






参考文档:
简书网友提供:
编程圈网友提供:
https://www.bianchengquan.com/article/131965.html
官方网站提供:
添加GPFS Client操作
软件包:https://pan.baidu.com/s/1qqwbfg3EuCUGKJ7nkLeb7Q
提取码:6lhi
一、GPFS介绍(最小内存2G,不然无法启动)
IBM Spectrum Scale是一个集群文件系统,它提供从多个节点对单个文件系统或一组文件系统的并发访问。节点可以是 SAN 连接的、网络连接的、SAN 连接和网络连接的混合,或者在无共享集群配置中。这可以实现对这组通用数据的高性能访问,以支持横向扩展解决方案或提供高可用性平台。
IBM Spectrum Scale具有许多常见数据访问之外的功能,包括数据复制、基于策略的存储管理和多站点操作。您可以创建由 AIX® 节点、Linux 节点、Windows 服务器节点或三者混合组成的集群。IBM Spectrum Scale可以在虚拟化实例上运行,提供环境中的通用数据访问、利用逻辑分区或其他管理程序。多个IBM Spectrum Scale集群可以在一个位置内或跨广域网 (WAN) 连接共享数据。
IBM Spectrum Scale提供了一个全局命名空间、 IBM Spectrum Scale 集群之间的共享文件系统访问、多个节点的同步文件访问、通过复制实现的高可恢复性和数据可用性、在安装文件系统时进行更改的能力,即使在大型环境中也能简化管理。
IBM Spectrum Scale是一个定义在一个或多个节点上的集群文件系统。在集群中的每个节点上, IBM Spectrum Scale由三个基本组件组成:管理命令、内核扩展和多线程守护进程。
IBM频谱的比例簇可以以各种方式来配置。集群可以是硬件平台和操作系统的异构组合。
二、环境介绍
| 节点名 | 节点IP | 节点作用 |
| gpfsnode1 | 192.168.27.61 | gpfs主节点 |
| gpfsnode2 | 192.168.27.62 | gpfs从节点 |
| gpfsclient | 192.168.27.63 | gpfs客户端 |
| timeserver | 192.168.0.7 | 时间同步服务器 |
三、安装前准备
- 配置yum源
- 配置/etc/hosts
- 配置ssh免密登录
- 关闭防火墙,selinux
- 配置时间同步
- 安装依赖包
-
3.1 配置yum源。
使用安装系统时的镜像作为yum的本地源来配置yum源。
3.2 配置/etc/hosts
将两台节点的信息分别写入各自机器的/etc/hosts文件下
-
[root@gpfsnode1 gpfs]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.198.131 gpfsnode1 nd1
192.168.198.129 gpfsnode2 nd2
192.168.198.130 gpfsclient cl1
192.168.198.128 timeserver ti1 -
3.3 配置ssh免密登录
分别配置三台机器之间root用户的免密登录

[root@gpfsnode1 ~ ]# ssh-keygen -t rsa Enter file in which to save the key (/root/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: [root@gpfsnode1 ~ ]# ssh-copy-id -i ~/.ssh/id_rsa.pub root@gpfsnode2 /usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/root/.ssh/id_rsa.pub" Are you sure you want to continue connecting (yes/no)? yes root@gpfsnode2's password: 这里输入gpfsnode2的密码

3.4 关闭防火墙、selinux
防火墙
关闭防火墙 [root@gpfsnode1 ~] systemctl stop firewalld 设置防火墙不开机自动启动 [root@gpfsnode1 ~] systemctl disable firewalld
SELinux
[root@gpfsnode1 ~] vim /etc/selinux/config SELINUX=disabled
注意:SELinux修改后需要重新启动机器
3.5 配置时间同步
[root@gpfsnode1 ~] crontab -e */5 * * * * /usr/sbin/ntpdate 192.168.0.7;/usr/sbin/hwclock -w
-
3.6 安装依赖包
对照如下表格安装所需依赖包
包名 功能 安装命令 Gcc 代码编译包 yum install gcc Cpp 计算机编程语言 yum install cpp Automake Makefile文件编辑器 yum install automake Kernel-devel 内核文件开发包 yum install kernel-devel Kernel-headers 系统内核头文件包 yum install kernel-headers binutils 一组开发工具包 yum install binutils Python Python主安装文件 yum install python Make Linux系统的编译工具 yum install make Ksh 交互式的命令解释器和命令变成语言 yum install ksh Gcc-c++ 针对C++的代码编译包 yum install gcc-c++ rpm-build rpm安装包编译工具 yum install rpm-build
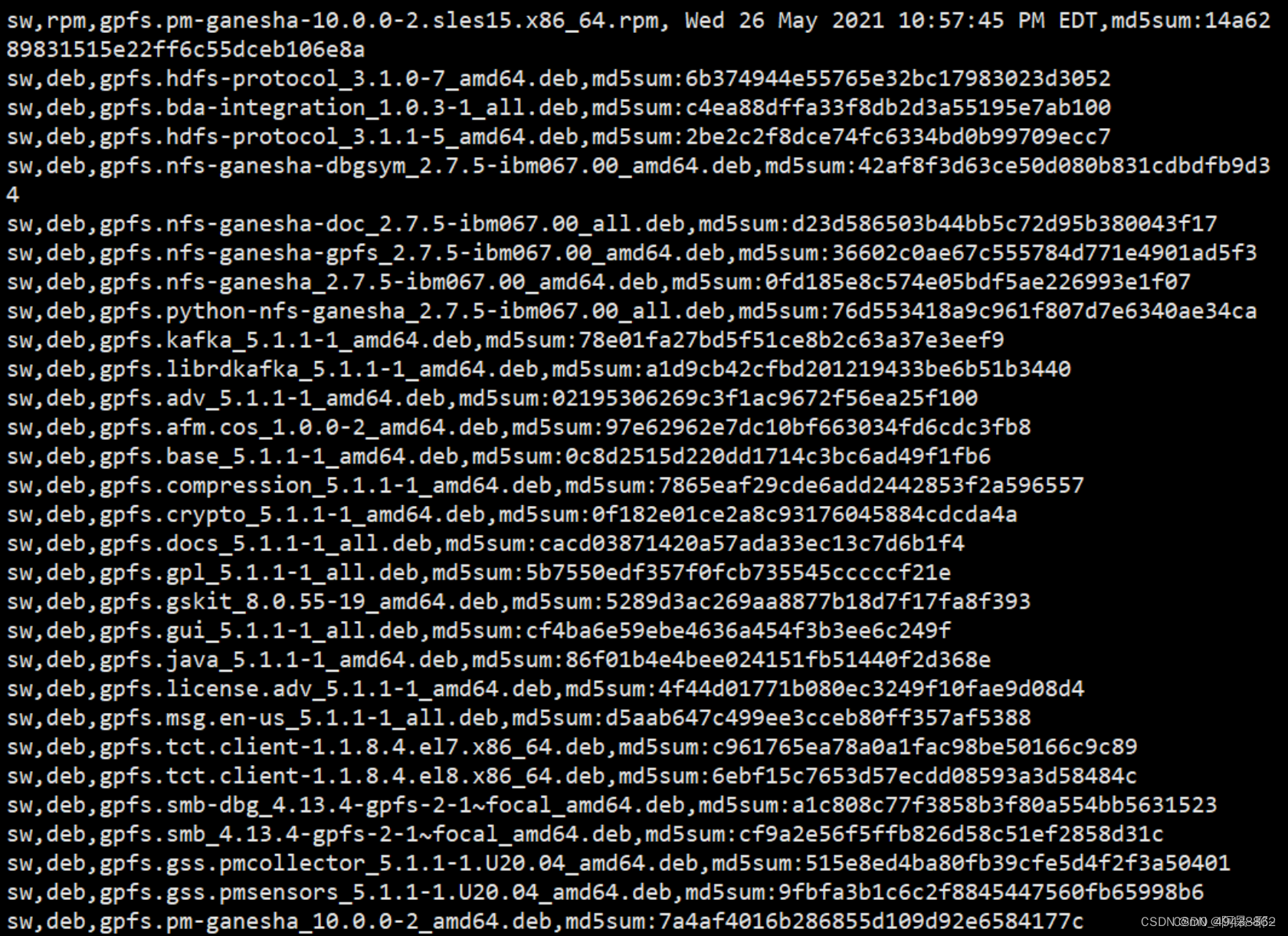
3.7安装gpfs软件包
[root@gpfsnode1 gpfs1]# ll
total 1378192
-rwxr-xr-x 1 root root 1411264833 Oct 27 16:40 Spectrum_Scale_Advanced-5.1.1.1-x86_64-Linux-install
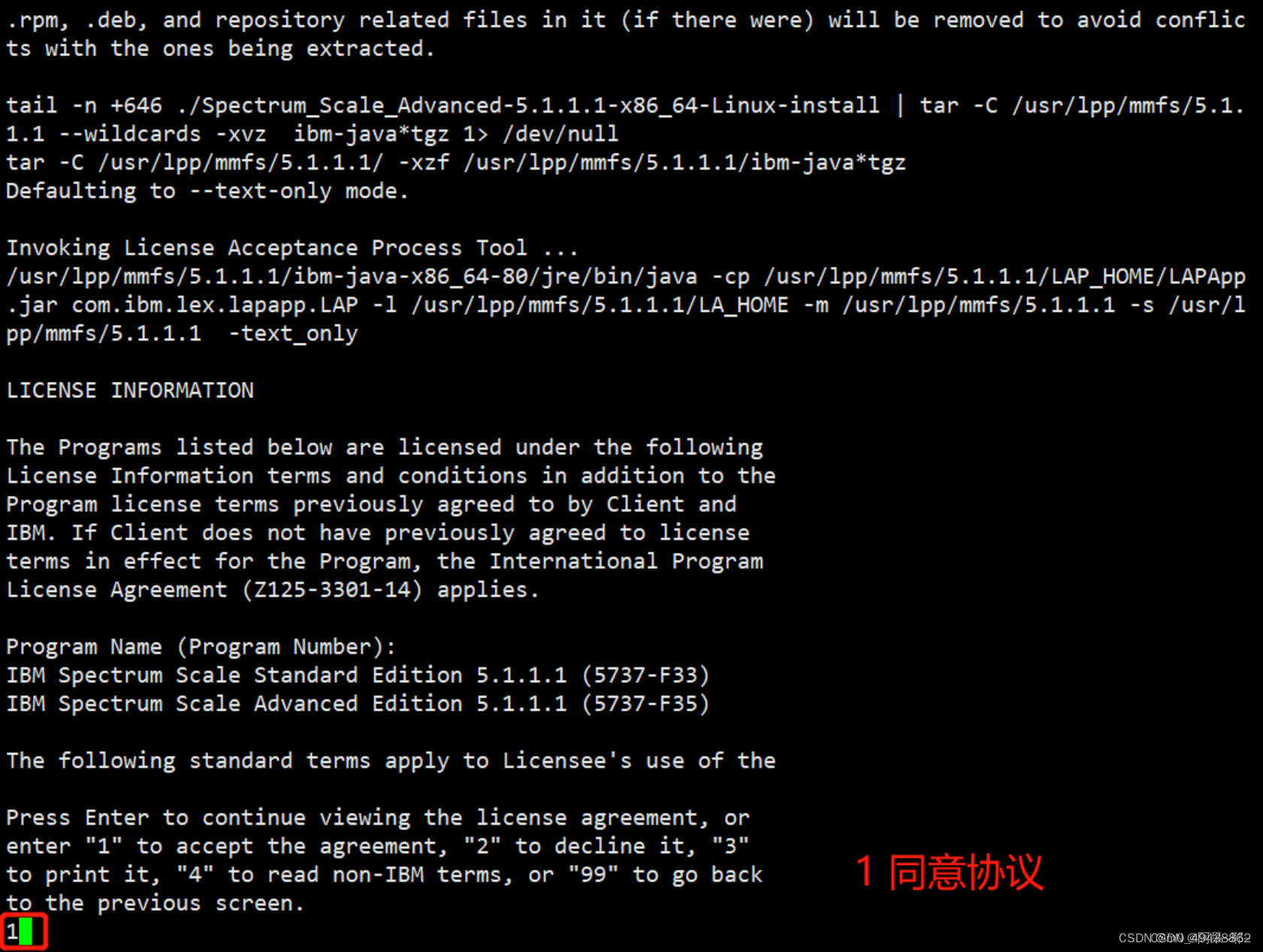
root@gpfsnode1 gpfs1# ./Spectrum_Scale_Advanced-5.1.1.1-x86_64-Linux-install --manifest
运行时,输出解释了如何接受协议:
默认情况下,RPM 软件包将被解压到以下位置:/usr/lpp/mmfs/5.0.3.0,一般redhat的rpm包在gpfsf_rpm目录里
