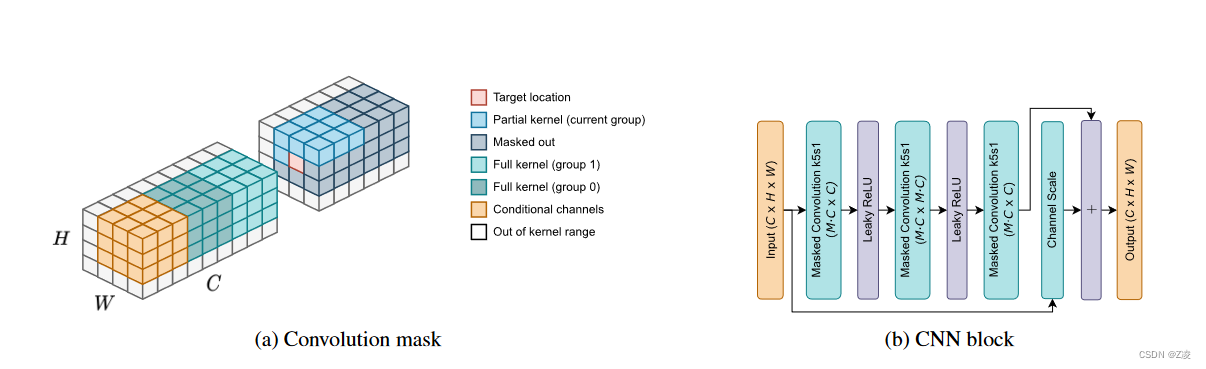
- 通道分组和上下文处理:通道被分成固定大小的组,同一位置上的通道并行处理,上下文包括之前所有组的位置以及当前组之前的位置。
- Markov属性:通过在卷积核上应用掩码来强制执行Markov属性。
- CNN架构设计:包括可扩展的残差连接和自动回归卷积层,增加了建模能力。
- 模型预测:预测对应于高斯分布的均值和尺度,通过添加(-0.5,0.5)的均匀噪声来模拟量化。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









