









一、概述
Generative与discriminative models这两大类型的模型对于理解和实现CRF(Conditional Random Fields)都是非常重要的,包括如何进行优化。
二、NLP信息提取中的Generative versus Discriminative Models解密
- Classification与Sequence Models剖析
关于classification,就是当给定一个vector表示features x = (x1, x2, . . . , xK)的情况下,预测单个离散型变量y。完成这个任务的一种简单的方式是,假设这个class label是已知的,所有features是相互独立的,虽然这样的假设看起来不太符合实际情况,但是在机器学习领域,由于数据的驱动,有着广泛的应用,包括垃圾邮件的分类,各种信息的识别等。这样获得的分类器被称为naive Bayes classifier,它是基于联合概率的模型,联合概率公式为:
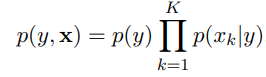
可以把p(y)看做是代表所有的情况,然后乘以在y的条件下xk的概率,k代表很多种情况 。
这个模型通过下图左侧示意的有向模型来进行描述(左边是naive Bayes classifier,即有向模型,右边是factor graph),可以看到从y到x有很多不同的路径,实际就是根据观察到的现象进行逆向的推导,这就是朴素贝叶斯所考虑到的基本情况:
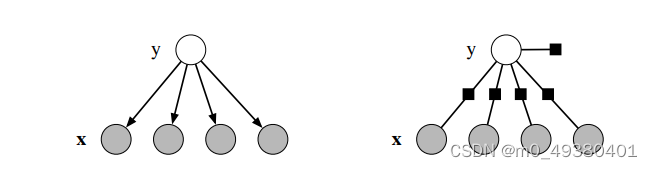
我们也可以通过为每一个feature定义一个factor Ψ(y) = p(y)和一个factor Ψk(y, xk) = p(xk|y)的方式把这个模型变为一个factor graph,那么在图中就是表达factors之间的相互作用关系。
另外一种知名的以图形化方式表示的模型是logistic regression,有时也被称为maximum entropy classifier。从统计学来说,这种模型是基于这种log概率假设产生的,即每一个类别的log p(y|x)是x的一个线性函数,再加上一个正则化常量,这就会导致条件分布:

这里的Z(x) 是一个常量:
![]()
在naive Bayes中,θy是一个bias weight,所起作用类似log p(y)。这里不是为每个类别使用一个weight vector,而是使用一个不同的notation,即一个weights的集合被多个类别所共享。这里的技巧是定义一套feature函数,它们对于单个类别来说是非零的,这些feature函数用于feature weights时可以被定义为:
![]()
而用于bias weights时可以被定义为:
![]()
然后使用fk对每一个用于feature weight的feature函数进行索引,使用θk对对应的weight θy ‘ ,j 进行索引,从而把逻辑回归模型表示为:
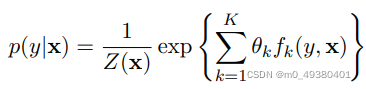
Classifier只预测单个类别变量,而图形化模型真正强有力的地方在于这种模型能够对很多相互依赖的变量进行建模的能力。这里讨论一种可能是最简单的依赖,输出变量排列在一个sequence中。这里讨论来自NER的一种应用,NER用于识别和分类文本中的正确名称,包括位置,人,组织等。NER任务是基于一个给定的句子,通过对句子进行划分(segmentation),得到哪些单词属于entities的一部分,然后通过type对每个entity进行分类(type包括位置,人,组织等),这项任务的挑战在于许多命名实体由于太少而不会出现在大规模训练集中,所以系统必须只基于上下文来识别它们。
使用NER的一种方式是为每个单词进行独立分类而不考虑它们之间的依赖关系。这种方式使用的假设显然是不符合实际情况的,在自然语言中,相邻单词的命名实体labels之间是有依赖关系的,例如,New York是一个地点,而New York Times是一个组织。放松这种独立性假设的一种方式是,以线性链的方式排列这些输出变量。这也是HMM模型所采用的方式。一个HMM对observations X进行建模:
![]()
假设存在一个基本的状态sequence 来自于有限状态集S:
![]()