[root@gpfsnode1 ~]# cd /usr/lpp/mmfs/5.1.1.0/gpfs_rpms
在Redhat Linux安装gpfs文件系统所需要的软件包如下:
![]()
gpfs.base-5.1.1-1.*.rpm
gpfs.gpl-5.1.1-1.noarch.rpm
gpfs.compression-5.1.1-1.*.rpm
gpfs.gskit-8.0.50-86.*.rpm
gpfs.msg.en_US-5.1.1-1.noarch.rpm
gpfs.license.xxx-5.1.1-1.*.rpm(其中 xxx 是许可证类型)
gpfs.adv-5.1.1-1.*.rpm(仅限 IBM Spectrum Scale Advanced 或 Data Management Edition)
gpfs.crypto-5.1.1-1.*.rpm(仅限 IBM Spectrum Scale Advanced 或 Data Management Edition)
按照如下顺序安装rpm包:
![]()
rpm -ivh gpfs*.rpm --nodeps -force 强制安装
四、安装gpfs软件包
4.2 配置环境变量
打开root用户的.bash_profile文件,添加如下内容。
vim /root/.bash_profile
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
PATH=$PATH:$HOME/bin:/usr/lpp/mmfs/bin
export PATH
4.3 构建 GPFS 可移植层
[root@gpfsnode1 ~]# /usr/lpp/mmfs/bin/mmbuildgpl --build-package
注意:
- GPFS 可移植性层特定于当前内核和 GPFS 版本。如果内核或 GPFS 版本发生变化,则需要构建新的 GPFS 可移植层。
- 尽管操作系统内核可能会升级到新版本,但它们在重新启动后才处于活动状态。因此,必须在重新启动操作系统后为这个新内核构建一个 GPFS 可移植层。
- 在安装新的 GPFS 可移植层之前,请确保先卸载先前版本的 GPFS 可移植层。
命令完成后,它会显示生成的包的位置,如下例所示:
Wrote: /root/rpmbuild/RPMS/x86_64/gpfs.gplbin-3.10.0-229.el7.x86_64-5.1.1-x.x86_64.rpm
然后,将生成的包复制到其他机器进行部署。默认情况下,生成的包只能部署到架构、分发级别、Linux 内核和IBM Spectrum Scale维护级别与构建gpfs.gplbin包的机器相同的机器上。但是,可以通过设置将生成的包安装在具有不同 Linux 内核的机器上MM_INSTALL_ONLY安装生成的包之前的环境变量。如果安装 gpfs.gplbin包,则不需要安装 gpfs.gpl包
4.4 创建集群
4.4 创建集群
[root@gpfsnode1 ~]# mmcrcluster -N /tmp/mmfs/nodefile -p gpfsnode1 -s gpfsnode2 -C gpfscluster -A -r /usr/bin/ssh -R /usr/bin/scp
参数说明:
-N表示节点的配置文件
-p表示主节点
-s表示第二节点
-C集群名称
-A表示当一个节点重启的时候GPFS守护进程不会关闭。
-r和-R都是通信协议。
nodefile是一个文件,其中包含要添加到集群中的节点和节点名称的列表,其内容如下:参数说明:
-N表示节点的配置文件
-p表示主节点
-s表示第二节点
-C集群名称
-A表示当一个节点重启的时候GPFS守护进程不会关闭。
-r和-R都是通信协议。
nodefile是一个文件,其中包含要添加到集群中的节点和节点名称的列表,其内容如下:
gpfsnode1:quorum-manager:
gpfsnode2:quorum-manager:
gpfsclience:
timeserver:
注意:GPFS的仲裁机制和ZooKeeper的仲裁机制类似,当有一半以上的节点是quorum时,集群才可以启动,即:quorum >= 1+sizeof(all nodes)/2
配置完成后,就可以通过 Spectrum Scale 内置指令创建集群,所有角色将自动按照事先定义的服务器自动推送与设置。
接受适用节点许可证。
[root@gpfsnode1 ~]# mmchlicense server --accept -N all
从节点使用以下命令启动 GPFS 守护进程和集群。
[root@gpfsnode1 ~]# /usr/lpp/mmfs/bin/mmstartup -N Nodename
4.5 创建NSD
创建要与mmcrnsd命令一起使用的 NSD 配置文件。
配置文件内容如下,放在任意位置即可。
%nsd:device=/dev/sdb nsd=data01 servers=gpfsnode1 usage=dataAndMetadata failureGroup=1 pool=system %nsd:device=/dev/sdb nsd=data02 servers=gpfsnode2 usage=dataAndMetadata failureGroup=1 pool=system %nsd:device=/dev/sdb nsd=data04 servers=timeserver usage=dataAndMetadata failureGroup=2 pool=system %nsd:device=/dev/sdb nsd=data03 servers=gpfsclient usage=dataAndMetadata failureGroup=2 pool=system %nsd:device=/dev/sdc nsd=data05 servers=gpfsnode1 usage=dataAndMetadata failureGroup=1 pool=system %nsd:device=/dev/sdc nsd=data06 servers=gpfsnode2 usage=dataAndMetadata failureGroup=1 pool=system %nsd:device=/dev/sdc nsd=data07 servers=timeserver usage=dataAndMetadata failureGroup=2 pool=system %nsd:device=/dev/sdc nsd=data08 servers=gpfsclient usage=dataAndMetadata failureGroup=2 pool=system
参数说明:
nsd (网络共享磁盘)表示网络共享磁盘的名称
device 表示真正的设备
servers 表示节点
usage 表示用途,metadataOnly(用于存放元数据)
failureGroup 失败组
pool 存储池
注意: NSD 配置文件中使用的服务器名称必须可由系统解析。
使用以下命令创建 NSD:
[root@gpfsnode1 ~]# mmcrnsd -F /gpfsfile/NSDfile
查看nsd:
[root@gpfsnode1 ~]# mmlsnsd -m
启动集群:
[root@gpfsnode1 ~]# mmstartup -a
查看集群状态:
[root@gpfsnode1 ~]# mmgetstate -Las
4.6 创建gpfs文件系统
使用以下命令创建 GPFS 文件系统。
[root@gpfsnode1 ~]# mmcrfs gpfs -F /tmp/mmfs/nsdfile -A yes -j hcluster -m 2 -r 2 -M 2 -R 2 -T /gpfs --metadata-block-size 256K
官方给出的命令如下(一般用这个创建):
[root@gpfsnode1 ~]# mmcrfs gpfs -F /tmp/mmfs/nsdfile -k nfs4
参数说明:(官方给出的命令没办法高可用,需要设置最小节点)
gpfs:表示文件系统的名称
-F:指定NSD配置文件
-A:当系统守护进程启动时该项设置为yes
-B:指定数据块的大小,其值必须是16k,64k,128k,256k,512k,1M,2M,4M,8M,16M.
-j:指定映射类型
-m:元数据副本数的默认值
-M:元数据副本数的最大值
-r:数据副本数的默认值
-R:数据副本数的最大值
-T:挂载点
--metadata-block-size:元数据节点块的大小
4.7 挂载文件系统
使用如下命令挂载gpfs文件系统,挂载成功后使用df命令可以查询到。
[root@gpfsnode1 ~]# mmmount gpfs /gpfs -N all
查询挂载是否成功,看见文件系统为gpfs的表示挂载成功。
4.8 创建文件集
[root@gpfsnode1 ~]# mmcrfileset gpfs sqdb
[root@gpfsnode1 ~]# mmlinkfileset gpfs sqdb -J /gpfs/sqdbfolder
[root@gpfsnode1 ~]# mmlsfileset gpfs
4.9 其他操作
![]()
查看节点
# mmlsnode
查看集群
# mmlscluster -Lsa
增加节点(如下为增加服务端,也可以修改server的参数后增加客户端)
# mmaddnode -N gpfs04:quorum
# mmchlicense server --accept -N gpfs04
关闭所有节点
# mmshutdown -a
# mmshutdown -N nodename
查看配置
# mmlsconfig all
修改配置
# mmchconfig
使用以下命令卸载 GPFS 文件系统并停止所有节点上的 GPFS。
# mmshutdown -a
卸载gpfs分区
# mmumount gpfs
使用以下命令在可用文件系统之一上配置 CES 共享根文件系统。
# mmchconfig cesSharedRoot=/gpfs/fs0
使用以下命令在集群中的所有节点上启动 GPFS。
# mmstartup -a
# mmstartup -N nodename
使用以下命令在所需节点上启用 CES。
# mmchnode --ces-enable -N prnode1,prnode2,prnode3
使用以下命令将协议节点的 IP 地址添加到 CES。
# mmces address add --ces-ip 198.51.100.2
# mmces address add --node prnode1 --ces-ip 198.51.100.2
使用以下命令验证 CES 配置。
# mmlscluster --ces
# mmces address list
![]()
更改自动挂载点
官方解释:
每个 GPFS 文件系统都有一个与之关联的默认挂载点。可以使用mmcrfs和mmchfs命令的-T选项指定和更改此挂载点。
如果您在创建文件系统时没有指定挂载点,GPFS 会将默认挂载点设置为/gpfs/ DeviceName。
mmcrfs -T
mmchfs -T
具体使用方式和其他命令使用方式可以参考官方网址:IBM Documentation
五、添加GPFS 客户端操作
通过上述操作,已经将GPFS群集搭建完成,并且已经生成文件系统和共享磁盘供客户端调用。之前已经介绍过GPFS是C/S结构的,为了让OpenStack中的nova、glance和cinder可以使用共享磁盘,本章将通过在OpenStack中安装GPFS客户端的方式,将共享磁盘挂载到云环境中的计算节点、镜像节点以及块存储节点。
5.1 安装GPFS软件
安装软件可以参考文章开头的操作过程,GPFS服务器端的安装和客户端的安装没有任何区别,软件的依赖关系也是一样的。
5.2 修改Host文件
在客户端修改/etc/hosts,加入GPFS的三台服务器,同时确保所有服务器和客户端可以免密码登陆,具体设置方法可以参考本章GPFS安装与配置。
5.3 创建客户端Nodefile
前面已经介绍,GPFS的客户端和服务器的区别主要是靠配置文件中的角色定义所决定。为了批量安装和配置好客户端,本项目将采用Nodefile方式对客户端进行单独安装。编辑addnodefile文件:
gpfsclient:client
5.4 添加客户端节点
在GPFS集群的任意节点上执行mmaddnode命令,将客户端节点加入到现有集群中,-N指定前面创建addnodefile文件。
[root@gpfsclient ~]# mmaddnonde -N addnodefile
同样,安装完成后,需要通过mmchlicense命令同意客户端的许可,并通过mmstartup启动客户端服务,通过mmgetstate命令查看群集状态:
[root@gpfsclient ~]# mmchlicense client --accept -N gpfsclient
[root@gpfsclient ~]# mmstartup -N gpfsclient
[root@gpfsclient ~]# mmmount gpfs /gpfs -N gpfsclient
节点服务启动后,GPFS文件系统会自动挂载,可以通过df -h命令查看。
5.5 其他操作
重新挂载
如果需要对gpfs文件重新挂载,那么先使用mmumount gpfs卸载后,重新执行mmmount 进行挂载。
[root@gpfsclient ~]# mmumount gpfs
[root@gpfsclient ~]# mmmount gpfs /gpfs -N ${CLIENT_NODE_NAME}