每个observation xt是位置t的单词的ID,每个状态yt是命名实体label,即这些实体类型中的一个:Person,Location,Organization和 Other。为了对联合概率p(y, x)进行建模,HMM做出两个独立的假设:
-假设每个状态只依赖与它的immediate predecessor(它前面一个位置的内容),即状态yt独立于它之前的所有的ancestors:y1, y2, . . . , yt−2, yt−1
-假设每个observation 变量xt只依赖当前状态yt
通过上面的假设,使用三种概率分布来说明HMM:
-基于初始状态的概率p(y1)
-转移概率p(yt |yt−1)
-观察概率p(xt |yt)
那么由一个状态sequence y和一个observation sequence x构成的联合概率表达如下:
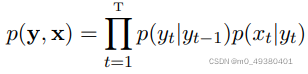
为了简化公式表达,把初始状态概率p(y1)表示为p(y1|y0),在自然语言处理时,HMMs被用于sequence labeling任务,譬如POS tagging,NER,以及信息提取。
2. generative与discriminative models解密
Generative models使用联合概率,描述了从概率来讲如何把输出生成为输入的一个函数,而discriminative models使用条件概率。Generative models包括naive Bayes 和hidden Markov models,discriminative models就是逻辑回归模型,
这两种模型主要的不同是条件概率p(y|x)不包括p(x)模型(x代表的情况都一样,不需要做任何分类)。p(x)建模的难点在于经常会包含很多高度依赖的features,从而导致很难建模,例如,在NER中,一个HMM只依赖一个feature,即单词的identity,但是很多单词的正确的名称没有出现在训练集中,所以word-indentity feature无法获取。为了对“不可见”单词进行标注,可以挖掘一个单词的其它features,譬如单词的大小写,相邻的单词,前缀和后缀,在人和地点的预定义列表中的成员关系等。这些建模中出现的问题及解决方式其实并不仅限于HMM或者CRF,在NLP处理中,我们需要尽可能考虑更多的维度层次,例如从词汇级别和字符级别来说,显然是捕获不同层次的信息,关于“不可见”的词汇可能是非常重要或者有价值的,在下面的DIET架构图中,在输入信息处理时,既有sparse features,又有pretrained embedding,从而可以混合各种不同层面的信息:
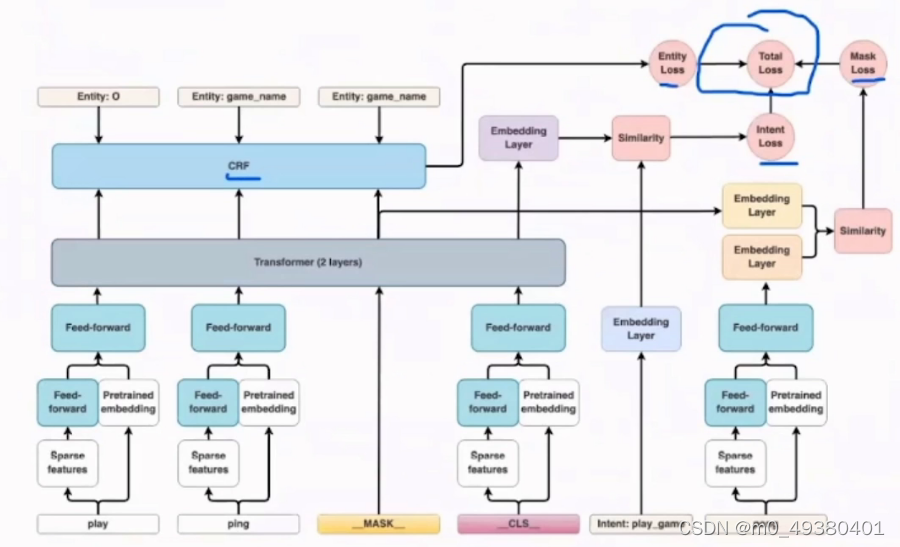
对于discriminative models来说,其核心优势在于可以更好地适配丰富的,重叠的各种features。
CRF在y之间做出独立性假设,并且假设y是如何依赖整个x sequence。可以这样来理解,假设用一个factor graph来表示联合概率p(y, x),然后构建一个graph来表示条件概率p(y|x),任何只依赖于x的factors从这个条件概率分布的图形化结构中消失。
为了把相互依赖的features包括在一个generative模型中,有两种方式:增强模型来表示输入之间的依赖性,或者简化独立性假设,譬如naive Bayes的假设。采用增强模型的方式会导致模型参数更复杂,计算量增加,而第二种方式因为独立性假设可能会使模型表现下降,例如虽然naive Bayes classifier在文档分类中表现良好,但是在大量应用中平均来说比逻辑回归模型表现差。
3. Naive Bayes, logistic regression, HMMs, linear-chain CRFs分析
Naive Bayes和logistic regression的不同之处在于前者是generative的,而后者是discriminative的。对于离散型输入来说,这两个分类器在所有其它方面都是相同的。这两种分类器都考虑同样的假设空间,从这个意义上来说,任何的逻辑回归分类器都可以转换成使用同样的decision boundary的Naive Bayes分类器,反之亦然。
Naive Bayes模型定义了与逻辑回归模型同样的概率分布范围,通常表示为:
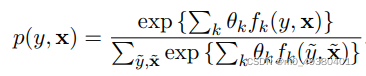
下面论文中的这幅图描述了各个模型之间的关系:
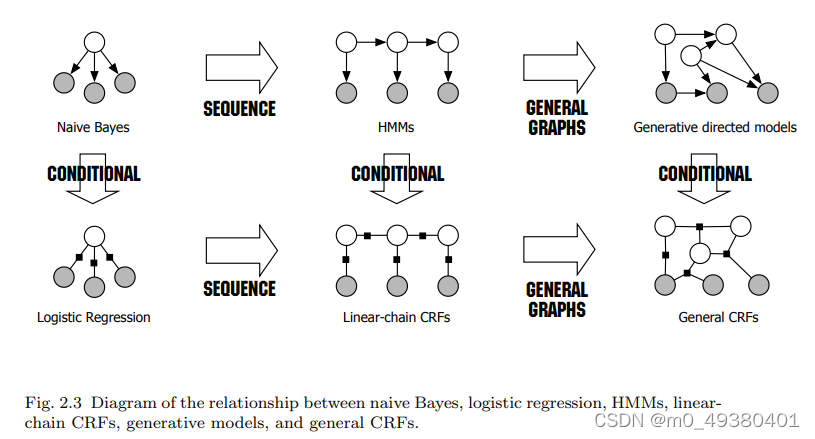