关于环境重启后恢复环境的操作:
如果需要重新启动环境,需要执行如下步骤才能恢复环境到正常情况
1.重启Server端的服务。
[root@gpfnode1 ~]# mmstartup -a
2.挂载Server端的gpfs目录。
[root@gpfnode1 ~]# mmmount gpfs /gpfs -N all
3.重启Client端的服务,如果gpfs自动挂载的路径不对,需要手动卸载gpfs的目录重新挂载。
[root@gpfsclient ~]# mmstartup -N gpfsclient
卸载:mmumount gpfs
[root@gpfsclient ~]# mmmount gpfs /gpfs -N gpfsclient
结束语
通过在 Redhat 上实现GPFS群集的部署与在云计算方面的应用,可以更多的了解其优秀的特性,提高存储性能及云计算的灵活性、扩展性。同时通过本文,可以让读者对GPFS有一个直观的了解和认识,不仅在Linux平台,在AIX和Windows平台上,GPFS也有不俗的表现。
gpfs 高级配置、升级等其他操作请查看官网手册
gpfs相关命令使用方式查询链接
https://www.ibm.com/docs/en/spectrum-scale/5.0.3?topic=command-reference
六、GPFS3 日常维护手册
原创
mb5fdcad5445be32020-12-21 21:00:31©著作权
GPFS相关名词解释
NSD
是Network Shared Disk的缩写,最早应用在GPFS的Linux集群上面。是GPFS实现的一种通过网络共享磁盘的技术,集群节点可以通过标准以太网访问NSD,使得不需要将集群的所有的节点都连到SAN上,而是基于NSD创建GPFS文件系统。
NodeQuorum
quorum机制决定了至少有多少个quorum节点可用时,集群才可以启动。Quorum的算法为:quorum= 1 + sizeof(quorum nodes)/2。
Filesystem Descriptor Quorum
顾名思义即描述文件系统信息的数据。我们在几个不同的failure-group 的磁盘上创建 GPFS 文件系统时,会把文件系统的配置信息(简写为 FD)的拷贝写到多个磁盘上,以实现冗余备份。FDquorum 的机制即通过判断含有 FD 磁盘的在线情况来判断当前系统是否正常,当超过半数的含有 FD 的磁盘掉线时,就判断为系统故障,将会自动关闭文件系统。
ConfigurationManager
配置管理器,在GPFS集群里面具有最长连续运行时间的节点自动被选为配置管理器,配置管理器有两个职能:1.选择文件系统管理器;2.判断quorum是否满足。
FileSystem Manager
文件系统管理器,每一个GPFS文件系统被分配一个文件系统管理器,文件系统管理器有如下几个功能:1.文件系统配置管理,如增加磁盘,修复文件系统;2.文件系统mount和umount处理.3.磁盘空间分配管理。
TokenManager:
执行分布式Token管理的功能节点,由集群管理软件根据工作负载情况动态地选择哪些节点、多少节点执行Token manager的功能。Token用来维护节点间数据的一致性和完整性。
GPFS相管理类命令
1.cluster启动:
使用root用户登录,执行:
| # mmstartup -a |
2.cluster停止:
使用root用户登录,执行:
| #mmshutdown -a |
3. 单节点启动:
使用root用户登录,执行:
| #mmstartup –N nodeName |
4.单节点停止:
使用root用户登录,执行:
| #mmshutdown –N nodeName |
5.查看cluster的配置信息:
使用root用户登录,执行:
| # mmlscluster 以测试系统为例: [root@sokf4a] /> mmlscluster GPFS cluster information ======================== GPFS cluster name: wxy-gpfs GPFS cluster id: 13882618647599424699 GPFS UID domain: wxy-gpfs Remote shell command: /usr/bin/rsh Remote file copy command: /usr/bin/rcp GPFS cluster configuration servers: ----------------------------------- Primary server: 4b-gpfs Secondary server: 4c-gpfs Node Daemon node name IP address Admin node name Designation ----------------------------------------------------------------------------------------------- 1 4a-gpfs 192.168.251.201 4a-gpfs quorum-manager 2 4b-gpfs 192.168.251.202 4b-gpfs quorum-manager 3 4c-gpfs 192.168.251.203 4c-gpfs quorum-manager 4 4d-gpfs 192.168.251.204 4d-gpfs quorum-manager 5 quorum-gpfs 10.19.84.136 quorum-gpfs quorum 在上面输出信息中: “Daemon node name”: 可以是hostname或IP address; “IP address”:GPFS网络的IP地址; “AdminNodeName”:管理节点属性是可选项,可配置为节点在DNS中名称,缺省为节点名 “Designation”:节点标识用于标识节点角色的属性列表, l Quorum 或 nonquorum l Client或manager |
6.查看所有节点状态:
使用root用户登录,执行:
| #mmgetstate –a 以测试环境为例: [root@sokf4a] /> mmgetstate -a Node number Node name GPFS state ------------------------------------------ 1 4a-gpfs active 2 4b-gpfs active 3 4c-gpfs active 4 d-gpfs active 5 quorum-gpfs active 在上面的输出结果中, “Node number”列表示本节点在GPFS集群中的节点号; “Node name”列表示节点的名称; “GPFS state ”列表示本节点GPFS服务的状态; l Active: 已启动就绪 l Arbitrating: 节点启动中等待仲裁quorum就绪 l Down: 节点停止 l Unknown: 未知,节点不能到达或发生其它异常错误 |
7. 查看文件系统的mount情况:
使用root用户登录,执行:
| # mmlsmount all –L 以测试环境为例: [root@sokf4a] /> mmlsmount all -L File system arch is mounted on 4 nodes: 192.168.251.201 4a-gpfs 192.168.251.203 4c-gpfs 192.168.251.204 4d-gpfs 192.168.251.202 4b-gpfs
File system db is mounted on 4 nodes: 192.168.251.202 4b-gpfs 192.168.251.204 d-gpfs 192.168.251.201 4a-gpfs 192.168.251.203 4c-gpfs 在上面的输出结果中,显示了GPFS文件系统已经在哪个节点上处于mount状态。 |
8.查看文件系统包含的NSD磁盘的状态
| #mmlsdisk fsName -L 以测试环境为例: [root@sokf4a] /> mmlsdisk arch -L disk driver sector failure holds holds storage name type size group metadata data status availability disk id pool remarks ------------ -------- ------ ------- -------- ----- ------------- ------------ ------- ------------ ----- nsd_fg2_9 nsd 512 2 yes yes ready up 1 system desc 在上面的输出结果中, “failure group”:表示该磁盘所属的失效组的编号; “availability”:表示该nsd的状态; l up 表示可用 l down表示不可用 “remarks”:此列默认为空,若为desc,则表示该磁盘为File system Descriptor Quorum,即参与文件系统仲裁。 |
9.查看文件系统的属性
使用root用户登录,执行:
| # mmlsfs fsName 以测试环境为例: [root@sokf4a] /> mmlsfs arch flag value description ------------------- ------------------------ ----------------------------------- -m 2 Default number of metadata replicas -M 2 Maximum number of metadata replicas -r 2 Default number of data replicas -R 2 Maximum number of data replicas -B 4194304 Block size -A yes Automatic mount option -T /arch Default mount point 在上面的输出结果中, “-m”和“-M”分别表示该文件系统默认的元数据副本的数量和最大的数量; “-r”表示该文件系统数据是否做了复制,1表示数据未复制;2表示数据复制; “-R”表示该文件系统中数据最多的份数; “-B”表示该文件系统的block size; “-A”表示该文件系统在GPFS服务启动时是否自动mount,yes表示自动mount;no表示不自动mount; “-T”表示该文件系统的挂载点; |
10. 扫描系统中的NSD
| #mmnsddiscover 以测试环境为例: [root@sokf4a] /> mmnsddiscover mmnsddiscover: Attempting to rediscover the disks. This may take a while ... mmnsddiscover: Finished. 上面输出信息表示系统扫描nsd完成。 |
11. 在GPFS集群的一个节点mount文件系统:
使用root用户登录,执行:
| #mmmount fsName |
12. 在GPFS集群的一个节点上umount文件系统:
使用root用户登录,执行:
| #mmumount fsName |
GPFS变更命令
1. 修改节点的角色
| I) 环境确认 查看集群信息,目前所有节点的角色都是quorum。 #mmlscluster GPFS cluster information ======================== GPFS cluster name: orakf4-gpfs.4a-gpfs GPFS cluster id: 13882618647599424699 GPFS UID domain: orakf4-gpfs.4a-gpfs Remote shell command: /usr/bin/rsh Remote file copy command: /usr/bin/rcp GPFS cluster configuration servers: ----------------------------------- Primary server: 4b-gpfs Secondary server: 4c-gpfs Node Daemon node name IP address Admin node name Designation ----------------------------------------------------------------------------------------------- 1 4a-gpfs 192.168.251.201 4a-gpfs quorum-manager 2 4b-gpfs 192.168.251.202 4b-gpfs quorum-manager 3 4c-gpfs 192.168.251.203 4c-gpfs quorum-manager 4 d-gpfs 192.168.251.204 d-gpfs quorum-manager 5 quorum-gpfs 10.19.84.136 quorum-gpfs quorum II) 角色修改 可以为节点增加/去除quorum或者manager角色,例如 为quorum-gpfs节点增加manager角色: # mmchnode --manager -N quorum-gpfs 取消quorum-gpfs的quorum角色: # mmchnode --nonquorum -N quorum-gpfs 让quorum-gpfs节点不承担任何角色: # mmchnode --client -N quorum-gpfs 更多用法可以参考man mmchnode. |