对于generative模型来说,有以下几个优点:
-在处理部分标注或者没有标注的数据时会更加自然,尤其是在完全没有标注数据时,能够以无监督的方式来使用,而discriminative模型在无监督学习方面仍然处于研究中
-在处理某些数据时,generative模型的表现比discriminative模型更好,这是因为输入模型p(x)可以对条件有一个平滑的效果,特别是在小数据集时效果更明显。对于任何特殊数据集来说,不可能提前预测哪一个模型表现更好。
naive Bayes 和logistic regression之间的关系类似于HMMs和linear-chain CRFs之间的关系。
欢迎订阅Rasa系列课程:
========================================================================
Rasa 3.x 源码高手之路:系统架构、内核算法、源码实现详解:
https://appz0c1mshy7438.h5.xiaoeknow.com/v1/auth?redirect_url=https%3A%2F%2Fappz0c1mshy7438.h5.xiaoeknow.com%2Fv1%2Fgoods%2Fgoods_detail%2Fp_62353091e4b0beaee43652c9%3Fentry%3D2%26entry_type%3D2001%26share_type%3D5%26share_user_id%3Du_621b7b85b8dc5_3yDAYnFXeM%26type%3D3
Rasa 3.x 源码高手之路:基于Transformer的对话机器人RasaPolice:
https://appz0c1mshy7438.h5.xiaoeknow.com/v1/auth?redirect_url=https%3A%2F%2Fappz0c1mshy7438.h5.xiaoeknow.com%2Fv1%2Fgoods%2Fgoods_detail%2Fp_62353421e4b04d7e2fd83665%3Fentry%3D2%26entry_type%3D2001%26share_type%3D5%26share_user_id%3Du_621b7b85b8dc5_3yDAYnFXeM%26type%3D3
星空NLP对话机器人论文班:NLP领域10篇最高质量的对话机器人经典论文解密:
https://appz0c1mshy7438.h5.xiaoeknow.com/v1/goods/goods_detail/p_623874b7e4b04e8d90256da1?type=3&share_type=5&share_user_id=u_621b7b85b8dc5_3yDAYnFXeM&entry=2&entry_type=2001
Rasa 3.X 智能对话机器人案例开发硬核实战高手之路 (7大项目Expert版本):
https://appz0c1mshy7438.h5.xiaoeknow.com/v1/goods/goods_detail/p_62276dd8e4b0beaee431c848?type=3&share_type=5&share_user_id=u_621b7b85b8dc5_3yDAYnFXeM&entry=2&entry_type=2001
Advanced Python硬核实力高手实战之路:架构、算法、源码、案例(81讲):
https://appz0c1mshy7438.h5.xiaoeknow.com/v1/goods/goods_detail/p_6227e564e4b0beaee431ce2a?type=3&share_type=5&share_user_id=u_621b7b85b8dc5_3yDAYnFXeM&entry=2&entry_type=2001
NLP on Transformers 高手之路137课Pro版:
https://appz0c1mshy7438.h5.xiaoeknow.com/v1/goods/goods_detail/p_621c0289e4b04d7e2fd0365a?type=3&share_type=5&share_user_id=u_621b7b85b8dc5_3yDAYnFXeM&entry=2&entry_type=2001



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