2. 变更配置节点(configuration server)
| 当前主配置节点为4b-gpfs,从配置节点为4c-gpfs。 欲将主配置节点设置为4a-gpfs节点,备配置节点设置为d-gpfs: # mmchcluster -p 4a-gpfs -s d-gpfs mmchcluster: GPFS cluster configuration servers: mmchcluster: Primary server: 4a-gpfs mmchcluster: Secondary server: d-gpfs mmchcluster: Propagating the new server information to the rest of the nodes. mmchcluster: Command successfully completed |
3. 变更manager角色
| 将cluster manger指向4a-gpfs节点: #mmchmgr -c 4a-gpfs 将文件系统arch的manager更改为4b-gpfs节点: #mmchmgr arch 4b-gpfs GPFS: 6027-628 Sending migrate request to current manager node 192.168.251.201 (4a-gpfs). GPFS: 6027-629 Node 192.168.251.201 (4a-gpfs) resigned as manager for arch. GPFS: 6027-630 Node 192.168.251.202 (4b-gpfs) appointed as manager for arch. |
4. 设置/变更NSD的server list
| I) 修改NSD server list之前,需要在所有GPFS节点上umount NSD所对应的GPFS文件系统,例如: #mmumount db -a II) 修改所有磁盘的server list 在修改NSD的server list时,尽量做到不同的NSD在各个NSD server之间访问路径的负载均衡。 编写nsd配置文件如下: cat > nsd.cfg << EOF nsd_fg2_1:4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs nsd_fg2_2:4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs nsd_fg2_3:4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs nsd_fg2_4:4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs nsd_fg2_5:4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs nsd_fg2_6:4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs nsd_fg2_7:4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs nsd_fg2_8:4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs nsd_fg4_1:4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs nsd_fg4_2:d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs nsd_fg4_3:4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs nsd_fg4_4:d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs nsd_fg4_5:4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs nsd_fg4_6:d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs nsd_fg4_7:4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs nsd_fg4_8:d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs EOF # mmchnsd -F nsd.cfg III) 查看确认 #mmlsnsd ………… db nsd_fg2_1 4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs db nsd_fg2_2 4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs db nsd_fg2_3 4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs db nsd_fg2_4 4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs db nsd_fg2_5 4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs db nsd_fg2_6 4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs db nsd_fg2_7 4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs db nsd_fg2_8 4b-gpfs,4a-gpfs,d-gpfs,4c-gpfs db nsd_fg4_1 4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs db nsd_fg4_2 d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs db nsd_fg4_3 4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs db nsd_fg4_4 d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs db nsd_fg4_5 4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs db nsd_fg4_6 d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs db nsd_fg4_7 4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs db nsd_fg4_8 d-gpfs,4c-gpfs,4b-gpfs,4a-gpfs ………… IV) 重新mount GPFS文件系统: #mmmount db -a |
5. 增加节点
| I) 环境确认 首先确认,新节点不属于任何一个GPFS cluster: #mmlscluster mmlscluster: This node does not belong to a GPFS cluster. mmlscluster: Command failed. Examine previous error messages to determine cause. II) 修改节点配置文件 然后,修改新节点上和GPFS集群已有节点的/etc/hosts和/.rhosts,所有节点的信息须一致并且包含新节点的信息,例如: # cat /etc/hosts ………… #GPFS network 192.168.251.201 4a-gpfs 192.168.251.202 4b-gpfs 192.168.251.203 4c-gpfs 192.168.251.204 d-gpfs 10.19.84.136 quorum-gpfs 192.168.251.205 test-newnode ………… III) 增加节点 这一步骤需要在已有GPFS集群内的节点运行。 在增加节点的同时决定节点角色(以下示例中,将新节点设为quorum-manager),也可以根据日后更改节点角色: [root@sokf4b] /> mmaddnode -N test-newnode:quorum-manager 依据实际购买情况接受GPFSlicense。一般来讲,承担NSD server、quorum等重要角色的节点都应该购买server license。仅供自己访问数据的节点可以购买client license: # mmchlicense server --accept -N test-newnode 启动新节点: # mmstartup -N test-newnode IV) 修改NSD server list 如果需要,可以依据1.2.5中的步骤,将新增节点加入到NSDserver list中。 |
6. 删除一个节点
| 如果该节点在承担特殊角色,需要更改掉这些角色后才能够成功删除该节点。 I) 修改配置节点角色 如果要删除的节点是集群的配置节点,那么需要先将此角色指定给其他节点: 假如test-newnode之前是集群的primary configuration server,需要将这一角色交由其他节点承担,如4a-gpfs: # mmchcluster -p 4a-gpfs II) 修改文件系统的callback策略 如果该节点之前配置了callback,也不能直接删除。由于callback不能被修改,因此可以先删除callback,删除节点后再重新添加callback。 # mmdelcallback localread III) 修改NSD的server list 如果该节点在承担NSD serverlist角色,需要将该节点从NSD Server list中剔除。 修改NSD server list需要先umount对应的文件系统,例如删除d-gpfs节点需如下操作: # mmumount arch # mmumount db # mmlsnsd |awk '{if((NF>1)&&(NR>3))print $2":"$3}' | sed 's/d-gpfs,//g' | sed 's/,d-gpfs//g' > newnsd.cfg # mmchnsd -F newnsd.cfg IV) 如果该节点在承担quorum角色,也不能直接删除。可以将其更改为nonquorum节点: # mmchnode --nonquorum -N d-gpfs V) 删除节点 # mmdelnode -N d-gpfs VI) 恢复之前的callback策略 # mmaddcallback localread --command=/var/mmfs/gen/localread --event mount --parms %fsName -N 4c-gpfs,4b-gpfs,4a-gpfs |
7. 为GPFS文件系统增加磁盘
| I) 确认磁盘 确定直连存储的操作系统已经识别可需要添加的hdisk. II) 编辑配置文件 新建并编辑文件/tmp/Name.disk.desc,添加如下一行: hdisk:serverList:::failuregroup:nsdName 其中: hdisk:AIX操作系统中磁盘的名称 serverList:NSD Server的名称;多个Server Node请使用逗号隔开,最多指定8个NSD Server,这些节点必须直连存储,第一个Server Node为primary NSD Server failuregroup: 当前来自2中心的存储failure group设置为2,来自4中心的存储failure group设置为4 nsdName:在GPFS中指定该hdisk全局名称 例如: hdisk34:4a-gpfs,4b-gpfs,4c-gpfs,d-gpfs:::2:nsd_fg2_15 III) 创建NSD # mmcrnsd -F /tmp/Name.disk.desc IV) 欲将新建的nsd_fg2_15加入到db中,执行命令 # mmadddisk db nsd_fg2_15 V) 添加磁盘后,新数据会在所有NSD上进行条带。如果需要将以往数据进行条带,运行: # mmrestripefs filesystem_name -b 如 # mmrestripefs db -b |
8. 删除GPFS文件系统中的磁盘
| I) 从文件系统中剔除NSD 确认需要删除的NSD磁盘以及其所属的文件系统。例如,将nsd_fg2_15从db中删除 # mmdeldisk db nsd_fg2_15 这一步骤会自动将数据拷贝到其他NSD。 II) 删除NSD # mmdelnsd nsd_fg2_15 |
GPFS日常诊断与故障处理
1. 在GPFS运行不正常时,可采用如下命令进行基本诊断:
| 检查项目 | 检查方法 | |
| 底层存储 | 检查所有I/O节点是否可识别到所有磁盘,个数、容量是否正常。 | lsdev –Cc disk lspv |
| 裸设备是否可读 | 例如 dd if=/dev/hdisk29 of=/dev/null bs=1024k count=10 | |
| GPFS cluster | GPFS集群间节点时间是否同步 | [root@sokf4a] /> export WCOLL=/tmp/nodes [root@sokf4a] /> mmdsh date |
| 查看GPFS cluster配置是否正确 | mmlscluster 可检查GPFS cluster name, Primary server, Secondary server以及集群节点列表和角色。 mmchcluster -p NewPrimaryServer mmchcluster -s NewSecondaryServer | |
| 各节点GPFS daemon是否正常 | mmgetstate -a //正常状态为active。状态为down的节点存在问题。Arbitrating说明节点正在启动中。 | |
| GPFS文件系统 | 挂载状况 | mmmount all -a //在所有节点挂载 mmmount all //在单节点挂载 mmlsmount all //列出文件系统的挂载状况 |
| 文件系统使用状况 | df //文件系统空间使用状况 mmdf db mmdf arch 须确保inode利用率小于90%. 文件系统利用率不要超过90%. 否则需进行文件系统housekeeping. | |
| 文件系统NSD状态 | mmlsdisk db -e mmlsdisk arch -e 注意检查status与availability是否为ready和up. 如果状态为down,确保连线回复正常后,首先在4个NSD Server运行/var/mmfs/gen/repair.sh 随后用mmchdisk命令恢复,例如 mmchdisk arch start -a mchdisk db start -a | |
| 日志 | 日志检查 | GPFS日志位于/var/adm/ras。 可首先查看mmfs.log.latest。 如有故障,运行gpfs.snap收集必要信息。 |
| 重要目录 | 不可删除 | /usr/lpp/mmfs/bin //GPFS命令 /var/mmfs/ //GPFS关键配置信息 |
2. GPFS出现站点存储故障
| GPFS A-A环境中,出现站点存储故障不会造成业务瘫痪。当存储恢复后,需要进行如下操作。 I) 检查磁盘 查看GPFS各个节点上的磁盘和磁盘路径状态,确认均处于正常状态。 #lsdev –Cc disk #lspath |grep -i failed II) 修复磁盘 若磁盘已恢复,但仍有failed路径,则需要在GPFS的4个NSD server上直接执行修复脚本即可: #sh /var/mmfs/gen/repair.sh III) 查看NSD磁盘的状态: #mmlsdisk filesystem_name -e -e参数将会只列出失效的NSD [root@sokf4a] /> mmlsdisk db -e GPFS: 6027-623 All disks up and ready [root@sokf4a] /> mmlsdisk arch -e disk driver sector failure holds holds storage name type size group metadata data status availability disk id pool remarks ------------ -------- ------ ------- -------- ----- ------------- ------------ ------- ------------ --------- nsd_fg4_1 nsd 512 4 yes yes ready down system nsd_fg4_2 nsd 512 4 yes yes ready down system nsd_fg4_3 nsd 512 4 yes yes ready down system nsd_fg4_4 nsd 512 4 yes yes ready down system nsd_fg4_5 nsd 512 4 yes yes ready down system nsd_fg4_6 nsd 512 4 yes yes ready down system nsd_fg4_7 nsd 512 4 yes yes ready down system nsd_fg4_8 nsd 512 4 yes yes ready down system 如果nsd出现了down的状态,就需要进行手工修复。 IV) 修复NSD磁盘 选择在业务不繁忙的时间,执行如下命令: # mmchdisk filesystem_name start -a -N GPFS_Node1, GPFS_Node2…. 需要注意的是,如上命令 –N所加节点,不应包含仲裁节点,以免造成网络流量,如 # mmchdisk arch start -a -N 4c-gpfs,d-gpfs,4a-gpfs,4b-gpfs V) 查看NSD磁盘的状态: #mmlsdisk filesystem_name -e 确保所有的NSD的状态均处于up状态。 |
GPFS的日志查看
1. GPFS日志:
| I) /var/adm/ras/mmfs.log.latest 该文件记录GPFS相关最新的日志。 II) /var/adm/ras/mmfs.log.previous 该文件记录GPFS上一次的日志。 III) /var/adm/ras/mmfs.log.<timestamp> 该文件记录按时间点记录GPFS的历史日志。 GPFS的日志会记录相关的相信信息,节选内容如下: Fri Nov 15 22:29:07.611 2013: GPFS: 6027-629 Node 192.168.251.202 (4b-gpfs) resigned as manager for db. Fri Nov 15 22:29:07.628 2013: GPFS: 6027-630 Node 192.168.251.201 (4a-gpfs) appointed as manager for db. 上面日志信息记录了,在时间点: Fri Nov 15 22:29:07时,4a-gpfs节点被指定成为cluster manger. |
2. 操作系统日志
| AIX:errrpt 在errpt中,直接与GPFS相关的报错会通常以mmfs开头,如类似报错: mmfs: STORAGE SUBSYSTEM FAILURE |

















 1027
1027

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









